Google AI Edge Gallery動かしてみた: スマホで動くオフラインAI検証
はじめに
2025 年 5 月、Google が AI 業界に衝撃を与える新しいアプリケーション「Google AI Edge Gallery」をリリースしました。このアプリは、これまでクラウドベースが主流だった生成 AI をスマートフォン上で完全オフラインで実行できる画期的な技術です。ChatGPT や Gemini のようなクラウド AI サービスとは異なり、一度モデルをダウンロードすれば、インターネット接続なしで AI チャット、画像解析、プロンプト実行が可能になります。
この記事では、実際に Google AI Edge Gallery をインストールして各機能を試し、その過程のインストール方法や動作の様子をお見せしたいと思います。
スクリーンショットをいくつか張り付けているので、試す場合はぜひ参考にしていただければ幸いです!
前提知識・背景
Google AI Edge Galleryとは
Google AI Edge Gallery は、Google が開発した実験的なオープンソースアプリケーションで、Android(現在)および iOS(近日公開予定)デバイス上で生成 AI モデルを完全にローカルで実行できるように設計されています。このアプリの最大の特徴は、モデルを一度ダウンロードすれば、インターネット接続なしで動作する点にあります。
アプリは Apache 2.0 ライセンスの下でオープンソース化されており、GitHub で公開されています。現在は「実験的なアルファリリース」として位置付けられ、開発者コミュニティからのフィードバックを積極的に収集しています。
技術的基盤
このアプリは、Google の包括的な AI Edge エコシステム上に構築されています
- LiteRT(旧TensorFlow Lite): モバイルデバイス向けに最適化された軽量ランタイム
- Google AI Edge API: オンデバイス機械学習のためのコア API
- LLM推論API: 大規模言語モデルのオンデバイス実行を支援
- Hugging Face統合: オープンソースモデルの発見とダウンロード機能
インストール方法
動作要件
Google AI Edge Gallery を利用するためには、以下の要件を満たす Android デバイスが必要です
【要件】
- OS: Android 10 以上
- RAM: 6GB 以上(推奨8GB 以上)
- ストレージ: 5GB 以上の空き容量
- チップセット: 現代的なプロセッサー(Snapdragon 8 Gen 系、MediaTek Dimensity 系など)
【検証した端末】
-
Pixel 6a
