Google Cloud で簡単に分散処理 〜Dataflow job builder のご紹介〜
はじめに
こんにちは、クラウドエース データソリューション部の伊藤です。
普段は、データ基盤や機械学習基盤の構築だったり、Google Cloud 認定トレーナーとしてトレーニングを提供しております。
クラウドエース データソリューション部 について
クラウドエースのITエンジニアリングを担う システム開発統括部 の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのが データソリューション部 です。
弊社では、新たに仲間に加わってくださる方を募集しています。もし、ご興味があれば エントリー をお待ちしております!
今回は、Dataflow で新規機能としてリリースされた Dataflow job builder についてご紹介いたします。
Dataflowの新機能: job builder でコーディング不要のパイプライン構築
Dataflow にコーディングなしでパイプラインを構築・実行できる job builder が新たに追加されました。
これにより、データエンジニアやデータアナリストは、コーディングの知識がなくても、簡単にデータ処理パイプラインを構築できるようになります。
また作成されたパイプラインは、Dataflow で実行されるため、高速でスケーラブルな分散処理を行ってくれます。
この記事では、job builder の機能、特徴、ユースケース、使用方法について詳しく解説します。
job builder でできること
job builder はコーディングすることなく、大規模分散処理を行う Dataflow のパイプラインを構築することができます。
