Dataform を使って BigQuery データ パイプラインの依存関係を管理する



クラウドエースでデータ ML エンジニアをやっている神谷と申します。業務では、データ基盤構築やデータ分析に取り組んでいます。本記事では、最近パブリックプレビューになった Dataform を使って、BigQuery のデータ パイプラインの依存関係管理をしてみます(クイックスタートをベースとした前提条件の設定、Dataform プロジェクトの開始方法、画面操作イメージ等についてはこちらの記事を参照ください。)
1. はじめに
ビッグデータ基盤において、データ パイプラインやデータそのものの品質を保つことは難しいと考える人は少なくないと思います。扱うデータ量が多くなればなるほど技術的難易度や運用コストは上がります。そういった中で、Google Cloud においては BigQuery を導入することでスケーラビリティの確保とコスト最適化を実現してきました。
ひとたび BigQuery 内に DWH を作った後、例えばBI での可視化など、最終的に利用したいデータ形式に向けて、多段のデーマートを連ねてデータを洗練させていくと思います。これまでだと、そのような際のテーブル同士の依存関係管理は Cloud Composer や Workflows、Vertex AI Pipelines 等で DAG を組んでいたと思います。もちろんこれらのプロダクトも素晴らしいですが、重厚な OSS を覚えたり、サーバの管理をしたり、プログラムが複雑になったりと、それなりに敷居が高いものでした。
また、BigQuery 主体の ELT パイプラインの場合、テストコードを書いたり自動テストを導入したりといったことに手が回らなかったケースも多かったのではないでしょうか? Python や Java といった言語を使えば容易に実装できていた自動テストも、BigQuery で書いた SQL となるとあれやこれやと工夫を凝らす必要がありました。
Dataform はこれらの課題を解決するのに適したフレームワークです。Dataform を利用することで実装が楽になるだけでなく、データに対する信頼性や、テストまたはデプロイのしやすさを高めることができます。
2. Dataform とは
Dataform は、「データ分析者が BigQuery でデータ変換を行うための複雑な SQL ワークフローを開発、テスト、バージョン管理、スケジュール管理するためのサービス」[1]です。筆者が考える Dataform の特徴的な点は以下の通りです。
- SQLX(extension of SQL)という拡張 SQL 言語を使うことで、BigQuery で書いた SQL のテストを自動化できる
- SQL のコードリポジトリを GitHub に置き Cloud Build を利用して、クエリの CICD フローを組める
- BigQuery の機能特性上、弱点とされてきたことも Dataform を利用することで解消できる
例えば、BigQuery のテーブルのカラムには PK という概念がなく、通常の RDB に存在するような一意キー制約を設定することができません。Dataform では、テーブルの構造をメタ言語によって管理でき、BigQuery のスキーマを拡張することができます。以下に示すように、config の設定で、アセットのタイプ(table or view)、テーブルの説明、カラムの説明のみならず、「assertions」という形で制約(「uniqueKey: ["id"]」)を追加することができます。
config {
type: "table",
description: "This table joins orders information from OnlineStore & payment information from PaymentApp",
columns: {
order_date: "The date when a customer placed their order",
id: "Order ID as defined by OnlineStore",
order_status: "The status of an order e.g. sent, delivered",
customer_id: "Unique customer ID",
payment_status: "The status of a payment e.g. pending, paid",
payment_method: "How the customer chose to pay",
item_count: "The number of items the customer ordered",
amount: "The amount the customer paid"
},
assertions: {
uniqueKey: ["id"]
}
}
3. データパイプラインのアーキテクチャ
改めて、今回検証・実装するデータ パイプラインのアーキテクチャは以下の通りです。

全体で三層構造となっており、DWHはブロンズ、データマートはシルバーとゴールドの二層に分かれています。ゴールドである「mart4」は、シルバーの2つ(「mart1」、「mart2」)を前提としており、これらはさらにブロンズの3つ(「sample_master」、「sample_master2」、「sample_tran」)を前提としています。
4. Dataform での実装
Dataform でのディレクトリ構成は以下のようになりました。

