Datastream を使って Cloud Storage と BigQuery に CDCデータを格納してみた
はじめに
こんにちは。クラウドエース第三開発部の工藤です。
今回は Datastream を使って Cloud SQL for PostgreSQL の Change data capture(以下、CDC)データを Cloud Storage と BigQuery に格納する方法を紹介します。
CDC とは
ソースとなるデータベースに加えられた変更をリアルタイムで記録し、追跡する手法です。
DB で発生した変更情報(INSERT、UPDATE、DELETE など)を追跡できます。
データベース複製や ETL 処理とは異なり、CDC は変更が発生したデータのみを抽出するため、データ処理の負荷を軽減し、データ ウェアハウスやリアルタイム分析システムへのデータ配信の遅延を最小限に抑えることができ、データ統合や分析、レプリケーションといった領域で重要な仕組みです。
Datastream
Datastream とは
Datastream は Google Cloud が提供する CDC およびレプリケーション サービスです。
Datastream を使用することで、データベースのデータを Cloud Storage または BigQuery にほぼリアルタイムで転送することができます。
転送元となる RDBMS は以下をサポートしています。
- Oracle
- MySQL
- PostgreSQL
- AlloyDB for PostgreSQL
- SQL Server
また、サーバレスのため、データ量などに応じて自動でスケールアップ/スケールダウンが可能です。
構成要素
Datastream は主に以下 3 つの要素で構成されています。(参照)
| 要素 | 概要 |
|---|---|
| プライベート接続 | プライベート ネットワークを介してソースとなるデータベースと接続が可能となり、 VPC とのピアリング接続を使用して通信が行われる |
| 接続プロファイル | ソースとなるデータベースと宛先(Cloud Storage か Big Query)の接続情報 |
