こんばんわ、がく@ちゅらデータエンジニアです。
さてさて、12月にアドベントカレンダーで燃え尽きて、はや2ヶ月・・・そろそろブログも再開していこうと思います。
※完成した対策の記事を誤って空記事で上書いてしまって全部消えて。。。。
失意のあまり、インフルに掛かって2週間ほどぶっ倒れていたなんて言えない
(たまたまインフルにかかっただけで、寝込み正月だったorz)
Cortex Searchとは
早速ChatGPTに聞いてみましょう
- Snowflake Cortex Searchは、Snowflakeが提供するフルマネージド型のハイブリッド検索サービスで、非構造化データやドキュメントに対する高品質な「ファジー」検索を低レイテンシーで実現
- ベクトル検索とキーワード検索を組み合わせたハイブリッド検索を提供し、検索拡張生成(RAG)アプリケーションやエンタープライズ検索が可能
- データの取り込み、埋め込み、インデックス作成、検索、リランキングといったプロセスが自動化されている
- ただし、画像内のテキスト抽出やPDFの内容検索を行う際には、事前に適切なテキスト抽出処理を行い、データベースに取り込む必要がある
といったことで、RAGを構成するのに色々と用意されてて使いやすいですよー
Snowflakeの資産(認証認可などのセキュリティ・ガバナンス)を使いませわますよーー
って感じですね
こちらにCortex Searchのチュートリアルが3つ出ているので、こちらをやってどんなものかを体感していきたいと思います
チュートリアル
チュートリアル1:Cortex Searchで簡単な検索アプリケーションを構築する
Step1: 設定する
ここでは、このチュートリアルをやるデータベースと仮想ウェアハウスを作ります。
サンプルデータを取得する
Huggingfaceでホストされるサンプルデータを使用し・・・・と記載していますが、AirBnBのリンクがリンクデッドになっている・・・
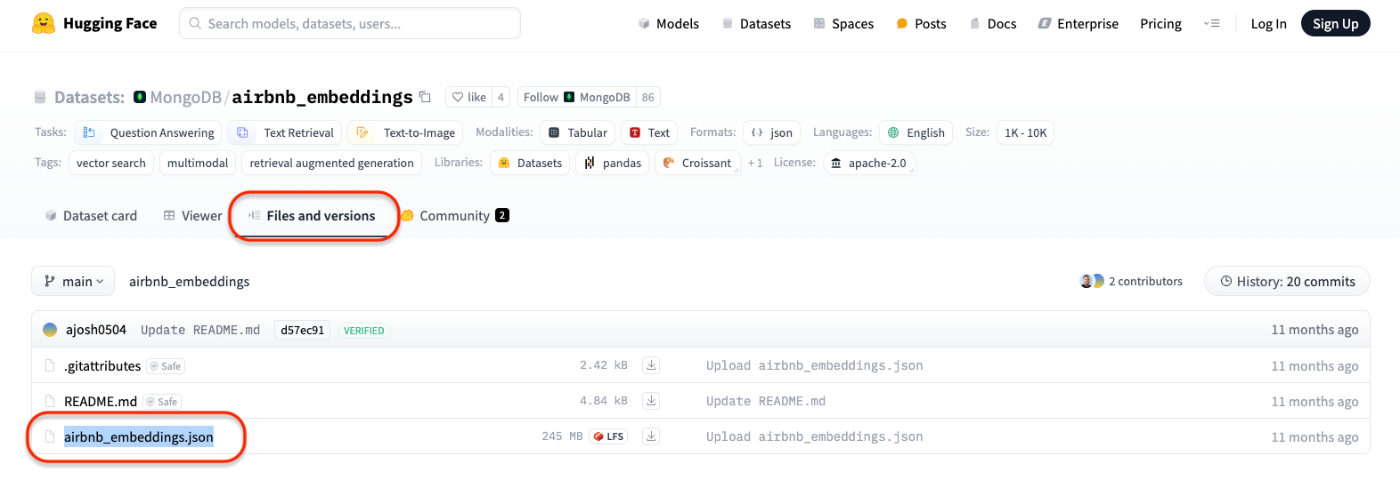
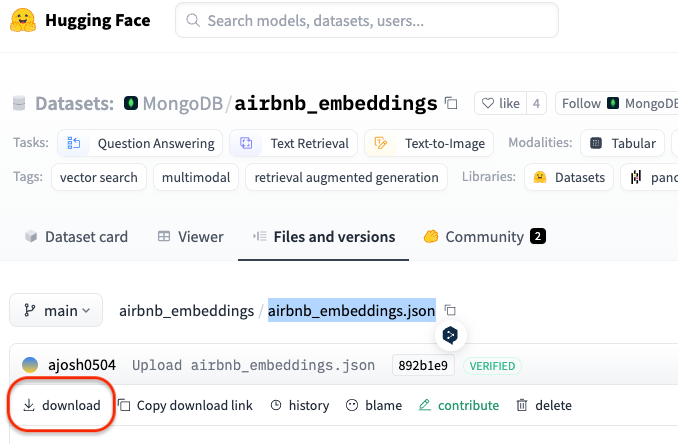
こちらのdownloadボタンをクリックすると、ファイルがダウンロードできます

