Google Cloud で簡単にデータ分析基盤を作ろう
はじめに
こんにちは、クラウドエースのデータソリューション部の伊藤です。
普段は、データ基盤や機械学習基盤の構築だったり、Google Cloud 認定トレーナーとしてトレーニングを提供しております。
データ分析基盤の構築は、ビジネスにおける意思決定を迅速かつ正確に行うために不可欠です。しかし、データの収集、変換、格納といったプロセスは複雑で、多くの時間と労力を必要とします。
この記事では、Google Cloud の BigQuery を中心としたデータ分析基盤を作りたいと思いつつも、今ひとつ手が出ないような方向けに、(おそらく)最も簡単だろうと思われるデータ分析基盤のアーキテクチャを紹介します。
「こういうのでいいんだよこういうので」というお手軽さを目指します。
前提
- Google Cloud の UI を通した基本操作を理解していること
- BigQuery と Cloud Storage の基本操作を理解していること
全体アーキテクチャ
以下のようなアーキテクチャでデータ分析基盤を構築します。
Google Cloud の BigQuery Data Transfer Service を活用し、Google Cloud Storage( GCS )に置かれたファイルをデータソースとして、BigQuery を中心としたデータ分析基盤を構築します。
さらに、データの変換にはスケジュールドクエリを用いた ELT パターンを採用したものを解説します。
以下を参考にしてください。
データソースは CSV ファイルが GCS に置かれていることを想定しています。(BigQuery Data Transfer Service が対応している形式なら他のファイル形式でも OK)
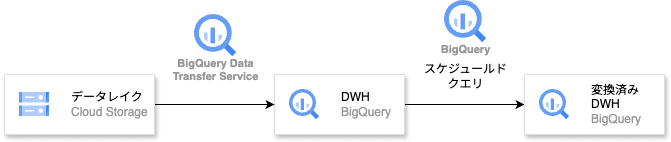
ポイントは
- BigQuery が中心
- 自動的な定期実行
- すべてサーバーレス
であることです。
これらの特徴により、設定や運用が容易なデータ分析基盤を構築できます。
また、BigQuery を中心としておけば AI/ML のサービスと将来組み合わせるとなったときにも、優位に立つことができるでしょう。
用語説明
- データレイク:生のデータソースの置き場
- データウェアハウス(DWH):分析可能な加工済みデータの保存場所
1. 準備
ファイルアップロード先の GCS バケットを作成します。
以下を参考に、GCS バケットを作成してください。
また、BigQuery データセットとテーブルを作成します。
以下を参考に、BigQuery データセットとテーブルを作成してください。
データセットの作成
テーブルの作成
このとき、データソースの CSV ファイルのスキーマに合わせてテーブルを作成してください。
データロード時にスキーマが合わないとエラーが発生します。
2. BigQuery Data Transfer Service を使ったデータロード

GCS に置かれた CSV ファイルを BigQuery に自動的にロードし、DWH(Data Warehouse)として保存したいと思います。