| ストリーム | 接続プロファイルの情報を使用し、データを転送する |
プライベート接続に関しては後述するように接続方法で IP 許可リストを選択する場合、構成しなくても Datastream を使用することができます。
その他の 2 つは必須で構成する必要があります。
Cloud Storage に CDC データを格納する
ソースデータベース設定
今回はソースとなるデータベースに Cloud SQL for PostgreSQL を使用し、例としてproduct_dataというproduct_id、product_name、created_atの 3 つのカラムを持つテーブルを用意しています。
また、Cloud SQL for PostgreSQL を使用する場合、以下の設定を行う必要があります。
- 論理レプリケーションを有効にする
- パブリケーション、レプリケーション スロットを作成する
以下の公式ドキュメントを参考に設定をしておきましょう。
構成
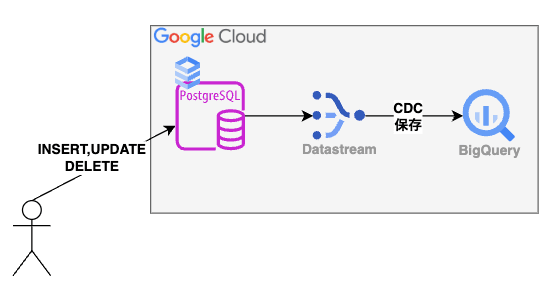
構成は非常にシンプルです。
Cloud SQL for PostgreSQL に対して、変更(INSERT、UPDATE、DELETE)があると Datastream がそのデータを Cloud Storage に転送し、保存します。
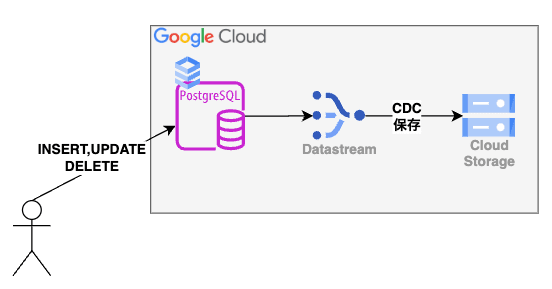
Datastream 構築
では、Datastream の構築を行います。
Datastream は大きく以下の手順で構築します。
- ソース接続プロファイル作成
- 宛先接続プロファイル作成
- ストリーム作成
ソース接続プロファイル作成
Datastream のページにて画面左の[接続プロファイル]を選択し、上部の[プロファイルの作成]をクリックします。

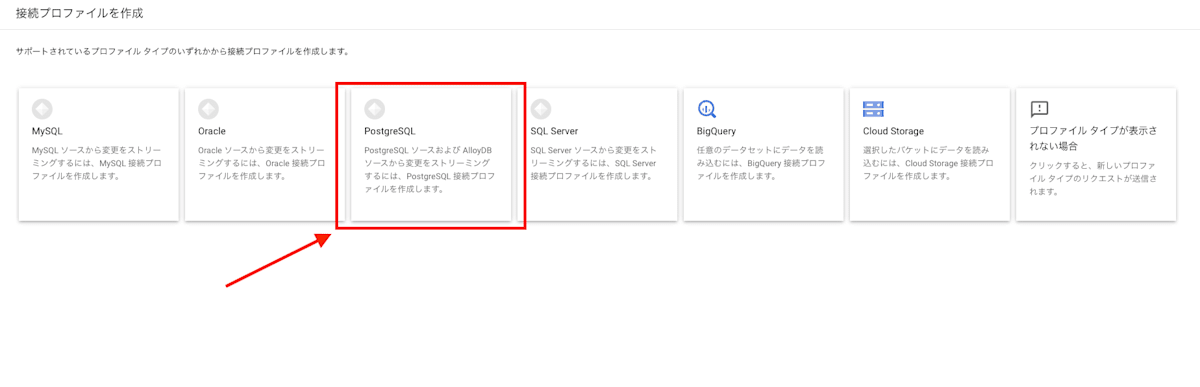
[接続プロファイルの作成]ページでプロファイル タイプを選択します。
