OpenAI Embedded SDKをPSRAMなしで動かす
OpenAI Embedded SDKをPSRAMなしで動かす
本記事は M5Stack Advent Calendar 2024の 25日目の記事です。
概要
2024年10月1日に、OpenAIからRealtime APIが発表されました。
Realtime APIではOpenAIのサービスとWebRTCもしくはWebSocketによるリアルタイムでのストリーム接続を行い、クライアントからの音声入力に対し、対話応答の音声を出力します。
特筆すべき点は応答速度ですが、リアルタイムでの対話が成立する程度に十分な遅延時間で応答します。
さらに、2024年12月の第3週に、Realtime APIをWiFi通信機能付きマイコン ESP32-S3 から呼び出すサンプルとして OpenAI Realtime Embedded SDK (https://github.com/openai/openai-realtime-embedded-sdk) がGitHubで公開されました。
このサンプルでは、ESP32-S3 を搭載した評価ボード Freenove ESP32-S3-WROOM および Sonatino 向けに、Realtime APIでの音声対話を実装しており、ESP32-S3という安価なMCUとインターネット接続のみでリアルタイムの対話応答を実現します。
一方、M5Stackの製品として、ESP32-S3、マイクおよびスピーカーを搭載している製品として CoreS3 とその廉価版である CoreS3 SEがあります。
そこで、OpenAI Realtime Embedded SDK を CoreS3 SE 向けにポーティングしてみました。
ポーティング方針
OpenAI Realtime Embedded SDKの構造
OpenAI Realtime Embedded SDK (以降サンプルと呼称) は、Espressifの公式開発ツールである ESP-IDF のv4.1.0以上向けのプロジェクトとして構成されています。
SDKと名前がついていますが、特定のボード向けに OpenAI Realtime API による音声対話応答を実装したサンプルといった程度の規模のものです。
特にターゲットボードごとの抽象化やポーティング等の構造は用意されていませんので、現時点では該当箇所を直接書き換えていくことになります。
リポジトリ上の README.md にビルド方法などが記載されていますが、リポジトリからの取得方法が記載されておらず、git submoduleによって管理されている部分があるのでビルドして初めて足りないことに気づきます。
以下にビルド手順を示します。ESP-IDF v4.1以上がすでにインストールされており使用可能な状態 (source export.shなどで環境変数が設定されている状態) のLinux環境を前提とします。
submoduleを使っているので --recursive をつけてcloneします。
git clone https://github.com/openai/openai-realtime-embedded-sdk --recursive
もし --recursive をつけるのを忘れた場合は、 git submodule update を実行してサブモジュールを取ってきます。
cd openai-realtime-embedded-sdk
git submodule update --init --recursive
あとはREADME.mdの手順通り、環境変数を設定してビルドします。
cd openai-realtime-embedded-sdk
export WIFI_SSID=(WiFI APのSSID)
export WIFI_PASSWORD=(WiFi APのパスワード)
export OPENAI_API_KEY=(OpenAIのAPI Key)
idf.py set-target esp32-s3
idf.py build
これでまずはオリジナルのコードのビルドができることを確認できました。
M5Unifiedの使用
M5StickC以降の中規模以上のM5Stack製コアモジュールには、大抵何かしらの電源管理ICが搭載されています。CoreS3にもAXP2101という電源管理ICが搭載されており、電源投入後に初期化処理をおこなわなければ周辺回路に電源が供給されません。
AXP2101の初期化処理を実装することもできますが、初期化手順が公式では非公開であったりと少々厄介です。
M5Stack製品のコアモジュール等の共通のドライバ実装として M5Unified (https://github.com/m5stack/M5Unified) があります。M5Unifiedを使えば電源管理ICの初期化やマイク・スピーカーからの音声入出力を行えますので、こちらを使って実装を始めました。
M5UnifiedはArduino向けのライブラリですが、ESP-IDFのコンポーネントとしても使用可能です。今回は components ディレクトリにsubmoduleとして追加して使用します。
cd components
git submodule add https://github.com/m5stack/M5Unified
また、コンポーネントを参照できるように src/CMakeLists.txt の idf_component_register の REQUIRES の内容を以下のとおり変更します。
idf_component_register(
SRCS ${COMMON_SRC} "wifi.cpp" "media.cpp"
REQUIRES driver esp_wifi nvs_flash peer esp_psram esp-libopus esp_http_client M5Unified)
これでM5Unifiedを呼び出せるようになるので、 src/main.cpp で M5Unifiedを初期化します。
M5Unifiedの設定 cfg の値のうち internal_spk と internal_mic に false を設定してから M5.begin(cfg) を呼び出します。
M5Unifiedが内蔵スピーカーとマイク 以外の 電源管理IC等の初期化を行います。
#include <M5Unified.h>
...
