Umami Cloudからセルフホスト型のUmamiにCSVをインポートする方法
はじめに
Umamiは、使いやすいインターフェースと強力なウェブサイト分析を提供しており、多くの開発者やウェブサイトオーナーに人気のある選択肢です。ただし、長期間のデータ保持やより広範囲なドメイン分析に関しては、Umami Cloudの無料版では十分ではありません。このチュートリアルでは、Umami Cloudから自己ホスト型のUmamiにデータを移行する方法を紹介します。
Youtubeビデオチュートリアル
Githubリポジトリ
Huggingface Space
English Version
なぜ移行するのですか?
Umami Cloudの無料版は便利なホスティングを提供していますが、2つの明確な制限があります:
- データ保持期間の制限:データは1年間のみ保持され、その後自動的に削除されます。
- ドメイン名の使用制限:最大3つのドメイン名を分析できます。
セルフホスト版に移行することは、データを保持し、時間をかけて複数のプロジェクトを分析したいユーザーにとって理想的なオプションです。
ステップ1. データのエクスポート
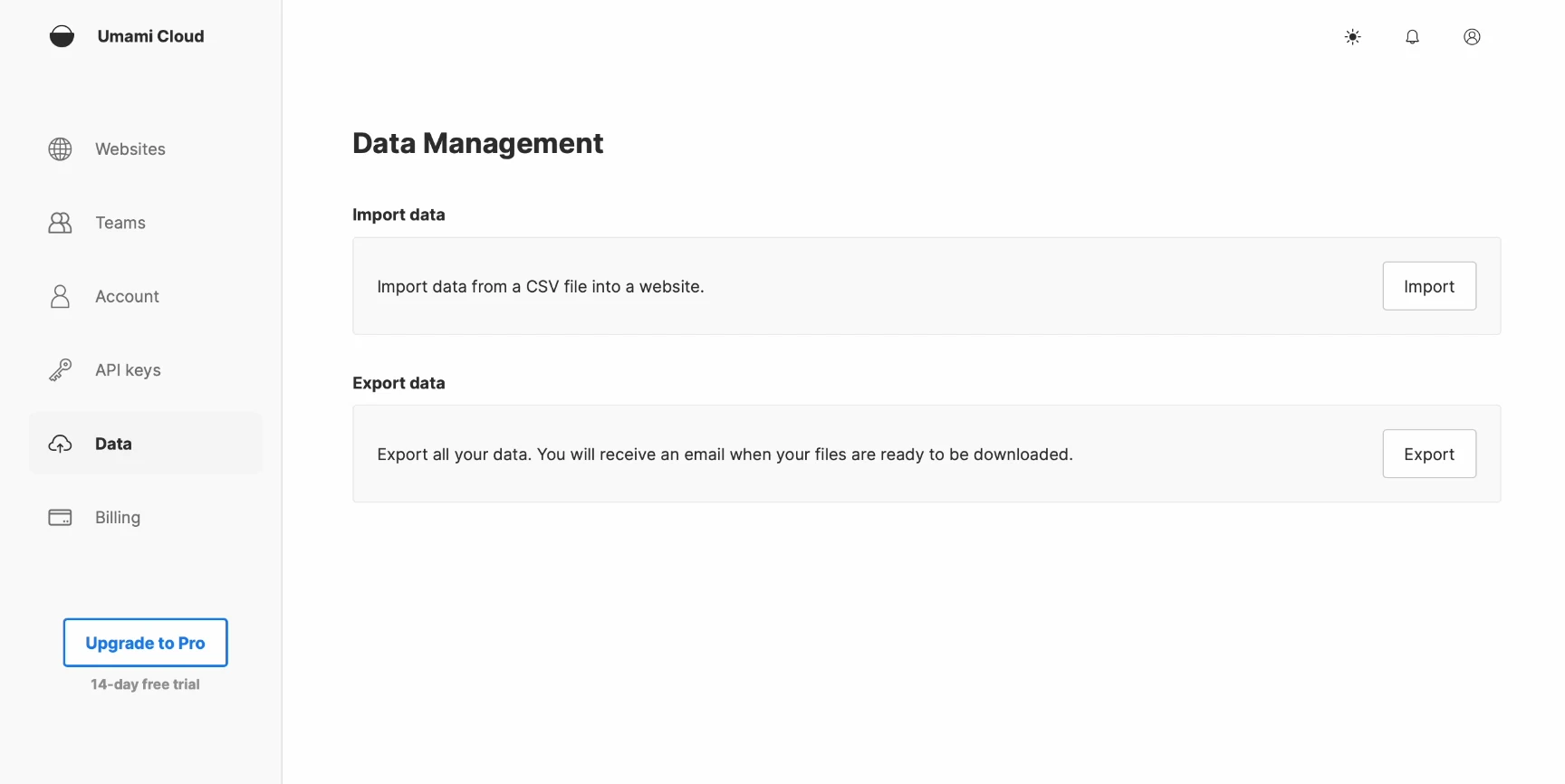
Umami Cloudからデータをエクスポートする
データを転送するためには、まずUmami Cloudからcsvデータをエクスポートする必要があります。
- Umami Cloudアカウントにログインします。
- データ管理ページに移動し、エクスポートするウェブサイトデータを選択します。
- Umamiは選択したデータをパッケージ化し、準備ができ次第、ダウンロードリンクをメールで送信します。
ステップ2. データ処理
CSVファイルをダウンロードしたら、Pythonスクリプトを使用してそれらを処理して、データベースにインポートできるようにする必要があります。このスクリプトは、データを準備し、自己展開バージョンのデータベースにインポートするために適していることを確認するのに役立ちます。このスクリプトは、GitHubからダウンロードするか、Huggingface Spaceを使用できます。
Umamiのデータベースには、website_eventとsessionの2つの主要なデータタイプが関係しています。データをインポートする際に、新しいサイトインスタンスを作成し、古いサイトIDを新しいサイトIDで置き換える必要があります。
pip install pandas
import pandas as pd
# User enter filename and new website id
original_csv_file = input("Please enter the filename of the original CSV file path: ")
new_website_id = input("Please enter the new website ID: ")