上記の通り、今回は[PostgreSQL]プロファイル タイプをクリックします
[接続設定の定義]セクションで以下の情報を定義します。
- 接続プロファイルの名前:ソース接続プロファイルの表示名
- 接続プロファイル ID:接続プロファイル名に基づいて Datastream が自動的に入力
- リージョン:接続プロファイルが保存されるリージョンを選択
-
ホスト名または IP:Datastream がソース データベースへの接続に使用できるホスト名または IP アドレスを入力
- 今回は接続方法に IP 許可リスト(後述)を使用するためデータベースのパブリック IP を入力
-
ポート:ソース データベース用に予約されているポート番号を入力
- 通常 PostgreSQL のデフォルトポートは 5432
- ユーザー名/パスワード:ソース データベースへの認証用に入力
- データベース:データベース インスタンスを識別する名前を入力
また、今回は設定しませんが、必要に応じてラベルの設定も行うことができます。
情報の入力が完了したらページ下部の[続行]をクリックします。

[接続方法の定義]セクションでプルダウン メニューから使用する接続方法を選択します。
今回は構成が簡単な[IP 許可リスト]を選択します。
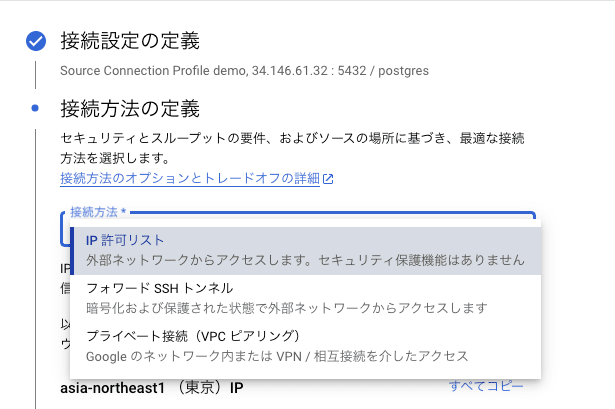
IP 許可リストは Datastream のパブリック IP からの接続を許可するようにソース データベースを構成することで機能する手法です。
詳細やその他の接続方法については以下の公式ドキュメントをご参照ください。
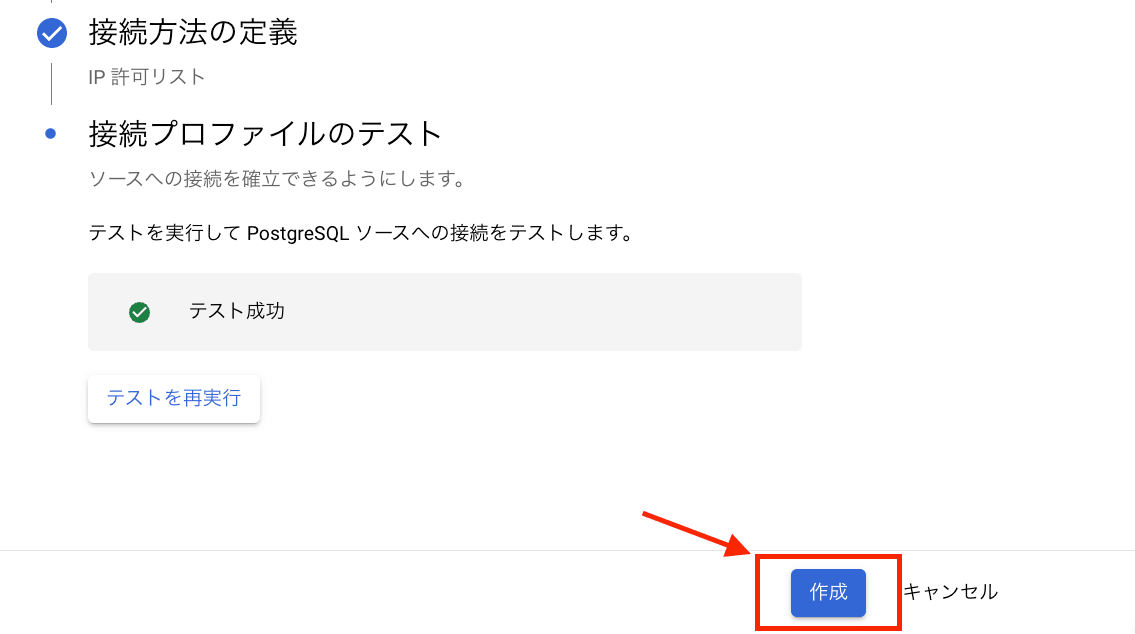
[接続プロファイルのテスト]セクションでソース データベースへの接続をテストします。
テストが問題なく成功すれば、[作成]をクリックします。
宛先接続プロファイル作成
宛先接続プロファイルもソース接続プロファイルの時と同様に[プロファイルの作成]からプロファイル タイプを選択します。
宛先となる [Cloud Storage]プロファイル タイプ をクリックします。