extern "C" void app_main(void) {
...
auto cfg = M5.config();
cfg.internal_spk = false;
cfg.internal_mic = false;
M5.begin(cfg);
...
}
マイクとスピーカーの同時使用
電源の初期化やマイク・スピーカーの動作は確認できたものの、マイクとスピーカーが同時に使用できないという致命的な問題にぶつかりました。
この問題についてXにポストしたところ、ESP32-S3のI2S通信機能は送受信を同時に行えるので、I2Sペリフェラルを直接扱えばマイク・スピーカーを同時に仕様できるはずというリプライをもらいました。
調べてみたところできそうだったので、その方針で実装を勧めました。M5Unifiedを使ってマイクとスピーカーを除くペリフェラルの制御を行い、マイクとスピーカーはESP-IDFのI2Sドライバを用います。
幸い、サンプル自体がもともとESP-IDFのI2Sドライバを使って実装されていたので、最終的にパラメータを適切に設定し、CoreS3 SEのマイクとスピーカーで動作するようになりました。
サンプルではI2Sを用いたマイク・スピーカーの音声入出力およびOpusでのエンコード・デコード処理は src/media.cpp に記述されています。
まずはCoreS3 (SE) のマイク・スピーカーのピン接続に合わせて、I2Sのピン定義を変更します。元の定義ではマイク用とスピーカー用で MCLK_PIN 以外の定義が分かれていましたが、
CoreS3では共用しているのでデータピン以外は共通の定義に変更します。
#define MCLK_PIN 0
#define BCLK_PIN 34
#define LRCLK_PIN 33
#define DATA_IN_PIN 14
#define DATA_OUT_PIN 13
つぎに、I2Sの初期化処理を入出力別の2チャンネル分から、共通の1チャネルのみに変更します。
i2s_config_t::mode に対して i2s_mode_t::I2S_MODE_MASTER | i2s_mode_t::I2S_MODE_TX | i2s_mode_t::I2S_MODE_RX と、TXおよびRXの両方を有効にすると、共通のI2Sチャネルで入出力を同時に行えます。
また、CoreS3 SEの内蔵マイクとスピーカーはいずれもモノラルなので、 i2s_config_t::channel_format を I2S_CHANNEL_FMT_RIGHT_LEFT から I2S_CHANNEL_FMT_LEFT_ONLY に変更します。
ESP_LOGI(TAG, "Initializing I2S for audio input/output");
i2s_config_t i2s_config = {
.mode = (i2s_mode_t)(I2S_MODE_MASTER | I2S_MODE_TX | I2S_MODE_RX),
.sample_rate = SAMPLE_RATE,
.bits_per_sample = I2S_BITS_PER_SAMPLE_16BIT,
.channel_format = I2S_CHANNEL_FMT_ONLY_LEFT,
.communication_format = I2S_COMM_FORMAT_I2S,
.intr_alloc_flags = ESP_INTR_FLAG_LEVEL1,
.dma_buf_count = 8,
.dma_buf_len = BUFFER_SAMPLES,
.use_apll = 1,
.tx_desc_auto_clear = true,
};
if (i2s_driver_install(I2S_NUM_0, &i2s_config, 0, NULL) != ESP_OK) {
ESP_LOGE(TAG, "Failed to configure I2S driver for audio input/output");
return;
}
