Cloud Spanner のバッチ指向スキャンを試してみた
はじめに
こんにちは!クラウドエース データ ML ディビジョン所属のマルフォイです。
データ ML ディビジョンでは、Google Cloud が提供しているデータ領域のプロダクトについて、新規リリースをキャッチアップするための調査報告会を毎週実施しています。
新規リリースの中でも、特に重要と考えるリリースを記事としてまとめ、本ページのように公開しています。
今回ご紹介するリリースは、「Cloud Spanner バッチ指向のスキャン」についてです。
このリリースによって、今まではサポートされていなかったバッチ指向のスキャン機能が追加され、スキャンのスループットとパフォーマンス向上が期待できます。
Cloud Spanner とは?
Cloud Spanner とは、フルマネージドのリレーショナルデータベースサービスです。 最大 99.999 % の可用性、柔軟なスケーリング、強力な整合性・一貫性を持ち、大規模データのトランザクション処理を高速で実現できます。
Cloud Spanner では、取得するデータを指定する SQL 文を使用して、データベースに対してクエリを実行できます。
クエリを実行する主な方法は以下の通りです。
- Google Cloud コンソールから、ユーザーが直接実行する
- クライアントライブラリを使用したアプリケーションから実行する
- gcloud コマンドライン ツールを使用して実行する
リリース内容
今回ご紹介するリリースは、 2023 年 11 月 10 日に発表された Cloud Spanner がバッチ指向のスキャンをサポートしたことについてです。
このリリースにより、任意の検索クエリ実行時にバッチ指向のスキャンを選択できるようになりました。
先に、本記事で登場する重要な用語について簡単に解説します。
- スキャン:データベースの中から情報を探し出す際に、データベース全体を一つずつチェックして探す方法です。
- シーク:データベースの中から情報を探し出す際に、特定の情報を直接探しに行く方法です。
- バッチ指向のスキャン:データベースから複数の行をまとめて取り出して処理する方法のことです。この方法は、一度に大量のデータを効率良く処理できる点がメリットです。
スキャン方法の種類
Cloud Spanner のスキャン方法は、これまで行指向のスキャンのみでした。今回のリリースでバッチ指向のスキャンが追加されたことにより、現在はクエリ実行時のスキャン指定方法が 3 種類あります。
-
行指向のスキャン:データベースから一行ずつデータを処理する方法です。Google Cloud コンソール上では [ Scalar ] と表示されます。

Scalar -
バッチ指向のスキャン:データベースから複数の行をまとめて取り出して処理する方法のことです。Google Cloud コンソール上では [ Vectorized ] と表示されます。

Vectorized -
自動:このスキャン方法では、最初は常に行指向のスキャン方法で実行を開始します。Cloud Spanner がランタイムメトリクス(プログラムが実行されている間に収集されるデータ)を収集し、バッチ指向のスキャンが最適と判断した場合に、自動でバッチ指向のスキャン方法に切り替えます。直接指定しない限り、この方法がデフォルトです。公式ドキュメントでは、このデフォルトの方法を推奨しています。 Google Cloud コンソール上では [ Automatic ] と表示されます。