まず、ブロンズ層を定義します。ブロンズ層は一番初めに必要となるもので、Dataform においては「データソース」と呼ばれます。「type: "declaration"」で定義します。
config {
type: "declaration",
database: "ca-int-ml1-research",
schema: "sample_dataset",
name: "sample_master",
}
次に、シルバー層を定義します。シルバー層はブロンズ層のテーブルを組み合わせて作るもので、以下のようなクエリになります。ポイントは、前提となるテーブルを「${ref("sample_tran")} 」という記法で参照できている点です。Dataform におけるテーブル間の依存関係管理はこれを書くだけで OK です。
config {
type: "table"
}
SELECT
t.key1,
t.key2,
t.attribute1,
m.attribute2
FROM
${ref("sample_tran")} AS t
INNER JOIN
${ref("sample_master")} AS m
ON
t.key1 = m.key1
LEFT JOIN
${ref("sample_master2")} AS m2
ON
t.key1 = m2.key1
and t.key2 = m2.key2
次に、ゴールド層を定義します。ゴールド層は、シルバー層のテーブルを組み合わせて作るもので、シルバー層を作るときと考え方は同じです。以下のようにシルバー層のテーブル2つ(「mart1」、「mart2」)を UNION ALL して作ります。このときも先程と同じように、「${ref("テーブル名(sqlxファイル名)")} 」といった書き方で前提テーブルを参照しています。
config {
type: "table"
}
SELECT * FROM ${ref("mart1")}
UNION ALL
SELECT * FROM ${ref("mart2")}
5. Dataform での実行と結果
それでは Dataform で作ったアクションを実行します。
以下のように「definitions/mart4.sqlx」を選択し、実行します。
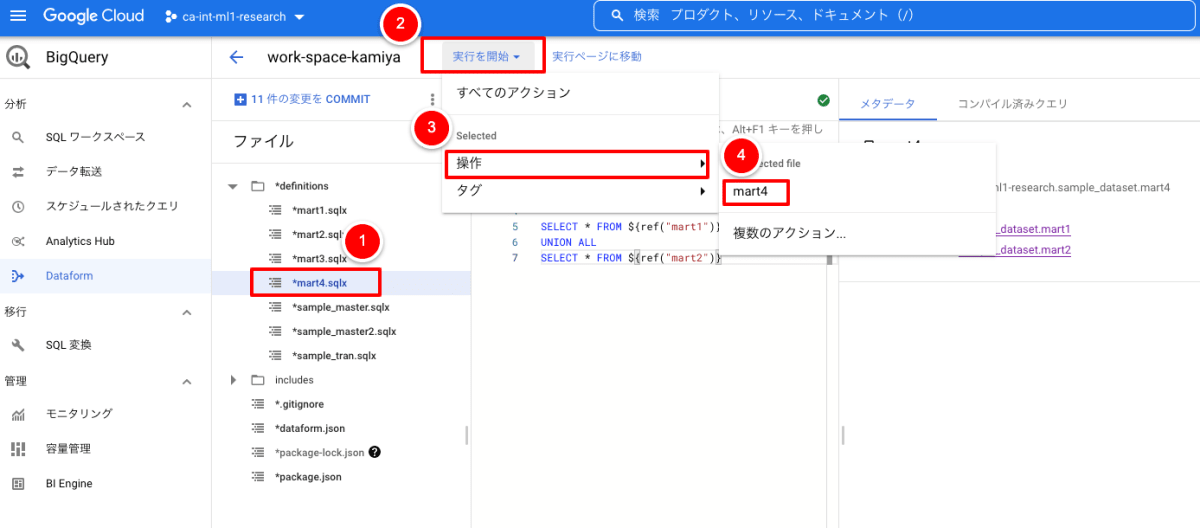
「Execute」画面で「依存関係を含める」にチェックを入れて、「実行を開始」ボタンを押下します。

実行の詳細画面は以下の通りです。

「mart4」の前提となるテーブルを作るアクションが依存関係の順序通りに実行されています。「mart3」作成のアクションは「mart4」の前提とはなっていないため、実行されていません。Dataform を利用することで、通常の SQL を書くのと大差ないレベルでテーブル間の依存関係管理ができるようになりました。
6. まとめ
Dataform を使って BigQuery テーブル間の依存関係管理をサクッと作ることができました。ここにさらに自動テストや CICD を加えたりと、データ品質やそれに必要なデータパイプラインのコード品質を高める取り組みが簡単に行なえます。Dataform の良いところは、BigQuery の拡張という形で BigQuery の良さを活かしつつ、ツールとして程よい機能性を持っている点にあると感じました。また別の記事で「assertions」について検証してみたいと思います。
※ BigQuery enterprise data warehouse、Google Cloud Storage service は Google LLC の商品です。
Discussion