Step2: データをSnowflakeにロードする
色々やり方はあるけど、このチュートリアルではGUI(Snowsight)から、先程取得した airbnb_embeddings.json をテーブルにロードします。
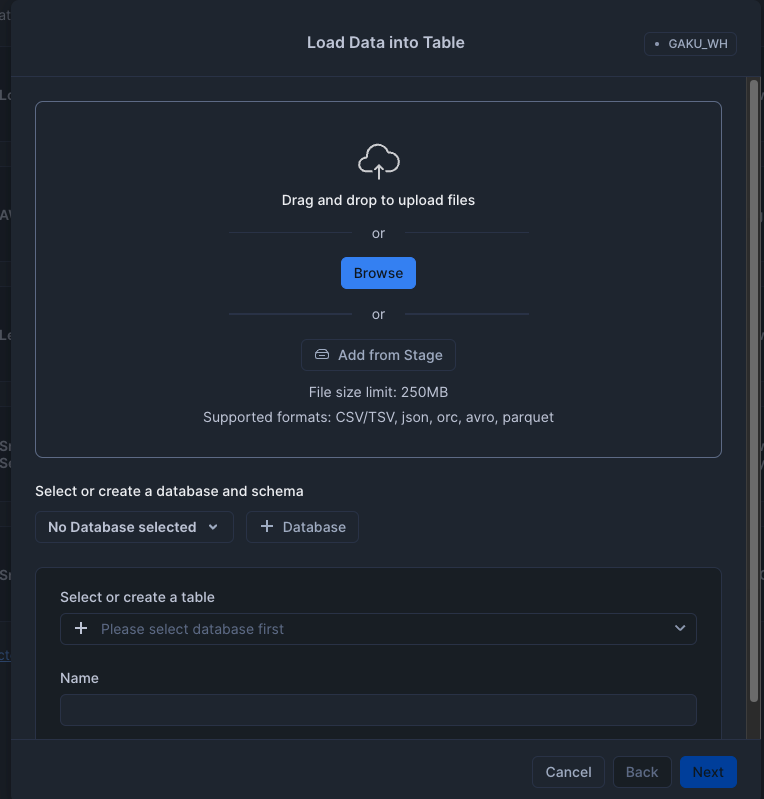
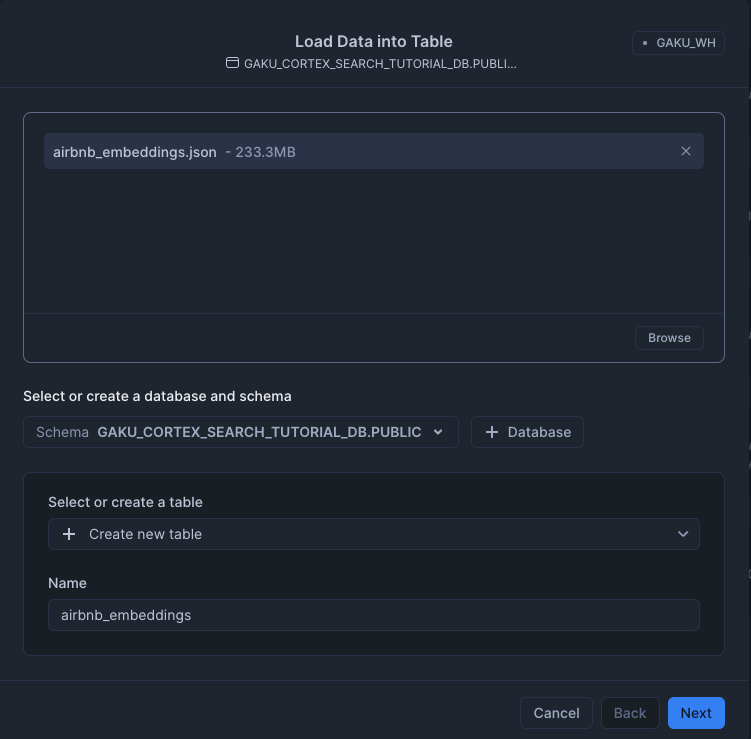
- airbnb_embeddings.jsonファイルを選び、
- DatabaseとSchemaを選択:GAKU_CORTEX_SEARCH_TUTRIAL_DB.PUBLIC
- +Create new table として、
- テーブル名は、「airbnb_embedinngs」
Nextボタンをクリック
Load Data into Tableで取り込むカラムを調整
(チュートリアルと違うのは)
Load as a single variant column? のチェックを外す
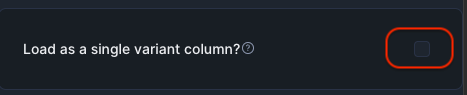
こうすることで、Edit Schemaが選択できるようになる
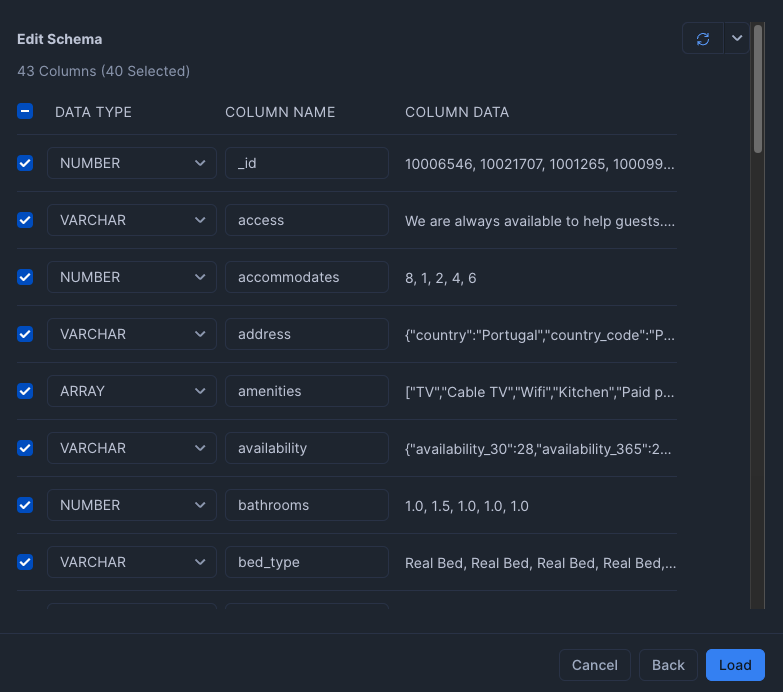
こんな感じでJSONの解析をして取り込める
- amenities を ARRAY型に変更
- image_embeddings, images, text_embeddings のチェックを外す

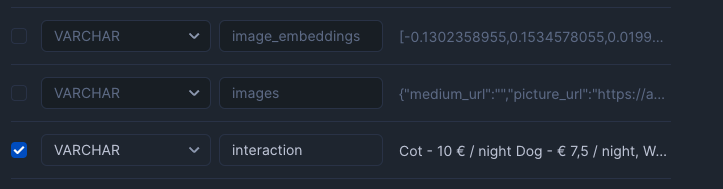
しばらくすると取り込み成功の画面になるので、Query Data をクリックする。

ステップ3: 検索サービスを作成する

ちゃんとSnowsightのタグ名(画像上部)を「Cortex Search Tutorial Step3」とつけることを忘れない(キリッ
※2025-02-26 10:30:00 とかのままにしないっ
SELECT
*
FROM
"GAKU_CORTEX_SEARCH_TUTORIAL_DB"."PUBLIC"."AIRBNB_LISTINGS"
LIMIT
10;
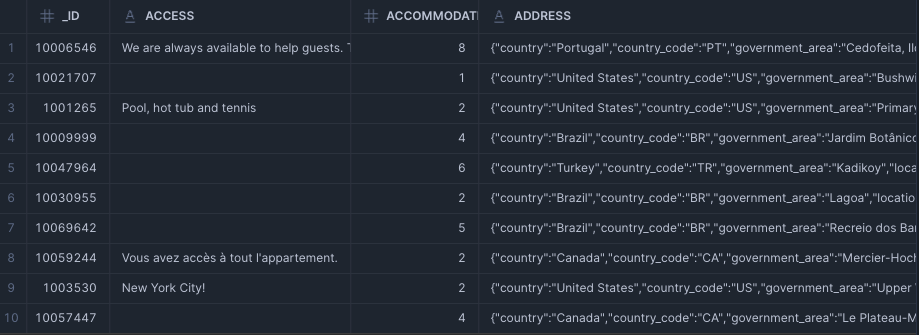
こんな感じに取り込まれている
CREATE OR REPLACE CORTEX SEARCH SERVICE gaku_cortex_search_tutorial_db.public.airbnb_svc
ON listing_text
ATTRIBUTES room_type, amenities
WAREHOUSE = gaku_cortex_search_tutorial_wh
TARGET_LAG = '1 hour'
AS
SELECT
room_type,
amenities,
price,
cancellation_policy,
('Summary\n\n' || summary || '\n\n\nDescription\n\n' || description || '\n\n\nSpace\n\n' || space) as listing_text
FROM
gaku_cortex_search_tutorial_db.public.airbnb_listings;
22s(ウェアハウスサイズ:X-Small)で、

