概要
対象者:
データベースの技術に興味があるエンジニアや開発者
内容:
オープンソースの分散SQLデータベース「TiDB」の特徴、HTAPの概念、実際の導入手順やチュートリアルの紹介
記事を読むとわかること:
TiDBの基本的な特徴と利点、HTAPの概念、分散SQLデータベースの仕組み、実際の導入手順とチュートリアルの流れ
序章
みなさんTiDB(「たいディービィー)はご存知でしょうか?
TiDBは何と言っても、ハイブリッドトランザクションおよび分析処理 (HTAP) ワークロードをサポートするオープンソースの分散 SQL データベースです。
今日はその導入の紹介をします。
HTAPについて
「ハイブリッド トランザクションおよび分析処理」を英語にすると
Hybrid Transactional and Analytical Processingです。
この頭文字をとってHTAPと呼びます。
「ハイブリッドトランザクション」ではなく、トランザクションと分析処理のハイブリットという意味です。
では次に、トランザクションとは?分析処理とは?を説明します
トランザクション処理
OLTP: Online Transaction Processingとも呼ばれます。
データベースにデータを頻繁に書き込み、更新する操作を行います。
例えば、銀行の取引やオンラインショッピングの購入処理などが含まれます。
分析処理
OLAP: Online Analytical Processingとも呼ばれます。
データベースから大量のデータを読み込み、集計や分析を行います。
例えば、売上データの分析や顧客行動の分析などが含まれます。
HTAPの利点
HTAPのメリットを説明します。
-
一元化
トランザクションデータと分析データを同じデータベースで管理できるため、データの一貫性が保たれます。 -
リアルタイム分析
トランザクションデータが即座に分析処理に利用できるため、リアルタイムでの意思決定が可能です。 -
コスト削減
トランザクション処理用と分析処理用の二重のデータベース管理が不要となり、システムのコストが削減されます。
つまり、HTAPを導入すると、トランザクション処理用と分析処理用のデータベースを別に管理する必要がなくなり、データの一貫性やリアルタイム性、運用コストを抑えられるというお話です。
分散SQLデータベースについて
分散SQLデータベースとは、分散型アーキテクチャを採用したsqlDBです。
では、分散型アーキテクチャとはなんでしょうか?
分散型アーキテクチャとは、データを複数のサーバーに分散して保存・処理する仕組みです。
一つのサーバーにかかる負荷を軽減し、システム全体のパフォーマンスや信頼性を向上させることができます。
特にTiDBでは、TiDBサーバ、TiKVサーバ、PDの3つのコンポーネントで構成されています。