Pub/Sub、BigQuery、Cloud Storage のデータを読み込み、フィルタ、結合、集計などの変換処理を適用し、結果を Pub/Sub Topic、BigQuery、Cloud Storage に出力できます。
また、UI 上で作成されたパイプラインは、Apache Beam の YAML ファイルとして Cloud Storage に保存できるため、再利用が容易になります。
job builder のユースケース
公式ドキュメント[1]では以下のように案内されています。
- コーディングなしでパイプラインを迅速に構築したい場合
- パイプラインをYAML形式で保存して再利用したい場合
- サポートされているソース、シンク、変換でパイプラインを表現できる場合
- Google が提供するテンプレートがユースケースに合致しない場合
job builder の使い方
ここではサンプルの Word Count パイプラインを作成する手順を紹介します。
Google Cloud コンソールで「Jobs」ページを開き、「テンプレートからジョブを作成」をクリックします。
「Job builder」を選択します。
今まではこのページには Dataflow テンプレートしかなかったのですが、「Job builder」が追加されました。

大きく分けて以下の内容を埋めていく必要があります
- Job name
- Batch/Streaming
- Sources(入力)
- Transforms(変換処理)
- Sinks(出力)
- Dataflow Options(Dataflow 関連のオプションパラメータ)
解説のために今回はすでに用意されているサンプルの Word Count パイプラインを確認していきます。
右上の「LOAD」から「Word Count」を選択します。

Sources と Transforms、Sinks の3つのセクションが埋め込まれて表示されています。
