概要
この記事を読む対象者: Snowflakeを利用しており、新機能「Cortex Analyst」に興味がある技術者やデータ分析者。
この記事の内容: Snowflake Cortex Analystの仕組みと利用するための具体的な技術的手順を解説します。
この記事を読むとわかること: 自然言語による質問を通じてSQLを書かずにデータ分析ができるCortex Analystの活用方法が理解できます。
序説
Text2SQLという技術をご存じでしょうか?
Text2SQLとは、自然言語(テキスト)からSQLクエリを生成する技術やシステムのことを指します。従来、データベースへのアクセスにはSQLという専門的なスキルが必要でしたが、Text2SQLの登場により、ビジネスユーザーや非技術者でも簡単にデータにアクセスし、分析を行うことが可能になりました。
本記事では、そんなText2SQL技術を活用したSnowflakeの革新的なサービス「Cortex Analyst」について詳しく紹介します。
Cortex Analyst
Cortex Analystとは
Cortex Analystはご存知でしょうか?
Cortex Analystは、Snowflake Cortexの機能の一部で、構造化データに基づいてビジネス質問に答えるアプリケーションを作成するための完全管理型のLLM(大規模言語モデル)駆動のツールです。
自然言語で質問を行い、SQLを書くことなく直接回答を得ることができるのが特徴です
全体像

1. ユーザーの質問をアプリケーションから送信
ユーザーはアプリケーションを通じて自然言語で質問を行います。この質問はREST APIを介してCortex Analystに送信されます。
2. 質問の理解
Cortex Analystは、受け取った質問を理解し、分類、強化、抽出を行います。セマンティックモデルを使用して、質問に関連する追加の情報を付加し、解答可能な形式に変換します。
3. SQLの生成
質問の理解が完了した後、Cortex Analystは質問を解釈し、適切なSQLクエリを生成します。このSQLクエリは、質問の意図を正確に反映するように生成、修正、統合されます。
4. SQLクエリの実行と回答の返却
生成されたSQLクエリは、顧客のデータベースおよびウェアハウスで実行されます。実行結果はアプリケーションに返され、ユーザーに回答が提供されます。
このプロセスにより、ユーザーは自然言語で質問を行い、SQLを書くことなくデータにアクセスし、分析を行うことができます。
手順
1. データの用意
データの用意を行います。
今回は、ダミーで売上データ、商品データ、地域データを用意しました。
以下のpythonコードよりダミーデータを用意しました。
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
# 日付範囲の生成
start_date = datetime(2023, 1, 1)
end_date = datetime(2024, 12, 31)
dates = pd.date_range(start=start_date, end=end_date, freq='D')
# 基本となる売上データの生成
def generate_base_revenue(dates):
np.random.seed(42) # 再現性のため
n_days = len(dates)
# トレンドと季節性を持つ基本売上の生成
trend = np.linspace(0, 20000, n_days) # 上昇トレンド
seasonality = 10000 * np.sin(np.linspace(0, 4*np.pi, n_days)) # 季節性
noise = np.random.normal(0, 5000, n_days) # ランダムノイズ
base_revenue = 100000 + trend + seasonality + noise
return np.maximum(base_revenue, 50000) # 最小値を設定
# 1. daily_revenue.csv の生成
base_revenue = generate_base_revenue(dates)
daily_revenue_df = pd.DataFrame({
'date': dates.strftime('%Y-%m-%d'),
'revenue': base_revenue,
'cogs': base_revenue * np.random.uniform(0.4, 0.6, len(dates)),
'forecasted_revenue': base_revenue * np.random.uniform(0.8, 1.2, len(dates))
})
# 2. daily_revenue_by_product.csv の生成
products = ['Premium', 'Standard', 'Basic', 'Enterprise']
product_weights = {
'Premium': 0.35,
'Standard': 0.30,
'Basic': 0.20,
'Enterprise': 0.15
}
product_data = []
for date, revenue in zip(dates, base_revenue):
for product in products:
product_revenue = revenue * product_weights[product] * np.random.uniform(0.9, 1.1)
product_data.append({
'date': date.strftime('%Y-%m-%d'),
'product_line': product,
'revenue': product_revenue,
'cogs': product_revenue * np.random.uniform(0.4, 0.6),