CORTEX SEARCH SERVICE である、AIRBNB_SVCが作成成功
パラメータの解説
- ON listing_text : ON は、検索する列を示す。
- この例では「('Summary\n\n' || summary || '\n\n\nDescription\n\n' || description || '\n\n\nSpace\n\n' || space) as listing_text」
- ATTROBUTES room_type, amenities
- 検索結果をフィルターする列を指定
- WAREHOUSE、TARGET_LAG = '1 hour'
- どのウェアハウスを使うかと、検索サービスの鮮度(この場合は1時間以内)を指定する
- AS : CORTEX SERCH SERVICEのソーステーブルを定義する。
- この場合、複数のフィールドを検索できるように元テーブル(airbnb_listings)の複数のカラム(summary、description、space)連結して、listing_text にしている
ステップ4: Streamlitアプリを作成する
Projects(左の柱メニュー)→ Streamlit → +Streamlit App をクリック

適宜入力をしてCreate

左ペインに、サンプルアプリケーションのコードを貼り付ける
サンプルアプリケーションのコード
Import python packages
import streamlit as st
from snowflake.core import Root
from snowflake.snowpark.context import get_active_session
Constants
DB = "gaku_cortex_search_tutorial_db"
SCHEMA = "public"
SERVICE = "airbnb_svc"
BASE_TABLE = "gaku_cortex_search_tutorial_db.public.airbnb_listings"
ARRAY_ATTRIBUTES = {"AMENITIES"}
def get_column_specification():
"""
Returns the name of the search column and a list of the names of the attribute columns
for the provided cortex search service
"""
session = get_active_session()
search_service_result = session.sql(f"DESC CORTEX SEARCH SERVICE {DB}.{SCHEMA}.{SERVICE}").collect()[0]
st.session_state.attribute_columns = search_service_result.attribute_columns.split(",")
st.session_state.search_column = search_service_result.search_column
st.session_state.columns = search_service_result.columns.split(",")
def init_layout():
st.title("Cortex AI Search")
st.markdown(f"Querying service: {DB}.{SCHEMA}.{SERVICE}".replace('"', ''))
def query_cortex_search_service(query, filter={}):
"""
Queries the cortex search service in the session state and returns a list of results
"""
session = get_active_session()
cortex_search_service = (
Root(session)
.databases[DB]
.schemas[SCHEMA]
.cortex_search_services[SERVICE]
)
context_documents = cortex_search_service.search(
query,
columns=st.session_state.columns,
filter=filter,
limit=st.session_state.limit)
return context_documents.results
@st.cache_data
def distinct_values_for_attribute(col_name, is_array_attribute=False):
session = get_active_session()
if is_array_attribute:
values = session.sql(f'''
SELECT DISTINCT value FROM {BASE_TABLE},
LATERAL FLATTEN(input => {col_name})
''').collect()
else:
values = session.sql(f"SELECT DISTINCT {col_name} AS VALUE FROM {BASE_TABLE}").collect()
return [ x["VALUE"].replace('"', "") for x in values ]
def init_search_input():
st.session_state.query = st.text_input("Query")
def init_limit_input():
st.session_state.limit = st.number_input("Limit", min_value=1, value=5)
def init_attribute_selection():
st.session_state.attributes = {}
for col in st.session_state.attribute_columns:
is_multiselect = col in ARRAY_ATTRIBUTES
st.session_state.attributes[col] = st.multiselect(
col,
distinct_values_for_attribute(col, is_array_attribute=is_multiselect)
)
def display_search_results(results):
"""
Display the search results in the UI
"""
st.subheader("Search results")
for i, result in enumerate(results):
result = dict(result)
container = st.expander(f"[Result {i+1}]", expanded=True)
# Add the result text.
container.markdown(result[st.session_state.search_column])
# Add the attributes.
for column, column_value in sorted(result.items()):
if column == st.session_state.search_column:
continue
container.markdown(f"**{column}**: {column_value}")
def create_filter_object(attributes):
"""
Create a filter object for the search query
"""
and_clauses = []
for column, column_values in attributes.items():
if len(column_values) == 0:
continue
if column in ARRAY_ATTRIBUTES:
for attr_value in column_values:
and_clauses.append({"@contains": { column: attr_value }})
else:
or_clauses = [{"@eq": {column: attr_value}} for attr_value in column_values]
and_clauses.append({"@or": or_clauses })
return {"@and": and_clauses} if and_clauses else {}
def main():
init_layout()
get_column_specification()
init_attribute_selection()
init_limit_input()
init_search_input()
if not st.session_state.query:
return
results = query_cortex_search_service(
st.session_state.query,
filter = create_filter_object(st.session_state.attributes)
)
display_search_results(results)
if name == "main":
st.set_page_config(page_title="Cortex AI Search and Summary", layout="wide")
main()
※DBとBASE_TABLEを修正(GAKU_CORTEX_SEARCH_TUTRIAL_DB.PUBLICってしたので)
▶Runをクリックすると
うごいたーー

チュートリアル2: シンプルなチャットアプリケーションの構築
使うデータをKaggleからDownloadする

Downloadをクリック
Download dataset as zip (55MB) をクリックして、ファイルをダウンロード
しようとしたらKaggleに登録してね〜〜って
・・・・・いっそKagglerになるか!(ならない、もといなれない)
アカントを作ります。

「Download dataset as zip(55 MB)」をクリックして、ファイルをダウンロードしましょう。
ステージを作ります
CREATE OR REPLACE STAGE books_data_stage
DIRECTORY = (ENABLE = TRUE)
ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE');
show stages;

ディレクトリテーブルについてはこちらを参考に
- ステージにあるファイルのリストを取得(クエリ)できる
- 内部ステージのディレクトリテーブルでは、 手動でメタデータをリフレッシュする 必要がある
- 外部ステージは、REFRESH って設定できる
- ディレクトリテーブルをクエリする際は、「SELECT * FROM DIRECTORY( @<stage_name> )」
いかん、脱線しました
次に行きます。
先ほど、KaggleのサイトからダウンロードしたBOOKなZIPファイル(55MB、archive.zip)を解凍して、BooksDatasetClean.csv をStageにアップロードします。

