みなさんこんにちは、クルトンです!
ちゅらデータ入社後初ブログとして、Databricks のチュートリアル
「ノートブックから CSV データをインポートして視覚化する」
をやってみました 🎉
チュートリアルの公式ドキュメントはこちらです。
👉 Databricks 公式チュートリアル(GCP 版)
🧭 やってみた
まず、チュートリアルページから以下の CSV ファイルをダウンロードしましたが、結果的には不要でした。
Databricks ワークスペースで Unity Catalog が有効になっているかを確認します。
ドキュメントの手順にある「Unity Catalog の使用を開始する」でも確認できますが、今回は SQL でチェックしてみました。
SQL Editor を起動します。

-- カタログ名を確認
SHOW CATALOGS;
既存環境では、カタログが複数存在している状態を確認しました。
自分が使って良いカタログの名前をここで確認しました。
続いてスキーマ名を確認します。
-- スキーマ名を確認
SHOW SCHEMAS IN <カタログ名>;

結果として、information_schema のみが存在していました。
スキーマの作成
チュートリアル用に新しいスキーマを作成します。
USE CATALOG <カタログ名>;
CREATE SCHEMA tutorial_schema;
結果に OK と表示されれば成功です。
Volume の確認と作成
次に、Volume の存在を確認します。
SHOW VOLUMES IN <カタログ名>.tutorial_schema;

当然のことながら、何も表示されなかったので新たに Volume を作成します。
CREATE VOLUME <カタログ名>.tutorial_schema.tutorial_volume;
こちらも OK と表示されました。
🧑💻 Notebook でチュートリアルを実行
準備が整ったので Notebook を起動してチュートリアルを開始します。
まずは変数を設定します。
catalog = "<カタログ名>"
schema = "tutorial_schema"
volume = "tutorial_volume"
download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv"
file_name = "baby_names.csv"
table_name = "baby_names"
path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume
path_table = catalog + "." + schema
print(path_table)
print(path_volume)
出力結果は以下のようになります。
<カタログ名>.tutorial_schema
/Volumes/<カタログ名>/tutorial_schema/tutorial_volume
CSV ファイルのインポート
dbutils.fs.cp(f"{download_url}", f"{path_volume}/{file_name}")
ここで使用している dbutils は、Databricks が提供する便利なユーティリティモジュールです。
データを DataFrame に読み込む
df = spark.read.csv(f"{path_volume}/{file_name}",
header=True,
inferSchema=True,
sep=",")
DataFrame を表示する
display(df)
初期表示は以下のようになります。
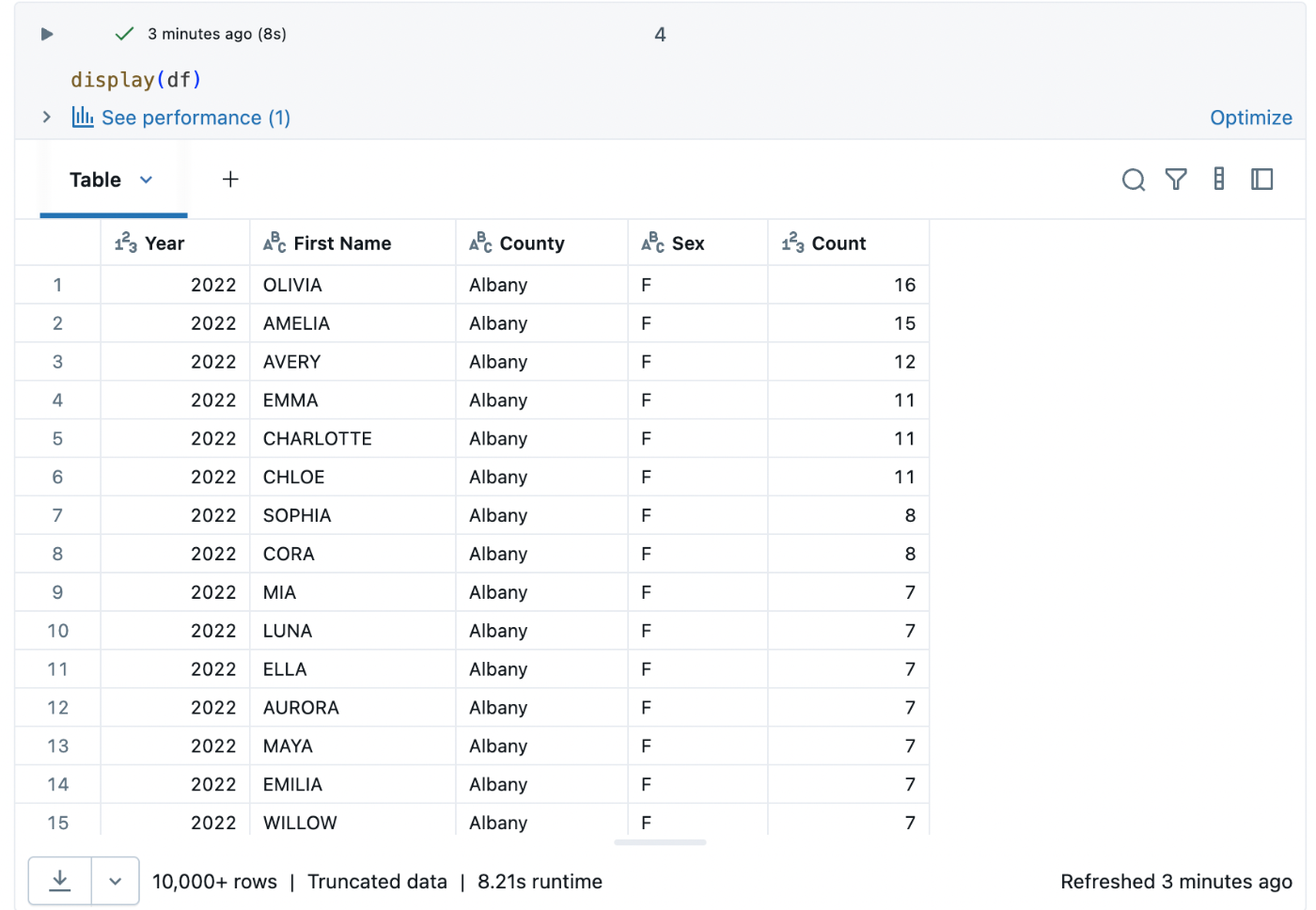
📊 データを視覚化してみた
表形式のままだと味気ないので、「Visualization」をクリックします。
チュートリアル通りに Word Cloud を表示してみました。
頻度はチュートリアルと異なり「50」を設定。
“David” など、聞き覚えのある名前がたくさん出てきて面白かったです!

✨ 終わりに
初めて Databricks のチュートリアルを触ってみましたが、想像以上に簡単でした!
Snowflake にも触れた経験がありますが、Databricks でも USE 文など馴染みのある SQL が使えるのが嬉しかったです。
データのインポートから可視化までスムーズに行えるのはとても楽で魅力的に感じました。
今回はここまで。
それでは、また!

Discussion