i2s_pin_config_t pin_config = {
.mck_io_num = MCLK_PIN,
.bck_io_num = BCLK_PIN,
.ws_io_num = LRCLK_PIN,
.data_out_num = DATA_OUT_PIN,
.data_in_num = DATA_IN_PIN,
};
if (i2s_set_pin(I2S_NUM_0, &pin_config) != ESP_OK) {
ESP_LOGE(TAG, "Failed to set I2S pins for audio input/output");
return;
}
i2s_zero_dma_buffer(I2S_NUM_0);
I2Sの入出力を共通化したことにより、I2Sの入出力でのDMAバッファのサイズも共通となります。元のコードでは入出力でバッファサイズが異なっていたので、マイク入力の処理をスピーカー出力のバッファサイズに合わせます。
I2SドライバのDMAバッファサイズは bits_per_sample * チャネル数 * dma_buf_len / 8 [bytes] となります。
今回の設定では channel_format を I2S_CHANNEL_FMT_ONLY_LEFT つまりモノラルの設定、 dma_buf_len = BUFFER_SAMPLES、 bits_per_sample = I2S_BITS_PER_SAMPLE_16BIT にしているので、
16 * 1 * BUFFER_SAMPLES / 8 = BUFFER_SAMPLES * 2 です。
元のコードでは入力バッファのサイズは BUFFER_SAMPLES となっていたので、バッファのサイズを BUFFER_SAMPLES*2 に変更し、I2Sからの読み出し時の長さも同様に変更します。
変更後は定数の名前通り BUFFER_SAMPLES が入出力両方のバッファのサンプル数を表すようになったので、 BUFFER_SAMPLES * sizeof(opus_int16) でバッファのバイト単位でのサイズを計算するようにします。
また、opus_encode の第3引数はサンプル数単位での入力サイズを指定するので、 BUFFER_SAMPLES/2 から BUFFER_SAMPLES に変更します。
void oai_init_audio_encoder() {
int encoder_error;
opus_encoder = opus_encoder_create(SAMPLE_RATE, 1, OPUS_APPLICATION_VOIP,
&encoder_error);
if (encoder_error != OPUS_OK) {
ESP_LOGE(TAG, "Failed to create OPUS encoder");
return;
}
if (opus_encoder_init(opus_encoder, SAMPLE_RATE, 1, OPUS_APPLICATION_VOIP) !=
OPUS_OK) {
ESP_LOGE(TAG, "Failed to initialize OPUS encoder");
return;
}
opus_encoder_ctl(opus_encoder, OPUS_SET_BITRATE(OPUS_ENCODER_BITRATE));
opus_encoder_ctl(opus_encoder, OPUS_SET_COMPLEXITY(OPUS_ENCODER_COMPLEXITY));
opus_encoder_ctl(opus_encoder, OPUS_SET_SIGNAL(OPUS_SIGNAL_VOICE));
encoder_input_buffer = (opus_int16 *)malloc(BUFFER_SAMPLES*sizeof(opus_int16)); // 変更
encoder_output_buffer = (uint8_t *)malloc(OPUS_OUT_BUFFER_SIZE);
}
...
