
がく@ちゅらデータです。
リアルイベントはやっぱりいいねぇ〜
先日、2023年7月11日にSnowflakeのリアルイベント「Build.local」に参加してきました。
イベントの内容はこんな感じ
アジェンダはこんな感じ
| Time | |
|---|---|
| 15:00〜 | What's New in Snowflake for BUILDers |
| 15:45〜 | 分科会 【90名限定!】Snowpark+StreamlitによるMLアプリ実装体験ハンズオン |
| 17:30〜 | noteのワークフローを変えたSnowpark |
| 18:00〜 | ネットワーキング |
What's New in Snowflake for BUILDers
ちょっと仕事で、到着が遅れていまい、途中からだったのですが・・・・

こちらから合流しましたが・・

個人的には、Summit2023でTop3の衝撃の一つ
試してみないとなーと思ってます、そのうちブログにでも書きたいな

こちらも近いうちにPublic Previewになるかも?って話を小耳に挟みました。早く使いたいですね!
個人的には、30 Days Of Streamlit を初めています。
今後、Snowflakeをやるうえでは、避けて通れない技術になりそうですからね!

現時点でPrivate Previewですが、Summitで一番の衝撃があった発表だと思いました。

Snowflakeを支える?パートナーたち
こちらには乗っていませんが、Airbyteが乗ったりして、Snowflakeのプラットフォームで、ELTが全部できてしまう!みたいな世界がすぐそこに来てます。
閑話休題

今回は、ちゅらTシャツで参加しました♪
Streamlit + Snowparkのハンズオン

KTさんの案内

ハンズオンをすすめるShoujiさん

ハンズオンの流れはこんな感じ
※事前に、環境設定はしてくるようにとのこと(事前にドキュメントを頂いておりました)
- データ、テーブルなどの準備
- Snowparkでデータエンジニアリング(Jypyter notebookを使って)
- Pythonで機械学習っぽいこと
- Streamlitでデータ・アプリケーションを動かしてみよう
こちらのQuickstartの内容をみんなでやるという形式でした。