(下の図を先に見るとイメージしやすいかも)
TiDBサーバ
役割
SQLクエリの解析と実行を担当します。
特徴
ステートレス(状態を持たない)であり、リクエストごとに独立して動作します。
これにより、スケーラビリティが高く、必要に応じて簡単にサーバーを追加できます。
TiKVサーバ
役割
データの保存と管理を担当します。
特徴
データの永続性を確保し、キー(Key)とバリュー(Value)のペア形式でデータを保存します。
(そのためKVと名がつく)
分散ストレージとして機能し、データの一部を各TiKVサーバーに分散して保存します。
Placement Driver(PD)
役割
クラスタ全体のメタデータ管理とスケジュールを担当します。
特徴
データの分散配置を管理し、各TiKVサーバーの負荷をバランスさせます。
また、データの複製や再配置などを行い、高可用性を実現します。
分散アーキテクチャのメリット
次に、分散アーキテクチャのメリットを紹介します。
負荷分散
データと処理が複数のサーバーに分散されるため、高い負荷がかかっても各サーバーの負担が軽減され、システム全体のパフォーマンスが向上します。
高可用性
データが複数のサーバーに複製されて保存されるため、1つのサーバーが故障しても他のサーバーがデータを保持しており、サービスの継続運用が可能です。
スケーラビリティ