void oai_send_audio(PeerConnection *peer_connection) {
size_t bytes_read = 0;
if( esp_err_t err = i2s_read(I2S_NUM_0, encoder_input_buffer, BUFFER_SAMPLES*sizeof(opus_int16), &bytes_read, // 変更
portMAX_DELAY) ; err != ESP_OK ) {
ESP_LOGE(TAG, "Failed to read audio data from I2S: %s", esp_err_to_name(err));
}
auto encoded_size =
opus_encode(opus_encoder, encoder_input_buffer, BUFFER_SAMPLES, // 変更 (opus_encodeの第3引数はサンプル数単位での入力サイズを指定する)
encoder_output_buffer, OPUS_OUT_BUFFER_SIZE);
peer_connection_send_audio(peer_connection, encoder_output_buffer,
encoded_size);
}
マイクとスピーカーの初期化
CoreS3 SEに搭載されているマイクおよびスピーカーは、I2Sとは別に I2C (typoではない) でESP32-S3と接続されています。
マイクおよびスピーカーを動かすにはI2C経由で設定の初期化が必要です。
これらのデバイスの初期化処理は、M5Unifiedの M5Unified.cpp のなかに記述されているので、必要な部分だけもらってきます。
マイクのデバイス ES7210 のレジスタに関する情報は入手可能なデータシートに記載されていないので内容はよくわかりませんが、スピーカー用DAC AW88298 はレジスタマップが記載されたデータシートが公開されているため、設定内容がある程度わかります。
M5Unifiedのもとのコードではサンプリングレートからレジスタ 0x06 の I2SSR の値を計算する処理がはいっていましたが、今回は8kHz固定なので、 i2SSR = 0 としたときの固定値で初期化しています。
// Initialization of AW88298 and ES7210 from M5Unified implementation.
constexpr std::uint8_t aw88298_i2c_addr = 0x36;
constexpr std::uint8_t es7210_i2c_addr = 0x40;
constexpr std::uint8_t aw9523_i2c_addr = 0x58;
static void aw88298_write_reg(std::uint8_t reg, std::uint16_t value)
{
value = __builtin_bswap16(value);
M5.In_I2C.writeRegister(aw88298_i2c_addr, reg, (const std::uint8_t*)&value, 2, 400000);
}
static void es7210_write_reg(std::uint8_t reg, std::uint8_t value)
{
M5.In_I2C.writeRegister(es7210_i2c_addr, reg, &value, 1, 400000);
}
static void initialize_speaker_cores3()
{
M5.In_I2C.bitOn(aw9523_i2c_addr, 0x02, 0b00000100, 400000);
aw88298_write_reg( 0x61, 0x0673 ); // boost mode disabled
aw88298_write_reg( 0x04, 0x4040 ); // I2SEN=1 AMPPD=0 PWDN=0
aw88298_write_reg( 0x05, 0x0008 ); // RMSE=0 HAGCE=0 HDCCE=0 HMUTE=0
aw88298_write_reg( 0x06, 0x14C0 ); // INPLEV=0 (not attenuated), I2SRXEN=1 (enable), CHSEL=01 (left), I2SMD=00 (Philips Standard I2S), I2SFS=00 (16bit), I2SBCK=00 (32*fs), I2SSR=0000 (8kHz)
aw88298_write_reg( 0x0C, 0x0064 ); // volume setting (full volume)
}
static void initialize_microphone_cores3()
{
es7210_write_reg(0x00, 0xFF); // RESET_CTL
struct __attribute__((packed)) reg_data_t
{
uint8_t reg;
uint8_t value;
};
static constexpr reg_data_t data[] =
{
{ 0x00, 0x41 }, // RESET_CTL
{ 0x01, 0x1f }, // CLK_ON_OFF
{ 0x06, 0x00 }, // DIGITAL_PDN
{ 0x07, 0x20 }, // ADC_OSR
{ 0x08, 0x10 }, // MODE_CFG
{ 0x09, 0x30 }, // TCT0_CHPINI
{ 0x0A, 0x30 }, // TCT1_CHPINI
{ 0x20, 0x0a }, // ADC34_HPF2
{ 0x21, 0x2a }, // ADC34_HPF1
{ 0x22, 0x0a }, // ADC12_HPF2
{ 0x23, 0x2a }, // ADC12_HPF1
{ 0x02, 0xC1 },
{ 0x04, 0x01 },
{ 0x05, 0x00 },
{ 0x11, 0x60 },
{ 0x40, 0x42 }, // ANALOG_SYS
{ 0x41, 0x70 }, // MICBIAS12
{ 0x42, 0x70 }, // MICBIAS34
{ 0x43, 0x1B }, // MIC1_GAIN
{ 0x44, 0x1B }, // MIC2_GAIN
{ 0x45, 0x00 }, // MIC3_GAIN
{ 0x46, 0x00 }, // MIC4_GAIN
{ 0x47, 0x00 }, // MIC1_LP
{ 0x48, 0x00 }, // MIC2_LP
{ 0x49, 0x00 }, // MIC3_LP
{ 0x4A, 0x00 }, // MIC4_LP
{ 0x4B, 0x00 }, // MIC12_PDN
{ 0x4C, 0xFF }, // MIC34_PDN
{ 0x01, 0x14 }, // CLK_ON_OFF
};
for (auto& d: data)
{
es7210_write_reg(d.reg, d.value);
}
}
void oai_init_audio_capture() {
ESP_LOGI(TAG, "Initializing microphone");
initialize_microphone_cores3();
ESP_LOGI(TAG, "Initializing speaker");
initialize_speaker_cores3();
...