BigQuery Data Transfer Service は、様々なデータソースから BigQuery へのデータロードを自動化するサービスです。Cloud Storage だけでなく、Amazon S3、Azure Blob Storage、プレビューにはなりますが Oracle や Salesforce のデータなど、様々なデータソースに対応しています。
設定はとても簡単で、UI から操作するだけです。
BigQuery のコンソールから「データ転送」を選択し、新しいデータ転送ジョブを作成します。
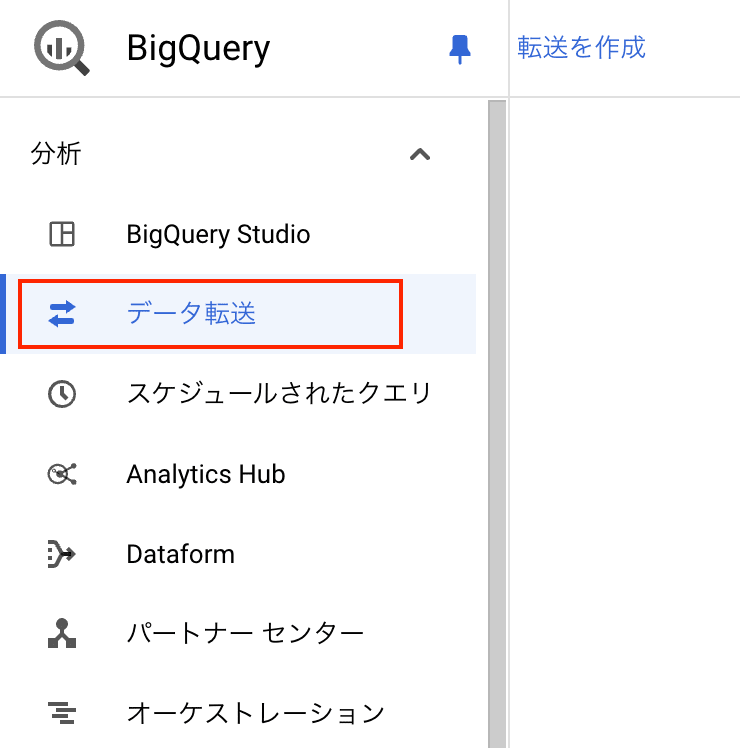
データソースについて選択し、データ転送のスケジュールを設定します。

保存先の BigQuery テーブルの情報を記載し、データ追加方法を選択します。
「APPEND」モードだと、データが追加されるたびに新しい行が追加されます。「MIRROR」モードだと、実行されるたびに全データが上書きされます。
データのアップロードし直しなどの複雑なパターンを考えない場合は「APPEND」モードを選択するのが無難です。

Cloud Storage URI はデータソースへのパスを記載しましょう。
日々、増分のデータを GCS へアップロードする場合※には、「gs://my-bucket/daily_*」のように「*」を使ってワイルドカード指定することもできます。
オブジェクトの更新されたタイムスタンプと BigQuery Data Transfer Service の過去の実行時間を比較して、新しいデータがあるかどうかを自動で判断してくれるので、特に気にすることなく日々のファイルをアップロードすることができます。
※
gs://my-bucket/daily_20220101.csv
gs://my-bucket/daily_20220102.csv
...
のように日々データをアップロードする場合
3. データ変換
DWH にデータがロードされたら、データ分析・可視化などを行いやすい形式に変換しましょう。
せっかく保存しても分析などがしにくい形式だと意味がありません。
変換が必要な場合、以下のような方法が考えられます。
- データの変換(単位揃え、型変換、NULL埋めなど)
- データの結合(複数データソースの統合)
- データのフィルタリング
特に不要な場合は、ここの変換はスキップし、データアナリストやデータサイエンティストの方に DWH のテーブルを共有したり、可視化のダッシュボードを作り始めるのもありでしょう。
このデータ変換を実現する方法としてはビュー、マテリアライズドビュー、スケジュールドクエリなどがありますが、ここではスケジュールドクエリを使ったデータ変換を紹介します。
例えば、日付が STRING 型で格納されている場合、DATE 型に変換するクエリは以下のようになります。
SELECT
CAST(date_column AS DATE) AS date_column,
other_column