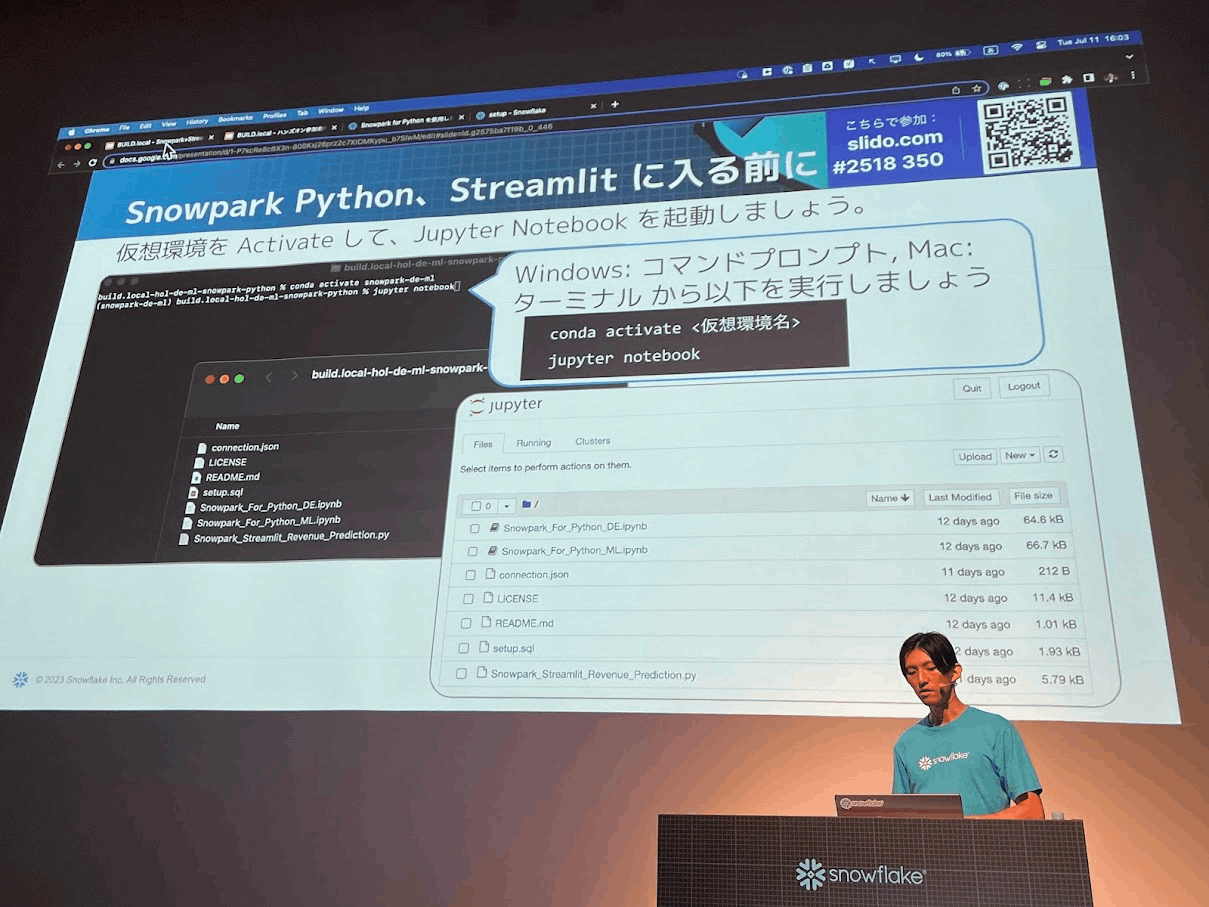
こんな感じで、事前準備されたファイルをDLして取り込み、ハンズオンを行いました。
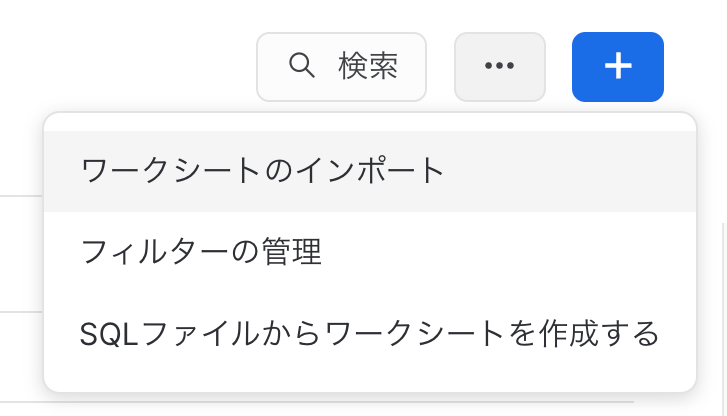
※Snowflakeのワークシートで、「SQLファイルからワークシートを作る」を使って、取り込みました。実は知らない機能でした
少し罠があったりしましたが、基本的に用意されているJupyter notebook を一つ一つ実行していくだけだったので、トラブルも少なく、Streamlitアプリを動かすところまで行けました
感想
- pythonからデータにアクセスする(SQLを組み立てる)・・・んだけど、そこの記法が、SQLに慣れてきている現在の自分からは、不自然やなぁ〜て感じてしまいました。。。かなりSQL脳になってきてるなぁ(笑
- Pythonの記載は、SQLの実行順序によってものになっていて、そこは、なるほど納得って感じでした
- 対象Tableを指定して(FROM)
- フィルタリング(WHERE)して
- グルーピングして(GROUP BY)
- 最後に、表示するカラムを指定する(SELECT)
- 今回の配布資料では、Snowpark_Streamlit_Revenue_Prediction.py の95行目〜がコメントアウトされていてそこが罠でした。(gitで配布されているファイルにはコメントアウトはなかったので多分問題は起きないと思います)
noteさんのプレゼン
データ基盤チームリーダーの久保田さん

Snowparkというと、MLをまわしたり・・・・という印象があったのですが、それまでGlueなどで動いていたELTの仕組みをSnowpark化(もともとSparkで実装)したり、中間テーブルの作成の自動化をやったり
こういう使い方もあるのか!とびっくりしました

Snowflakeにしてから、クエリ数が約3倍になり、データの利活用が活発化したとのことでした。




無限大(∞)ですよね!

Discussion