}
ESP-IDF設定の変更
最後にCoreS3 (SE)向けにESP-IDFの設定を変更します。
CoreS3 (SE) は、フラッシュ・メモリ 16MB、PSRAM 8MBを搭載していますが、これらの接続方法は両方ともQSPI接続となっています。対応するESP-IDFの設定を以下の通り sdkconfig.defaults に設定します。
## For CoreS3
CONFIG_ESPTOOLPY_FLASHMODE_QIO=y
CONFIG_ESPTOOLPY_FLASHSIZE_16MB=y
CONFIG_SPIRAM_MODE_QUAD=y
CONFIG_SPIRAM_SPEED_80M=y
CONFIG_SPIRAM_SPEED=80
CONFIG_FLASHMODE_QIO=y
すでにビルド済みの場合は sdkconfig を削除し再度ビルドすると上記の設定が適用されます。
SPI RAM(PSRAM) は本当に必要か?
サンプルの設定ではESP32-S3に対する外付けのSPI RAMが必要となっています。SPI RAMが必要なほどメモリを使用するのであれば仕方ないのですが、全体のコードを見ている感じではそんなにメモリを使わなさそうに見えました。
そこでSPI RAMを無効化してビルドしたところ、ログ出力上は正常だが対話応答が動かないことが分かりました。
メモリ使用量調査
ESP-IDFの CONFIG_SPIRAM を無効化するとSPI RAMは無効になります。SPI RAM無効時のメモリ使用量をログ出力して調べてみます。
ESP-IDFにはメモリ使用状況を確認するためのいくつかのAPIが実装されています。これらを定期的に呼び出してログ出力するようにします。
まずは定期実行のために esp_timer を使うので、 src/CMakeLists.txt を修正して esp_timer を REQUIRES に追加します。
idf_component_register(
SRCS ${COMMON_SRC} "wifi.cpp" "media.cpp"
REQUIRES driver esp_wifi nvs_flash peer esp_psram esp-libopus esp_http_client esp_timer M5Unified)
次に、 src/main.cpp に定期実行してログ出力する処理を追加します。
#include <esp_timer.h>
#include <esp_heap_caps.h>
#include <M5Unified.h>
constexpr const char* TAG = "main";
#ifdef CONFIG_ENABLE_HEAP_MONITOR
static esp_timer_handle_t s_monitor_timer;
#endif // CONFIG_ENABLE_HEAP_MONITOR
extern "C" void app_main(void) {
esp_err_t ret = nvs_flash_init();
if (ret == ESP_ERR_NVS_NO_FREE_PAGES ||
ret == ESP_ERR_NVS_NEW_VERSION_FOUND) {
ESP_ERROR_CHECK(nvs_flash_erase());
ret = nvs_flash_init();
}
ESP_ERROR_CHECK(ret);
#ifdef CONFIG_ENABLE_HEAP_MONITOR
esp_timer_create_args_t timer_args = {
.callback = [](void* arg) {
ESP_LOGW(TAG, "current heap %7d | minimum ever %7d | largest free %7d ",
xPortGetFreeHeapSize(),
xPortGetMinimumEverFreeHeapSize(),
heap_caps_get_largest_free_block(MALLOC_CAP_DEFAULT));
},
.arg = nullptr,
.dispatch_method = ESP_TIMER_TASK,
.name = "monitor_timer"
};
ESP_ERROR_CHECK(esp_timer_create(&timer_args, &s_monitor_timer));
ESP_ERROR_CHECK(esp_timer_start_periodic(s_monitor_timer, CONFIG_HEAP_MONITOR_INTERVAL_MS * 1000ULL));
#endif // CONFIG_ENABLE_HEAP_MONITOR
auto cfg = M5.config();
cfg.internal_spk = false;
cfg.internal_mic = false;
M5.begin(cfg);
...
