LangChain で社内チャットボット作ってみた
こんにちは、クラウドエース SRE ディビジョン所属の茜です。
今回は、現在最も普及している対話型 AI サービスである ChatGPT で使用されているモデルと、LLM を使ったアプリケーション開発に特化したライブラリである LangChain を用いて社内向けのチャットボットを作成します。
ターゲット
- 任意のデータを元に回答を行うチャットボットを作成したい方
- 任意のデータを元に回答させる仕組みを知りたい方
ChatGPT とは

ChatGPT とは、ユーザーが入力した質問に対して、まるで人間のように自然な対話形式でAIが答えるチャットサービスです。2022 年 11 月に公開されて以来、回答精度の高さが話題となり、利用者が急増しています。
人工知能の研究開発機関「OpenAI」により開発されました。
執筆時点では、GPT-3.5、GPT-4 という大規模言語モデル (LLM) が使用されています。
LangChain とは

LangChain とは、LLM を活用してサービスを開発する際に役立つライブラリです。
LangChainには大きく分けて 2 つの側面があります。1 つは、LLM を用いたアプリケーション開発に必要なコンポーネントを、抽象化されたモジュールとして提供していることです。もう 1 つは、特定のユースケースに特化した機能を備えたモジュールを提供していることです。
これらのモジュールを使用することで、少ない実装量でのプロトタイプの作成が可能となります。また、特定のユースケースに特化した機能を持つモジュールを活用することにより、独自性の高いアプリケーションの実装が実現できます。
主要モジュール
執筆時点では、モジュールは大きく以下の 6 つに分類されています。
これらのカテゴリに対して、機能に応じてさらに細かく分類されています。
-
Model I/O
- Prompts
- LLMs
- Chat Models
- Output Parsers
-
Retrieval
- Document loaders
- Text Splitting
- Text embedding models
- Vector stores
- Retrievers
- Indexing
-
Agents
- Agent
- AgentExecutor
- Tools
- Toolkits
- Chains
- Memory
- Callbacks
RAG について
社内チャットボットでは、企業が持つ社内データを参考に回答を生成する必要があります。
それを実現するために使用されるのが、RAG (Retrieval Augmented Generation) と呼ばれる仕組みです。
RAG では、以下の流れで任意のデータを元にした回答が行われます。
- ユーザーの質問を元に関連性のあるデータをベクターストアから検索し取得
- 質問と取得したデータを埋め込んだプロンプトを作成
- LLM に問い合わせ

RAG の流れ
Retrieval で RAG を実装
RAG を実装するために使用するモジュールが、Retrieval です。
以下の機能を使用します。
- Document loaders:データソースからドキュメントを読み込む
- Text Splitting:ドキュメントをチャンクという単位に分割
- Text embedding models:テキストをベクトル化
- Vector stores:ベクトル化したテキストの保存先
- Retrievers:ユーザー入力と関連するドキュメントを検索し取得

