がく@ちゅらデータエンジニアです!
現在、Frosty Friday Live Challangeとして、最初からやっていますが、Week100到達!ってことで、やってみました♪
こんぐらっちゅれーしょ〜〜んWeek100到達!
※2022年7月がWeek1だったとおもうので、2年ほどずっと・・・・頭が下がります
Week100 - Hard Streamlit Images
問題
🎉100回のチャレンジを祝います! 🎉
約 2 年間、素晴らしい日々が続きましたが、100 回目のチャレンジという節目に到達できたことを嬉しく思います。
Frosty_Friday チームは、F_F の周囲に生まれた活気あるコミュニティに驚いています。私たちは本当に素晴らしい人々と出会い、Snowflake から受けたサポートは驚異的でした。
私たちがこの旅に乗り出したときは、フロスティ教授とインターン生がサミットで独自のブースを構えることになるとは夢にも思っていませんでした。
100 回目のチャレンジを盛大に祝うために、私たちは Snowflake のクリエイティブな才能に声をかけ、特に刺激的なチャレンジのアイデアをいくつか提供してもらいました。そして、彼らは私たちの予想をはるかに超える成果を出してくれたとだけ言っておきましょう。
私たちが受け取った数多くの素晴らしいアイデアの中で、特に目立ったものが 1 つありました。Snowflake の主任開発者アドボケートである Dash は、古いものと新しいものの両方の長所を組み合わせ、さらに Streamlit を少し加えて風味を増した素晴らしいコンセプトを提案しました。
お祝いに参加するためのあなたの仕事は次のとおりです:
FILE_NAME以下に示す起動コードを使用して、と の2 つの列を持つテーブルを作成します
IMAGE_BYTES以下に csv で共有する 16 進数でエンコードされた画像が保存されます。Streamlit でこれらの画像を紹介していただきたいと思っていますが、もちろん、これらの画像に命を吹き込んで Streamlit アプリに表示するのはあなた次第です。
実際のデータは、S3 バケットのcsv ファイルで確認できます。
皆さんがどんな独創的な解決策を思いつくのか、とても楽しみです。この 100 回目のチャレンジを思い出に残るものにしましょう!
楽しいコーディングをし、これからも一緒にたくさんの挑戦をしましょう!🥳
スタートアップコードは
create or replace table images (file_name string, image_bytes string);
https://frostyfridaychallenges.s3.eu-west-1.amazonaws.com/challenge_100/images.csv
にファイルがあるので、こちらを取り込むところから作ります
ファイルの取り込み
単純な方法でもできるんですが、趣味で、INFER_SCHEMAとMETADATAを取り入れています。
INFER_SCHEMAを使う場合のFile Formatでは
parse_header = true
error_on_column_count_mismatch = false -- default true : 入力ファイルの区切り列(フィールド)の数が対応するテーブルの列の数と一致しない場合に、解析エラーを生成するかどうかを指定するブール値
-- copy into include_metadata を使うには、falseにする必要がある
この2つが重要です。
また、テーブルの作成には、
- using template
- array_agg (object_construct