'forecasted_revenue': product_revenue * np.random.uniform(0.8, 1.2)
})
daily_revenue_by_product_df = pd.DataFrame(product_data)
# 3. daily_revenue_by_region.csv の生成
regions = ['North America', 'Europe', 'Asia Pacific', 'Latin America']
region_weights = {
'North America': 0.40,
'Europe': 0.30,
'Asia Pacific': 0.20,
'Latin America': 0.10
}
region_data = []
for date, revenue in zip(dates, base_revenue):
for region in regions:
region_revenue = revenue * region_weights[region] * np.random.uniform(0.9, 1.1)
region_data.append({
'date': date.strftime('%Y-%m-%d'),
'sales_region': region,
'revenue': region_revenue,
'cogs': region_revenue * np.random.uniform(0.4, 0.6),
'forecasted_revenue': region_revenue * np.random.uniform(0.8, 1.2)
})
daily_revenue_by_region_df = pd.DataFrame(region_data)
# 数値を2桁に丸める
for df in [daily_revenue_df, daily_revenue_by_product_df, daily_revenue_by_region_df]:
for col in ['revenue', 'cogs', 'forecasted_revenue']:
df[col] = df[col].round(2)
# CSVファイルとして保存
daily_revenue_df.to_csv('daily_revenue.csv', index=False)
daily_revenue_by_product_df.to_csv('daily_revenue_by_product.csv', index=False)
daily_revenue_by_region_df.to_csv('daily_revenue_by_region.csv', index=False)
# サンプルデータの表示(最初の数行)
print("daily_revenue.csv の最初の3行:")
print(daily_revenue_df.head(3).to_string())
print("\ndaily_revenue_by_product.csv の最初の3行:")
print(daily_revenue_by_product_df.head(3).to_string())
print("\ndaily_revenue_by_region.csv の最初の3行:")
print(daily_revenue_by_region_df.head(3).to_string())
SnowflakeDBの用意
先ほど作成したcsvファイルをSnoflakeのDBにロードします。
まず、Snowsightを開き、Schema, Tableを作成します。
以下のコードを実行します。
<YOUR_WH_NAME>や<YOUR_DB_NAME>は書き換えてください。
CREATE OR REPLACE SCHEMA revenue_timeseries;
USE WAREHOUSE <YOUR_WH_NAME>;
CREATE STAGE raw_data DIRECTORY = (ENABLE = TRUE);
CREATE OR REPLACE TABLE <YOUR_DB_NAME>.REVENUE_TIMESERIES.DAILY_REVENUE (
DATE DATE,
REVENUE FLOAT,
COGS FLOAT,
FORECASTED_REVENUE FLOAT
);
CREATE OR REPLACE TABLE
<YOUR_DB_NAME>.REVENUE_TIMESERIES.DAILY_REVENUE_BY_PRODUCT (
DATE DATE,
PRODUCT_LINE VARCHAR(16777216),
REVENUE FLOAT,
COGS FLOAT,
FORECASTED_REVENUE FLOAT
);
CREATE OR REPLACE TABLE <YOUR_DB_NAME>.REVENUE_TIMESERIES.DAILY_REVENUE_BY_REGION (
DATE DATE,
SALES_REGION VARCHAR(16777216),
REVENUE FLOAT,
COGS FLOAT,
FORECASTED_REVENUE FLOAT
);
次にcsvファイルをアップロードします。
左のナビゲーションバーのDataをクリックします。
そして、Add Dataをクリックします。
次にLoad into the Stageをクリックします。
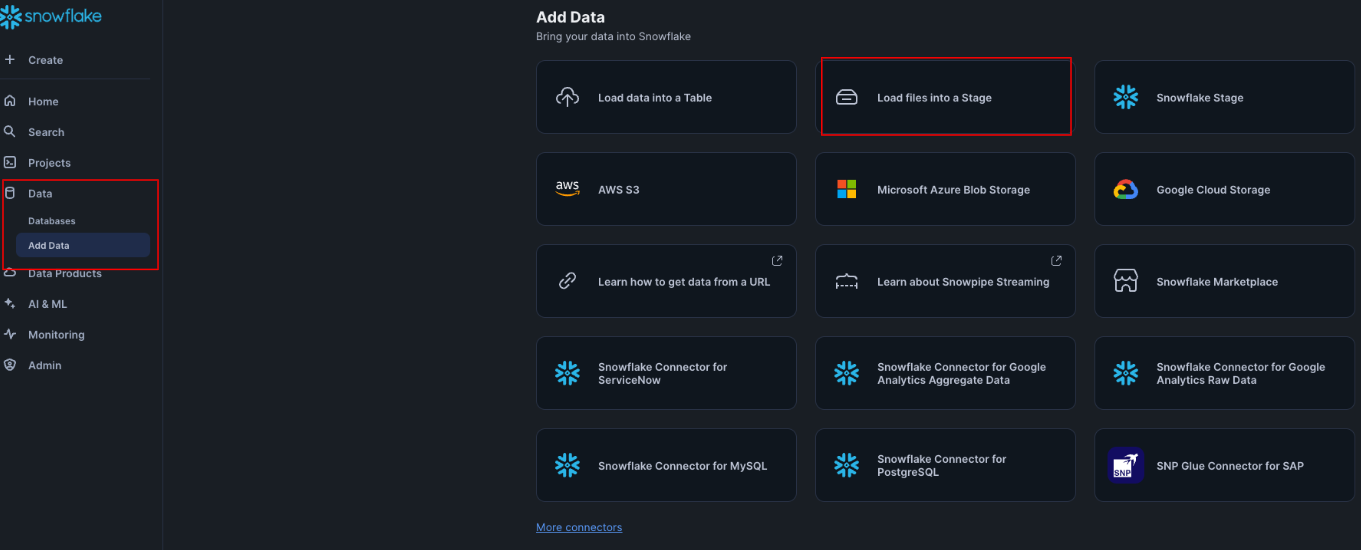
そして、先ほど作成したファイルをアップロードします。
DBは、<YOUR_DB_NAME>でスキーマはrevenue_timeseriesを選択します。

そして、ステージに上げたデータをtableにコピーします。
コピーできたかselect文で確認し、データが表示されれば成功です。