}
xPortGetFreeHeapSize で現在のヒープ全体の空きサイズ、 xPortGetMinimumEverFreeHeapSize で起動してから今までで一番ヒープ残量が減ったときのサイズ、 heap_caps_get_largest_free_block(MALLOC_CAP_DEFAULT) で一番大きい空き連続ブロックのサイズを取得し、それぞれログ出力します。
esp_timer_create で設定に従ったタイマーを作成し、 esp_timer_start_periodic で指定した間隔で定期実行します。
ここで出てくる CONFIG_ENABLE_HEAP_MONITOR および CONFIG_HEAP_MONITOR_INTERVAL_MS は、調査時の状況によって変更したいので、ESP-IDFの設定として変更できるように定義ファイル src/Kconfig.projbuild を追加します。
menu "Embedded SDK Configuration"
config ENABLE_HEAP_MONITOR
bool "Enable Heap Monitor"
default n
help
If this option is set (not default),
the heap monitor will be enabled.
config HEAP_MONITOR_INTERVAL_MS
int "Heap Monitor Interval (ms)"
default 1000
depends on ENABLE_HEAP_MONITOR
help
The interval in milliseconds to print the heap monitor.
endmenu
これで idf.py menuconfig を実行すると、Embedded SDK Configuration として設定項目が追加されます。デフォルトでは CONFIG_ENABLE_HEAP_MONITOR は無効化しているので、有効化しておきます。
(Top) → Embedded SDK Configuration
Espressif IoT Development Framework Configuration
[*] Enable Heap Monitor
(1000) Heap Monitor Interval (ms)
この状態で実行すると、WiFi接続完了後、HTTPSでのリクエスト送信時に minimum ever が2kB台まで低下し、場合によってはメモリ確保に失敗してpanicすることが分かりました。
サンプルでは起動後OpenAIのサーバーとのWebRTCセッション確立のための初回のみHTTPS通信を行い、それ以降はWebRTCのセッションのみ維持しているので、瞬間的な同時メモリ使用量を減らすことができれば動くのではないかと考えられます。
そこでいくつか既存の設定を見直したところ、ESP-IDFのWiFiドライバの送信バッファがWiFiドライバ初期化時に静的確保される設定になっていたため、動的確保するように変更しました。[1]
また、libpeerがスタックを大量に消費するためメインタスクのスタックサイズが16kBになっていましたが、10kBでも動くようなので減らしています。
# libpeer requires large stack allocations
CONFIG_ESP_MAIN_TASK_STACK_SIZE=10240
...
