がく@ちゅらデータエンジニアです。
先日、東京虎ノ門のCARTA HOLDINGS様のオフィスにて、Tokyo dbt Meetup #15 に参加してきましたので、そちらのイベントレポート
今回のテーマは「dbt x LLM」
発表の内容は
- Ubie由川さん「dbt民主化とLLMによる開発ブースト ~ AI Readyな分析サイクルを目指して ~」
- ちゅらデータ菱沼CTO「dbtモデルをLLMに作らせたい」
- NTTデータグループ長塚さん「LLMで育てるメタデータ〜dbt-mcpを添えて」
の3本でした。
dbt民主化とLLMによる開発ブースト ~ AI Readyな分析サイクルを目指して ~
Ubie由川さん
発表:20分、質問:5分
発表のスライドはこちら
Ubieさんといえば生成AIの活用がすごく進んでいて、データ分析系のお話でもガンガン発信なさっています。
LLMxdbtという生成AI活用の最先端グループをひた走っているのがUbieさんではないでしょうか

淡々と発表なさっていたのが印象的
しかしその内容は熱い

会場は大盛況
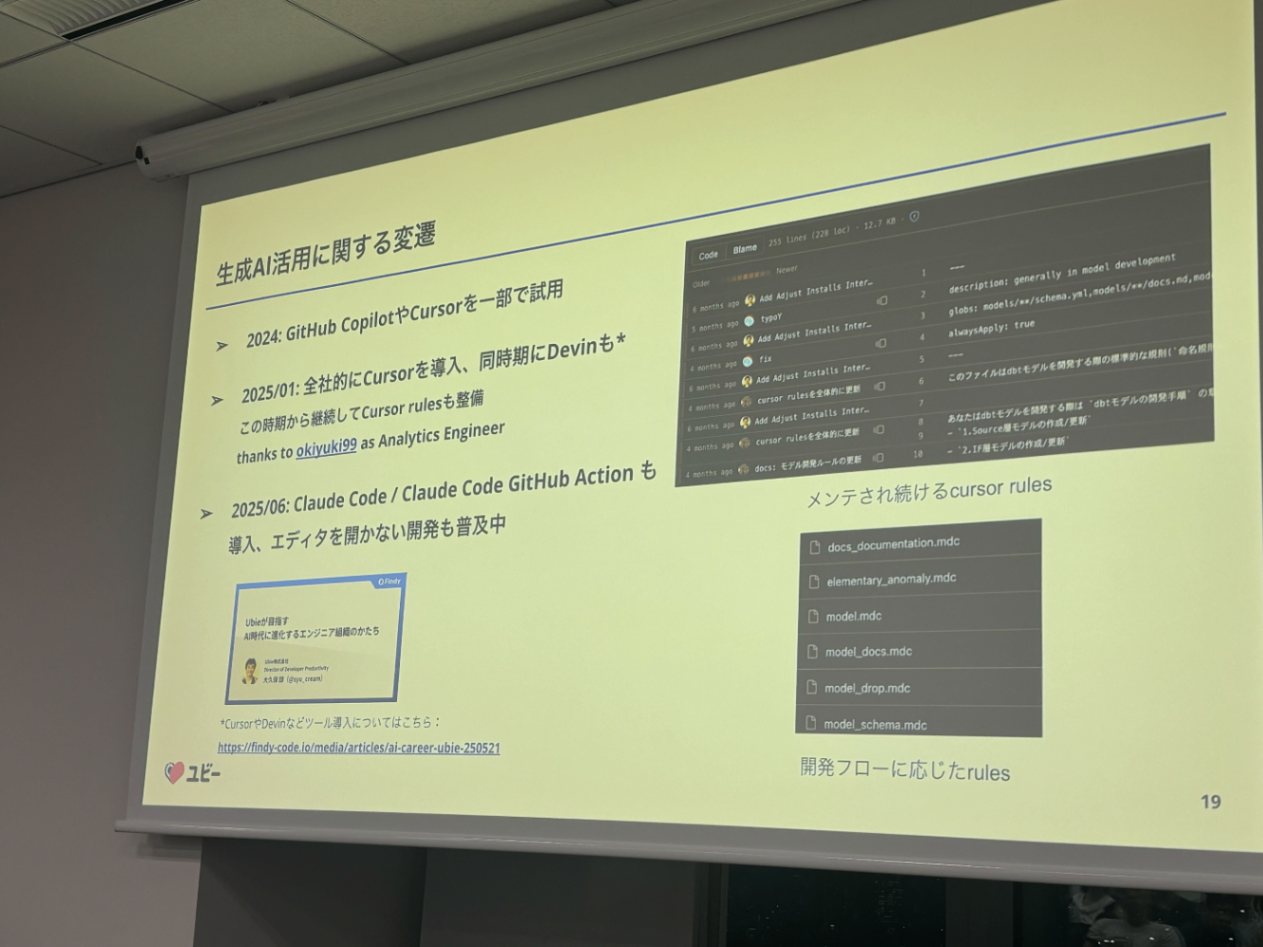
いち早く生成AI、もしくはAIコーディングエージェントなどを活用しているのがわかります。

Claude Code Actionは使わないとなぁーー

自分的には、AIにレビューをさせる、それがすごくやりたいです。

生成AIを前提とする開発では(でなくても)ドキュメントはとにかく重要
ここは、至言ですね。ほんとそれ

「AIドキュメントに読ませたいものは、Git Repository」
これは最近すごく思っていて、参考となるGit Repository(データ基盤のスケルトン的な)があれば、それを参考にコードを生成してくれたりしています