COPY INTO <YOUR_DB_NAME>.REVENUE_TIMESERIES.DAILY_REVENUE
FROM @raw_data
FILES = ('daily_revenue_combined.csv')
FILE_FORMAT = (
TYPE=CSV,
SKIP_HEADER=1,
FIELD_DELIMITER=',',
TRIM_SPACE=FALSE,
FIELD_OPTIONALLY_ENCLOSED_BY=NONE,
REPLACE_INVALID_CHARACTERS=TRUE,
DATE_FORMAT=AUTO,
TIME_FORMAT=AUTO,
TIMESTAMP_FORMAT=AUTO
EMPTY_FIELD_AS_NULL = FALSE
error_on_column_count_mismatch=false
)
ON_ERROR=CONTINUE
FORCE = TRUE ;
COPY INTO <YOUR_DB_NAME>.REVENUE_TIMESERIES.DAILY_REVENUE_BY_PRODUCT
FROM @raw_data
FILES = ('daily_revenue_by_product_combined.csv')
FILE_FORMAT = (
TYPE=CSV,
SKIP_HEADER=1,
FIELD_DELIMITER=',',
TRIM_SPACE=FALSE,
FIELD_OPTIONALLY_ENCLOSED_BY=NONE,
REPLACE_INVALID_CHARACTERS=TRUE,
DATE_FORMAT=AUTO,
TIME_FORMAT=AUTO,
TIMESTAMP_FORMAT=AUTO
EMPTY_FIELD_AS_NULL = FALSE
error_on_column_count_mismatch=false
)
ON_ERROR=CONTINUE
FORCE = TRUE ;
COPY INTO <YOUR_DB_NAME>.REVENUE_TIMESERIES.DAILY_REVENUE_BY_REGION
FROM @raw_data
FILES = ('daily_revenue_by_region_combined.csv')
FILE_FORMAT = (
TYPE=CSV,
SKIP_HEADER=1,
FIELD_DELIMITER=',',
TRIM_SPACE=FALSE,
FIELD_OPTIONALLY_ENCLOSED_BY=NONE,
REPLACE_INVALID_CHARACTERS=TRUE,
DATE_FORMAT=AUTO,
TIME_FORMAT=AUTO,
TIMESTAMP_FORMAT=AUTO
EMPTY_FIELD_AS_NULL = FALSE
error_on_column_count_mismatch=false
)
ON_ERROR=CONTINUE
FORCE = TRUE ;
SELECT * FROM DAILY_REVENUE;
SELECT * FROM DAILY_REVENUE_BY_PRODUCT;
SELECT * FROM DAILY_REVENUE_BY_REGION;
SemanticModelの作成
Semantic Modelを作成します。
セマンティックモデルは メタデータ のようなもので、
テーブルの名前、カラムの情報、サンプルデータなどを保持しています。
事前にyamlファイルを作成する必要があるのですが、
これを自動で作成するツールもあります。
上記のツールなど利用し、今回は以下のyamlファイルを作成しました。
name: revenue_timeseries
tables:
- name: DAILY_REVENUE
description: This table stores daily revenue data, including the date, actual
revenue, cost of goods sold (COGS), and forecasted revenue for a business.__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
base_table:
database: <YOUR_DB_NAME>
schema: REVENUE_TIMESERIES
table: DAILY_REVENUE
# filters:
# - name: ' ' # <FILL-OUT>
# synonyms:
# - ' ' # <FILL-OUT>
# description: ' ' # <FILL-OUT>
# expr: ' ' # <FILL-OUT>
time_dimensions:
- name: DATE
synonyms:
- ' ' # <FILL-OUT>
description: Date of daily revenue transactions.__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
expr: DATE
data_type: DATE
sample_values:
- '2023-01-01'
- '2023-01-02'
- '2023-01-03'
measures:
- name: REVENUE
synonyms:
- ' ' # <FILL-OUT>
description: Daily Revenue__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
expr: REVENUE
data_type: FLOAT
sample_values:
- '102483.57'
- '99508.21'
- '103637.45'
- name: COGS
synonyms:
- ' ' # <FILL-OUT>
