一般提供になった AlloyDB AI で、RDB から LLM を呼び出してみる
TL; DR
- AlloyDB for PostgreSQL にて、AlloyDB AI が GA になりました
- AlloyDB AI を用いることで、以下のようなユースケースにさらによく対応できるようになりました
- RDB に格納されたデータを Vertex AI でホストした機械学習モデルに与え、結果を取得したいとき
- (今回は試していませんが) 生成 AI を活用したアプリのバックエンドとして、エンベディングしてベクトル化されたデータを、高速にクエリしたいとき
はじめに
こんにちは、クラウドエース データソリューション部所属の田中です。
データソリューション部では、Google Cloud が提供しているデータ領域のプロダクトについて、新規リリースをキャッチアップするための調査報告会を毎週実施しています。
新規リリースの中でも、特に重要と考えるリリースを記事としてまとめ、本ページのように公開しています。
クラウドエース データソリューション部 について
クラウドエースの IT エンジニアリングを担う システム開発統括部 の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのが データソリューション部 です。
弊社では、新たに仲間に加わってくださる方を募集しています。もし、ご興味があれば エントリー をお待ちしております!
今回紹介するリリースは、「AlloyDB AI が GA (一般提供) になった」という内容です。該当リリースはこちらからご覧ください。
こちらのリリースにより、AlloyDB for PostgreSQL (以下、AlloyDB と表記) の機械学習関連の機能を、AlloyDB の SLA に基づいて提供することが可能になりました。つまり、本番環境のような、より信頼性が求められるユースケースにも対応できるようになりました。
AlloyDB AI でできること
AlloyDB AI でできることとしては、以下のようなものがあります。
- AlloyDB の中身を Vertex AI でホストしている機械学習モデルに入力として与え、結果を取得する
- AlloyDB 上でエンべディングを行い、ベクトル化した情報を保存する
例えば 1 では、すでに AlloyDB に格納されているテーブルのデータを機械学習モデルに与え、テーブルや列のデータを要約してもらう、などがユースケースになります。こちらの機能については後で実際に試してみます。
2 のユースケースとしては、例えば Langchain を使用したアプリケーションのデータベースとして、AlloyDB を用いるなどがあります。こちらのパフォーマンスは Google Cloud 公式ブログによると、以下のような効果があったとのことです。
Google のパフォーマンス テストでは、AlloyDB は、標準的な PostgreSQL と比較して最大 100 倍の速さで分析クエリを実行でき、AlloyDB AI は、IVFFlat インデックスを使用した場合、標準的な PostgreSQL と比較して最大 10 倍の速さでベクトルクエリを実行できました。
今回はこちらの機能については試せませんが、別の記事でご紹介できたらと思っております。
なお、AlloyDB AI の利用にあたって追加の料金は発生しません。ただし AlloyDB を使用する際の料金や、Vertex AI を利用する場合はそちらの料金は発生します。詳しくは AlloyDB の料金体系および 「Vertex AI の生成 AI」の料金体系をご覧ください。
(補足)AlloyDB for PostgreSQL とは
AlloyDB はフルマネージドかつ PostgreSQL と 100% 互換のリレーショナルデータベースサービスです。それだけなら Cloud SQL for PostgreSQL でも同じですが、AlloyDB の特徴としては、コンピュートレイヤーとストレージレイヤーが分離されていることが挙げられます。これにより、例えばストレージだけをスケールアウトさせるなど、より柔軟な運用が可能になります。
ストレージレイヤー部分には Google の諸サービス(Cloud Spanner など)で使用されている分散ストレージシステムである Colossus が採用されており、高い可用性および耐久性を実現しています。
他にも、クエリのパフォーマンスを向上させるために、インデックスを貼るべき列を提案してくれる index_advisor 機能や、列志向(カラムナ)エンジンによる分析クエリの高速化など、AlloyDB では様々な機能が提供されています。
実際に試してみた
ではここからは、今回 GA になった AlloyDB AI の機能を実際に試してみようと思います。