データ量やアクセス数が増加した場合でも、サーバーを追加することで簡単にシステムの処理能力を拡張できます。
データの読み書きの流れ
コンポーネントとメリットがざっくり見てきましたが、次に実際の動きを説明します。
①クライアントがSQLクエリを送信
クライアント(例えば、アプリケーション)がSQLクエリをTiDBサーバーに送信します。
②TiDBサーバーがクエリを解析
TiDBサーバーがSQLクエリを解析し、どのデータが必要かを決定します。
③PDがデータの場所を提供
PDがどのTiKVサーバーに必要なデータが保存されているかを教えます。
④TiKVサーバーからデータを取得
TiDBサーバーが対応するTiKVサーバーにアクセスしてデータを取得します。
⑤クライアントに結果を返す
TiDBサーバーがデータを処理し、クエリの結果をクライアントに返します。
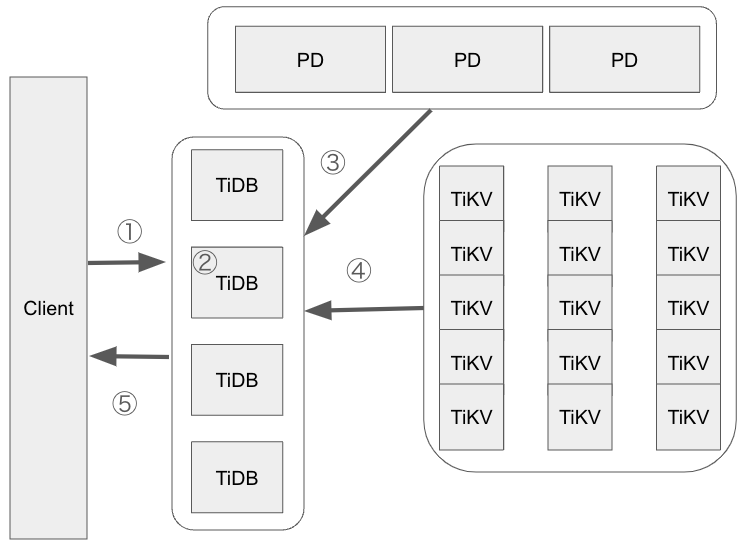
上記は、ざっくりとした流れになっています。
詳しく知りたい方はぜひ、公式ドキュメントを参照してください。
TiDBの実践
実際に、アカウントを作成して、TiDBのチュートリアルを使ってみたいと思います。
TiDBは無料枠があり、登録、チュートリアルの実行は無料でできます。
詳しくはこちら。
アカウント登録
tidbのリンクを開きます。
右上の「無料で始める」ボタンをクリックします