FROM
`your_project.your_dataset.your_dwh_table`
上記のクエリは BigQuery のクエリエディタで実行することができますが、スケジュールドクエリとして設定する場合は、以下のようにエディタ上部の「スケジュール」からジョブをスケジュールします。
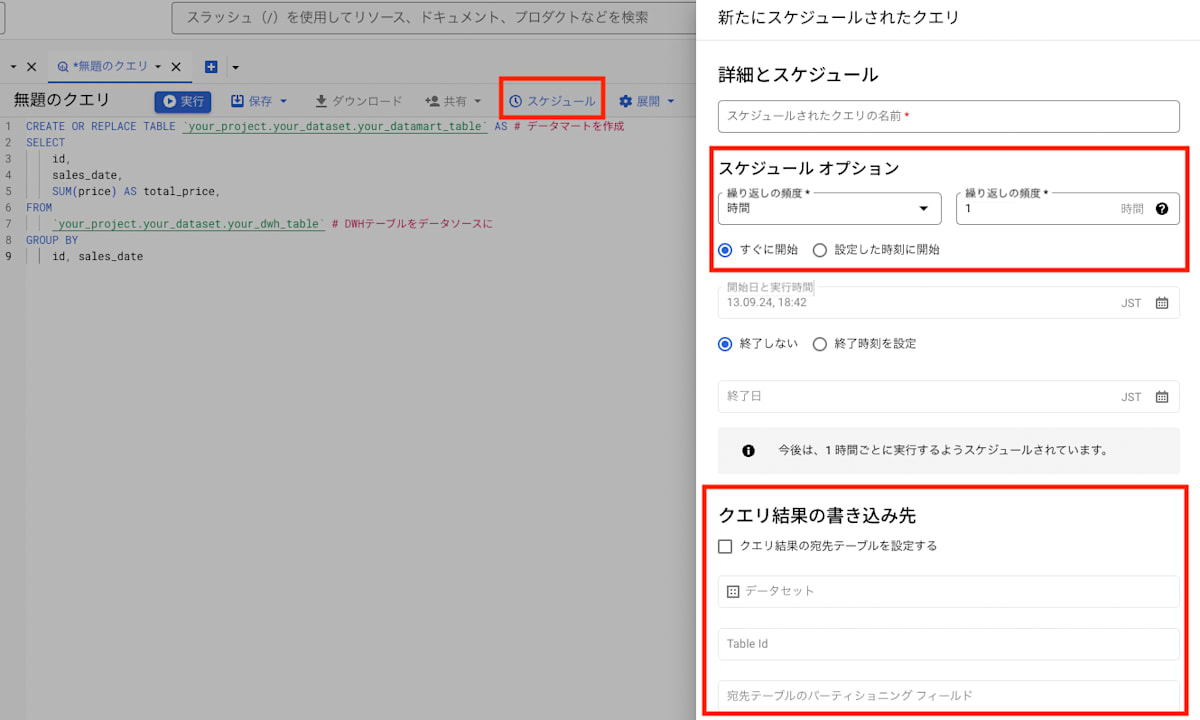
実行の頻度と上書き先のテーブル(今回作ろうとしているデータマート)の情報を埋めて設定します。
BigQuery Data Transfer Service のスケジュールと合わせて、スケジュールするのが良いでしょう。
4. データ分析
変換済み DWH まで用意ができたら、BigQuery の豊富な分析機能を使ってデータ分析を行います。
例えば、以下のような方法が挙げられます。
- BigQuery の SQL によるデータ分析
- BigQuery ML による機械学習
- Looker Studio などの BI ツールとの連携
- スプレッドシートとの連携
- BigQuery data canvas によるインタラクティブなデータ分析
- Notebooks によるデータ分析
- etc...
データ分析基盤構築後に何をすればいいかわからない場合は、上記を参考にしてみてください。
さらに強固なデータ分析基盤を構築するために
ここまでで、一番シンプルなデータ分析基盤のアーキテクチャを紹介しました。
このアーキテクチャは、データ分析基盤の構築を始める際に最初に取り組むべきステップとして適しています。
しかし、データ量やデータの複雑さが増加するにつれて、より強固なデータ分析基盤を構築するためには、以下のような拡張を検討することが重要です。
ジョブのスケジュールを Workflows や Cloud Composer などのジョブ管理サービスと組み合わせることで、データ分析基盤の自動化をさらに強化することができます。
また、データのセキュリティやガバナンスを強化するために、Dataplex を利用したメタデータ管理、データアクセス制御などの設定を行うことも重要です。
一定期間運用が安定してきたら、ぜひ上記のような拡張を検討してみてください。
まとめ
この記事では、BigQuery を中心としたデータ分析基盤を構築するためのシンプルかつ効率的なアーキテクチャを紹介しました。
BigQuery Data Transfer Service を活用することで、データの自動ロードを実現し、スケジュールドクエリを用いた ELT パターンによってデータ変換を自動化できます。
このアーキテクチャは、サーバーレスであるため運用負荷が低く、BigQuery の持つ強力な分析機能と将来的な AI/ML 活用への拡張性を備えています。データ分析基盤構築の第一歩として、ぜひ本記事の内容を参考にしてみてください。
外部データソースから Google Cloud にデータを持ってくるのが大変なんだよ...という声も聞こえてくる気がするので、これはまた別の機会に記事にしたいと思います。
Discussion