かれこれ4年弱ほど使っている古い端末ですが、これでも動くことが検証できています!
インストール手順
現在、Google AI Edge Gallery は Google Play Store では提供されておらず、APKファイルを使用したサイドローディングが必要です。
方法1: 直接APKをダウンロード
-
開発者向けオプションを有効化
- 設定 → デバイス情報 → ビルド番号を 7 回タップ
- 「開発者になりました!」と表示されれば成功
-
提供元不明のアプリを許可
- 設定 → セキュリティ → 提供元不明のアプリ → ファイルマネージャーを許可
-
APKファイルをダウンロード
- GitHub の公式リポジトリにアクセス
- 「Releases」セクションから最新の APK ファイルをダウンロード

-
インストール実行
- ダウンロードした APK ファイルをタップ
- インストールの確認画面で「インストール」を選択
方法2: ADBを使用(開発者向け)
# USB デバッグを有効にした後
adb install -t ai-edge-gallery.apk
セットアップ
1. アプリを起動
- インストール完了後、アプリアイコンをタップして起動
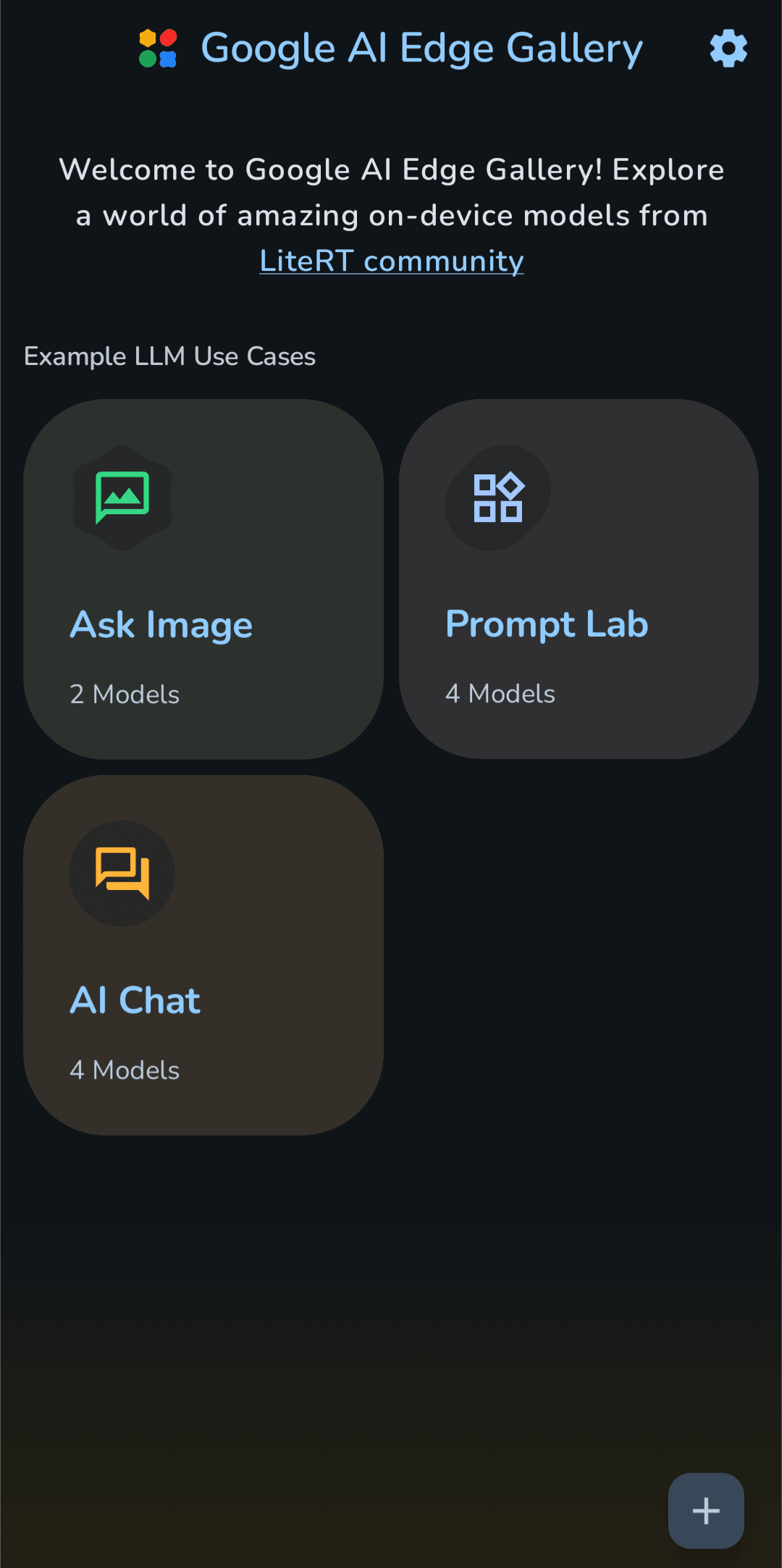
- アプリを起動すると、シンプルで直感的なホーム画面が表示されます。主要な機能は以下の 3 つのカテゴリに分かれています