ファイルをアップロードします。

アップロードしたファイル(BooksDatasetClean.csv)をテーブルにロードします。
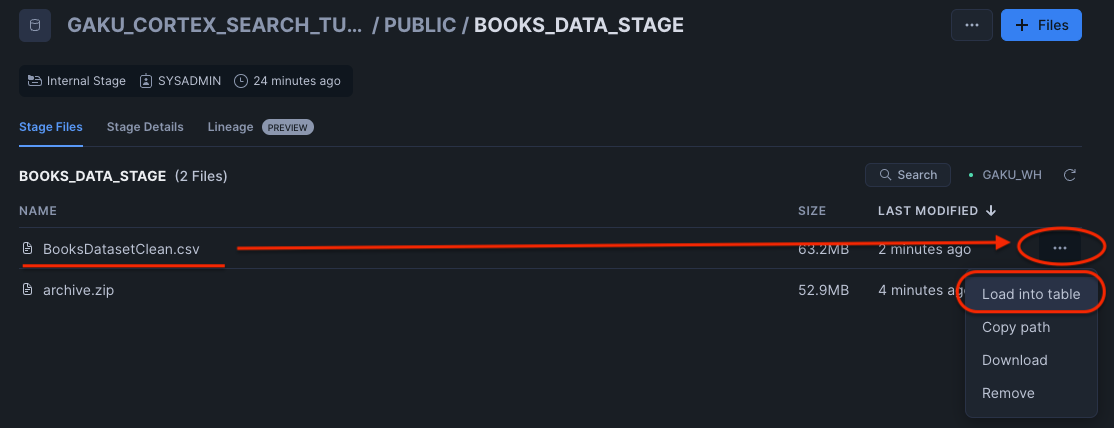
テーブル名は、BOOKS_DATASET_RAW にします。
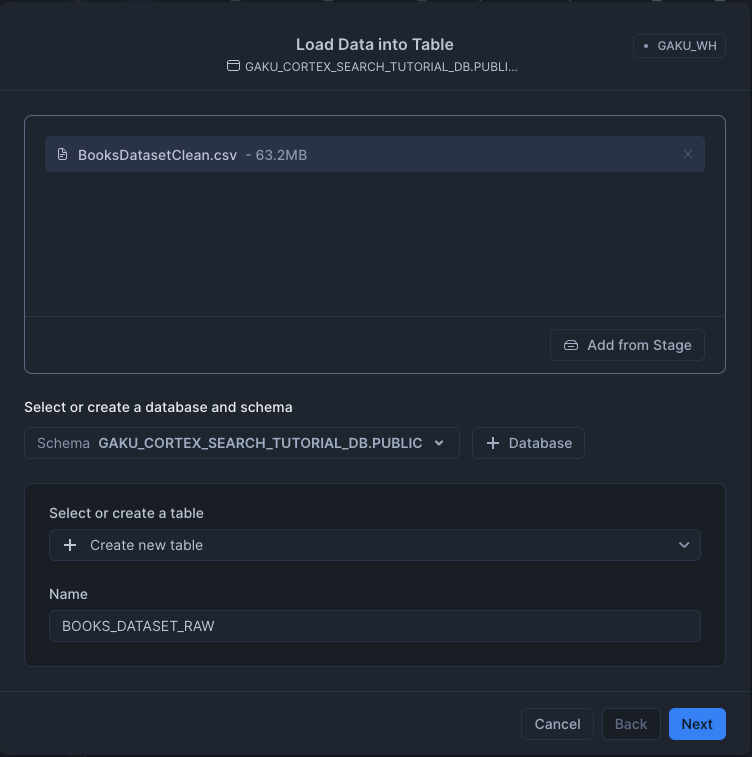
View options をクリックして、開き、HeaderをFirst line contains headerを選択します。
3件エラーが出るので、ヘッダ名を修正(「スペース」を取りのぞく、「()」を取り除く)
※下記のようにヘッダ名を修正
- Price Starting With ($) → PriceStartingWithDollar
- Publish Date (Month) → PublishDateMonth
- Publish Date (Year) → PublishDateYear
book_chunk python function
CREATE OR REPLACE FUNCTION gaku_cortex_search_tutorial_db.public.books_chunk(
description string, title string, authors string, category string, publisher string
)
returns table (chunk string, title string, authors string, category string, publisher string)
language python
runtime_version = '3.9'
handler = 'text_chunker'
packages = ('snowflake-snowpark-python','langchain')
as
$$
from langchain.text_splitter import RecursiveCharacterTextSplitter
import copy
from typing import Optional
class text_chunker:
def process(self, description: Optional[str], title: str, authors: str, category: str, publisher: str):
if description == None:
description = "" # handle null values
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 2000,
chunk_overlap = 300,
length_function = len
)
chunks = text_splitter.split_text(description)
for chunk in chunks:
yield (title + "\n" + authors + "\n" + chunk, title, authors, category, publisher) # always chunk with title
$$;
LangChain を用いてますね。
ステップ4:チャンクテーブルを構築する
チャンクテーブルの構築
CREATE TABLE gaku_cortex_search_tutorial_db.public.book_description_chunks AS (
SELECT
books.*,
t.CHUNK as CHUNK
FROM gaku_cortex_search_tutorial_db.public.books_dataset_raw books,
TABLE(gaku_cortex_search_tutorial_db.public.books_chunk(books.description, books.title, books.authors, books.category, books.publisher)) t
);
select chunk, * from book_description_chunks LIMIT 10;

chunkが生成されています。
BOOKSテーブルのTITLEとAUTHORSとDESCRIPTION、CATEGORY、PUBLISHERを元に作成されていますね。
ステップ5: Cortex Search Serviceを作成する
チャンク検索ができるようにします
CREATE CORTEX SEARCH SERVICE gaku_cortex_search_tutorial_db.public.books_dataset_service
ON CHUNK
WAREHOUSE = gaku_cortex_search_tutorial_wh
TARGET_LAG = '1 hour'
AS (
SELECT *
FROM gaku_cortex_search_tutorial_db.public.book_description_chunks
);
なのでこの「CORTEX SEARCH SERVICE:books_dataset_service」は、ベーステーブル(book_description_chunks)のCHUNKを元に、1時間以内にインデックスに反映させる
って感じになります。
ステップ6: Streamlitアプリを作成する
Snowsightのproject→Streamlitを選び、画面右上の+Streamlit Appをクリック
適宜情報を入力して、Create