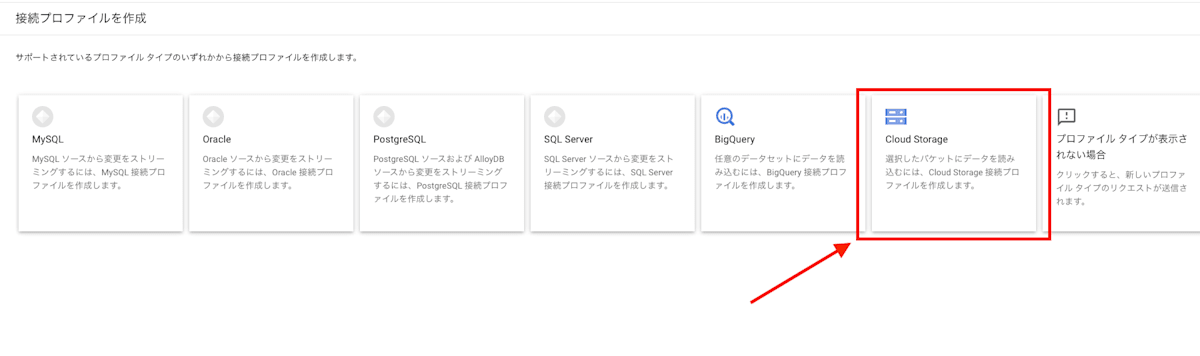
[Cloud Storage プロファイルの作成]ページでプロファイル名/プロファイル ID とリージョンを定義し、[参照]からデータを格納するバケットを選択します。
事前に作成したものを選択するか、作成していない場合はこの場で作成することも可能です。
必要に応じてラベルを定義し、ページ下部の[作成]をクリックすれば設定完了です。

ストリーム作成
各接続プロファイルを作成したらストリームの作成を行います。
Datastream のページにて画面左の[ストリーム]を選択し、上部の[ストリームの作成]をクリックします。
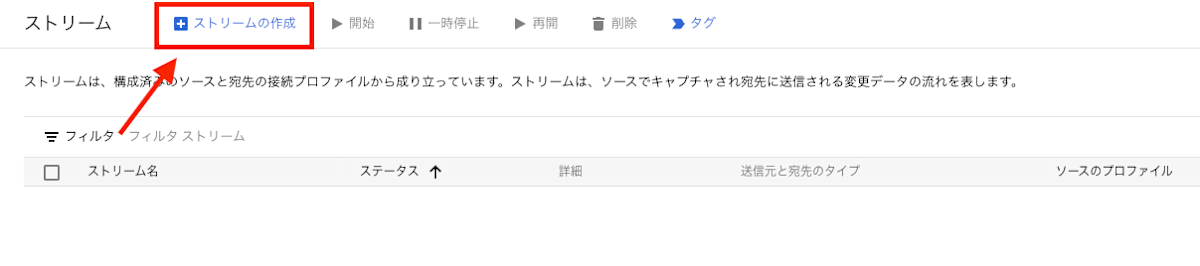
[始める]ページにて以下のストリームの基本設定を定義します。
- ストリームの名前:ストリームの表示名
- ストリーム ID:ストリーム名に基づいて Datastream が自動的に入力
- リージョン:ストリームが保存されるリージョンを選択
- ソースタイプ:ソース接続プロファイルを作成したときに選択したプロファイル タイプを選択
- 宛先の種類:宛先接続プロファイルを作成したときに選択したプロファイル タイプを選択
- 暗号化:Google Cloud が管理する暗号鍵を使用するか顧客管理の暗号鍵(CMEK)を使用するかを選択
上記の入力を終えたら必要に応じてラベルを追加し、ページ下部に出てくる[続行]をクリックします。

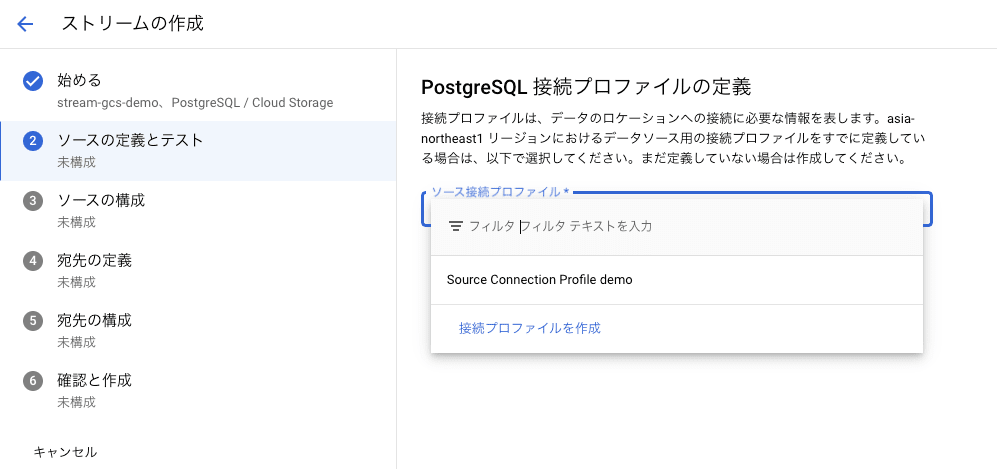
[ソースの定義とテスト]ページにて、作成したソース接続プロファイルを選択します。
接続プロファイルを選択すると、[テスト実行]ボタンが表示され、ここでもソース データベースとの接続をテストできます。
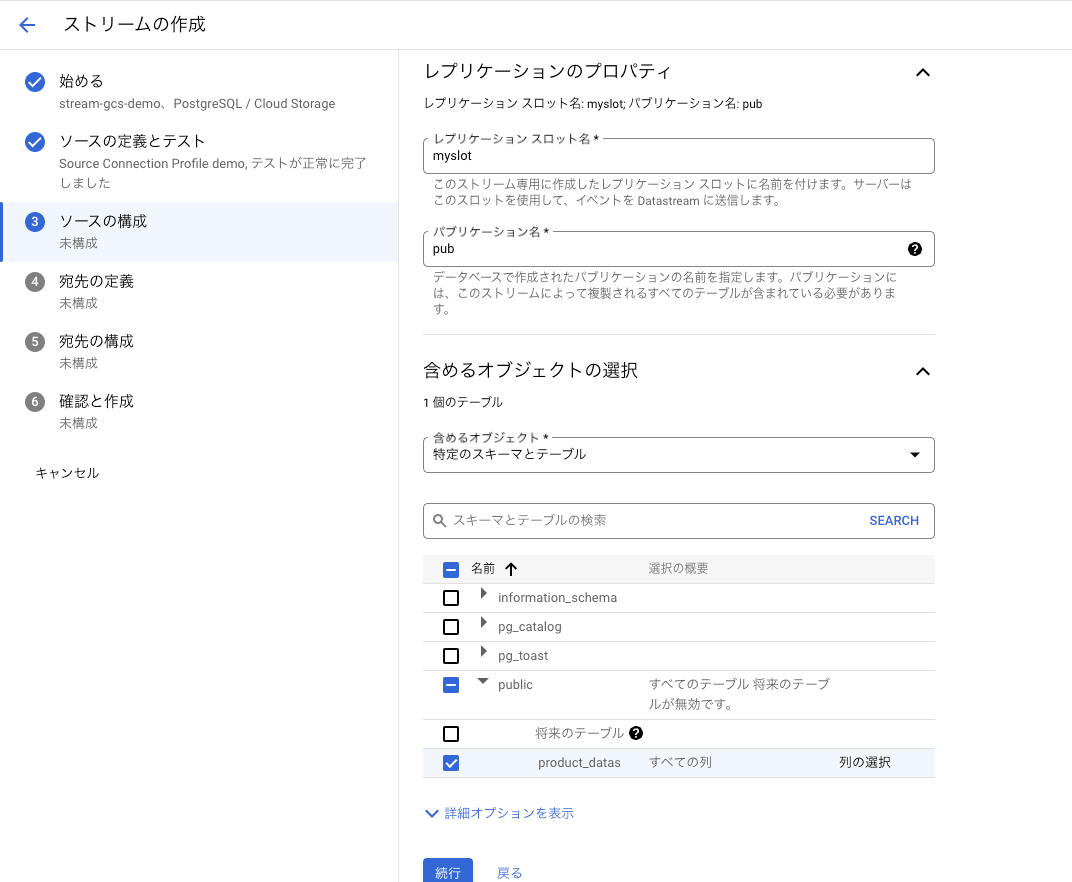
[ソースの構成]ページではレプリケーション プロパティと含めるオブジェクトを定義します。
レプリケーションプロパティについてはソース データベースが PostgreSQL の場合のみ必要な設定になっています。