右側には定義されている変換がビジュアライゼーションされ、どういったパイプラインの処理なのか一目でわかります。かっこいいですね。
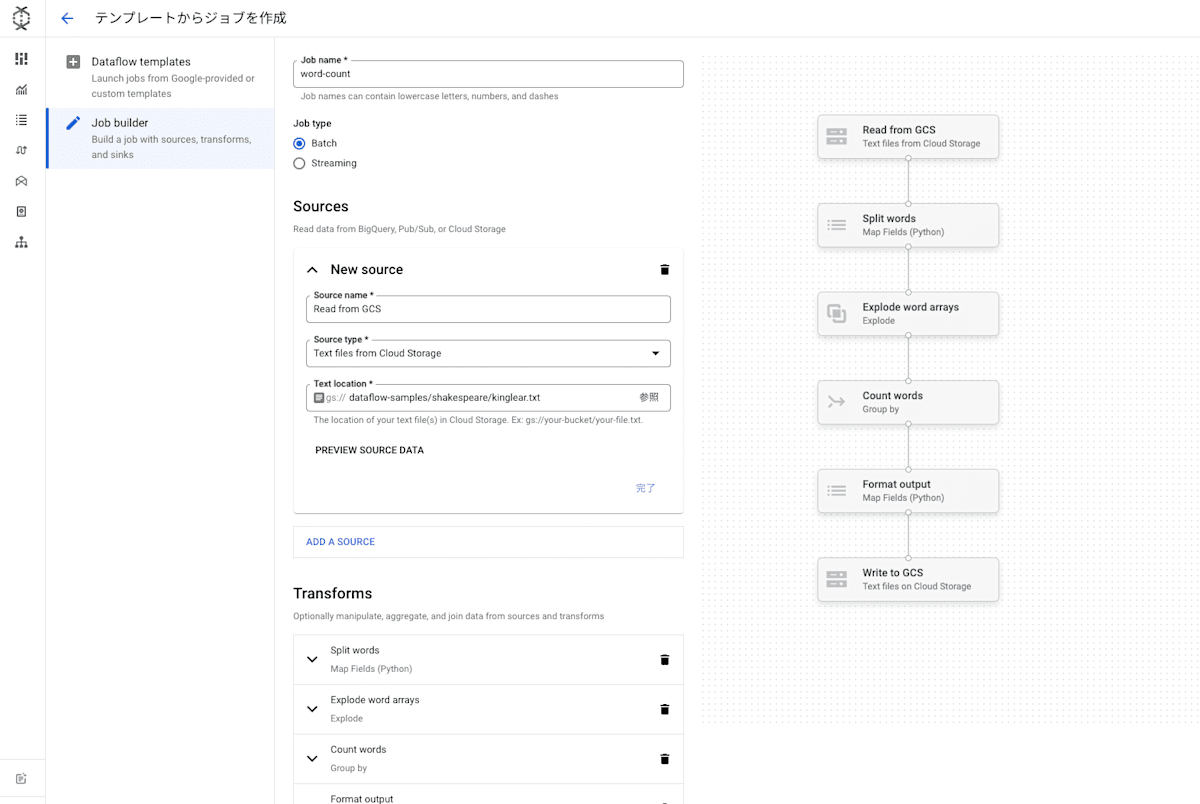
このサンプルの場合、Sink の出力先ファイルの指定が必要です。
Google Cloud Storage バケットを用意して、ファイル名とともに入力しましょう。

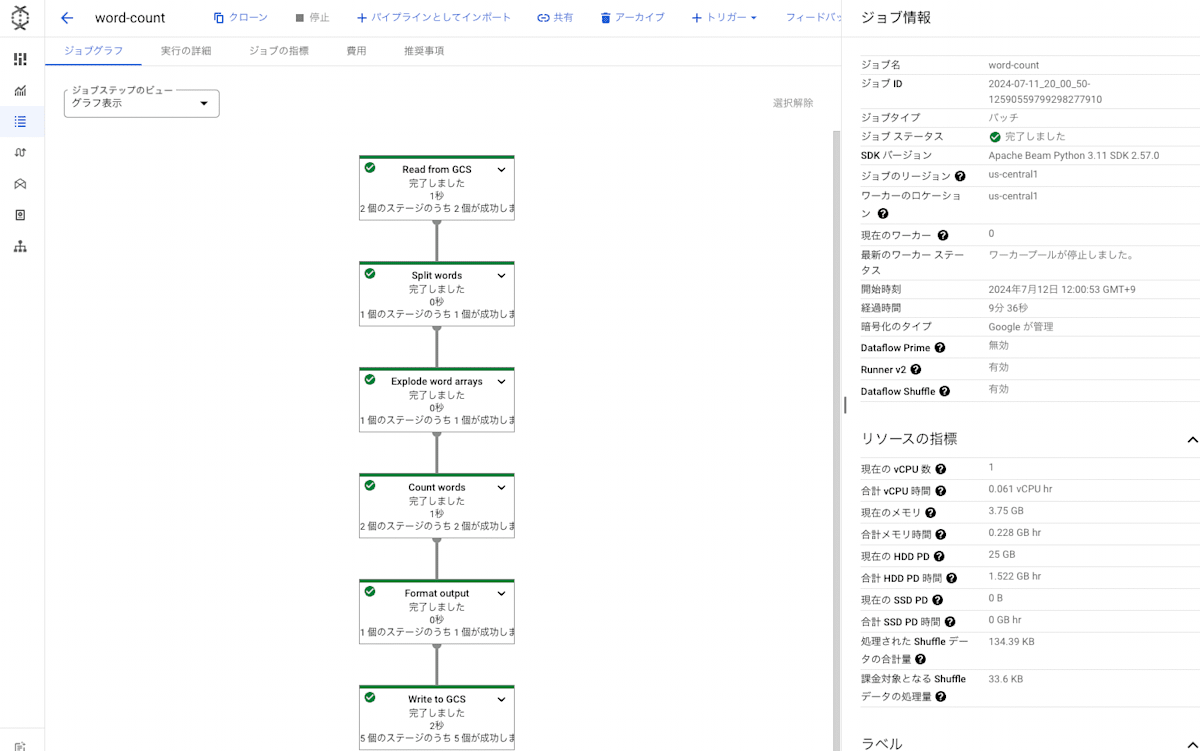
必要な設定が完了したら一番下の「ジョブを実行」をクリックし、ジョブを実行します。
ジョブが完了すると以下のような画面が表示されます。
job builder の特徴
さて、ここでは Word Count の例を通じて、job builder の特徴を解説します。
Sources
Sources はパイプラインの入力データを指定します。
2024年7月現在、以下の Sources がサポートされています。
- Pub/Sub
- BigQuery
- Cloud Storage(CSV、JSON、TEXT)
また、データソースをプレビューし、データの中身を確認することもできます。
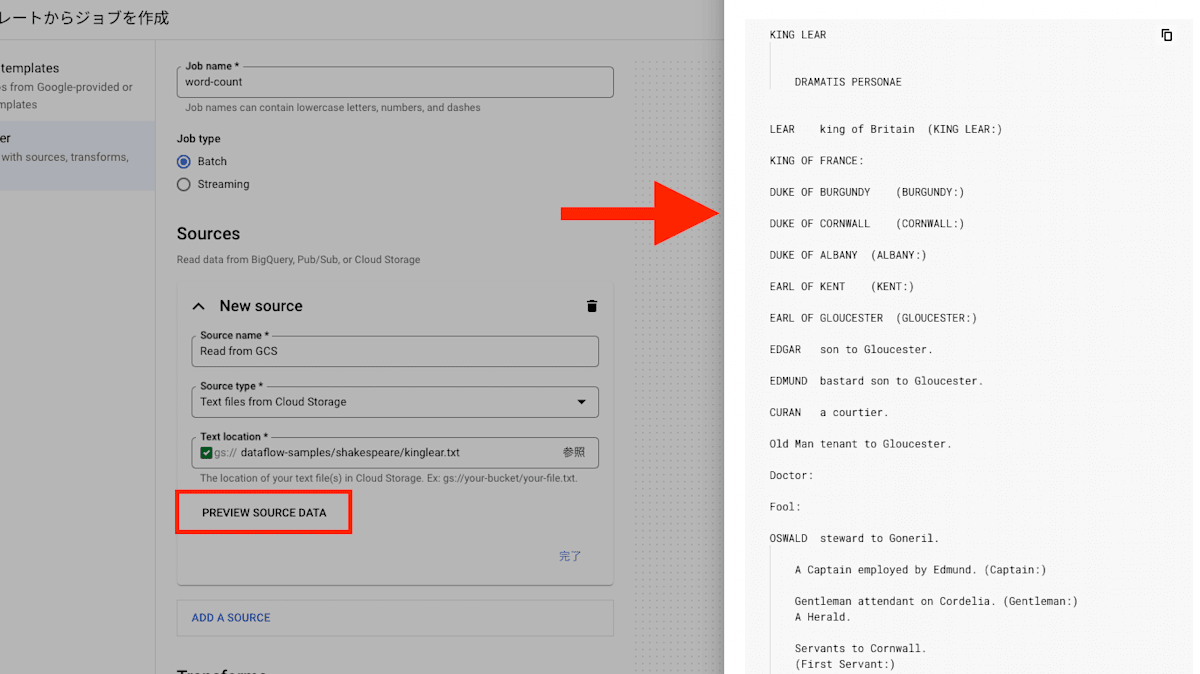
データソースは複数個選択でき、後述する変換処理でデータを結合することも可能です。
Transforms
Transforms はパイプラインの中でのデータ変換処理を指定します。
入力ステップと変換処理を入力し、データの変換処理を定義します。
2024年7月現在、以下の変換処理がサポートされています。
カッコ内の言語は、その言語での実装が必要であることを示しています。
- Filter(Python)
- データをフィルタリングします。
- Join
- 入力で指定した2種類のデータを結合します。
- Map(Python, SQL)
- データを個別に変換します。いわゆる1:1の変換処理になります。