アカウントを登録します。
アカウント登録が成功すると、TiDB Cloudのページに移動します
チュートリアル
早速チュートリアルをしていきます
右下の?ボタンをクリックします
Help画面が表示されますので、「Interactive Tutorials」をクリックします。
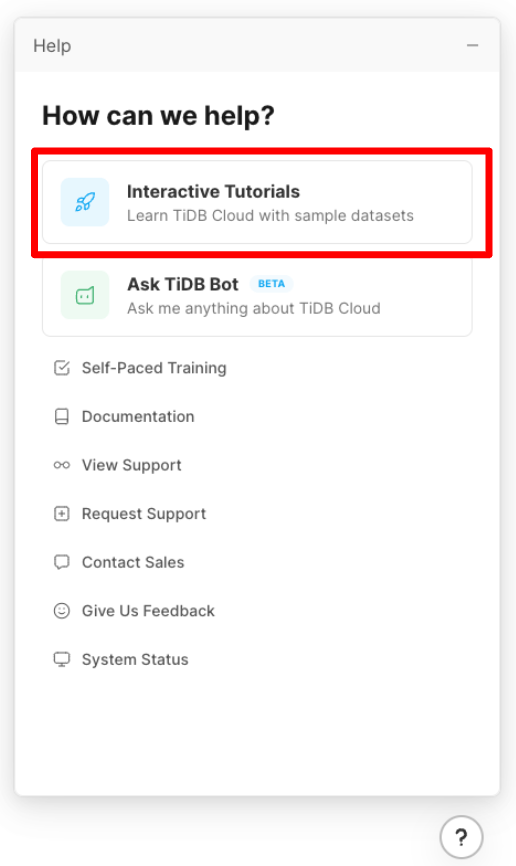
チュートリアルは複数あります。今回は「Steam Game Stats」を選択します。
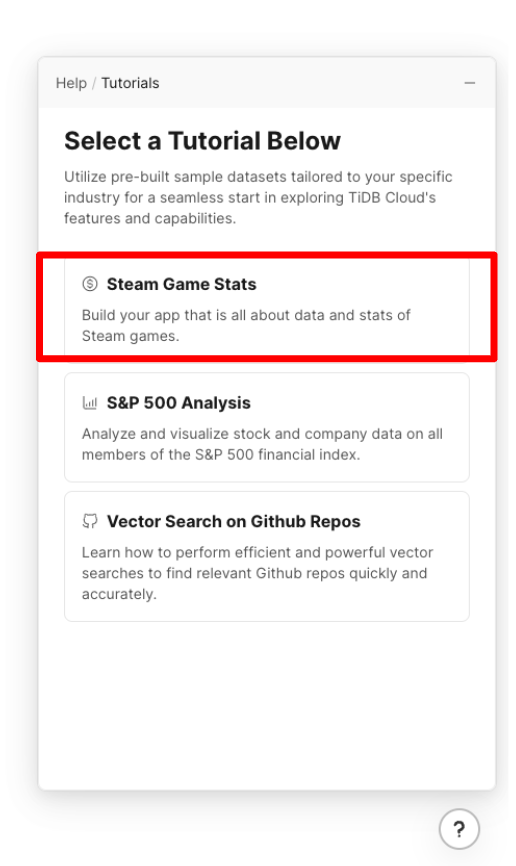
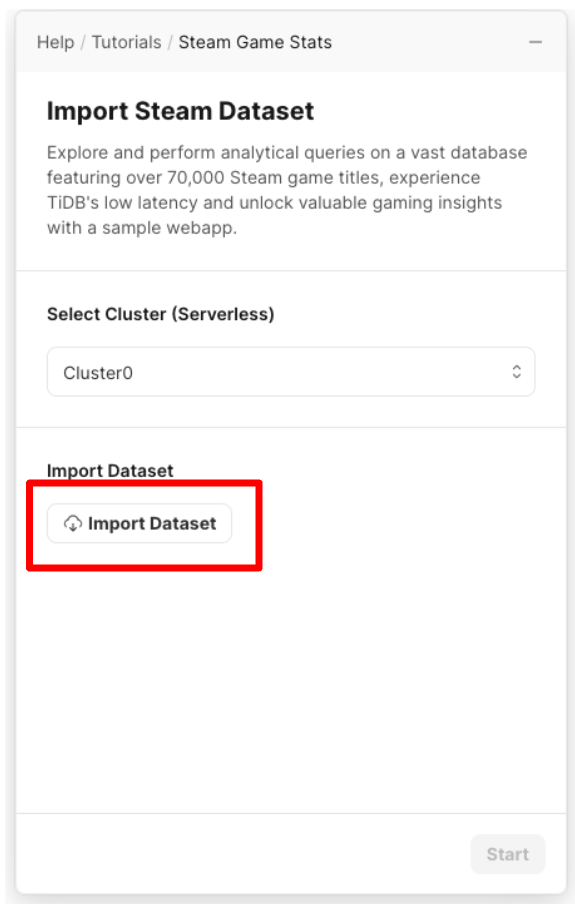
クラスターを選択し、import Datasetをクリックします。
ここでデータをインポートします。
1分ほど待ち「start」ボタンが青くなれば、インポート完了です。
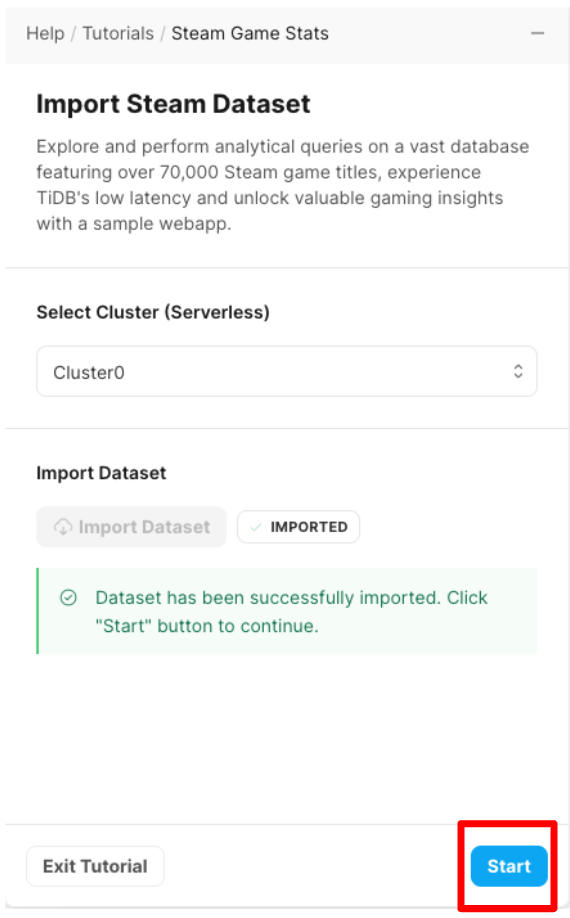
次は、sql文が出てきます。「Paste into SQL Editor」をクリックします。
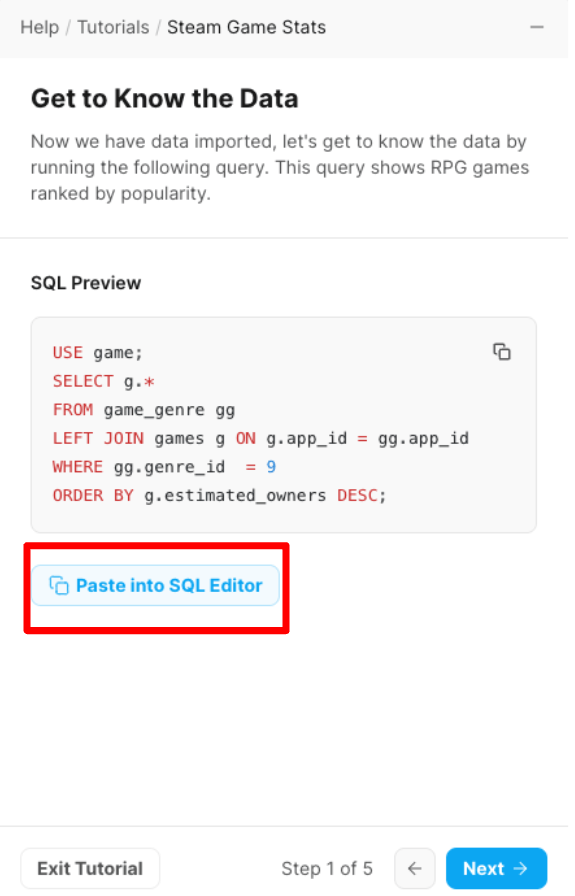
「Go to the SQL Editor?」と表示されるので「OK」をクリックします。
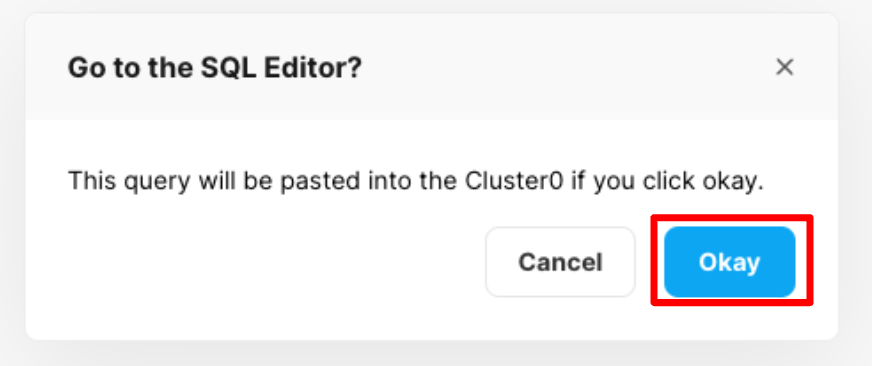