[レプリケーションのプロパティ]セクションでは事前にソース データベースにて設定したレプリケーション スロットとパブリケーションの名前を入力します。
[含めるオブジェクトを選択]セクションでは、[含めるオブジェクト]プルダウン メニューから、Datastream が転送するソース データベースのテーブルとスキーマを選択します。
今回は[特定のスキーマとテーブル] を選択し、Datastream に pull するスキーマとテーブルのチェックボックスをオンにします。
[宛先の定義]ページにて、作成した宛先接続プロファイルを選択します。

[宛先の構成]ページでは書き込まれるファイルの形式を選択します。
今回は JSON を選択します。
また、ファイルの接頭辞を指定することもできますが今回は指定せずに作成します。

[確認と作成]ページではストリームの詳細とソース、宛先の詳細が表示され、ストリームを検証することができます。
[検証を実行]をクリックし、ストリームを検証します。
全ての検証が完了したら[作成]もしくは[作成して開始]をクリックし、ストリームを作成します。
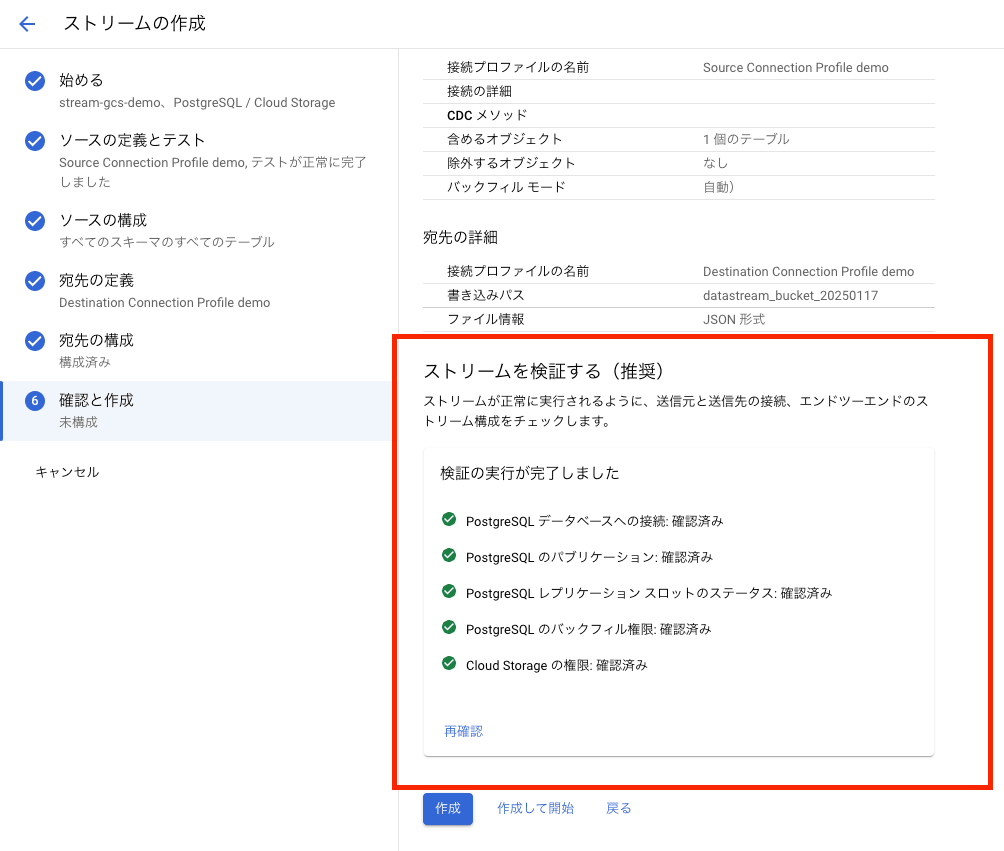
[作成して開始]をクリックした場合はその名の通り作成後にそのままストリームが実行されます。
[作成]をクリックすると、作成のみが行われ、ストリームのステータスが[開始されていません]になります。画面上部の[開始]をクリックし、ストリームを実行しましょう。

動作確認
ストリームが開始されたら、データベースでデータの挿入、更新、削除などを行ってみましょう。
Cloud Storage で該当バケットを確認し、以下のようにデータが格納されていればストリームが正しく動作しています。
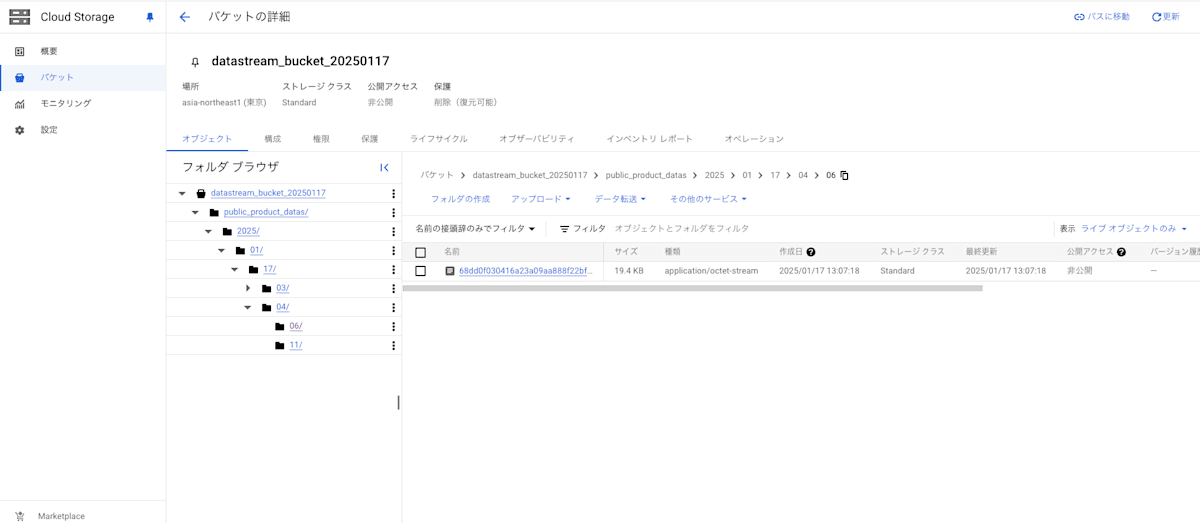
保存されるデータの例
以下のようなデータが JSONL 形式で保存されます。
{
"uuid": "e99c742f-daba-7013-bbd3-e35e00001010",