Packagesに、Snowflakeを追加
※ドキュメントには「バージョン>= 0.8.0」となっていたが、2025年2月現在の最新版は 1.0.2 だったのでそちらにしてみる。
Streamlit App Code
import streamlit as st
from snowflake.core import Root # requires snowflake>=0.8.0
from snowflake.snowpark.context import get_active_session
MODELS = [
"mistral-large",
"snowflake-arctic",
"llama3-70b",
"llama3-8b",
]
def init_messages():
"""
Initialize the session state for chat messages. If the session state indicates that the
conversation should be cleared or if the "messages" key is not in the session state,
initialize it as an empty list.
"""
if st.session_state.clear_conversation or "messages" not in st.session_state:
st.session_state.messages = []
def init_service_metadata():
"""
Initialize the session state for cortex search service metadata. Query the available
cortex search services from the Snowflake session and store their names and search
columns in the session state.
"""
if "service_metadata" not in st.session_state:
services = session.sql("SHOW CORTEX SEARCH SERVICES;").collect()
service_metadata = []
if services:
for s in services:
svc_name = s["name"]
svc_search_col = session.sql(
f"DESC CORTEX SEARCH SERVICE {svc_name};"
).collect()[0]["search_column"]
service_metadata.append(
{"name": svc_name, "search_column": svc_search_col}
)
st.session_state.service_metadata = service_metadata
def init_config_options():
"""
Initialize the configuration options in the Streamlit sidebar. Allow the user to select
a cortex search service, clear the conversation, toggle debug mode, and toggle the use of
chat history. Also provide advanced options to select a model, the number of context chunks,
and the number of chat messages to use in the chat history.
"""
st.sidebar.selectbox(
"Select cortex search service:",
[s["name"] for s in st.session_state.service_metadata],
key="selected_cortex_search_service",
)
st.sidebar.button("Clear conversation", key="clear_conversation")
st.sidebar.toggle("Debug", key="debug", value=False)
st.sidebar.toggle("Use chat history", key="use_chat_history", value=True)
with st.sidebar.expander("Advanced options"):
st.selectbox("Select model:", MODELS, key="model_name")
st.number_input(
"Select number of context chunks",
value=5,
key="num_retrieved_chunks",
min_value=1,
max_value=10,
)
st.number_input(
"Select number of messages to use in chat history",
value=5,
key="num_chat_messages",
min_value=1,
max_value=10,
)
st.sidebar.expander("Session State").write(st.session_state)
def query_cortex_search_service(query):
"""
Query the selected cortex search service with the given query and retrieve context documents.
Display the retrieved context documents in the sidebar if debug mode is enabled. Return the
context documents as a string.
Args:
query (str): The query to search the cortex search service with.
Returns:
str: The concatenated string of context documents.
"""
db, schema = session.get_current_database(), session.get_current_schema()
cortex_search_service = (
root.databases[db]
.schemas[schema]
.cortex_search_services[st.session_state.selected_cortex_search_service]
)
context_documents = cortex_search_service.search(
query, columns=[], limit=st.session_state.num_retrieved_chunks
)
results = context_documents.results
service_metadata = st.session_state.service_metadata
search_col = [s["search_column"] for s in service_metadata
if s["name"] == st.session_state.selected_cortex_search_service][0]
context_str = ""
for i, r in enumerate(results):
context_str += f"Context document {i+1}: {r[search_col]} \n" + "\n"
if st.session_state.debug:
st.sidebar.text_area("Context documents", context_str, height=500)
return context_str
def get_chat_history():
"""
Retrieve the chat history from the session state limited to the number of messages specified
by the user in the sidebar options.
Returns:
list: The list of chat messages from the session state.
"""
start_index = max(
0, len(st.session_state.messages) - st.session_state.num_chat_messages
)
return st.session_state.messages[start_index : len(st.session_state.messages) - 1]
def complete(model, prompt):
"""
Generate a completion for the given prompt using the specified model.
Args:
model (str): The name of the model to use for completion.
prompt (str): The prompt to generate a completion for.
Returns:
str: The generated completion.
"""
return session.sql("SELECT snowflake.cortex.complete(?,?)", (model, prompt)).collect()[0][0]
def make_chat_history_summary(chat_history, question):
"""
Generate a summary of the chat history combined with the current question to extend the query
context. Use the language model to generate this summary.
Args:
chat_history (str): The chat history to include in the summary.
question (str): The current user question to extend with the chat history.
Returns:
str: The generated summary of the chat history and question.
"""
prompt = f"""
[INST]
Based on the chat history below and the question, generate a query that extend the question
with the chat history provided. The query should be in natural language.
Answer with only the query. Do not add any explanation.
<chat_history>
{chat_history}
</chat_history>
<question>
{question}
</question>
[/INST]
"""
summary = complete(st.session_state.model_name, prompt)
if st.session_state.debug:
st.sidebar.text_area(
"Chat history summary", summary.replace("$", "\$"), height=150
)
return summary
def create_prompt(user_question):
"""
Create a prompt for the language model by combining the user question with context retrieved
from the cortex search service and chat history (if enabled). Format the prompt according to
the expected input format of the model.
Args:
user_question (str): The user's question to generate a prompt for.
Returns:
str: The generated prompt for the language model.
"""
if st.session_state.use_chat_history:
chat_history = get_chat_history()
if chat_history != []:
question_summary = make_chat_history_summary(chat_history, user_question)
prompt_context = query_cortex_search_service(question_summary)
else:
prompt_context = query_cortex_search_service(user_question)
else:
prompt_context = query_cortex_search_service(user_question)
chat_history = ""
prompt = f"""
[INST]
You are a helpful AI chat assistant with RAG capabilities. When a user asks you a question,
you will also be given context provided between <context> and </context> tags. Use that context
with the user's chat history provided in the between <chat_history> and </chat_history> tags
to provide a summary that addresses the user's question. Ensure the answer is coherent, concise,
and directly relevant to the user's question.
If the user asks a generic question which cannot be answered with the given context or chat_history,
just say "I don't know the answer to that question.
Don't saying things like "according to the provided context".
<chat_history>
{chat_history}
</chat_history>
<context>
{prompt_context}
</context>
<question>
{user_question}
</question>
[/INST]
Answer:
"""
return prompt
def main():
st.title(f":speech_balloon: Chatbot with Snowflake Cortex")
init_service_metadata()
init_config_options()
init_messages()
icons = {"assistant": "❄️", "user": "👤"}
# Display chat messages from history on app rerun
for message in st.session_state.messages:
with st.chat_message(message["role"], avatar=icons[message["role"]]):
st.markdown(message["content"])
disable_chat = (
"service_metadata" not in st.session_state
or len(st.session_state.service_metadata) == 0
)
if question := st.chat_input("Ask a question...", disabled=disable_chat):
# Add user message to chat history
st.session_state.messages.append({"role": "user", "content": question})
# Display user message in chat message container
with st.chat_message("user", avatar=icons["user"]):
st.markdown(question.replace("$", "\$"))
# Display assistant response in chat message container
with st.chat_message("assistant", avatar=icons["assistant"]):
message_placeholder = st.empty()
question = question.replace("'", "")
with st.spinner("Thinking..."):
generated_response = complete(
st.session_state.model_name, create_prompt(question)
)
message_placeholder.markdown(generated_response)
st.session_state.messages.append(
{"role": "assistant", "content": generated_response}
)
if __name__ == "__main__":
session = get_active_session()
root = Root(session)
main()
ステップ7: アプリを試す
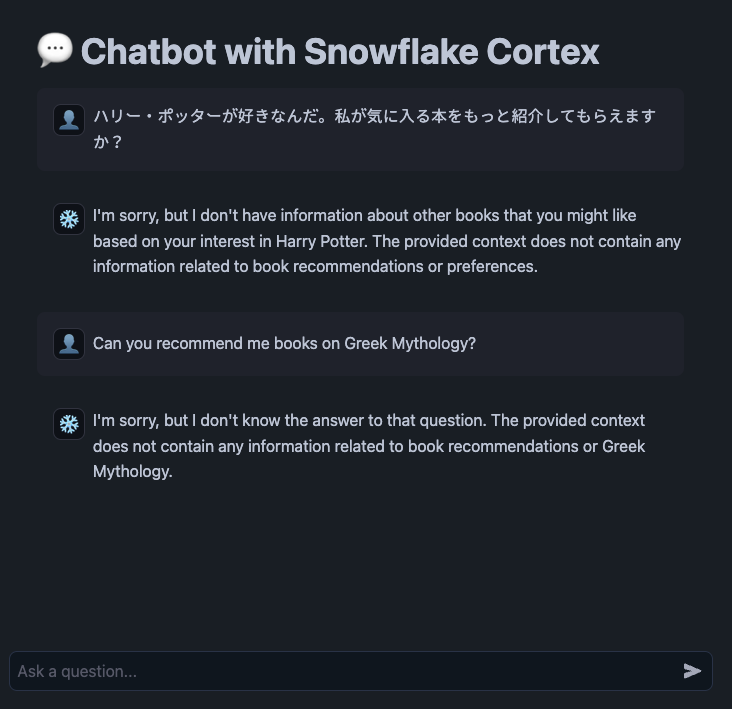
- ハリー・ポッターが好きなんだ。私が気に入る本をもっと紹介してもらえますか?
- 申し訳ございませんが、ハリー・ポッターにご興味がおありとのことで、他にお好きそうな本の情報はございません。提供された文脈には、おすすめの本や嗜好に関する情報は含まれていません。
- Can you recommend me books on Greek Mythology?
- 申し訳ありませんが、その答えはわかりません。提供された文脈には、お勧めの本やギリシャ神話に関連する情報は含まれていません。
いいクエリあるかな・・・
Can you recommend me books on Teddy Bears?
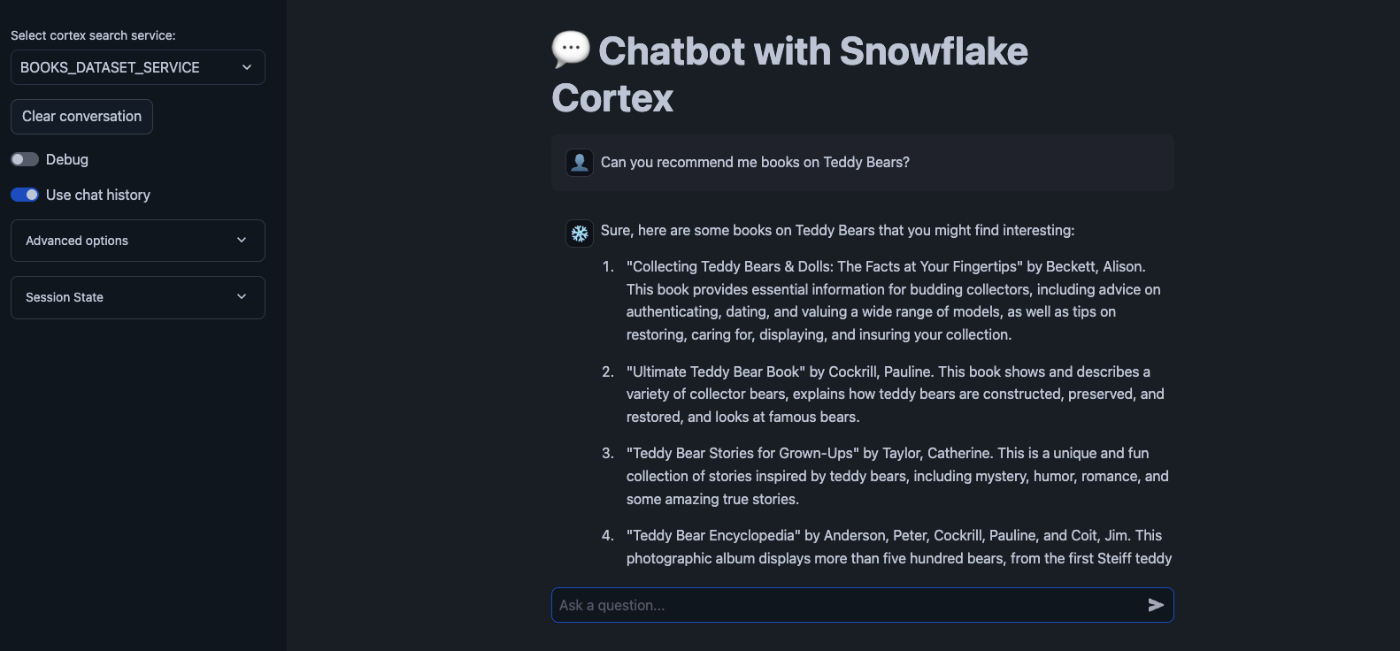
返ってきた!
試しに日本語でも聞いてみた
「テディベアについておすすめの本はありますか」

