はじめに
株式会社CLIMTのshalinです。
普段はAUTOMATIC1111/stable-diffusion-webuiを利用してStableDiffusionを実行させていただいてますが、最近どうも更新が遅くなってしまったりバグが増えてきたりと、ビジネス利用をする上で悩ましい点が増えてきました。
せっかくOSSのstable diffusionなので、自分たちの要件にあったWebUIを作ってしまおうということで、Gradioを使って自作していこうと思います。
前提
- python3.9以降がインストールされている
- pythonを最低限触ったことがある
環境構築
まずは必要なディレクトリとファイルを用意します。
mkdir <プロジェクトディレクトリ>
cd <プロジェクトディレクトリ>
touch requirements.txt main.py
その次に必要なパッケージ類をインストールします。
以下のパッケージをrequirements.txtに記載します。
gradio
diffusers
記載できたらターミナルでインストールします。
pip install -r requirements.txt
実装
基本的に実装は main.py に追記していきます。本当はファイル分けなどした方がいいですが今回は気にしません。
今回は王道のtext2imgを実装します。
diffusers
from diffusers import DiffusionPipeline
def text2img(prompt):
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
pipeline.to("cpu")
return pipeline(prompt).images[0]
まずはじめに from diffusers import DiffusionPipeline でdiffusersのDiffusionPipelineをimportします。pipelineを利用して画像生成を行うことになります。
その次に関数を定義し、 pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5") で、modelを読み込みます。
読み込み方法は2種類あり、
- hugging-faceから読み込む
- リポジトリ内にダウンロードして読み込む
今回はrepoを大きくしたくないので、1の方法でrunwayml/stable-diffusion-v1-5を利用します。
pipeline.to("cpu") では cpu を指定していますが、GPUを積んだPCを利用されている方は cuda と記載すれば生成スピードがかなり速くなります。
最後に return pipeline(prompt).images[0] で実行し生成できた画像を返します。
gradio
import gradio as gr
from diffusers import DiffusionPipeline
def text2img(prompt):
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
pipeline.to("cpu")
return pipeline(prompt).images[0]
app = gr.Interface(
text2img,
"text",
gr.Image(shape=(512, 512)),
)
app.launch()
まず import gradio as gr でgradioをimportします。
次に gr.Interface(...) でgradioを使ってUIの定義をしていきます。第1引数はUIで実行する関数、第2引数はinputの形、第3引数はoutputの形になります。
今回は、テキストを受け取り、画像を出力するという形のinterfaceにしてます。
最後に app.launch() でGradioのUIが起動されます。
実際に起動して触ってみましょう。
python3.9 main.py
テキストフィールドに任意のプロンプトを入力して送信ボタンを押してみましょう。

ちょっと顔は崩れてますが無事に生成できましたね(M2 MacBookだと3分くらいかかります...)
改造
これだけだとpromptしか調整できず楽しくないため、できることを増やしてみましょう。
import gradio as gr
from diffusers import DiffusionPipeline
def text2img(prompt, negative_prompt, step):
pipeline = DiffusionPipeline.from_pretrained("andite/anything-v4.0")
pipeline.to("cpu")
return pipeline(prompt=prompt, num_inference_steps=step, negative_prompt=negative_prompt).images[0]
app = gr.Interface(
text2img,
[
gr.TextArea(label="Prompt"),
gr.TextArea(label="Negative Prompt"),
gr.Slider(minimum=1, maximum=150, value=50, step=1, label="Sampling Step")
],
gr.Image(shape=(512, 512)),
)
app.launch()
inputの量を増やしました。元々textのみinputとして渡してましたが、negative promptやsampling stepも追加してみました。
実際の画面の写真がこちら
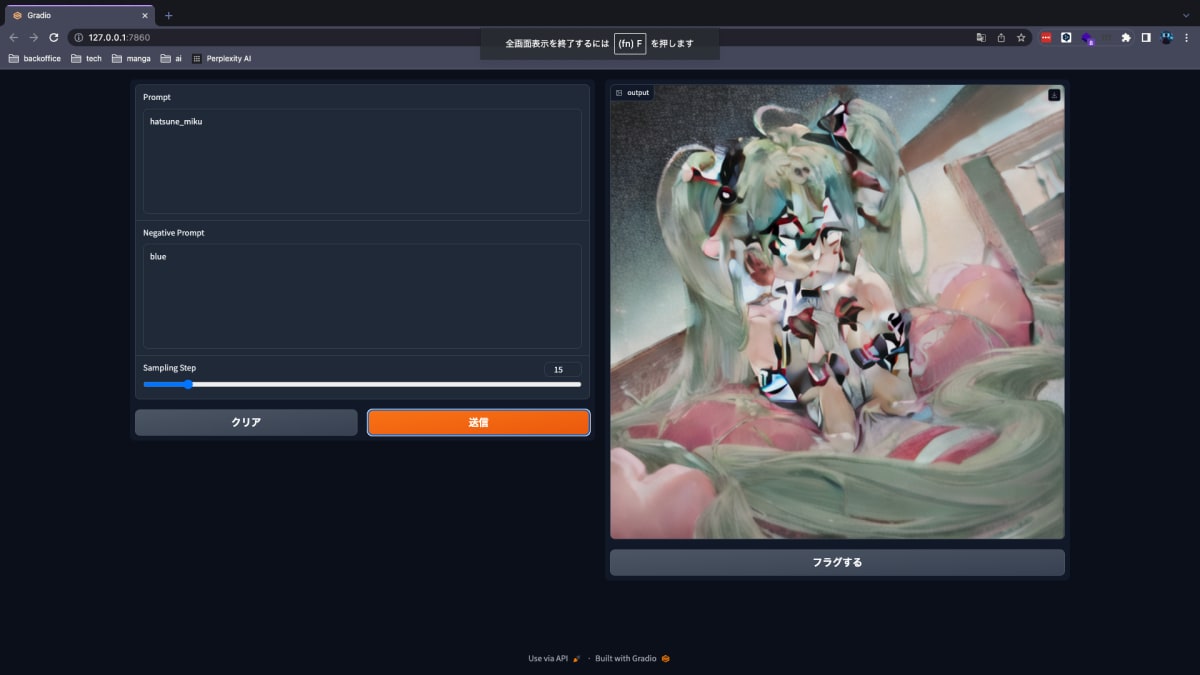
だいぶホラーですね...Sampling stepを15まで下げた効果が出ています。
おわりに
この記事ではGradioを使ったStable DiffusionのWebUIを自作する方法を紹介しました。
かなり少ないコードで作れるため、皆さんもぜひ試してみてください。

Discussion