CONFIG_ESP_WIFI_DYNAMIC_TX_BUFFER=y
これで再度実行したところ、 minimum everは10kB台までしか減らなくなりましたがそれでもログ出力にはエラーが見られれないにもかかわらず、対話応答は動きませんでした。
音声処理タスク生成処理の修正
どこかにエラー処理を握りつぶしている、もしくは適切なエラー処理をしていない箇所があるのではと思い、まずは音声入出力まわりを調査したところ、 src/webrtc.cpp でマイク入力タスクを起動する処理でSPI RAMがあることを前提とした実装を見つけました。
マイク入力タスクのスタックとしてSPI RAMからメモリを確保しタスクを起動しようとしますが、当然SPI RAMが無い場合はメモリの確保に失敗し nullptr が返ります。
その際の戻り値を確認せず xTaskCreateStaticPinnedToCore を呼び出しているため、マイク入力タスクが動いていない状態です。
StackType_t *stack_memory = (StackType_t *)heap_caps_malloc(
20000 * sizeof(StackType_t), MALLOC_CAP_SPIRAM);
xTaskCreateStaticPinnedToCore(oai_send_audio_task, "audio_publisher", 20000,
NULL, 7, stack_memory, &task_buffer, 0);
対策として、SPI RAMが無効の場合は普通に内蔵RAMからメモリを確保するようにします。またメモリ確保に失敗したら再起動するようにします。
#ifdef CONFIG_SPIRAM
constexpr size_t stack_size = 20000;
StackType_t *stack_memory = (StackType_t *)heap_caps_malloc(
stack_size * sizeof(StackType_t), MALLOC_CAP_SPIRAM);
#else // CONFIG_SPIRAM
constexpr size_t stack_size = 20000;
StackType_t *stack_memory = (StackType_t *)malloc(stack_size * sizeof(StackType_t));
#endif // CONFIG_SPIRAM
if (stack_memory == nullptr) {
ESP_LOGE(LOG_TAG, "Failed to allocate stack memory for audio publisher.");
esp_restart();
}
xTaskCreateStaticPinnedToCore(oai_send_audio_task, "audio_publisher", stack_size,
NULL, 7, stack_memory, &task_buffer, 0);
これで動作確認をしたところ、SPI RAM無効でも対話応答が動くようになりました。
動作確認
CoreS3 SEに書き込んで動かしたときの動画は次の通りです。
応答速度がとても速く、普通に会話できるレベルですが、CoreS3 SEのマイクとスピーカーが近いからか、OpenAI Realtime API側の発話内容を入力として拾ってしまい、発話中によくわからない応答を始めてしまっています。
このあたりは適切なマスク処理などを追加する必要がありそうです。
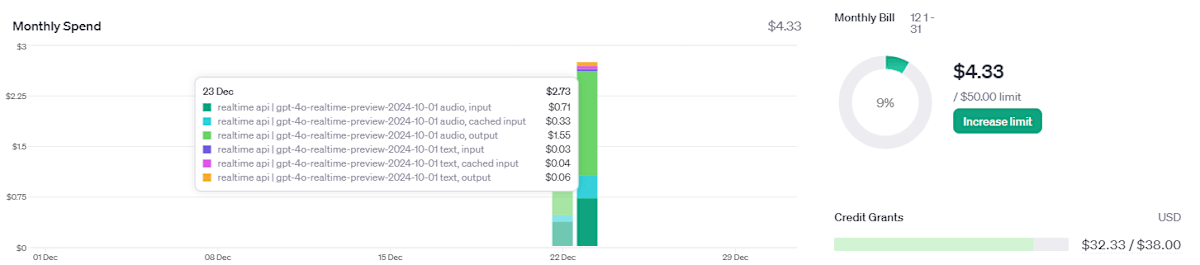
なお、ここまでのデバッグで使ったAPI利用料は $4.33 でした。合計20分も使ってないとおもいますが、なかなか高コストなので使いどころは考える必要がありそうです。
修正版のコード
修正版のコードは筆者のGitHubリポジトリにfork版として公開しています。 https://github.com/ciniml/openai-realtime-embedded-sdk/tree/m5stack
SPI RAM無しで動かす調整に関してはPRを投げる予定です。 https://github.com/ciniml/openai-realtime-embedded-sdk/tree/no_psram
-
この辺の調整は、筆者がファームウェア開発を担当している Nature Remo nano や Nature Remo Lapis の開発時に結構調整したので、いろいろ知見が貯まっていたので手始めに試してみてうまく行きました。 ↩︎
Discussion