とはいっても 2 つとも試すとなると 1 つの記事では収まらなくなるので、今回は前述の通り 1 つめの「AlloyDB の中身を Vertex AI でホストしている機械学習モデルに入力として与え、結果を取得する」という機能を試します。
手順
今回は以下の手順で検証を行います。
- (準備)AlloyDB のクラスターを作成する
- (準備)AlloyDB にサンプルデータを投入する
- (検証)Vertex AI でホストされている機械学習モデルに、AlloyDB のデータを入力として与える
- (検証)結果を確認する
準備のセクションが長くなっているので、検証結果だけが気になる方は「Vertex AI でホストされている機械学習モデルに、AlloyDB のデータを入力として与える」までスキップしてください。
なお、この検証をお手元で行う場合は、以下の前提条件を満たす必要があります。
- Google Cloud のプロジェクトがある
- 対象のプロジェクトで、AlloyDB の API が有効になっている
- 操作するユーザーが以下のロールを全て持っている
-
roles/alloydb.admin(the AlloyDB Admin predefined IAM role) -
roles/owner(the Owner basic IAM role) -
roles/editor(the Editor basic IAM role) -
roles/storage.admin(Storage Admin) -
roles/compute.instanceAdmin.v1(Compute Instance Admin (v1))
-
AlloyDB クラスターの作成
まずは AlloyDB クラスターを作成します。
AlloyDB クラスターを作成するにあたって必要な設定項目は、大きく次の 3 つです。
- AlloyDB クラスターのタイプ
- クラスターの構成
- プライマリーインスタンスの構成
では、作成してみましょう。
まず Google Cloud コンソールから、AlloyDB のページに移動します。その後、「CREATE CLUSTER」ボタンをクリックします。
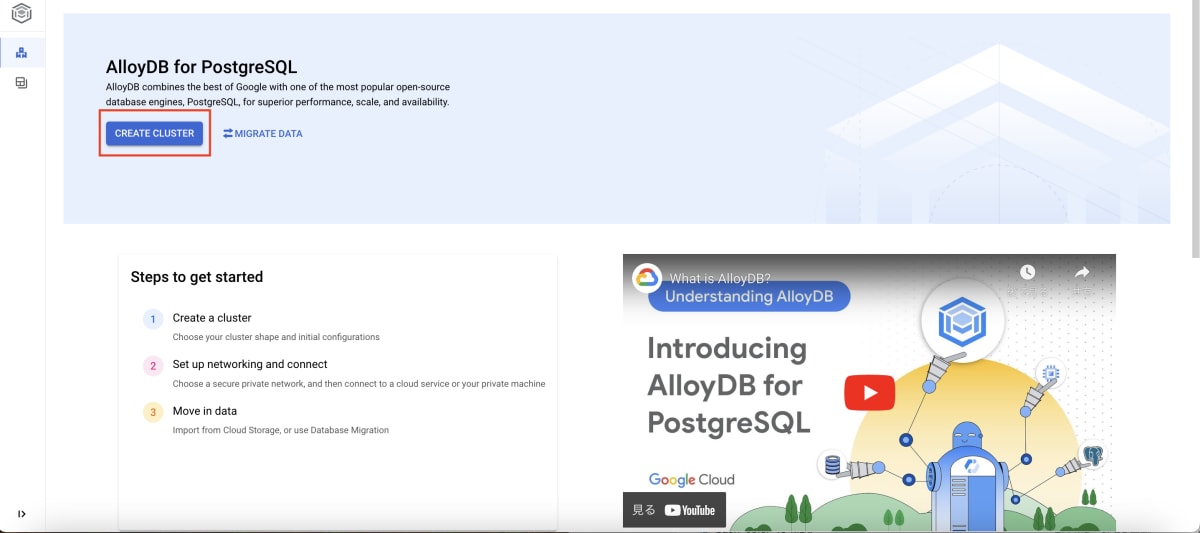
もしまだ AlloyDB API を有効にしていない場合、API の有効化を求められます。この場合は 「ENABLE API」 ボタンを押して、API を有効化します。

次の画面で、AlloyDB クラスターのタイプ、クラスターの構成、プライマリーインスタンスの構成のそれぞれを設定していきます。
弊社のコラムも参考にしつつ進めます。
AlloyDB クラスターのタイプとして、4 項目の中から 1 つを選択します。
- 高可用性(Highly available)
- 読み取りプール付き高可用性(Highly available with read pool(s))
- ベーシック(Basic)
- 読み取りプール付きベーシック(Basic with read pool(s))
AlloyDB クラスターのタイプとは
AlloyDB クラスターは、コンピューティングリソースとストレージリソースの組み合わせによって構成されています。
上記の AlloyDB クラスターのタイプは、コンピューティングリソースをどのように構成するのかに関わります。大きく分けて、高可用性 / ベーシック、読み取りプールの有無の 2 軸で選択できます。
高可用性を選択した場合、Google Cloud リージョン内部の複数ゾーンにプライマリーインスタンスが作成されます。プライマリーインスタンスはデータの読み込みだけでなく、書き込みも行うインスタンスになります。このプライマリーインスタンスが分散されていることで、障害が発生した場合でも別のゾーンにスムースなフェイルオーバーが行われます。一方でベーシックの場合は、単一のゾーンにプライマリーインスタンスが作成されます。
読み取りプールは、いわゆるリードレプリカを想像してください。リードレプリカの集合を読み取りプールと呼びます。AlloyDB の場合は、プライマリーインスタンスとリードレプリカの間のレプリケーションが高速化されるよう改善されています。参考
今回は検証ということもあるので、とりあえず手軽そうなベーシックを選択します。

次にクラスターの構成を設定します。こちらは以下の項目を設定します。
- 基本情報(Basic Info)
- クラスターの ID
-
postgresユーザーのパスワード - データベースのバージョン(2024/04/03 時点では PostgreSQL 14 および PostgreSQL 15 が選択可能です)
- 使用する Google Cloud リージョン(Location)
- 利用するサブネット(Networking)

上記のうち注意が必要なのは、利用する VPC ネットワークの選択です。
