【Kubernetes】k8sgptが監視ツールとして使えそうか試してみた
はじめに
k8sgptというKubernetesのクラスターに対して様々な問題を診断してくれるツールがあります。
この検証をローカル環境から直接試す記事はいくつかありましたが、執筆時点で「コンテナ化してCronjobで動かしてみよう」というのは見つからなかったので、本記事を記載してみました。
k8sgptとは?
k8sgptは、Kubernetes クラスターをスキャンし、シンプルな英語で問題を診断およびトリアージする(つまり、優先度の高い対応内容を把握する)ためのツールです。
使用できるモデルは、OpenAI、Azure、Cohere、Amazon Bedrock、
Google Gemini、ローカル モデル、等と記載されています。(ReadMeより)
本記事ではGoogle GeminiのAPI Keyを使用して検証してみました。
使い方の想定
クラスターの監視という視点で考えたときに、ローカル環境から監視することはまずありえません。
今回は、docker-desktopのローカルのk8sクラスタ環境を利用して、以下の図のように構成してみました。
- Ubuntuにk8sgptをインストールしたコンテナイメージを作成
- 作成したコンテナイメージを使用したCronjobを作成
- 監視(解析)対象を
testというNamespaceのPodに限定

準備
Dockerfile
まずはあらかじめ、Dockerfileと同ディレクトリにdocker-desktopの.kube/configを書き出しておきます。context名がdocker-desktopなら、以下でconfigというファイルに書き出せます。
kubectl config view \
--minify \
--flatten \
--context=docker-desktop \
> config
次に、そのconfigをマウントさせたDockerfileを以下のように作成してみました。
FROM ubuntu:22.04
COPY config /root/.kube/config
RUN apt update && \
apt install -y curl gnupg lsb-release
RUN curl -LO https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.4.21/k8sgpt_amd64.deb && \
dpkg -i k8sgpt_amd64.deb && \
rm k8sgpt_amd64.debp
ローカルでbuildしておきます。
docker buildx build -t k8sgpt . --platform linux/amd64
ServiceAccount
作成するk8sgptのCronjobが色々アクセス出来るよう、ちょっと乱暴ですが全権限付与したサービスアカウントを用意しておきます。
apiVersion: v1
kind: ServiceAccount
metadata:
name: k8sgpt-sa
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: k8sgpt-sa
rules:
- apiGroups: ["*"]
resources: ["*"]
verbs: ["*"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: k8sgpt-sa-binding
subjects:
- kind: ServiceAccount
name: k8sgpt-sa
namespace: k8sgpt
roleRef:
kind: ClusterRole
name: k8sgpt-sa
apiGroup: rbac.authorization.k8s.io
Cronjobとenv
.envファイルに、今回使用するGeminiAPIのAPI Keyを定義しました。
こちらは後ほどkustomizationでSecret化させます。
GEMINI_API_KEY=*****************************
そしてCronjobです。
apiVersion: batch/v1
kind: CronJob
metadata:
name: k8sgpt
namespace: k8sgpt
spec:
timeZone: Asia/Tokyo
schedule: "*/15 * * * *"
jobTemplate:
spec:
template:
spec:
serviceAccountName: k8sgpt-sa
containers:
- name: k8sgpt
image: k8sgpt
imagePullPolicy: Never
command:
- sh
- -c
- |
k8sgpt auth add --backend google --model gemini-2.5-flash --password ${GEMINI_API_KEY} && \
k8sgpt analyze -l Japanese -b google --explain --namespace=test --filter=Pod --anonymize
env:
- name: GEMINI_API_KEY
valueFrom:
secretKeyRef:
name: gemini-env
key: GEMINI_API_KEY
envFrom:
- secretRef:
name: gemini-env
restartPolicy: OnFailure
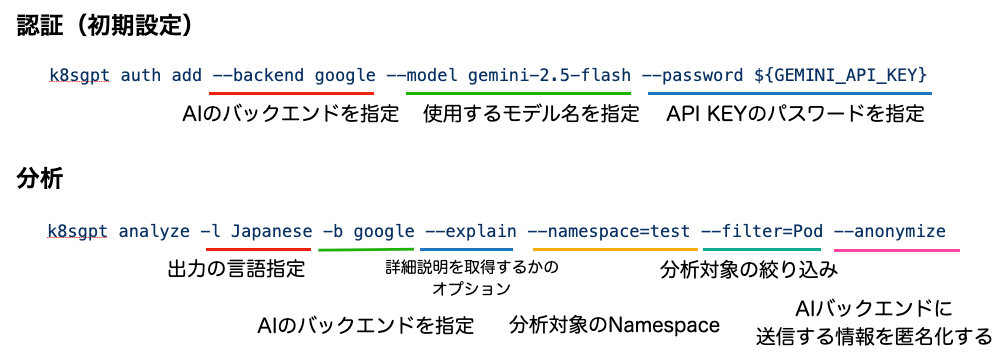
ここでcommandについて補足します。
詳しいリファレンスの基本は、公式リポジトリを参照いただきたいですが、
必要なコマンドは、
-
k8sgpt authコマンドで初期設定 -
k8sgpt analyzeコマンドで分析
という流れになります。
ここでは、今回の検証の要件を満たすよう、図のようなオプションを指定して実行しています。
Kustomization
先述した.envファイルは、ここでgemini-envとしてSecretに変換しています。
namespace: k8sgpt
resources:
- cronjob.yml
secretGenerator:
- name: gemini-env
envs:
- .env
generatorOptions:
disableNameSuffixHash: true
ここまで来たらCronjob周りはapplyして問題ございません。
% kubectl apply -k .
