がく@ちゅらデータエンジニアです。
こんばんわ!!
Snowflake World Tour Tokyo 2025 は、とてもとても盛況でしたね!つーでいず!!!めちゃくちゃ熱いセッションばかりでした!
私がSWTTokyo25への参加はこのセッションを聞くためだ!!といっても過言ではないセッションがありました

Snowflakeの神エンジニア(Co-Founderにアジアナンバーワンエンジニアと言われた)yoshiさんのセッションです。
毎年、本当に質の高いセッション内容で、内容は正直「地味」かもしれませんが、Snowflakeでいかにパフォーマンスを出すか?を説明いただいたセッションです。
※御本人に一応Blogで書いていい?とは聞いたので、大丈夫だと思う(が、間違っていたり、そこはかいたらあかん!があったら指摘をくださいw)
アジェンダ
- パフォーマンスチューニングにおける基礎
- Snowflakeにおける典型的なパフォーマンス問題
大きく分けてこの2つでお話しいただきました。
まずは、パフォーマンスチューニングってものの説明と基本的にどう進めるか?のお話をいただき、Snowflake特有という流れ
パフォーマンスチューニングにおける基礎

なにはともあれ「目標設定」が大切!
ほんとこれ!
「なんとなく早くしたい」「なるべくはやくして〜」
とかは論外!
しっかり定量化して数値目標を建てないいけませんね。
速度とコスト、この両方をバランスよく行きたいところ

パフォーマンスチューニングはイテレーティブ
はい、至言いただきました!!
繰り返し試行錯誤を繰り返して、一つずつ進めていくことが大切
これはどんなことにも言えると思っていますが、パフォーマンスチューニングにもとっても重要

- 一つを解決したら別の問題が
- 2つ試したら解決→2つ目だけしたら改善する場合もあるので、時には、イテレーションを戻ることも重要

比較はできるだけ条件を揃えて
はい、また至言をいただきました!
ある日突然クエリが遅くなったら、同じ条件下で何が変わったか?を徹底的に、冷静に、先入観なく・・・かな?

想定通りに時間がかかっていることもある
はい、これもよーーくあることですね
スキャン量がどうしても多い場合など、マジしょうががない部分はあります。
※ただ、このあたりSnowflakeが勝手に改善してしまって、将来的に治ってしまってるってこともままあるんですよね
クエリコンパイル時間
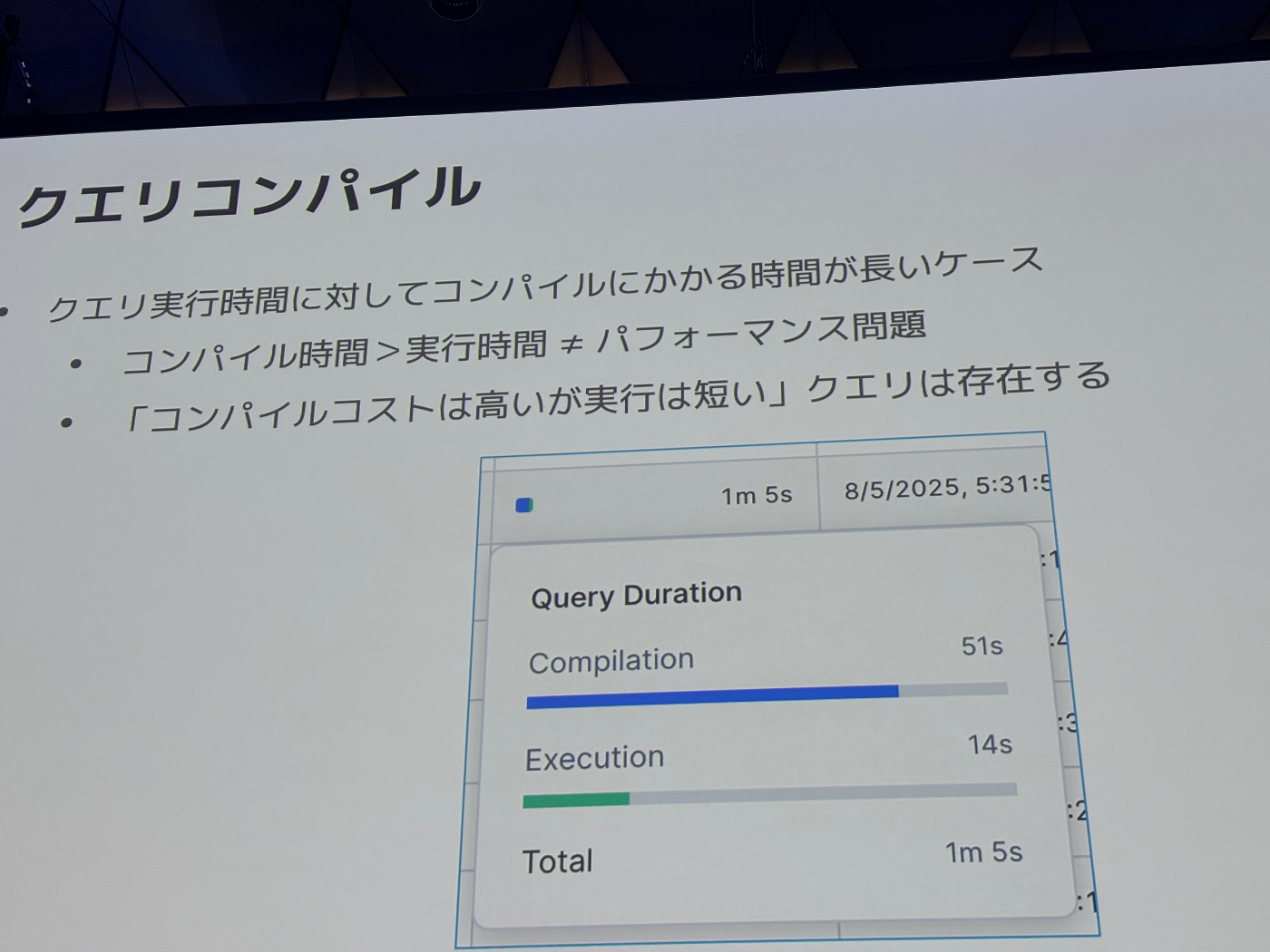