今回は検証が目的であり、手順の簡素化のためプロジェクト作成時に自動作成される default の VPC ネットワークを選択しました。本番目的で利用する際は専用の VPC ネットワークを作成した上で、そこにクラスタを作成することをおすすめします。また、当該の VPC ネットワークでは、他のサービスから AlloyDB クラスターが持つ内部 IP アドレスに排他的にアクセスできるよう、Private Service Access の有効化が必須です。まだ行っていない場合は、「SET UP CONNECTION」ボタンを押して、設定を行う必要があります。

「SET UP CONNECTION」ボタンを押すと、使用する IP 範囲を選択する画面になります。既存の IP 範囲を指定したり、手動で範囲を指定できます。また、Google によって自動的に割り振ってもらうことも可能です。今回はとりあえず自動で割り振ってもらうことにしました。

ちなみに Private Service Access では、VPC ピアリングが用いられています。詳しくは弊社の亀梨が先日公開した記事をご覧ください。
最後のプライマリーインスタンスの構成では、以下の 2 点を設定します。
- プライマリーインスタンスの ID
- インスタンスのマシンスペック

以上のような設定を行った後、「CREATE CLUSTER」ボタンを押すと、AlloyDB クラスターの作成が開始されます。
AlloyDB へのサンプルデータ投入
AlloyDB クラスターが作成できたら、次はサンプルデータを用意し、それを AlloyDB に投入します。
今回は手軽さを重視して、サンプルデータには BigQuery 公開データセットである bigquery-public-data.imdb のデータを利用しました。このデータには、ドラマや映画のタイトルとレビュー情報が格納されています。これを CSV ファイルとして出力し、AlloyDB に手動でインポートすることにします。
BigQuery のデータを CSV ファイルとして出力する方法は公式ドキュメントをご参照ください。
CSV ファイルのアップロードや psql クライアントの用意方法やファイルのインポート方法については、公式ドキュメント(英語版しかありませんが……)を参考にしつつ進めます。詳しくはそちらをご覧ください。
上記公式ドキュメントで案内されている手順に従い、手動のインポートでは以下の 3 つの手順を行います
- CSV ファイルのアップロード
- psql クライアントのインストール(必要であれば)
- AlloyDB データベースの作成
まず、Cloud Storage に CSV ファイルをアップロードします。次に Compute Engine の VM インスタンスを用意します。
今回用意した VM のスペックはこちらです。
- OS: Debian 12
- マシンタイプ: n1-standard-1 (1 vCPU, 3.75 GB RAM)
- ディスクサイズ: 10 GB
次に、Cloud Storage にある CSV ファイルを VM にコピーします。SSH 接続した VM 上で、下記のコマンドを実行することで可能です(以降は VM 上での作業となります)。BUCKET_NAME や CSV_FILE_NAME は適宜読み替えてください。
gsutil cp gs://BUCKET_NAME/CSV_FILE_NAME .
用意した VM に psql クライアントをインストールします。
sudo apt-get update
sudo apt-get install postgresql-client
psql クライアントがインストールされたら、作成した AlloyDB クラスターの内部 IP アドレスを使い、psql クライアントから接続します。
内部 IP アドレスは AlloyDB のコンソールから確認できます(添付画像赤枠「Private IP」)。
psql -h {IP_ADDRESS} -U postgres

次はデータベースの作成です。psql クライアントで接続した後、以下のコマンドを実行し、imdb_trial というデータベースを作成します。
CREATE DATABASE imdb_trial;
先ほど作成したデータベースに接続します。
\c imdb_trial
作成されたデータベースにテーブルを作成します。今回は以下のような CREATE TABLE 句を実行し、review というテーブルを作成しました。
CREATE TABLE review(
movie_id VARCHAR(255),
title VARCHAR(255),
review TEXT
);
次に、 \copy コマンドで CSV ファイルのデータを review テーブルにインポートします。CSV_FILE_NAME は適宜読み替えてください。