を使います。
object_construct(*) を使ってもいいですが、対象が大きくなりすぎるとSQL Compile Error が起きる恐れがあるので、
object_construct('COLUMN_NAME', column_name, 'TYPE', type, 'NULLABLE', nullable )
にしています。
from
table(infer_schema(
location=>'@ff_week_100_frosty_stage_for_inferschema'
, file_format=>'ff_csv_format_for_inferschema'
, ignore_case => true -- 大文字小文字が区別されないで、すべての列名は大文字になる
, max_records_per_file => 10000
)))
ここでは、ignore_caseをtrueにしましょう。Snowflake作法?では、""でカラム名を付けないと見れないのって結構罠なのでw
データの取り込み
copy into week100_tbl
from
@ff_week_100_frosty_stage_for_inferschema
match_by_column_name = case_insensitive
include_metadata = (
filename = METADATA$FILENAME
, file_row_number = METADATA$FILE_ROW_NUMBER
, start_scan_time = METADATA$START_SCAN_TIME
)
;
ここでは
- include_metadata
- match_by_column_name = case_insensitive
の2つがキーです
メタデータはぜひとも付けておきましょう
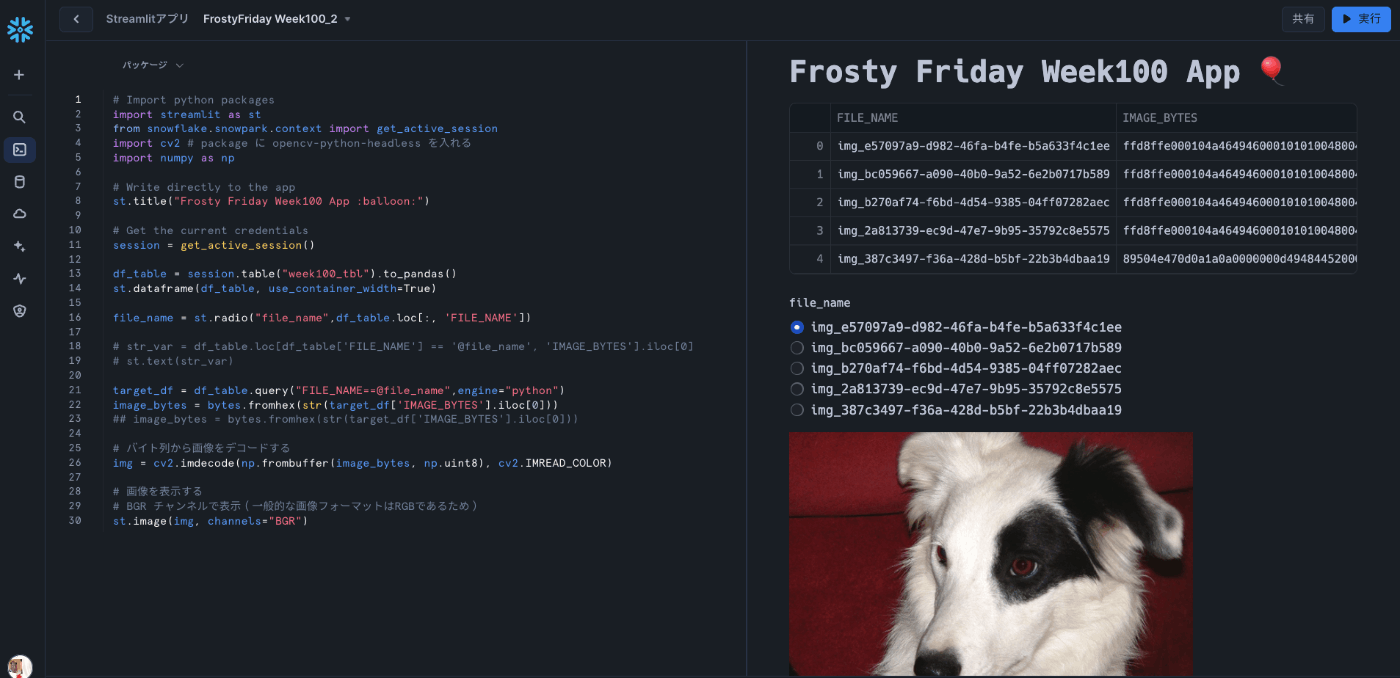
Streamlitで可視化
今回は、OpenCV(cv2)を使います。
こちらを使う場合は、パッケージに opencv-python-headless を追加する必要があります
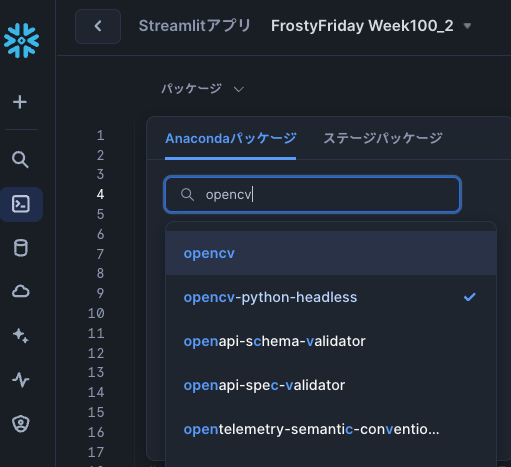
opencv にするとこんなエラーが出ました。この記事を見て対応しました
Streamlitで可視化(SQLが入っちゃう版)
正直に言うとものすごく稚拙なコードかなぁと思っています。
FILE_NAMEを取るなら、キャッシュしておけばいいとは思いますが、まぁ動くものを一旦・・・みたいな感じで作ってます
Streamlitで可視化(SQLを使わないようにした版)
pandasの扱いに慣れていないため、pandas.dataframeの値をString値に持っていくのがぜんぜんできない(Pythonのコーディング弱いんや・・・)
もっとPythonicにかけるようにならねば・・・・
酒徳さんの解法
さすがだなぁ〜とおもった
# Convert hex string to bytes
hex_string = df.loc[df["FILE_NAME"] == selected_image, "IMAGE_BYTES"].values[0]
image_bytes = bytes.fromhex(hex_string)
このあたりがとても参考になりました!!
Frosty Friday Live Challenge
tomoさんと二人のメインMCでやってるYoutubeはこちら
こちらは、Week1から解説しているのでぜひ御覧ください!
コメントとか高評価もらえるととても励みになります♪

Discussion