- クエリコンパイルは長いが実行が短いクエリもある
- ネストはしないほうが良さそう

クエリコンパイルに関するベスプラ
できるだけシンプルに保つ
はい、また至言いただきましたーー
なにげに
「ロールのネストレベルを下げる」
も重要なんだなという学びがありました。
ロールのネストが深い(例えば、1000階層)とかにすると、それぞれのテーブルに対して、権限があるのか?の検査にすごく時間がかかるそうです。
ですので、ロール設計に関しても、できるだけシンプルに、複雑さは最小限にするのが大事そうです
クエリ実行
クエリ実行:テーブルスキャン

プルーニングが全く聞いていないことが一番下からわかる
→ スキャン量をいかに減らすか?はまず最初に考えることで、これについては「フィルタを効かし」てスキャン量をまず減らせないか?を考えることが何より大切

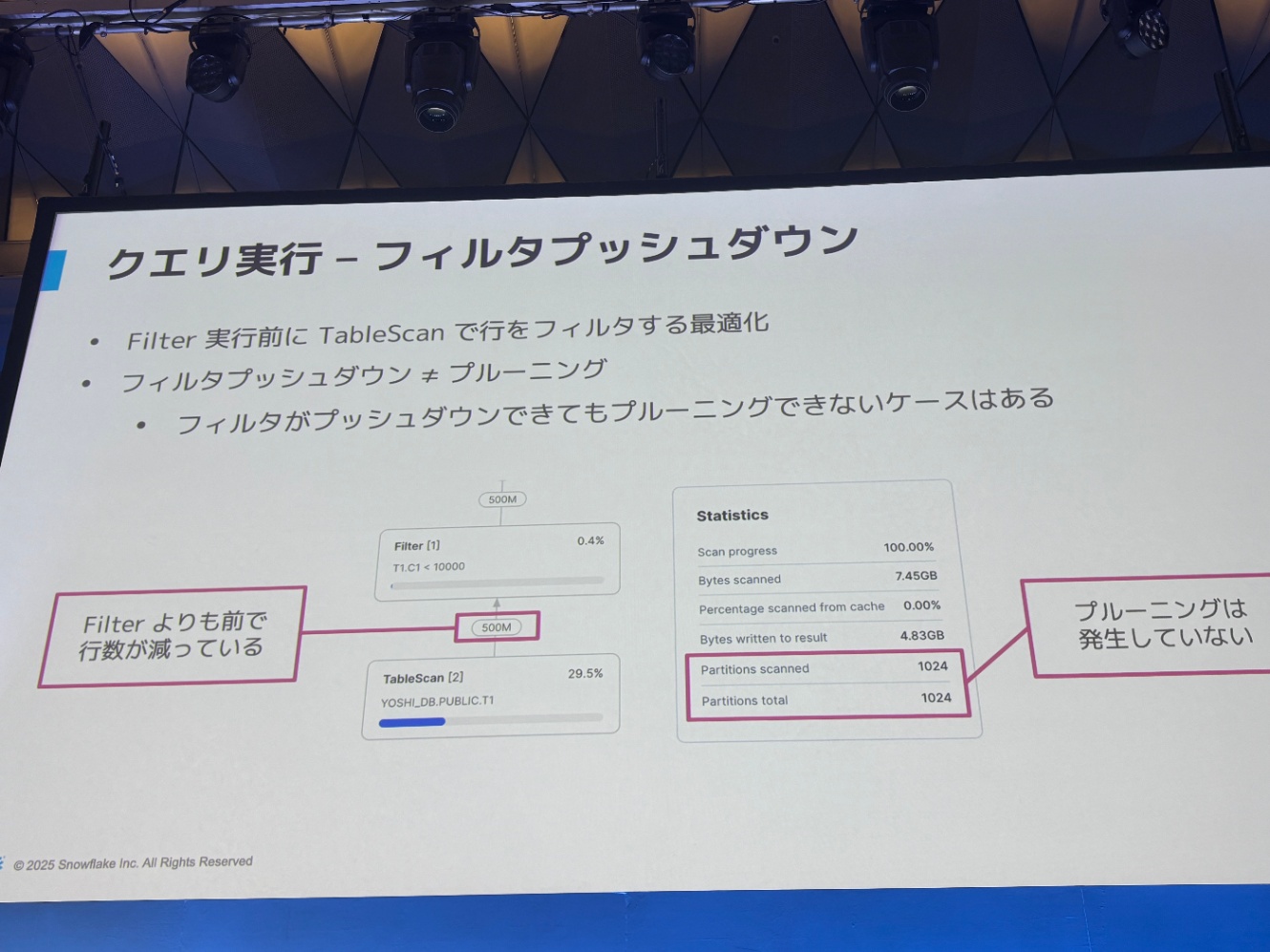
フィルタプッシュダウンとプルーニングは似てるように見えるが、実行中にもフィルタすることが「フィルタプッシュダウン」っぽい
こちらがクエリ実行時間をチューニングするためのベスプラ

- 主キーが複雑するとフィルタプッシュダウンが効かない
- → 一時テーブルにするとかCTEを使うなどして、先に計算してしまうなどして、条件を簡単にするなど
- どうしてもダメな場合は、クエリアクセラレータ機能を使おう
クエリ実行:メモリ不足

スピルには、ローカルスピルとリモートスピルがある

スピルが悪いわけではない(必要なスピルもあるっちゃある
ソートする際にスピルは起きる