Automatic
上記のスキャン方法を使い分けることによって、スキャンのスループットとパフォーマンスを最適化することができます。
バッチ指向のスキャンのユースケース
バッチ指向のスキャンでクエリのパフォーマンス向上が期待できるユースケースは、以下の通りです。
- 更新頻度の低いデータに対する大規模なスキャン
- 固定幅の列での述語によるスキャン(例 : WHERE ‘age’ > 60)
- 固定幅の列 : INT(64) のように、格納できる領域が固定されている列のことです。
- 述語 : WHERE 句や IN 句のように、データを選択または除外するための条件です。
- シーク数が多いスキャン
一方で、以下のようなケースでは、バッチ指向のスキャンでのパフォーマンス向上は期待できません。
- 1 行のみを取得するような、ポイント検索クエリ
- シーク数が多くない場合に数行のみをスキャンするテーブルスキャン
- LIMIT 句を使用するクエリ
- クエリの読み取り対象データの 10% 以上が頻繁に更新されるケース
- 大きな値(1 つの列に圧縮前で 32,000 バイトを超える値)を含む行でのクエリ
料金
今回のリリースでは、Cloud Spanner の料金に影響がありません。つまり、スキャン方法を指定することや、スキャン方法が自動で切り替わることは課金対象になりません。
Cloud Spanner で課金対象となる項目は、以下の通りです。詳細はリンクをご覧ください。
- インスタンスのコンピューティング容量
- データベースで使用しているストレージ量
- バックアップで使用しているストレージ量
- 使用したネットワーク帯域幅の量
試してみた
早速バッチ指向のスキャン方法を試してみましょう!
検証目的
同じデータに対してバッチ指向のスキャンと行指向のスキャンをそれぞれ実行し、パフォーマンスにどのような違いが出るか検証することを目的とします。
今回はバッチ指向のスキャンのユースケースである、シーク数が大きいスキャンを実行してみます。
検証用のデータには、BigQuery のパブリックデータの baseball データセットにある、games_wide テーブルにあるデータを使用します。
このデータには、2016 年のメジャーリーグ野球戦績が格納されています。
データ量やカラム数が大規模であることから、このパプリックデータを選定しました。
検証用データの準備
前準備では、 BigQuery にある検証用データを、 Dataflow を用いて Cloud Spanner にロードします。
実際に行った手順は以下の通りですが、Dataflow での具体的なデータのロード方法については記事の本質から逸れるため、詳細は割愛します。
詳細は公式ドキュメントをご覧ください。
-
Dataflow に関連するファイルや、検証用データ CSV を格納するための Cloud Storage バケットを作成する
-
検証用データ CSV を作成する
BigQuery とは異なり、Cloud Spanner では、テーブルを作成する際に主キーを設定する必要があります。
本検証で使用したgames_wideテーブルの中に、主キーとして設定できるカラムがなかったため、以下の操作を行いました。
- BigQuery にて、
games_wideテーブルのデータに uuid を付与するクエリを実行する
SELECT GENERATE_UUID() AS uuid, *
FROM `bigquery-public-data.baseball.games_wide`
- 結果を別の BigQuery テーブルに保存する
- 保存した BigQuery テーブルのデータを、手順 1 で作成した Cloud Storage のバケットに CSV 形式でエクスポートする
-
検証用データ CSV をロードするための Cloud Spanner テーブルを作成する
-
Dataflow を使用して、Cloud Spanner のテーブルにロードする
このとき、 Dataflow で用意されているCloud Storage Text to Cloud Spannerテンプレートを使用します。また、manifest.json というファイルを作成し、手順 1 で作成したバケットに格納します。manifest.json は、 Dataflow から Cloud Spanner へデータを書き込む際の設定値を指定するファイルです。
クエリの実行
それでは実際にクエリを実行してみましょう。
スキャンを方法を指定するには、 @{SCAN_METHOD=BATCH} のように、クエリの中にステートメントヒントを含めます。
以下のクエリを行指向のスキャンとバッチ指向のスキャンでそれぞれ 3 回実行しました。
シーク数を増やすために、UUID の最初の値が 3 より小さい、もしくは最初の値が 8 より大きい行を全て返すスキャンを行いました。
- バッチ指向のスキャン
@{SCAN_METHOD=BATCH}
SELECT * FROM `games_wide`
@{FORCE_INDEX=index_uuid}
WHERE uuid > '8'
OR uuid < '3'
- 行指向のスキャン
@{SCAN_METHOD=ROW}
SELECT * FROM `games_wide`
@{FORCE_INDEX=index_uuid}
WHERE uuid > '8'
OR uuid < '3'
以下の画像は、実際にクエリを実行したときの Google Cloud コンソール画面です。