secret/gemini-env created
cronjob.batch/k8sgpt created
CrashLoopBackOffなDeploymentの用意
簡単に用意できる異常なPodを用意します。
起動時にexit 1を実行するだけです。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-crashloop
spec:
replicas: 1
selector:
matchLabels:
app: nginx-crashloop
template:
metadata:
labels:
app: nginx-crashloop
spec:
containers:
- name: nginx
image: nginx:latest
command: ["sh", "-c", "exit 1"]
k8sgptの実行
分析結果
用意が整ったところで、早速Cronjobを実行してログを確認してみました。
なぜか日本語にならなかったのですが、下記のように出力されました。
0: Deployment test/nginx-crashloop()
- Error: Deployment test/nginx-crashloop has 1 replicas but 0 are available with status running
Error: Deployment 'nginx-crashloop' in 'test' namespace expects 1 pod, but none are available. Pods are likely stuck in a crash loop.
Solution: 1. `kubectl get pods -n test` (check status). 2. `kubectl logs <pod-name> -n test` (find crash reason). 3. `kubectl describe pod <pod-name> -n test` (check events/errors). Fix image/config/code.
正直、普段からKubernetesを運用している身としては、今回のケースに関しては特別なことは何一つ書いていない印象を受けました。
触り始めの人にとっては、どのようなコマンドを実行することでトラブルシューティング出来るかヒントを得られるため、役に立つかもしれません。
APIの使用トークン
上記の分量では、1リクエストで済んでおり、使用トークンは100ちょっとでした。

使ってみて分かったこと
ここからは上記以外で色々試してみて分かったことをいくつか記載してみます。
キャッシュが効くのでCronjobには不向きかもしれない
Cronjobではなく、ローカルのコンテナ等から何度か試すと分かったのですが、同じ状態に対して分析(k8sgpt analyze)を走らせた場合、キャッシュが効いて2回目以降はAIに問い合わせのリクエストがいかないことが分かりました。
上記に記載したCronjobは起動のたびに初期状態となるため、場合によっては同様の無駄なリクエストをAIに投げる可能性があると思い、Cronjobには不向きだなと感じました。
(追記: remote cacheを使えば解決できるかもしれません)
クラスタ全体の解析はそれなりに時間とコストがかかりそう
それなりの規模(Podだけで100超え)のクラスターに対して、filter指定をせずに分析を走らせると、分析5%程度でGeminiAPIの無料枠が吹っ飛んで429エラーが返ってきました。
トークンを潤沢に使ったとしても、以下の表示から20〜30分かかる見込みなのでしょうか...?
正直気軽に実行できないなと感じてしまいました。
5% | | (25/424, 12 it/min) [2m59s:32m46s]
Error: failed while calling AI provider google: googleapi: Error 429: You exceeded your current quota, please check your plan and billing details. For more information on this error, head to: https://ai.google.dev/gemini-api/docs/rate-limits.
セキュリティ面の懸念がある
一応anonymizeオプションが存在し、ReadMeには「データはAIバックエンドに送信される前に匿名化されます」という旨記載がありますが、これを信用しきって本番サービスが稼働中のクラスタに対し気軽に分析走らせられるかは要確認です。
使用するAIモデルの選定は必要
使用するAIモデルによって分析できる能力は変わってくるため、これについても運用する前に選定が必要だなと思います。
本記事ではそこまで検証できておりませんが、
以下のOpenAIとGeminiを比較した記事が大変参考になりました。
まとめ
以上、Cronjobでk8sgptを試す方法と感想でした。
今のところ、もしk8sgptを使うならCronjobではなくローカル環境からで、
まずは単発のエラー解析の手段として、きちんと対象を絞って実行するのが無難かなという印象です。
まだoperator等他の機能や要素を試していないため、引き続きキャッチアップしていこうと考えています。
ここまで読んでいただきありがとうございました。
Discussion