# Load the original CSV file
df = pd.read_csv(original_csv_file)
# Update the website_id column with the user-provided website ID
df['website_id'] = new_website_id
# Define the columns required for the website_event table
website_event_columns = [
'event_id', 'website_id', 'session_id', 'created_at', 'url_path',
'url_query', 'referrer_path', 'referrer_query', 'referrer_domain',
'page_title', 'event_type', 'event_name', 'visit_id'
]
# Create a new DataFrame for the website_event data with the required columns
df_website_event = df[website_event_columns]
# Save the new website_event data to a CSV file
df_website_event.to_csv('website_event.csv', index=False)
# Define the columns required for the session table
session_columns = [
'session_id', 'website_id', 'hostname', 'browser', 'os', 'device',
'screen', 'language', 'country', 'subdivision1', 'subdivision2',
'city', 'created_at'
]
# Create a new DataFrame for the session data with the required columns
df_session = df[session_columns]
# Save the new session data to a CSV file
df_session.to_csv('session.csv', index=False)
print("Successfully generated website_event.csv and session.csv")
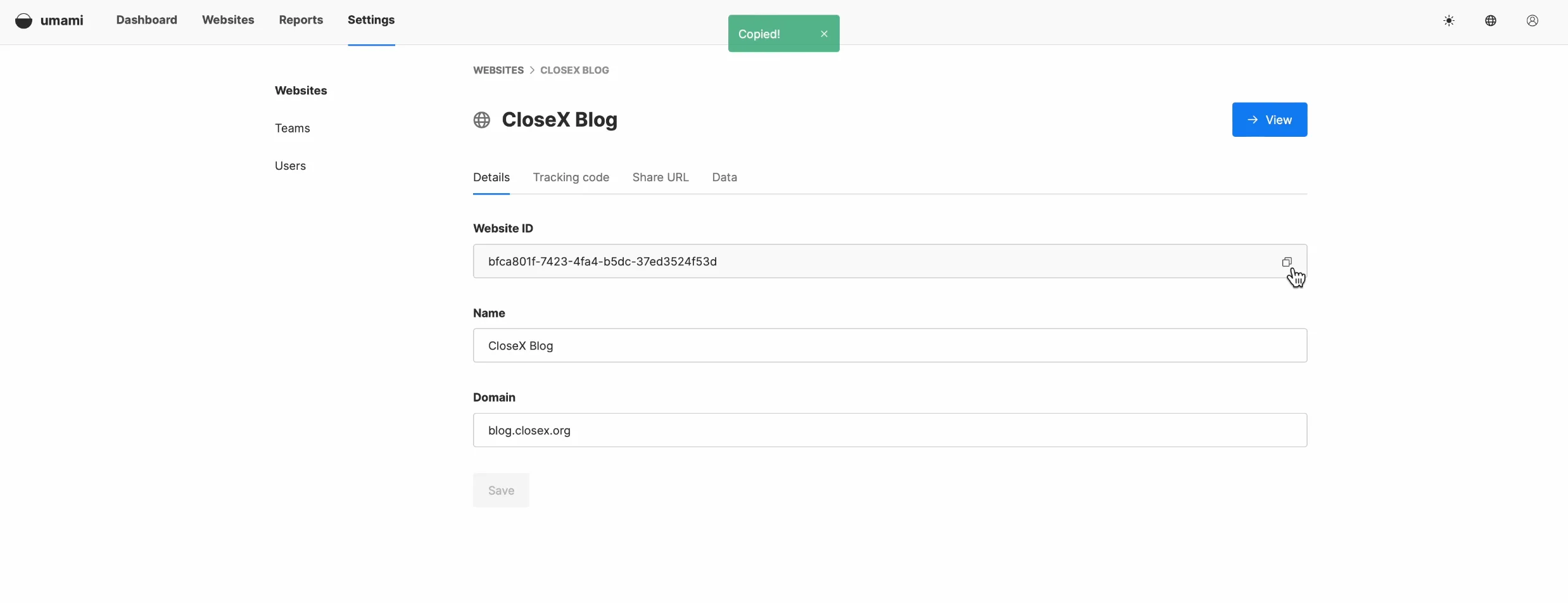
その前に、自己展開されたUmamiのウェブサイトIDをUmami Cloud上の古いウェブサイトIDで置き換える必要があります。ウェブサイトの設定画面でウェブサイトIDを見つけることができます。