今回の発表でいちばん大切なスライド とおっしゃってました。
ここが「人間がバリューを発揮するべきところ」

「データオーナーだけは何が何でも最新化しておくべし」
これだけは、これだけはやらにゃならんのや
まとめ

タイムキーパーやってましたw

dbtモデルをLLMに作らせたい
ちゅらデータ菱沼CTO
発表20分+質問5分

弊社菱沼の発表。
「生」沼です


今回は、Claude Code をつかって、dbtプロジェクトを「この発表中に」作っちゃおう!!っていうのが肝です
※ですので、会場のWiFiは参加者の方には極力使わないでねーーーってお願いをしたのでした。
Claude Code(や、コーディングエージェント)使ってますか?
※実際に使ってるのを始めてみたって方も多かったのではないでしょうか
Snowflakeにつなぐよ。
dbt debugとかやるよ

何をやるかタスクリストを出してる

所感
実際に、Claude Codeを使ってdbtの開発をするのを始めてみて、こんなに簡単にできるん??????って正直なところ思いました。
菱沼の言葉に「これまでのように劇的にAIの性能が上がることはなさそう、もう使える所まで来たので、腹をくくって、使っていくべき」があり、それはそうって思いました。
今までも、先行者メリットは有りつつも、デメリット(苦労といったほうがいいか?)のほうが大きかったようにも思います。
ただ、生成AIのモデルの進化も一段落ついてきたところで、ここからはもっともっとAIコーディングエージェントを使っていかねばなと思いを新たにしました。
あと、印象的なのは、Claude.mdなどを書いていないのに、生成されたSQLは「dbtのベストプラクティスに沿った形で出てきた」「テストもいい感じで勝手に生成してくれた」
もう生成AIは、インターネット上を(学習に使えるきれいなデータは)学習し尽くしているので、dbtのベスプラとかもすでに取り込んでしまっている
って感じでした。
たぶん、それぞれの会社がドメインによってチューニングしてその精度を上げていくことはしていかねばならないかもしれませんが、ある程度は出来てしまう証左かなと思いました。

質問もガンガン出ました
質疑応答
Q. 公式のMCPサーバはないですよね。何を使いましたか?
A. 今回は野良MCPサーバを使っていますが、ダメな作り(特に認証系でID/PW認証しか使えないなど)をしてるので、自分で作ったほうがいいです。
Q. dbtのベスプラ的なのが出てきましたが、なにかサンプルを置きましたか?
A. ほぼ素のClaude Codeですので、多分そもそも知ってる。claude.mdは、ClaudeCodeが生成した。
Q. DWのMCPサーバを試したこと無いのですが、Agentにデータを見せるんかいってのがあるんですが、どう対処します?
A. 開発用のデータは見てもいいようにしたい。分析用は本番を見ないといけないと思うが、MCPサーバは自作して外にデータが漏れないように担保して、実行するのがいいのではないか
(私信)Snowflakeが公式のMCPサーバを作ってくれればいいなぁ・・・いや、絶対近いうちにだしてくれるんちゃうかなぁ・・・って謎の信頼感があります
LLMで育てるメタデータ〜dbt-mcpを添えて
株式会社NTTデータグループ 長塚さん
発表25分+質問5分

今回の発表は「実際の案件で使ったものではなく、検証で使ったものなのでそこは留意ください」なんてお話が最初にありました。
が、メタデータに関するお話は、すごく示唆が富む話で、めちゃくちゃ良かったです。
※聞いてほんと良かった

至言「無いメタデータは無い」

dbt-mcpを相当チューニング


- Semantic Layerに情報があれば使う
- なければ、Martを見に行く

これを実現するために、dbt-mcpに相当手を入れたそうです。
- MetricFlow系がローカルで使えない
- dbt ls --resource-type metric を使って実装
- (mf list metrics が使われていた)
- 出力が冗長
- lsツールでの情報取得が荒い
- dbt ls --quiet --output json --output-keys="" を使う




Databricks AI/BI Genie では、事前に用意したSQLとチャットが出したSQLが一致するか?をみてるが、長塚さんの方式は「データでアサート」している。
→ SQLで比較すると順番とかで変わるしこれはこれできついんじゃねっておもう
→ データで見るのはdbtでも data_test でやってるので、こっちの方が筋が良さそう・・って話になりました。
まとめ「Let's メタデータエンジニアリング!」



質疑応答
Q. 大きな会社での組織変更とかがあるときつい
A. ない情報は取れない・・・ので、データオーナーだけは最新に保つところだけでも頑張る
データオーナーが誰か・・はいちばん重要なメタデータだとおもう
Q. メタデータが入ったことで、メタデータのテストで、カラムに入ってるデータを見てる?
A. テストのときは、正解SQLをつくり、その結果をJSON化しておいて、Chatでやったときに返ってきた結果を比べている
Q. セマンティックレイヤーとマートを見に行くというお話をなさってましたが、セマンティックレイヤーを見なくでまーとをみにいっちゃたっとかあった?ガードレールはどうしてる?
A. 正解SQLと同じものが返ってくるかをテストしてるので、どちらをみても結果が同じならいいよという割り切りをしている。
mdには、一応メトリクスを見に行くよう 書いている
ただ、メトリクスをちゃんと見てくれない場合は、デスクリプションを育てて、ちゃんと見るようにする
まとめ
ネットワーキングでは、いままでTwitterとかでしかお見かけしてなかった方々にあえたり、
FrostyFridayのリクルートできたりホント実りの多い一日でした♪
打ち上げ

めちゃくちゃ美味しかったですw

Discussion