"read_timestamp": "2025-01-17T03:43:37.791000Z",
"source_timestamp": "2025-01-17T03:43:37.788000Z",
"object": "public_product_datas",
"read_method": "postgresql-cdc",
"stream_name": "projects/283440563360/locations/asia-northeast1/streams/stream-gcs-demo",
"schema_key": "68dd0f030416a23a09aa888f22bf80e459239f8",
"sort_keys": [173229417788, "0/240032A0"],
"source_metadata": {
"schema": "public",
"table": "product_datas",
"is_deleted": false,
"change_type": "INSERT",
"tx_id": 2848,
"lsn": "0/240032A0",
"primary_keys": ["product_id"]
},
"payload": {
"product_id": "11 ",
"product_name": "Lemon",
"created_at": "2025-01-17T03:43:37.786452Z"
}
}
BigQuery に CDC データを格納する
では次に宛先を BigQuery とし、Cloud SQL for PostgreSQL から CDC データを転送する設定を行います。
構成は Cloud Storage 部分が BigQuery に変わっただけでほとんど変わりません。
作成手順も Cloud Storage の場合と同様であり、ソース接続プロファイルの設定に関しては上記で設定したものをそのまま使えるためスキップします。
Datastream 構築
宛先接続プロファイル作成
上記と同様に[プロファイルの作成]をクリックします。今回は[BigQuery]プロファイル タイプを選択します。