- Group by
- キーを指定し、平均、合計、最大、最小などを指定します。キーごとに指定した集計処理を行ってくれます。
- Explode
- 配列データを展開します。いわゆる Flatten と呼ばれる処理です。
基本的な変換処理はカバーできそうですが、複雑な処理を行いたい場合は少し難しそうです。
Filter や Map の処理を行う際には定義のために Python コード(もしくはSQL)を記述する必要があります。
ここでは Map を例として少し詳しく見ておきます。
「Word Count」のパイプラインの中で「Split Words」が Python 関数を利用した Map です。
関数として書いておけば、変換時に記述した関数が呼ばれるようです。
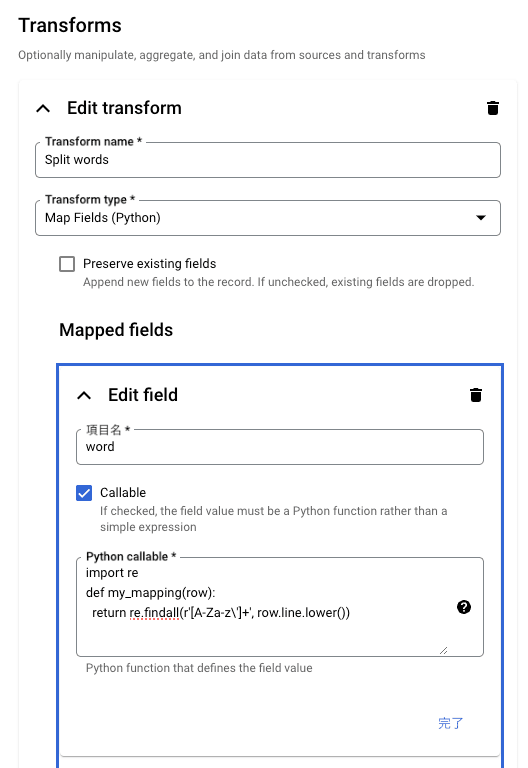
また「Format Ouptut」が Python 式を利用した Map です。
Callable のチェックボックスを外しておけば、式(expression)だけでも良さそうです。

「Input step for the transform」を同じものにすることで下図のように複数に分かれるパイプラインも構築することができます。
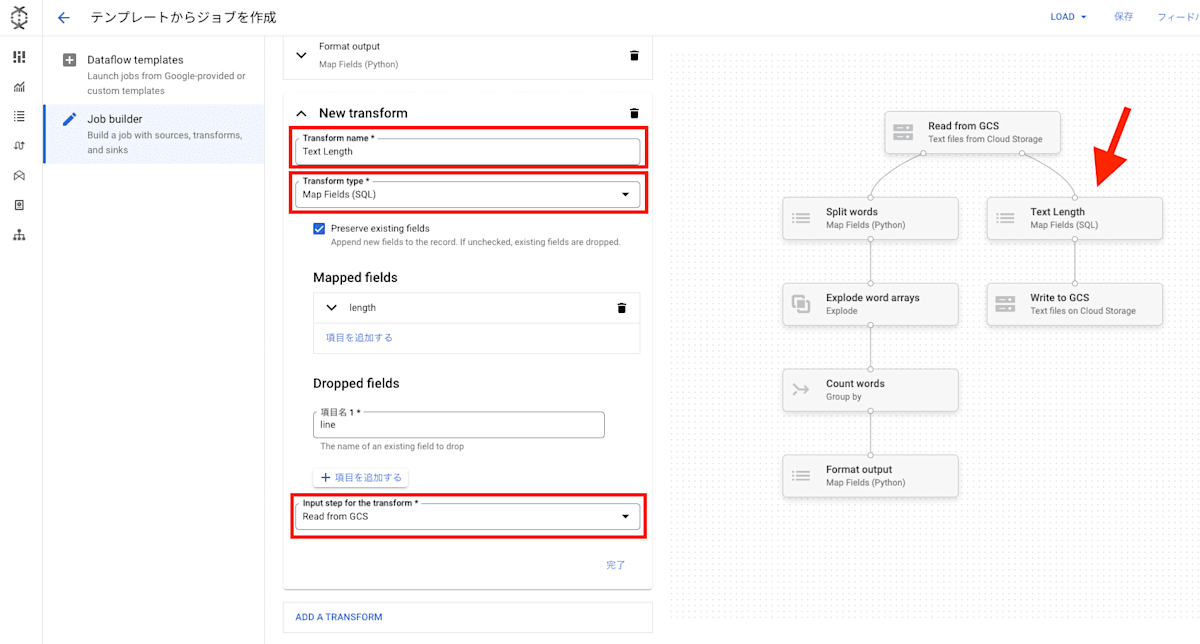
データのバリデーションも行われているようで、変換対象の field の指定を間違えると怒られます。

Sinks
Sinks はパイプラインの出力先を指定します。
ここでも複数の出力先を指定することができます(つまり最終結果を2箇所に書き込んだりすることもできます)。
2024年7月現在、以下の Sinks がサポートされています。
- Pub/Sub Topic
- BigQuery
- Cloud Storage(CSV、JSON、TEXT)