いけてそう
チュートリアル3:Cortex Searchで PDF チャットボットを構築する
チュートリアル2では、すでにテキスト抽出されたデータを使ったけど、pdfから抽出する方法をやってみる。
- Python UDFを用いて、ステージ内のPDFファイルからテキスト抽出
- Cortex Search Serviceを作成
- Streamlit in Snowflakeのチャットアプリを作成
ステップ1: 設定する
まずは、pdfデータを取得。今回は、連邦公開市場委員会(FOMC)の議事録
※チュートリアルのリンクはアクセス拒否されるので、
から取得する。
今回は、2025年1ファイル、2024年8ファイル取得した

環境設定を行う。(ロール、WH、Database、Schema)
use role sysadmin;
use warehouse gaku_cortex_search_tutorial_wh;
use database gaku_cortex_search_tutorial_db;
use schema public;
ステップ2: データをSnowflakeにロードする
Stageの作成
CREATE OR REPLACE STAGE gaku_cortex_search_tutorial_db.public.fomc
DIRECTORY = (ENABLE = TRUE)
ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE');
こんな記事もあるので参照のこと
アップロードします。

ステップ 3: PDF ファイルを解析する
前処理関数を作る
- PDFファイルを解析し、テキスト抽出する
- インデックス作成のためにテキストをチャンクに分割する
前処理関数
CREATE OR REPLACE FUNCTION gaku_cortex_search_tutorial_db.public.pdf_text_chunker(file_url STRING)
RETURNS TABLE (chunk VARCHAR)
LANGUAGE PYTHON
RUNTIME_VERSION = '3.9'
HANDLER = 'pdf_text_chunker'
PACKAGES = ('snowflake-snowpark-python', 'PyPDF2', 'langchain')
AS
$$
from snowflake.snowpark.types import StringType, StructField, StructType
from langchain.text_splitter import RecursiveCharacterTextSplitter
from snowflake.snowpark.files import SnowflakeFile
import PyPDF2, io
import logging
import pandas as pd
class pdf_text_chunker:
def read_pdf(self, file_url: str) -> str:
logger = logging.getLogger("udf_logger")
logger.info(f"Opening file {file_url}")
with SnowflakeFile.open(file_url, 'rb') as f:
buffer = io.BytesIO(f.readall())
reader = PyPDF2.PdfReader(buffer)
text = ""
for page in reader.pages:
try:
text += page.extract_text().replace('\n', ' ').replace('\0', ' ')
except:
text = "Unable to Extract"
logger.warn(f"Unable to extract from file {file_url}, page {page}")
return text
def process(self, file_url: str):
text = self.read_pdf(file_url)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 2000, # Adjust this as needed
chunk_overlap = 300, # Overlap to keep chunks contextual
length_function = len
)
chunks = text_splitter.split_text(text)
df = pd.DataFrame(chunks, columns=['chunk'])
yield from df.itertuples(index=False, name=None)
$$;
チュートリアル2との違いは、
- PyPDF2 を使っている
CREATE OR REPLACE TABLE gaku_cortex_search_tutorial_db.public.docs_chunks_table AS
SELECT
relative_path,
build_scoped_file_url(@gaku_cortex_search_tutorial_db.public.fomc, relative_path) AS file_url,
-- preserve file title information by concatenating relative_path with the chunk
CONCAT(relative_path, ': ', func.chunk) AS chunk,
'English' AS language
FROM
directory(@gaku_cortex_search_tutorial_db.public.fomc),
TABLE(gaku_cortex_search_tutorial_db.public.pdf_text_chunker(build_scoped_file_url(@gaku_cortex_search_tutorial_db.public.fomc, relative_path))) AS func;
作成できたテーブルを確認する
select * from gaku_cortex_search_tutorial_db.public.docs_chunks_table limit 100;