- クエリの並列実行がやばい
- CTEに同一SQLがあるとマテリアライゼーション(実体化)でおかしくなる
- 集約は早い段階でやるべし
クエリ実行:メモリ不足のベスプラ

クエリ実行:集約

Snowflakeではビッグデータを使う
→分散して各サーバ?(コンピュート?)で集約してから全部を集約する
なので、複雑な集約(Case式をつかった)はヤバい
一次テーブルを使うのも良き
ベスプラ

クエリ実行:結果生成・データ挿入

- VARIANT型やJSON型はリザルト作成で死ぬ
- ネイティブ型に比較して、2倍とか3倍とかの時間がかかることも
クエリ実行:結合順
- 結合はSQLに書いてあるとおりに結合するわけではない
- データに大きな偏りがある際に、オプティマイザーがご検知することはある → 基本的にオプティマイザーは、隔たりのない偏差?偏り?でデータが有るという前提で動くことが多いため
- プレースホルダではなくnullにしておくのが良い
- →これはその値がプレースホルダなのか、正当な値か?がはんだんできないため。nullにするとスキャン量を減らすことができる
- 結合条件に or があるとJoin爆発の原因、ヤバいことになりがち
- Joinは等価Join?がやっぱよさげ

ベスプラ

結合順に関しては、サポートに問い合わせてね!
そこはSnowflakeでやるし、駄目なパターンを教えてくれたらそれを反映できるし!!

まとめ

「遠慮なくサポートに頼る!!」
最後にまた至言いただきました
Snowflakeはここが強いからね、まじお世話になってます!!

Discussion