description: Cost of Goods Sold (COGS)__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
expr: COGS
data_type: FLOAT
sample_values:
- '46610.66'
- '50832.34'
- '54957.29'
- name: FORECASTED_REVENUE
synonyms:
- ' ' # <FILL-OUT>
description: Forecasted Revenue__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
expr: FORECASTED_REVENUE
data_type: FLOAT
sample_values:
- '117978.03'
- '114158.07'
- '116319.59'
- name: DAILY_REVENUE_BY_PRODUCT
description: This table stores daily revenue data by product line, including actual
revenue, cost of goods sold (COGS), and forecasted revenue, providing insights
into the financial performance of individual products over time.__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
base_table:
database: <YOUR_DB_NAME>
schema: REVENUE_TIMESERIES
table: DAILY_REVENUE_BY_PRODUCT
# filters:
# - name: ' ' # <FILL-OUT>
# synonyms:
# - ' ' # <FILL-OUT>
# description: ' ' # <FILL-OUT>
# expr: ' ' # <FILL-OUT>
dimensions:
- name: PRODUCT_LINE
synonyms:
- ' ' # <FILL-OUT>
description: Product Line__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
expr: PRODUCT_LINE
data_type: TEXT
sample_values:
- Premium
- Standard
- Basic
time_dimensions:
- name: DATE
synonyms:
- ' ' # <FILL-OUT>
description: Date of daily revenue records.__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
expr: DATE
data_type: DATE
sample_values:
- '2023-01-01'
- '2023-01-02'
- '2023-01-03'
measures:
- name: REVENUE
synonyms:
- ' ' # <FILL-OUT>
description: Daily Revenue by Product__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
expr: REVENUE
data_type: FLOAT
sample_values:
- '35220.94'
- '31395.51'
- '22497.34'
- name: COGS
synonyms:
- ' ' # <FILL-OUT>
description: Cost of Goods Sold (COGS)__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
expr: COGS
data_type: FLOAT
sample_values:
- '16280.65'
- '14847.52'
- '11041.7'
- name: FORECASTED_REVENUE
synonyms:
- ' ' # <FILL-OUT>
description: Forecasted Revenue by Product__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
expr: FORECASTED_REVENUE
data_type: FLOAT
sample_values:
- '37716.28'
- '27852.75'
- '24191.61'
- name: DAILY_REVENUE_BY_REGION
description: This table stores daily revenue data by region, including actual
sales revenue, cost of goods sold (COGS), and forecasted revenue for each region.__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
base_table:
database: <YOUR_DB_NAME>
schema: REVENUE_TIMESERIES
table: DAILY_REVENUE_BY_REGION
# filters:
# - name: ' ' # <FILL-OUT>
# synonyms:
# - ' ' # <FILL-OUT>
# description: ' ' # <FILL-OUT>
# expr: ' ' # <FILL-OUT>
dimensions:
- name: SALES_REGION
synonyms:
- ' ' # <FILL-OUT>
description: Geographic region where sales were generated.__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
expr: SALES_REGION
data_type: TEXT
sample_values:
- North America
- Europe
- Asia Pacific
time_dimensions:
- name: DATE
synonyms:
- ' ' # <FILL-OUT>
description: Date of daily revenue records by region.__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
expr: DATE
data_type: DATE
sample_values:
- '2023-01-01'
- '2023-01-02'
- '2023-01-03'
measures:
- name: REVENUE
synonyms:
- ' ' # <FILL-OUT>
description: Daily Revenue by Region__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
expr: REVENUE
data_type: FLOAT
sample_values:
- '44604.14'
- '33677.97'
- '21414.16'
- name: COGS
synonyms:
- ' ' # <FILL-OUT>
description: Cost of Goods Sold (COGS)__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
expr: COGS
data_type: FLOAT
sample_values:
- '22788.37'
- '17796.31'
- '12443.63'
- name: FORECASTED_REVENUE
synonyms:
- ' ' # <FILL-OUT>
description: Forecasted Daily Revenue by Region__ # <AUTO-GENERATED DESCRIPTION, PLEASE MODIFY AND REMOVE THE __ AT THE END>
expr: FORECASTED_REVENUE
data_type: FLOAT
sample_values:
- '46392.21'
- '27357.11'
- '23946.0'
このファイルをrevenue_timeseries.yamlとし、
先ほどのcsvと同様にstageにアップロードします。
appの作成
最後にstreamlitを用いてappを作成します。
まず、.envファイルを作成し、環境変数を設定します。
DATABASE="<YOUR_DB_NAME>"
SCHEMA="REVENUE_TIMESERIES"
STAGE="RAW_DATA"
FILE="revenue_timeseries.yaml"
WAREHOUSE="<YOUR_WH_NAME>"
# replace values below with your Snowflake connection information
HOST="<YOUR_ACCOUNT_NAME>.snowflakecomputing.com"
ACCOUNT="<YOUR_ACCOUNT_NAME>"
USER="<YOUR _EMAIL>"
PASSWORD="<PASSWORD>"
ROLE="SYSADMIN"
次にanalysis_demo.pyを作成し、アプリを作成します。
from typing import Any, Dict, List, Optional
import pandas as pd
import requests
import snowflake.connector
import streamlit as st
import os
from dotenv import load_dotenv
load_dotenv()
DATABASE = os.getenv("DATABASE")
SCHEMA = os.getenv("SCHEMA")
STAGE = os.getenv("STAGE")
FILE = os.getenv("FILE")
WAREHOUSE = os.getenv("WAREHOUSE")
# replace values below with your Snowflake connection information
HOST = os.getenv("HOST")
ACCOUNT = os.getenv("ACCOUNT")
USER = os.getenv("USER")
PASSWORD = os.getenv("PASSWORD")
ROLE = os.getenv("ROLE")
if 'CONN' not in st.session_state or st.session_state.CONN is None:
st.session_state.CONN = snowflake.connector.connect(
user=USER,
password=PASSWORD,
account=ACCOUNT,
host=HOST,
port=443,
warehouse=WAREHOUSE,
role=ROLE,
)
def send_message(prompt: str) -> Dict[str, Any]:
"""Calls the REST API and returns the response."""