\copy review(movie_id, title, review)
FROM 'CSV_FILE_NAME'
DELIMITER ','
CSV HEADER
;
これでデータのインポートが完了しました。
Vertex AI でホストされている機械学習モデルに、AlloyDB のデータを入力として与える
では、検証に移ります。
ここも公式ドキュメントを参考にしつつ進めていきます。詳細は記載しないので、適宜こちらのドキュメントを確認してください。
まず AlloyDB のサービスエージェントに、Vertex AI User のロールを付与します。
次に、格納したデータを Vertex AI でホストされている機械学習モデルに与えるため、google_ml_integration 拡張機能を PostgreSQL にインストールします。psql クライアントで以下の CREATE 句を実行します。
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
さらに下記を実行し、インストールした拡張機能のうち、ml_predict_row をユーザーが使えるようにします。{USER} は適宜読み替えてください。
GRANT EXECUTE ON FUNCTION ml_predict_row TO {USER};
それでは、格納したデータを Vertex AI でホストされている機械学習モデルに与えてみましょう。
ここでは 2 つの選択肢から、データを与える機械学習モデルを選択できます。
-
Vertex AI Model Garden でホストされているモデル
- 表形式の入力を受け付けるモデルか、カスタムモデルである必要があります
- アクティブな Vertex AI エンドポイントがあり、かつユーザーがアクセス権限を持っている Vertex AI モデル
- ただし、プライベートエンドポイントは AlloyDB ではサポートされていません。
今回は上記の選択肢から、Vertex AI Model Garden でホストされている大規模言語モデル (以下 LLM) の Gemini Pro を……使ってみようと思ったのですが、どうやらまだ対応していないようです。呼び出してみたら下記のようなエラーが返ってきました。
ERROR: Invalid arguments: RestError[400]: {
"error": {
"code": 400,
"message": "Gemini cannot be accessed through Vertex Predict/RawPredict API. Please follow https://cloud.google.com/vertex-ai/docs/generative-ai/start/quickstarts/quickstart-multimodal for Gemini usage.",
"status": "FAILED_PRECONDITION"
}
}
別の LLM である text-bison モデルなら呼び出せたので、それを使ってみます。今回は imdb のデータセットの中にあった「機動戦士ガンダム 第 08 MS 小隊(以下 08 小隊)」のレビューを使います。review テーブルから title 列と「 08 小隊」のレビューの要約をしてもらいます。
それには下記の SQL クエリを実行します。この中の ML_PREDICT_ROW 関数を使って、LLM を呼び出します。
select
title,
ML_PREDICT_ROW('projects/PROJECT_ID/locations/LOCATIONS/publishers/google/models/text-bison', json_build_object('instances', json_build_object('prompt', 'Summarize this review for Mobile Suit Gundam: The 08th MS Team. The summary should be concise : ' || review), 'parameters', json_build_object('maxOutputTokens', 1024,'topK', 40,'topP', 0.95,'temperature', 0.1))) as summary
from review
where title = 'Mobile Suit Gundam: The 08th MS Team';
ML_PREDICT_ROW 関数の第 1 引数には、モデルのパスを指定します。PROJECT_ID や LOCATIONS は適宜読み替えてください。