バッチ指向のスキャン

行指向のスキャン
結果の確認
Query Insights とクエリ実行プランビジュアライザを表示して、結果を比較します。
Query Insights とは、Cloud Spanner の機能の一つで、データベースのパフォーマンスを監視・分析するためのツールです。
下の画像のように、クエリまたはリクエストタグ(クエリにタグをつけることで、パフォーマンスを追跡しやすくする機能)ごとのパフォーマンスを確認できます。
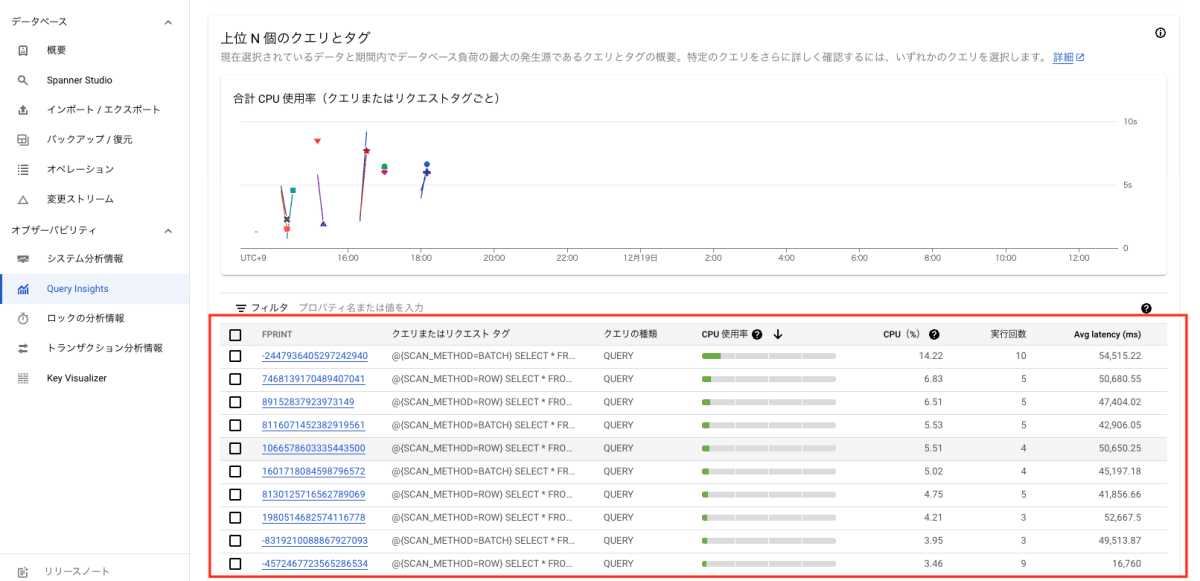
Query Insights の画面例
本検証で実行したクエリのパフォーマンスを見てみましょう。
下の画像は、本検証時の Query Insights 画面から、上の画像の赤枠部を抜き出したものです。
上段が行指向のスキャン、下段がバッチ指向のスキャンに関するデータです。