request_body = {
"messages": [{"role": "user", "content": [{"type": "text", "text": prompt}]}],
"semantic_model_file": f"@{DATABASE}.{SCHEMA}.{STAGE}/{FILE}",
}
resp = requests.post(
url=f"https://{HOST}/api/v2/cortex/analyst/message",
json=request_body,
headers={
"Authorization": f'Snowflake Token="{st.session_state.CONN.rest.token}"',
"Content-Type": "application/json",
},
)
request_id = resp.headers.get("X-Snowflake-Request-Id")
if resp.status_code < 400:
return {**resp.json(), "request_id": request_id} # type: ignore[arg-type]
else:
raise Exception(
f"Failed request (id: {request_id}) with status {resp.status_code}: {resp.text}"
)
def process_message(prompt: str) -> None:
"""Processes a message and adds the response to the chat."""
st.session_state.messages.append(
{"role": "user", "content": [{"type": "text", "text": prompt}]}
)
with st.chat_message("user"):
st.markdown(prompt)
with st.chat_message("assistant"):
with st.spinner("Generating response..."):
response = send_message(prompt=prompt)
request_id = response["request_id"]
content = response["message"]["content"]
display_content(content=content, request_id=request_id) # type: ignore[arg-type]
st.session_state.messages.append(
{"role": "assistant", "content": content, "request_id": request_id}
)
def display_content(
content: List[Dict[str, str]],
request_id: Optional[str] = None,
message_index: Optional[int] = None,
) -> None:
"""Displays a content item for a message."""
message_index = message_index or len(st.session_state.messages)
if request_id:
with st.expander("Request ID", expanded=False):
st.markdown(request_id)
for item in content:
if item["type"] == "text":
st.markdown(item["text"])
elif item["type"] == "suggestions":
with st.expander("Suggestions", expanded=True):
for suggestion_index, suggestion in enumerate(item["suggestions"]):
if st.button(suggestion, key=f"{message_index}_{suggestion_index}"):
st.session_state.active_suggestion = suggestion
elif item["type"] == "sql":
with st.expander("SQL Query", expanded=False):
st.code(item["statement"], language="sql")
with st.expander("Results", expanded=True):
with st.spinner("Running SQL..."):
df = pd.read_sql(item["statement"], st.session_state.CONN)
if len(df.index) > 1:
data_tab, line_tab, bar_tab = st.tabs(
["Data", "Line Chart", "Bar Chart"]
)
data_tab.dataframe(df)
if len(df.columns) > 1:
df = df.set_index(df.columns[0])
with line_tab:
st.line_chart(df)
with bar_tab:
st.bar_chart(df)
else:
st.dataframe(df)
st.title("Cortex Analyst")
st.markdown(f"Semantic Model: `{FILE}`")
if "messages" not in st.session_state:
st.session_state.messages = []
st.session_state.suggestions = []
st.session_state.active_suggestion = None
for message_index, message in enumerate(st.session_state.messages):
with st.chat_message(message["role"]):
display_content(
content=message["content"],
request_id=message.get("request_id"),
message_index=message_index,
)
if user_input := st.chat_input("What is your question?"):
process_message(prompt=user_input)
if st.session_state.active_suggestion:
process_message(prompt=st.session_state.active_suggestion)
st.session_state.active_suggestion = None
最後に以下のコマンドでstreamlitを起動します。
streamlit run analysis_demo.py
自然言語の質問に対してデータベースの内容を教えてくれます。

sqlを使用して、クエリの結果を表示してくれます。

日本語で返答してくださいと加えると、日本語で返してくれる時もありました。

日本語で返答してくださいと加えても、英語の場合もあり、返答の言語は基本英語みたいです。

結言
Cortex Analystすごい!と思うと同時に
どんどんエンジニアの仕事は減っていくんだろうなという未来が見えてきました。
まだ、SemanticModelを作る部分に手間や、細かなSQLや、エラー時の対応など細かなところでは人間は必要だと思いますが、大体の質問は答えられるのではと思いました。
こういう面倒なところをAIに任せて、もっと創造的な部分をできる人になりたいなああ!
参考記事

Discussion