こんな感じで、pdfを解析し、CHUNKに分割してます。
select relative_path, count(*) from gaku_cortex_search_tutorial_db.public.docs_chunks_table group by all order by 1 ;
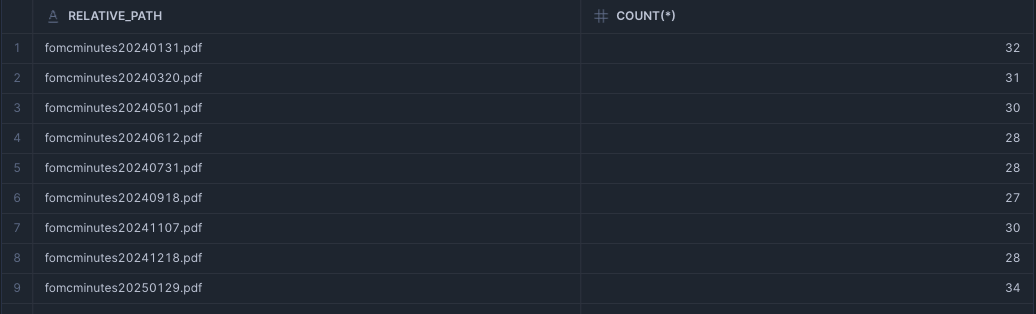
ひとつのPDFは、だいたい30個ぐらいに分割されているのがわかると思います。
ステップ4:検索サービスを作成する
CREATE OR REPLACE CORTEX SEARCH SERVICE gaku_cortex_search_tutorial_db.public.fomc_meeting
ON chunk
ATTRIBUTES language
WAREHOUSE = gaku_cortex_search_tutorial_wh
TARGET_LAG = '1 hour'
AS (
SELECT
chunk,
relative_path,
file_url,
language
FROM gaku_cortex_search_tutorial_db.public.docs_chunks_table
);
ステップ5: Streamlitアプリを作成する
Streamlitアプリを作成する。
Projects→Streamlit→+Streamlit Appを選択

Packagesに、snowflake(バージョン>=0.8.0)とsnowflake-ml-pythonを追加
fomc_search_appのコード
import streamlit as st
from snowflake.core import Root # requires snowflake>=0.8.0
from snowflake.cortex import Complete
from snowflake.snowpark.context import get_active_session
MODELS = [
"mistral-large",
"snowflake-arctic",
"llama3-70b",
"llama3-8b",
]
def init_messages():
"""
Initialize the session state for chat messages. If the session state indicates that the
conversation should be cleared or if the "messages" key is not in the session state,
initialize it as an empty list.
"""
if st.session_state.clear_conversation or "messages" not in st.session_state:
st.session_state.messages = []
def init_service_metadata():
"""
Initialize the session state for cortex search service metadata. Query the available
cortex search services from the Snowflake session and store their names and search
columns in the session state.
"""
if "service_metadata" not in st.session_state:
services = session.sql("SHOW CORTEX SEARCH SERVICES;").collect()
service_metadata = []
if services:
for s in services:
svc_name = s["name"]
svc_search_col = session.sql(
f"DESC CORTEX SEARCH SERVICE {svc_name};"
).collect()[0]["search_column"]
service_metadata.append(
{"name": svc_name, "search_column": svc_search_col}
)
st.session_state.service_metadata = service_metadata
def init_config_options():
"""
Initialize the configuration options in the Streamlit sidebar. Allow the user to select
a cortex search service, clear the conversation, toggle debug mode, and toggle the use of
chat history. Also provide advanced options to select a model, the number of context chunks,
and the number of chat messages to use in the chat history.
"""
st.sidebar.selectbox(
"Select cortex search service:",
[s["name"] for s in st.session_state.service_metadata],
key="selected_cortex_search_service",
)
st.sidebar.button("Clear conversation", key="clear_conversation")
st.sidebar.toggle("Debug", key="debug", value=False)
st.sidebar.toggle("Use chat history", key="use_chat_history", value=True)
with st.sidebar.expander("Advanced options"):
st.selectbox("Select model:", MODELS, key="model_name")
st.number_input(
"Select number of context chunks",
value=5,
key="num_retrieved_chunks",
min_value=1,
max_value=10,
)
st.number_input(
"Select number of messages to use in chat history",
value=5,
key="num_chat_messages",
min_value=1,
max_value=10,
)
st.sidebar.expander("Session State").write(st.session_state)
def query_cortex_search_service(query, columns = [], filter={}):
"""
Query the selected cortex search service with the given query and retrieve context documents.
Display the retrieved context documents in the sidebar if debug mode is enabled. Return the
context documents as a string.
Args:
query (str): The query to search the cortex search service with.
Returns:
str: The concatenated string of context documents.
"""
db, schema = session.get_current_database(), session.get_current_schema()
cortex_search_service = (
root.databases[db]
.schemas[schema]
.cortex_search_services[st.session_state.selected_cortex_search_service]
)
context_documents = cortex_search_service.search(
query, columns=columns, filter=filter, limit=st.session_state.num_retrieved_chunks
)
results = context_documents.results
service_metadata = st.session_state.service_metadata
search_col = [s["search_column"] for s in service_metadata
if s["name"] == st.session_state.selected_cortex_search_service][0].lower()
context_str = ""
for i, r in enumerate(results):
context_str += f"Context document {i+1}: {r[search_col]} \n" + "\n"
if st.session_state.debug:
st.sidebar.text_area("Context documents", context_str, height=500)
return context_str, results
def get_chat_history():
"""
Retrieve the chat history from the session state limited to the number of messages specified
by the user in the sidebar options.
Returns:
list: The list of chat messages from the session state.
"""
start_index = max(
0, len(st.session_state.messages) - st.session_state.num_chat_messages
)
return st.session_state.messages[start_index : len(st.session_state.messages) - 1]
def complete(model, prompt):
"""
Generate a completion for the given prompt using the specified model.
Args:
model (str): The name of the model to use for completion.
prompt (str): The prompt to generate a completion for.
Returns:
str: The generated completion.
"""
return Complete(model, prompt).replace("$", "\$")
def make_chat_history_summary(chat_history, question):
"""
Generate a summary of the chat history combined with the current question to extend the query
context. Use the language model to generate this summary.
Args:
chat_history (str): The chat history to include in the summary.
question (str): The current user question to extend with the chat history.
Returns:
str: The generated summary of the chat history and question.
"""
prompt = f"""
[INST]
Based on the chat history below and the question, generate a query that extend the question
with the chat history provided. The query should be in natural language.
Answer with only the query. Do not add any explanation.
<chat_history>
{chat_history}
</chat_history>
<question>
{question}
</question>
[/INST]
"""
summary = complete(st.session_state.model_name, prompt)
if st.session_state.debug:
st.sidebar.text_area(
"Chat history summary", summary.replace("$", "\$"), height=150
)
return summary
def create_prompt(user_question):
"""
Create a prompt for the language model by combining the user question with context retrieved
from the cortex search service and chat history (if enabled). Format the prompt according to
the expected input format of the model.
Args:
user_question (str): The user's question to generate a prompt for.
Returns:
str: The generated prompt for the language model.
"""
if st.session_state.use_chat_history:
chat_history = get_chat_history()
if chat_history != []:
question_summary = make_chat_history_summary(chat_history, user_question)
prompt_context, results = query_cortex_search_service(
question_summary,
columns=["chunk", "file_url", "relative_path"],
filter={"@and": [{"@eq": {"language": "English"}}]},
)
else:
prompt_context, results = query_cortex_search_service(
user_question,
columns=["chunk", "file_url", "relative_path"],
filter={"@and": [{"@eq": {"language": "English"}}]},
)
else:
prompt_context, results = query_cortex_search_service(
user_question,
columns=["chunk", "file_url", "relative_path"],
filter={"@and": [{"@eq": {"language": "English"}}]},
)
chat_history = ""
prompt = f"""
[INST]
You are a helpful AI chat assistant with RAG capabilities. When a user asks you a question,
you will also be given context provided between <context> and </context> tags. Use that context
with the user's chat history provided in the between <chat_history> and </chat_history> tags
to provide a summary that addresses the user's question. Ensure the answer is coherent, concise,
and directly relevant to the user's question.
If the user asks a generic question which cannot be answered with the given context or chat_history,
just say "I don't know the answer to that question.
Don't saying things like "according to the provided context".
<chat_history>
{chat_history}
</chat_history>
<context>
{prompt_context}
</context>
<question>
{user_question}
</question>
[/INST]
Answer:
"""
return prompt, results
def main():
st.title(f":speech_balloon: Chatbot with Snowflake Cortex")
init_service_metadata()
init_config_options()
init_messages()
icons = {"assistant": "❄️", "user": "👤"}
# Display chat messages from history on app rerun
for message in st.session_state.messages:
with st.chat_message(message["role"], avatar=icons[message["role"]]):
st.markdown(message["content"])
disable_chat = (
"service_metadata" not in st.session_state
or len(st.session_state.service_metadata) == 0
)
if question := st.chat_input("Ask a question...", disabled=disable_chat):
# Add user message to chat history
st.session_state.messages.append({"role": "user", "content": question})
# Display user message in chat message container
with st.chat_message("user", avatar=icons["user"]):
st.markdown(question.replace("$", "\$"))
# Display assistant response in chat message container
with st.chat_message("assistant", avatar=icons["assistant"]):
message_placeholder = st.empty()
question = question.replace("'", "")
prompt, results = create_prompt(question)
with st.spinner("Thinking..."):
generated_response = complete(
st.session_state.model_name, prompt
)
# build references table for citation
markdown_table = "###### References \n\n| PDF Title | URL |\n|-------|-----|\n"
for ref in results:
markdown_table += f"| {ref['relative_path']} | [Link]({ref['file_url']}) |\n"
message_placeholder.markdown(generated_response + "\n\n" + markdown_table)
st.session_state.messages.append(
{"role": "assistant", "content": generated_response}
)
if __name__ == "__main__":
session = get_active_session()
root = Root(session)
main()
snowflake 1.0.2, snowflake-ml-python 1.7.3 だとConflictでエラー発生
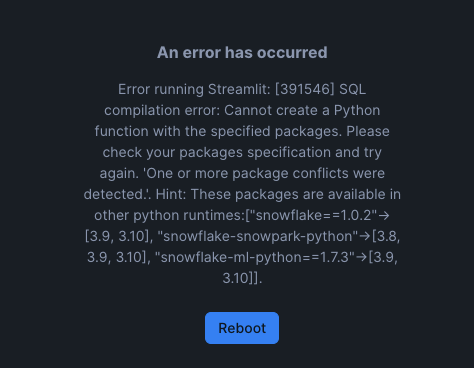
snowflake 0.13.1、1.0.0、だと問題なし
1.0.1はNG
※2025年2月26日現在
ステップ6: アプリを試す
Projects → Streamlit App → fmc_search_app