Retrieval の流れ (LangChain 公式より引用)
チャットボット作成
使用モジュール
今回のチャットボットでは、以下のモジュールを使用します。
Model I/O
「LLMs」または「Chat Models」というモジュールを使用することにより、さまざまな言語モデルを共通のインターフェースで使用することができます。
OpenAI の文章生成 API には、「Completions API」と「Chat Completions API」の2つがあり、前者を LangChain で使用するには LLMs モジュール、後者を使用するには Chat Models モジュールを使用します。
今回は、以下の理由から Chat Models モジュール (Chat Completions API) を使用します。
- 最新モデル (gpt-4、gpt-3.5-turbo) は、Chat Completions API のみで使用可能
- Completions API はレガシーな機能となっており、2023 年 7 月以降アップデートが行われていない
Retrieval
前述のように、「Document loaders」「Text Splitting」「Text embedding models」「Vector stores」「Retrievers」を使用し RAG を実装します。
Chains
LLM を使用したアプリケーションでは、単に LLM に入力して出力を得て終わりではなく、処理を連鎖的につなぎたいことが多いです。
今回の場合だと、以下の連鎖的処理が発生します。
- ユーザー入力を Embedding
- 関連性の高いテキストを検索し取得
- 取得した情報をプロンプトに埋め込む
- 文章生成 API を呼び出し、回答を取得
このような連鎖した処理を実現するのが、Chains モジュールであり、上記の一連の処理のために 「RetrievalQA」 という Chain (処理のまとまり) が提供されています。
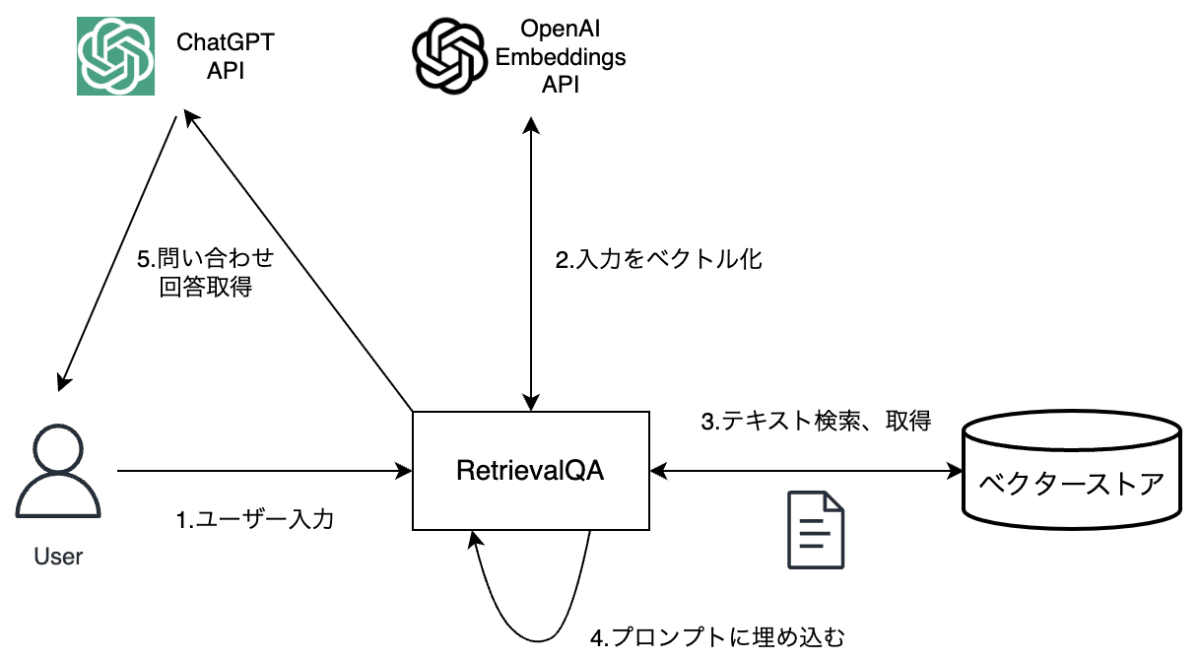
RetrievalQA の基本動作
Callbacks
Callbacksとは、アプリケーションのロギング、モニタリング、ストリーミングなどを効率的に管理する機能です。
これにより、あるイベントが発生したときや特定の条件が成立した場合に、自動的に関数やメソッドを呼び出すことができます。
今回は「StreamlitCallbackHandler」というモジュールを使用し、ストリーミングで応答を取得します。
事前準備
Open AI API キーの取得
Chat Completion API を使用するために、Open AI の API キーを準備します。
-
Open AI の Web サイトにアクセスし、ログインします。
-
API をクリックし、開発者向けの画面に遷移します。