[BigQuery プロファイルの作成]ページでプロファイル名/プロファイル ID とリージョンを定義します。
必要に応じてラベルを設定し、画面下部の[作成]をクリックします。

ストリーム作成
上記で設定した時と同様に [ストリームの作成]から作成を行います。
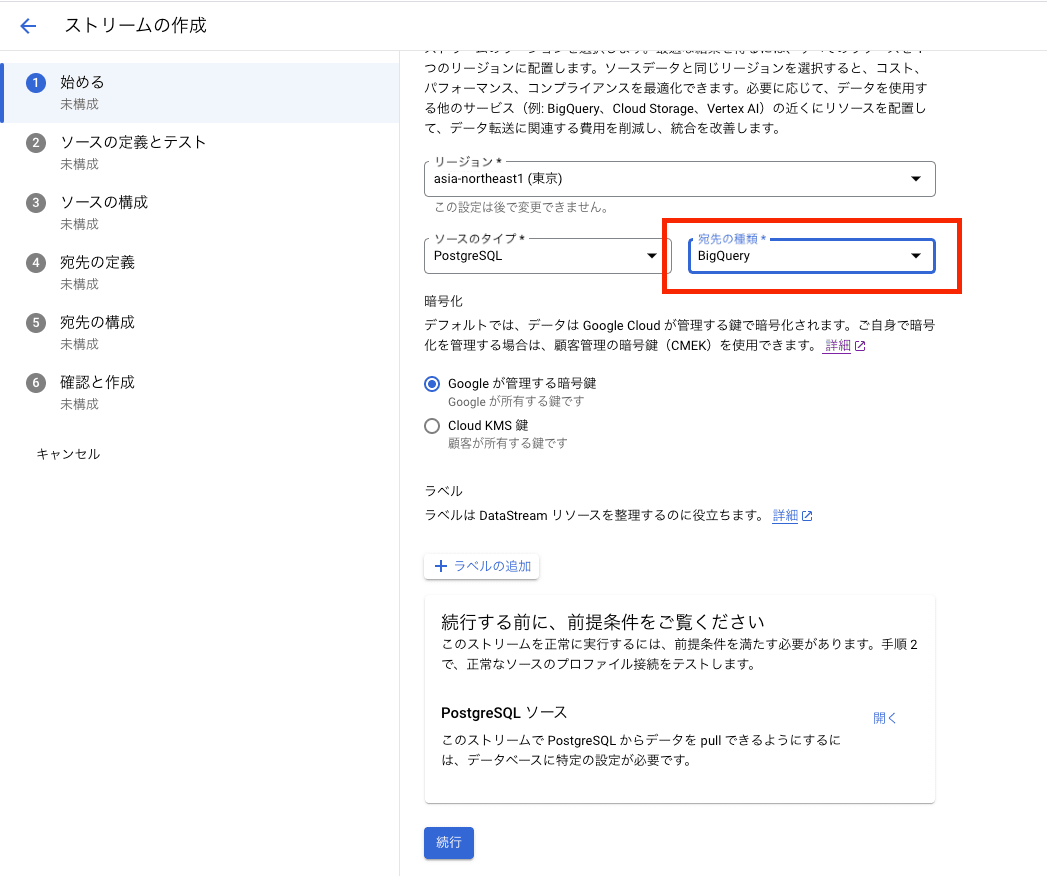
[始める]ページにてストリームの基本設定を定義します。この際、宛先の種類では BigQuery を選択します。
[ソースの定義とテスト]と[ソースの構成]ページでは上記で設定した時と同じ設定を行うためスキップします。
[宛先の定義]ページにて事前に作成した BigQuery を宛先とする接続プロファイルを選択します。
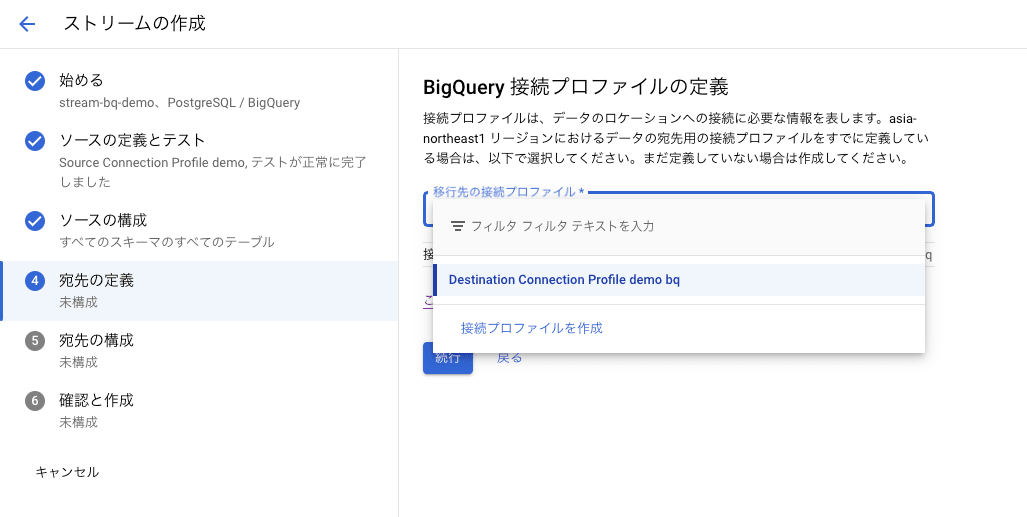
[宛先の構成]ページでは BigQuery の宛先を構成するために必要な情報を定義します。
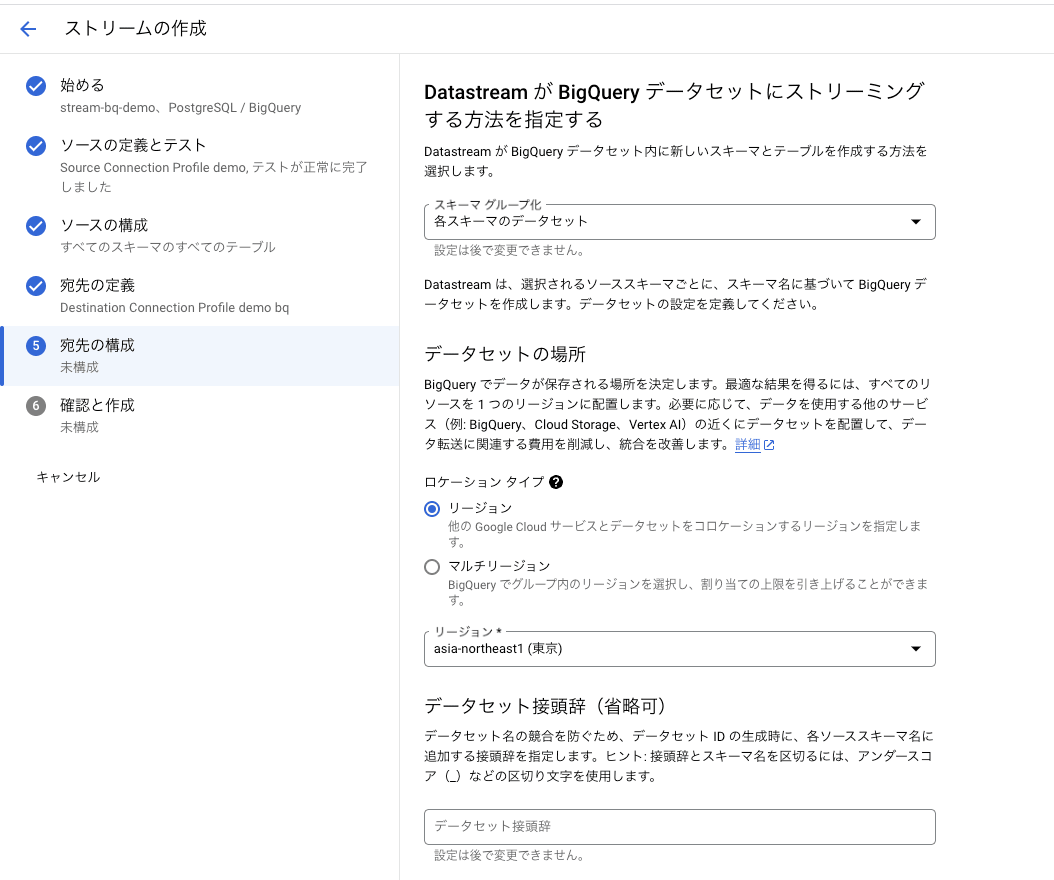
まずは[Datastream が BigQuery データセットにストリーミングする方法を指定する] セクションで Datastream が BigQuery データセット内に新しいスキーマとテーブルを作成する方法を[スキーマのグループ化]プルダウンから選択します。
このプルダウン メニューでは以下のいずれかのオプションを選択します。
- スキーマごとのデータセット
- すべてのスキーマに単一のデータセット
[スキーマごとのデータセット]を選択すると Datastream によってソース データベースのスキーマ名に基づきスキーマごとにデータセットを自動で作成します。
[すべてのスキーマに単一のデータセット]を選択すると、指定した既存のデータセットにソース データベースのテーブルを作成します。この場で新規に作成することも可能です。
今回は[スキーマごとのデータセット]を選択します。
また、今回のように[スキーマごとのデータセット]を選択した場合、データセットの場所やデータセットの接頭辞、暗号化オプションなどの設定も定義します。