その後、Editor上にSQL文がコピーされます。
右上の「▶️」か「command+Enter」で実行ができます
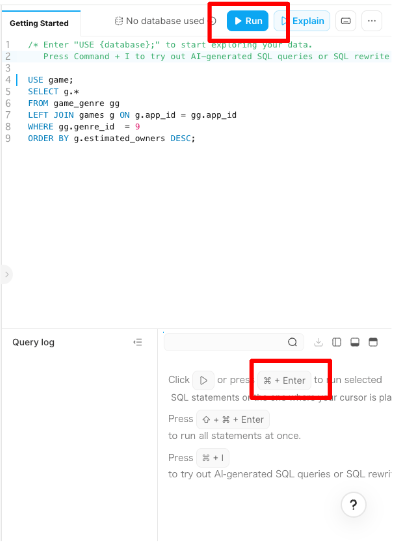
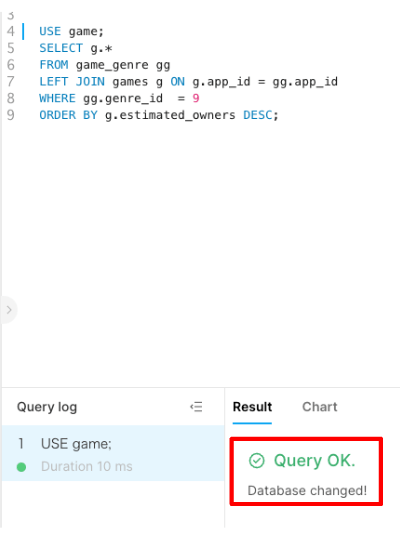
同様にQuery1、Query2を実行していきます
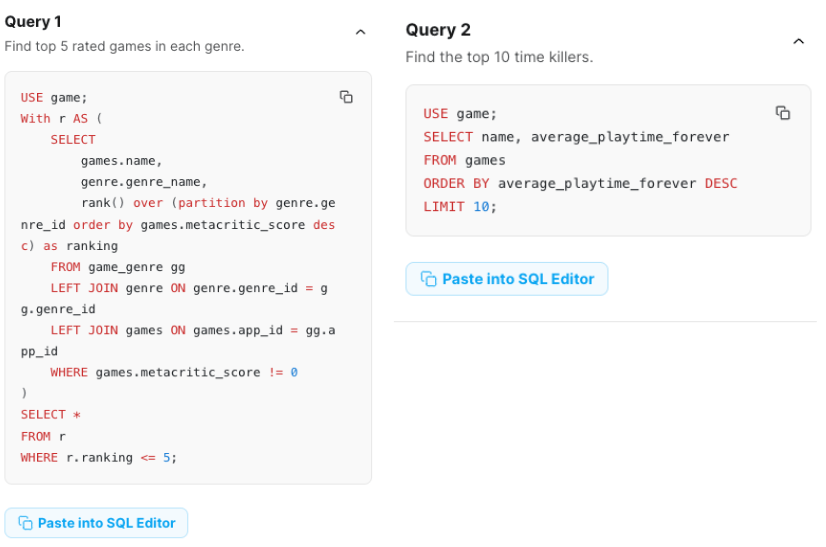
結果は以下のようになります。
確かに、genreごとのtop5のゲームとplaytimerのtop10が選択できています。
ここまではよくあるsql editorだと思います。
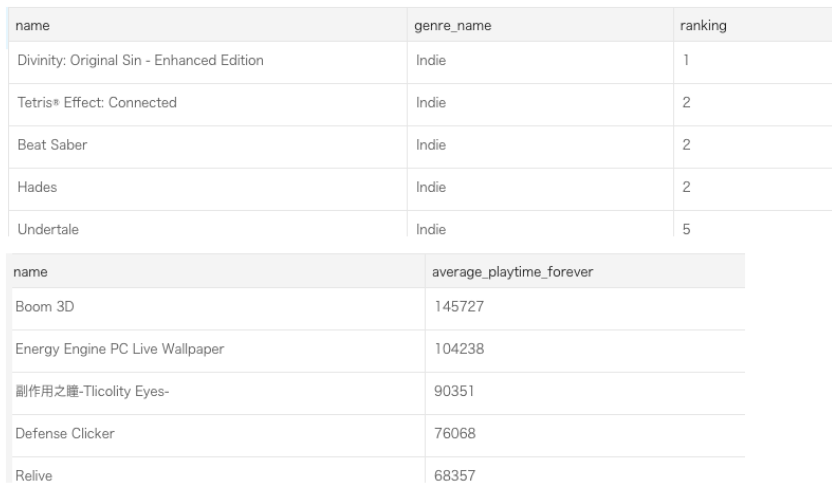
次は、text to sqlです。
まず、「comand + I」を入力します。
そして、「Top 10 popular games」と入力し、送信ボタンをクリックします。
すると、sql文を生成されます。
結果も表示されました。

さらに、vercelで、データの可視化もすることができます。
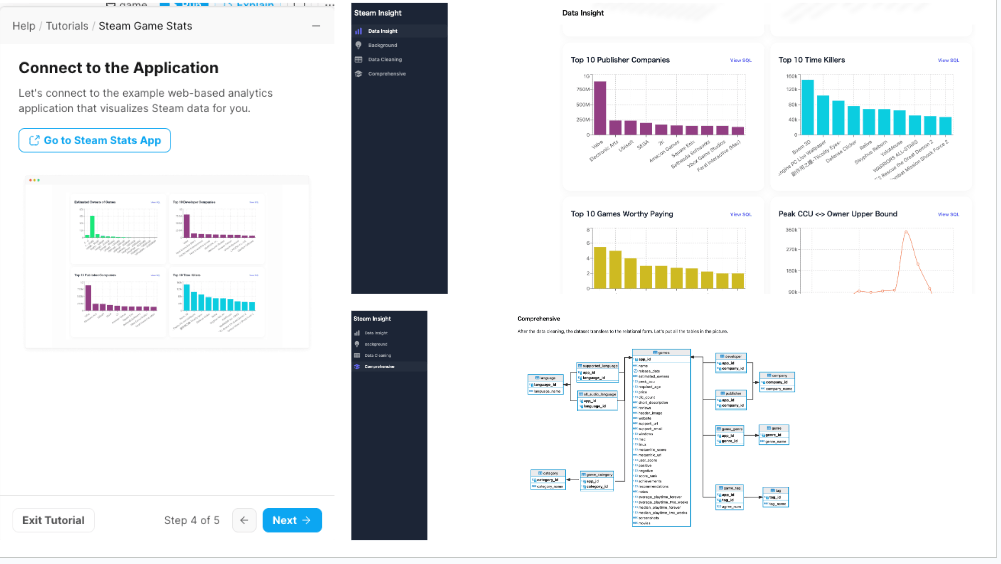
結言
TiDBを活用して、トランザクション処理と分析処理を一元化し、より効率的なデータベース運用を実現しましょう。

Discussion