-
API キーの一覧画面に遷移し、「Create new secret key」をクリックします。
-
任意の名前をつけ、API キーを発行します。
ベクターデータベースのセットアップ
社内ドキュメントから取得したベクトルデータを格納するベクターデータベースとして、Pinecone を使用します。
-
Pinecone の Web サイトにアクセスし、ログインします。
-
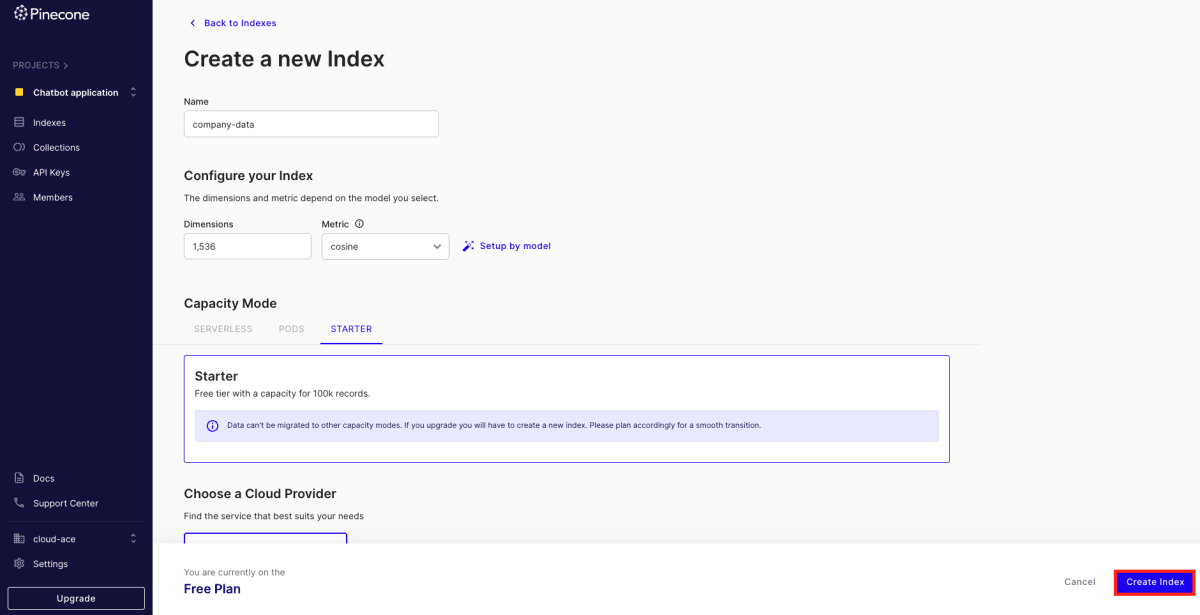
「Create Index」をクリックし、Index を作成します。Index とは、ベクトルデータをまとめて扱う単位のことです。
任意の名前を入力し、「Dimensions」の項目には、Open AI Embeddings API の次元数である「1536」を入力します。
-
「Create Index」をクリックすると Index が作成され、Index の詳細画面に遷移します。

-
API キー一覧画面から、発行されたキーを確認できます。

パッケージとライブラリのインストール
今回のアプリケーションでは、Web フレームワークとして streamlit を使用します。
pip install streamlit
LangChain モジュールと Open AI の API を使用するため「langchain」「langchain-community」「langchain-openai」パッケージをインストールします。
また、.env ファイルの内容を環境変数に設定するため「python-dotenv」パッケージをインストールします。
pip install langchain langchain-community langchain-openai python-dotenv
Pinecone を使用するため、クライアントライブラリ「pinecone-client」をインストールします。
また、OpenAIEmbeddings が必要とする「tiktoken」をインストールします。
pip install pinecone-client tiktoken
PDF などの生のドキュメントをテキストとして読み込むため「unstructured」パッケージをインストールします。
pip install "unstructured[all-docs]"
今回使用したバージョンは以下の通りです。
| パッケージ(ライブラリ)名 | バージョン |
|---|---|
| streamlit | 1.30.0 |
| langchain | 0.1.4 |
| langchain-community | 0.0.16 |
| langchain-openai | 0.0.5 |
| python-dotenv | 1.0.1 |
| pinecone-client | 2.2.4 |
| tiktoken | 0.5.2 |
| unstructured | 0.12.2 |
データの保存
ドキュメントをベクトル化し、Pinecone に保存する処理を実装していきます。
今回は社内ドキュメントとして、日本ディープラーニング協会が提供している生成AIの利用ガイドラインを PDF に変換し使用します。
Python プログラムから Pinecone に接続するため、環境変数として .env ファイルに Pinecone の API キーと Index 名、環境名を記載します。
また、Open AI モジュールを使用するため、Open AI API キーを記載します。使用するモデル、temperature も記載します。
PINECONE_API_KEY=<API キー>
PINECONE_INDEX=company-data
PINECONE_ENV=gcp-starter
OPENAI_API_KEY=<API キー>
OPENAI_API_MODEL=gpt-3.5-turbo
OPENAI_API_TEMPERATURE=0.5
add_document.py ファイルに処理を記述していきます。
import を記述し、load_dotenv で環境変数を設定します。
import os
import sys
import pinecone
from dotenv import load_dotenv
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import Pinecone
load_dotenv()
Pinecone を LangChain のベクターストアとして使用するための関数を定義します。
def initialize_vectorstore():
pinecone.init(
api_key=os.environ["PINECONE_API_KEY"],
environment=os.environ["PINECONE_ENV"],
)
index_name = os.environ["PINECONE_INDEX"]
embeddings = OpenAIEmbeddings()
return Pinecone.from_existing_index(index_name, embeddings)
メインの処理を実装します。
引数で与えられたファイルを UnstructuredFileLoader で読み込み、CharacterTextSplitter で分割し Pinecone に保存します。
ドキュメントのベクトル化処理は、ベクターストアにデータを保存する際に内部的に実行されます。
if __name__ == "__main__":
file_path = sys.argv[1]
loader = UnstructuredFileLoader(file_path)
raw_docs = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=30)
docs = text_splitter.split_documents(raw_docs)
vectorstore = initialize_vectorstore()
vectorstore.add_documents(docs)
add_document.py を実行します。
python add_document.py <ドキュメントパス>
Pinecone を確認すると、16 個のベクトルデータが保存されています。