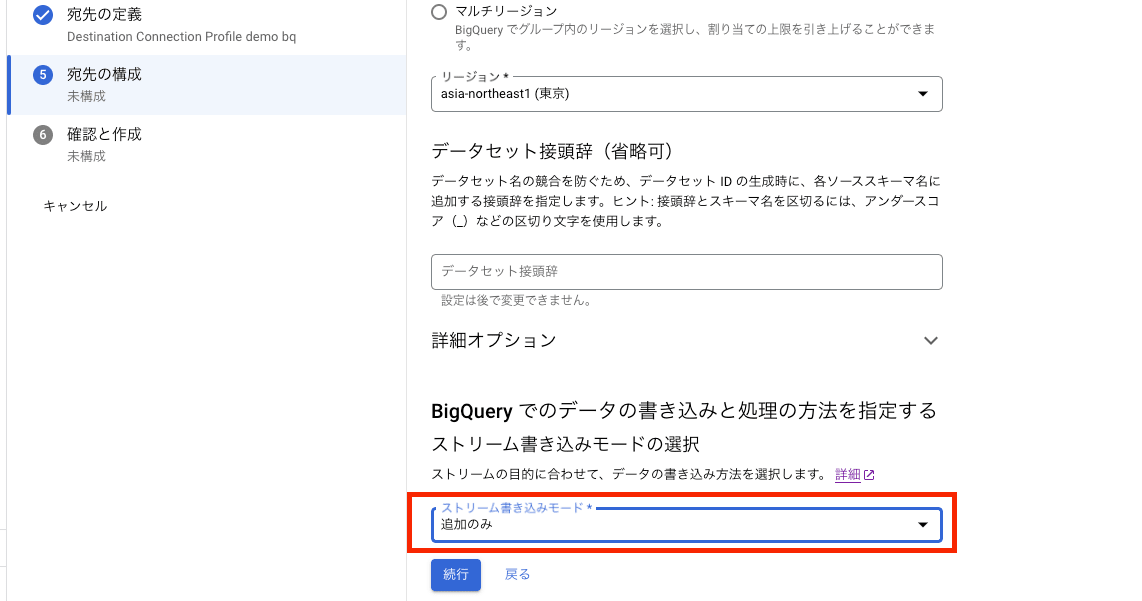
次に[BigQuery でのデータの書き込みと処理の方法を指定する]セクションでストリーム書き込みモードを以下のいずれかから指定します。
- 結合
- 追加のみ
[結合]では、ソースデータベースの現在のデータを同期し、過去のデータは同期しません。[追加のみ]では過去のデータも含めて全て保存します。
つまり、[結合]はソースとなるデータベースのデータをリアルタイムでレプリケートしたい場合に使用し、今回のように CDC データを保存したい場合は[追加のみ]を選択します。
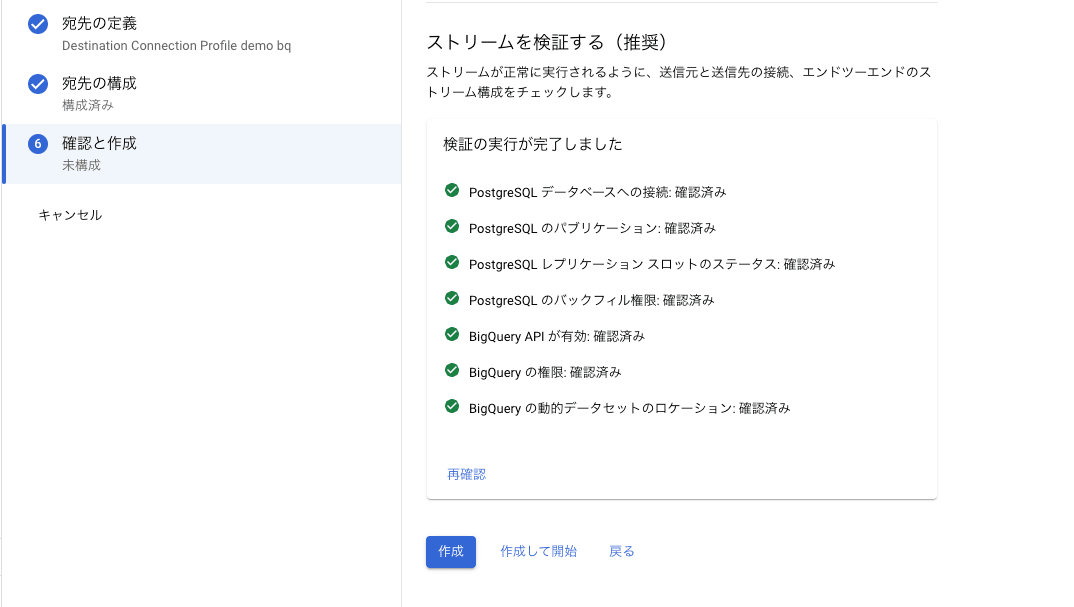
[確認と作成]ページでストリームを検証し、全て問題なく完了したら[作成]をクリックし、設定完了です。
動作確認
ストリームが開始されたら、データベースでデータの挿入、更新、削除などの操作を行い、BigQuery の該当データセットのプレビューを確認します。
プレビューで以下のようにデータが保存されていれば問題ありません。

書き込みモードが結合の場合の保存動作
上記のストリームの設定時に書き込みモードで[結合]を選択した場合、以下のように INSERT、UPDATE、DELETE のような情報はなく、あくまで現在のデータベースのデータが保存されます。
例えば DELETE をした場合、DELETE という情報を保存するのではなく、BigQuery 上でも同じようにデータが削除されます。

まとめ
今回は Datastream を使用して Cloud Storage と BigQuery に CDC データを格納する方法を紹介しました。
Datastream を使用することでかなり簡単にデータ パイプラインを構築することができます。
プライベート接続を使用するともう少し複雑にはなってしまいますが、シンプルで直感的に使えるのがいいなと個人的には感じています。
Datastream を使用する際に本記事が理解の一助になれば幸いです。
最後までご覧いただきありがとうございました。
Discussion