本検証での Query Insights 画面
| CPU(%) | Avg latency(ms) | |
|---|---|---|
| 行指向 | 35.42 | 25,640.61 |
| バッチ指向 | 30.96 | 21,176 |
各項目について、簡単に解説します。
- CPU : 一定間隔中に実行されていた全てのクエリでの CPU リソースの使用量を 100% としたときに、そのクエリが何 % を占めているかを表したもの
- Avg latency : そのクエリを実行したときの平均レイテンシ(本検証では 3 回 クエリを実行したので、3 回の平均レイテンシを表しています。)
CPU 使用率は 4.46% 、 Avg latency は 4,464.61 ミリ秒の差がありました。
一見顕著な差ではありませんが、バッチ指向のスキャンの方が CPU 使用率や Avg latency を低くすることができました。
Cloud Spanner が、低いレイテンシを必要とする金融業界やゲーミング業界などで使用されていることを踏まえると、有効な差であると考えます。
続いて、クエリ実行プランビジュアライザでさらに詳細なパフォーマンスを比較します。
クエリ実行プランビジュアライザとは、クエリの実行プランを視覚的に表示し、どのようにクエリが実行されるのかを確認できる画面のことです。
クエリを実行した後に [説明] ボタンを押すことで確認できます。
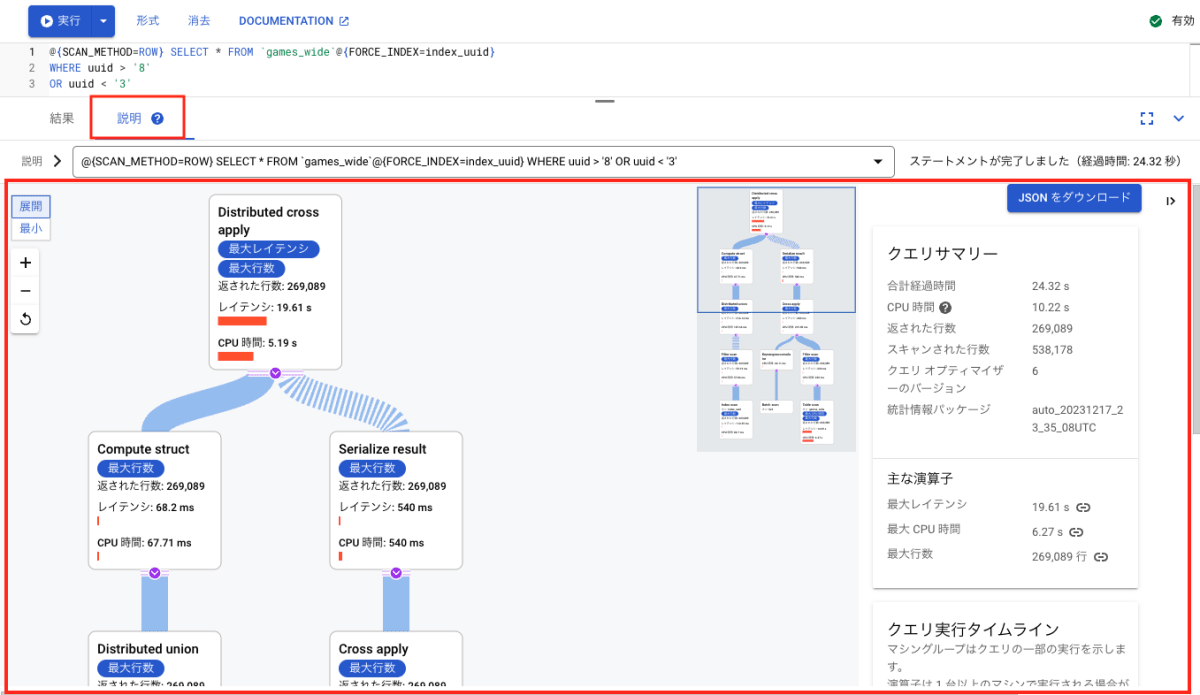
クエリ実行プランビジュアライザの画面例
画像右側のクエリサマリーでは、クエリを実行した際に要した CPU 時間や、各ステージの中での最大レイテンシ、最大 CPU 時間などが表示されています。
また、画像左側のように、クエリを実行した際の各ステージごとに CPU 時間やレイテンシを確認することもできます。
ここでは、 3 回目に実行したクエリの結果を比較します。
下の画像は、バッチ指向のスキャンと行指向のスキャンそれぞれのクエリサマリーです。
左がバッチ指向、右が行指向のスキャン結果です。

クエリサマリーの比較
| CPU 時間(s) | 最大レイテンシ(s) | 最大 CPU 時間(s) | |
|---|---|---|---|
| 行指向 | 10.22 | 19.61 | 6.27 |
| バッチ指向 | 9.77 | 18.3 | 5.91 |
各項目について、簡単に解説します。
- CPU 時間 : クエリを実行するために要した CPU 時間の合計(サーバーのレイテンシは含まない)
- 最大レイテンシ : 各ステージの中で最大を記録したレイテンシ
- 最大 CPU 時間 : 各ステージの中で最大を記録した CPU 時間
こちらも一見顕著な差ではありませんが、全ての項目においてバッチ指向のスキャンの方が良いパフォーマンスであることを確認できました。
まとめ
本記事では、Cloud Spanner の新機能「バッチ指向のスキャン」について紹介しました。
本記事には全ての結果を記載していませんが、検証で様々なクエリを実行した中で、特にバッチ指向の恩恵を感じられたケースは以下の 2 点でした。
- クエリの実行に時間がかかるような、大規模なスキャン
- LIMIT 句を使わないような、返す行が大量になるスキャン
実際に使用する際は、デフォルトのスキャン方法のままクエリを実行すれば、今回検証したような内容を Cloud Spanner 側で行い、スキャン方法を自動で切り替えてくれます!
この自動でスキャン方法を選択してくれる機能があることによって、実行するクエリやスキーマ設計を工夫すれば、さらにスキャンの最適化が期待できそうです。
最後まで読んでいただきありがとうございました。
Discussion