第 2 引数には、モデルに与えるパラメータを指定します。まず、prompt の部分で、次の文章を簡潔に要約することを指示する文章と review の内容を組み合わせて LLM にプロンプトとして渡しています。それらを JSON 形式にするために、json_build_object 関数を使っています。また、parameters の部分で、他のパラメーターも指定しています。それぞれ以下のような意味があります。
-
maxOutputTokens: レスポンスで生成できるトークンの最大数。これが大きくなると、レスポンスも長くなります -
topK: レスポンスの候補になるトークンを選ぶ際に、確率トップいくつのまでをトークンを選択の候補に入れるかを指定します。この数字が大きくなれば、LLM が返すレスポンスのランダム性が高くなります -
topP: topK と組み合わせて使います。トークンを選択する際に、モデルは topP の値と等しくなるまで、topK のランキング上位のトークンから選択の候補に入れます。 -
temperature: topK, topP と組み合わせて使います。選択の候補となったトークンからどの候補を選ぶのか、そのランダム性をコントロールします。topK, topP, temperature のそれぞれが大きくなると、生成されるレスポンスのランダム性が高くなります
topK, topP のもう少し細かい説明
今回の例だと topK が 40 なので、40 個の候補トークンが LLM によって用意されます。それぞれの候補トークンには、確率が指定されています。その確率をどうやって出しているんだとかは LLM がよしなにやっています。
それらの候補の中からさらに選抜するために、topP があります。候補トークンの確率はランクづけできるので、それを利用します。確率ランキング上位から確率を足し算していき、topP の値になったらそこで選抜を終了します。
topK, topP の過程で選抜された最終候補のトークンからどの結果が出力になるのかというところで、temperature が関わってきます。最終候補の中からどれを選ぶのかをコントロールするのが temperature です。これが低いほど、より確率の高い選択肢を選ぶようになります。参考
今回 LLM に与えた、review列の内容
This Gundam series only follows Gundam 0083 Stardust Memory. The story takes place during the same time line as the original Gundam in the year U.C. 0079 the time of the One year war, but the mobile suits are designed as new models are and are as a result look more articulate. The Hero of the story is a young Lt. Shiro Amada, who may lack any real combat experience but makes up for it with creativity and effort.His life get complicated when he meets Aina Sahalin a Jion ace pilot (the enemy), the to end up falling in love and begin to change their attitudes about the war around them. The other cast of characters in the story are not there for background either, every one in this story has a history to them.There is also another Ace mobile suit pilot in this series that can be added into the pantheon of ace mobile suit pilots. Right up there with Char Aznable and Anavel Gato is Norris Packard, not the top villain in this series, but his presence give the 8th mobile suit team a hard fight. 3 of them against Norris and his single MS-07B Gouf custom mobile suit.In conclusion This Gundam along with Stardust Memory is a must see!!