Q. what is the interest rate
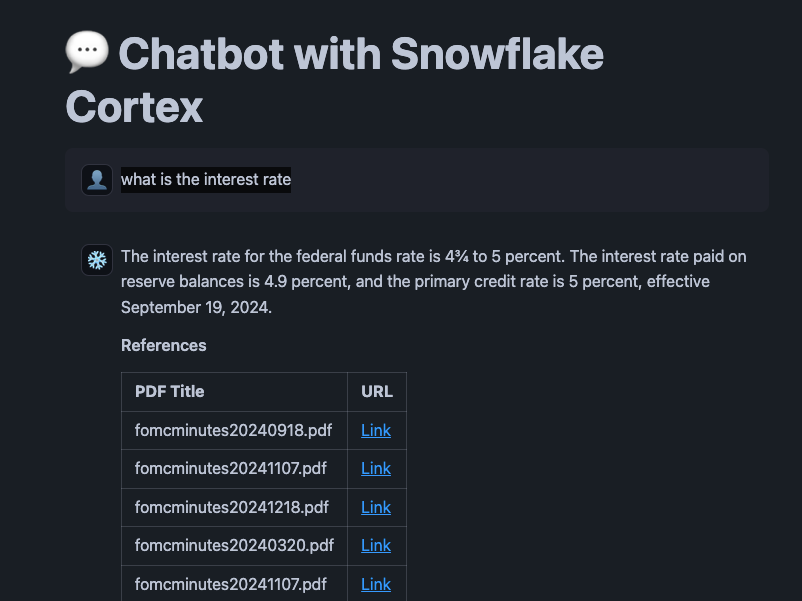
ためしに、Link(署名付きURL)をクリックしたら、エラーになった・・・

※ここは別途調査しよう
Q.How was gpd growth in q4 23?

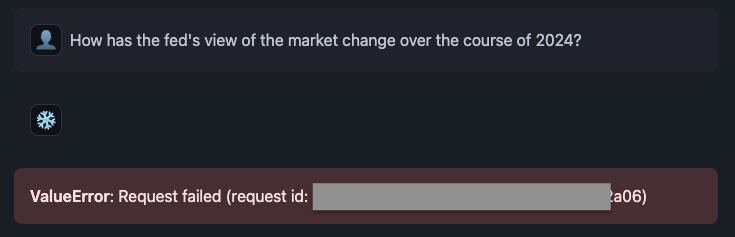
Q.How has the fed's view of the market change over the course of 2024?

modelを snowflake-arcticに変更するとエラーになった
まとめ
今回は、Cortex Searchについて調べ、チュートリアルを3つやりました。
個人的に感じたのは、Cortex Search ServiceのCREATE文は、全文検索システム(自分の経験だと、Apache Solr・・・20年前か)の構築をしてる気分になりました。
ONで、検索対象のカラムを設定しますが、その中に検索に含めたいフィールド(カラム)を文字列連結してってのが「全文検索システム(Apache SolrやElastic Search)構築」のノウハウそのままだなぁという点です。
いまはここがチャンクに分けて、RAGにするのが今風(死語)でしょう
古き良き全文検索システム構築を「Cortex Search Service」だけをすれば使えるというのは、なんかすごい進化したなぁ〜って、インターネット老人会な感想を持ちました。
いや、ベクトル検索や全文検索のハイブリットってことでそれを超えてるんですけどね。
かなり久々に全文検索系について触っているので、もっとキャッチアップをしていかねば、実際に手を動かしていかねばって感じです。エンジニアは生涯勉強、好奇心を持ち続けないとねぇ
Cortex Search自体は、設定することも少なく、とてもシンプルです。
そこに入れるまでの部分(パワポをどういれるか?)、チャンクにする といったあたりがより重要そうです。
ハイブリッド検索の部分を簡便化できるだけでも開発コストは減らせるとおもいます。
今後について(今回やってないこと)
今回は、日本語の取り込みファイルについてはやっていません。
また現段階では難しいかもなぁ・・・とも思っています
が、やはり日本語ドキュメントについてやっていかねば、お話にならないと思うので、現時点の状況を検証したいと思います。
Claude3.5 (3.7)などが使えたりなってきてるので、そちらを使う方法がないか?あたりも検証したいです。(COMPLETE関数に指定ができるだけで、PARSE_DOCUMENTでは無理そうだが・・・)
PDFからの読み込みについても日本語ができそうな雰囲気もあります。
そのあたりについて検証してみたいですね
また、コストやパフォーマンスについても今回は検証ができていないので、そこも

Discussion