ストリーミング
job builder はバッチ処理だけでなく、ストリーミング処理もサポートしています。
「NYC Taxi Pickups」サンプルはストリーミング処理のものですので、試してみると良いでしょう。
ただし、ストリーミング処理を行う場合は、ウィンドウの設定[2]が必要になります。このあたりの概念を理解してから利用することをおすすめします。

作成したパイプラインの保存と読み込み
パイプラインを Beam YAML ファイルとして Cloud Storage に保存したり、クリップボードにコピーしたりできます。
保存した YAML ファイルを job builder で読み込んで、パイプラインを変更・実行できます。
Apache Beam では少し前のバージョンから YAML API が提供されています[3]が、job builder はこの YAML API を利用しています。
YAML ファイルとしてパイプラインを保存するときには右上の「保存」ボタンをクリックします。
逆に YAML ファイルをパイプラインとしてロードするときには、右上の「LOAD」ボタンをクリックし、GCS に保存されている YAML ファイルを選択します。もしくは直接 YAML ファイルをコピーして貼り付けることもできます。
まとめ
Dataflow の job builder は、コーディング不要で簡単にパイプラインを構築できる強力なツールです。
使えるソース、シンク、変換処理は限られていますが、基本的なデータ処理はカバーできるため、データエンジニアやデータアナリストにとって非常に便利な機能です。
ぜひこの新しい機能を活用して、データ処理の効率化を図ってみましょう。
参考
- [1] Use the job builder UI
- [2] Streaming pipelines
- [3] Beam YAML API
Discussion