結果を確認する
LLM からの結果は JSON 形式で返ってきます。
詳しくは公式ドキュメントを読んでいただきたいですが、レスポンスの中の content フィールドが、LLM の生成した結果を格納しています。
中を見てみましょう。
{"content": " Mobile Suit Gundam: The 08th MS Team is a Gundam series set during the One Year War in U.C. 0079. It follows Lt. Shiro Amada, an inexperienced but creative pilot, and his team as they fight against the enemy forces. The series introduces new mobile suit designs and explores the personal struggles and relationships of the characters, including Aina Sahalin, a Jion ace pilot who falls in love with Shiro. The series also features Norris Packard, a formidable ace pilot who challenges the 8th mobile suit team. Overall, this Gundam series, along with Stardust Memory, is highly recommended for fans of the franchise."}
クエリの結果全文
Mobile Suit Gundam: The 08th MS Team | {"predictions": [{"content": " Mobile Suit Gundam: The 08th MS Team is a Gundam series set during the One Year War in U.C. 0079. It follows Lt. Shiro Amada, an inexperienced but creative pilot, and his team as they fight against the enemy forces. The series introduces new mobile suit designs and explores the personal struggles and relationships of the characters, including Aina Sahalin, a Jion ace pilot who falls in love with Shiro. The series also features Norris Packard, a formidable ace pilot who challenges the 8th mobile suit team. Overall, this Gundam series, along with Stardust Memory, is highly recommended for fans of the franchise.", "citationMetadata": {"citations": []}, "safetyAttributes": {"safetyRatings": [{"category": "Dangerous Content", "probabilityScore": 0.1, "severityScore": 0, "severity": "NEGLIGIBLE"}, {"category": "Harassment", "severityScore": 0, "severity": "NEGLIGIBLE", "probabilityScore": 0.1}, {"probabilityScore": 0.1, "category": "Hate Speech", "severityScore": 0.1, "severity": "NEGLIGIBLE"}, {"severityScore": 0, "category": "Sexually Explicit", "severity": "NEGLIGIBLE", "probabilityScore": 0.2}], "categories": ["Derogatory", "Insult", "Sexual"], "scores": [0.1, 0.1, 0.2], "
blocked": false}}], "metadata": {"tokenMetadata": {"outputTokenCount": {"totalBillableCharacters": 514, "totalTokens": 134}, "inputTokenCount": {"totalTokens": 280, "totalBillableC
haracters": 1009}}}}
たしかに要約された文章が返ってきています。これで、「 AlloyDB の中身を Vertex AI でホストしている機械学習モデルに入力として与え、結果を取得する」検証は終了です。
個人的には、もう少しいろいろなモデルで使えるとさらに良いですが、今の時点でもなかなか便利な機能だと思いました。AlloyDB では JSON 型や JSONB 型に対応しているので、LLM からのレスポンスをまるごと保持する列をテーブルに持たせておき、アプリからはその列の content フィールドを取り出す、などが実際の運用になるでしょうか。ユースケースを考えるのも楽しそうです。
まとめ
今回の記事の内容をまとめます。
- AlloyDB for PostgreSQL にて、AlloyDB AI が GA になりました
- AlloyDB AI を用いることで、以下のようなユースケースにさらによく対応できるようになりました
- RDB に格納されたデータを Vertex AI でホストした機械学習モデルに与え、結果を取得したいとき
- (今回は試していませんが) 生成 AI を活用したアプリのバックエンドとして、エンベディングしてベクトル化されたデータを、高速にクエリしたいとき
最後までお読みいただきありがとうございました。
Discussion