データを処理した後、生成される2つのファイルがあるのを確認できます。それらは「website_event.csv」と「session.csv」です。
ステップ3. データのインポート
データは、SQLコマンドラインを使用するか、PG adminなどのデータベース管理ツールを使用してインポートすることができます。インポートプロセスの詳細については、以下のチュートリアルリンクを参照してください。
以下のいずれかの方法を試すことができます:
MySQLテーブルにCSVファイルをインポートする
PostgreSQLテーブルにCSVファイルをインポートする
最初にwebsite_eventをインポートしてから、sessionをインポートします。次に、PGadminに切り替えて、「website_event」フォームを選択してデータのインポートを実行します。ファイルが正常にインポートされたら、Mamiインターフェースを更新するだけで、新しいデータが表示されるはずです。次に、「session」データのインポートを行います。session_idに関する問題が発生する可能性があります。この問題を解決するために、SQLコマンドを使用して関連付けられたユニークインデックスを直接削除することができます。この問題に対処するためのより良い方法がある場合や、困難に直面した場合は、記事の下のコメントセクションにメッセージを残してください。
-
主キー制約の削除: これにより、テーブルに重複する
session_idの値を受け入れることができます。次のコマンドを実行してください:ALTER TABLE session DROP CONSTRAINT session_pkey; -
ユニークインデックスの削除: 次のコマンドを実行して、
session_idの一意性制約を削除してください:DROP INDEX session_session_id_key;
これらの制約を削除すると、テーブルが重複するsession_idの値を受け入れるようになります。ただし、主キーとユニークインデックスは通常、データの整合性を確保し、パフォーマンスを最適化するために使用されるため、それらを削除すると他の問題が発生する可能性があります。
結論
最後に、ページを再度更新すると、すべてのデータが正しく表示されていることが確認できます。この時点で、データ移行は完了し、新しいトラッキングコードの使用を開始する準備が整いました。
GitHubで多くのユーザーがUmamiにインターフェイスから直接データをインポートする機能を追加することを要求していることに注目する価値があります。開発チームはこの機能を検討中であり、近い将来に実装されることを期待しています。
記事を読んでいただきありがとうございます。この記事がお役に立てば幸いです。質問や提案があれば、コメントで自由に議論してください。
Discussion