関連情報を元にした回答
質問に関連した文書を Pinecone から検索し、回答する処理を実装していきます。
internal_qa.py ファイルに処理を記述していきます。
import を記述し、load_dotenv で環境変数を設定します。
import os
import streamlit as st
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_community.callbacks import StreamlitCallbackHandler
from add_document import initialize_vectorstore
from langchain.chains import RetrievalQA
load_dotenv()
st.title("社内チャットボット")
ベクターストアからデータを参照し回答を行う処理を定義します。
ChatOpenAI クラスから OpenAI の言語モデルを使用するインスタンスを作成し、RetrievalQA を用いて質問に関するデータを検索し回答を生成する chain を構築します。
Retriever (質問に関するデータを取得するインターフェース) は、ベクターストアのインスタンスから作成できます。
def create_qa_chain():
vectorstore = initialize_vectorstore()
callback = StreamlitCallbackHandler(st.container())
llm = ChatOpenAI(
model_name=os.environ["OPENAI_API_MODEL"],
temperature=os.environ["OPENAI_API_TEMPERATURE"],
streaming=True,
callbacks=[callback],
)
qa_chain = RetrievalQA.from_llm(llm=llm, retriever=vectorstore.as_retriever())
return qa_chain
最後に UI 部分を実装していきます。
ユーザー入力を受け取り、それに対する応答を生成してチャット形式で表示するインターフェースを作成します。
st.session_state を使用することで、会話履歴が一時的に保持されます。
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
prompt = st.chat_input("What's up?")
if prompt:
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
with st.chat_message("assistant"):
qa_chain = create_qa_chain()
response = qa_chain.invoke(prompt)
st.session_state.messages.append({"role": "assistant", "content": response["result"]})
streamlit コマンドを使用し、アプリケーションを起動します。
streamlit run internal_qa.py --server.port 8080
以下の画面が表示されました。
質問をします。
ベクターストアに保存した情報を元に回答が生成されました。

まとめ
今回は、LangChain を使用し、任意のデータを元に回答を行うチャットボットを作成しました。
LangChain を使用することで、さまざまなモデルを統一のインターフェースで扱うことができました。また、LLM を用いたアプリケーションに必要な機能を簡単に実装することができました。
一方、以下の点には注意が必要です。
- 公式ドキュメントが分かりにくい
- 書籍 (ChatGPT / LangChain によるチャットシステム構築[実践]入門) や GitHub リポジトリも参考にして実装した。
- アップデートが頻繁に行われる
- 今回使用した RetrievalQA は既にレガシーとなっている。
LangChain を使用して、LLM を活かしたアプリケーションを作ってみてはいかがでしょうか。
Discussion