- AI Chat: 多ターン会話形式のチャットボット
- Ask Image: 画像に対する質問応答
- Prompt Lab: 単発タスクのプロンプト実行
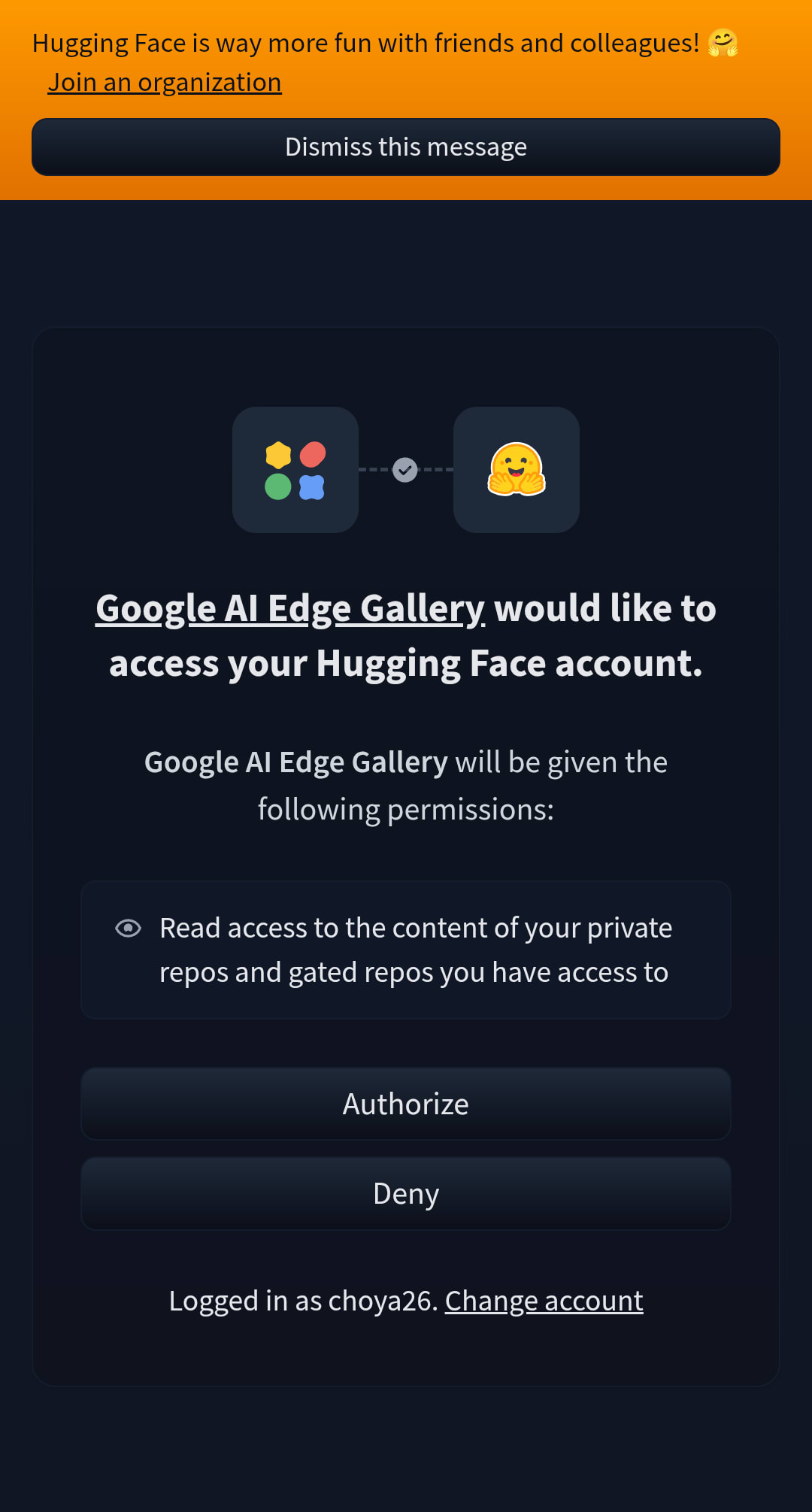
2. Hugging Faceアカウントでサインイン
- AI モデルをダウンロードするため、Hugging Face アカウントが必要
- アカウントがない場合は無料で作成可能
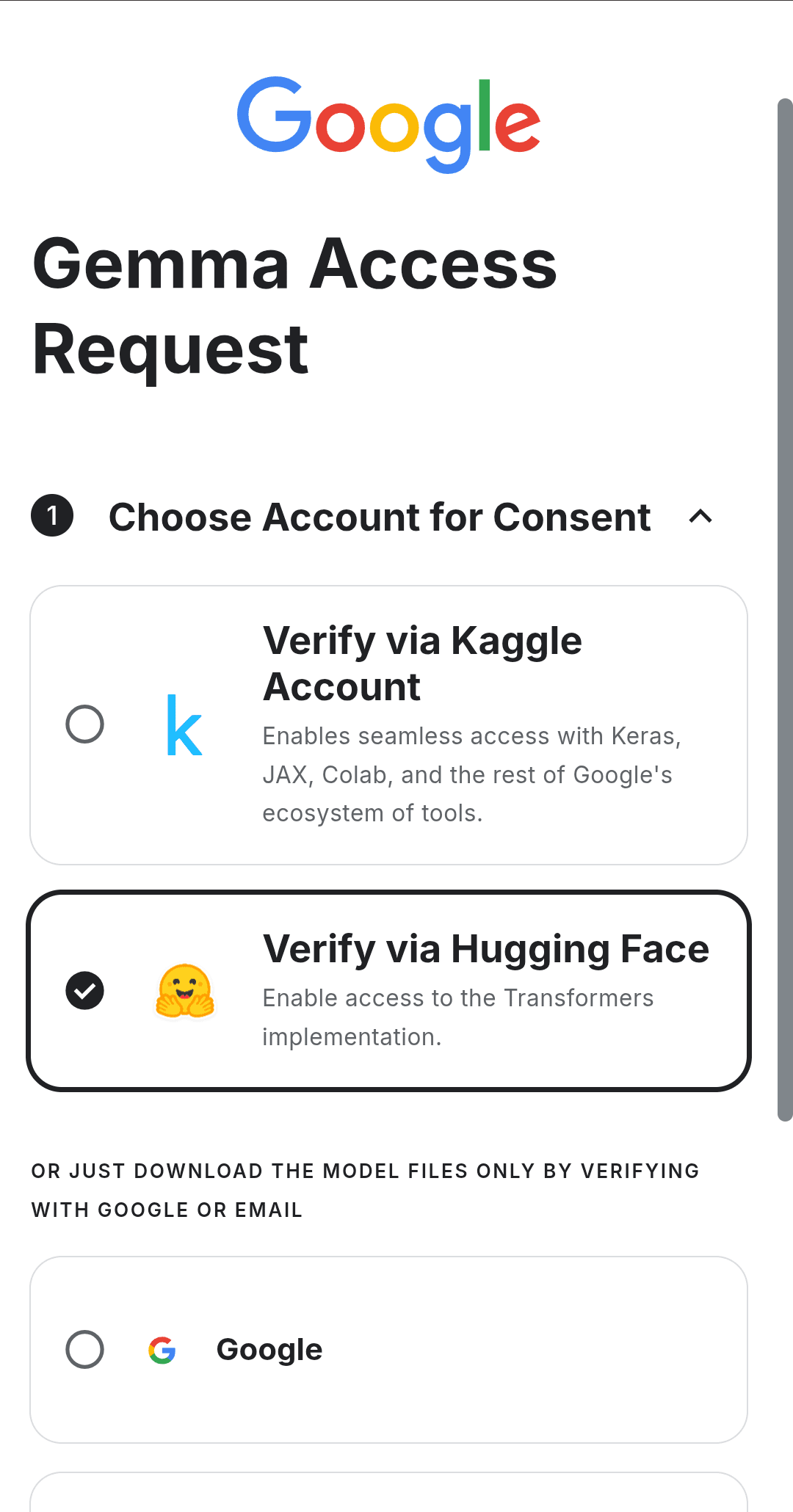
3. 利用規約への同意
- 各モデルの利用規約を確認し、同意が必要
4. モデルのダウンロード
利用可能なAIモデル
-
Googleモデル
- Gemma 3n(E2B/E4B): 最新のモバイル最適化モデル
- Gemma 3 1B/4B/12B/27B: 用途に応じたサイズ展開
- Gemma 2 2B: 前世代の軽量モデル
- MediaPipe: マルチモーダル処理用
-
サードパーティモデル
- Microsoft Phi-4-mini
- Alibaba Qwen 2.5 シリーズ
- DeepSeek-R1
- Ollama TinyLlama/Llama-3.2 シリーズ
- Hugging Face SmolLM-135M
-
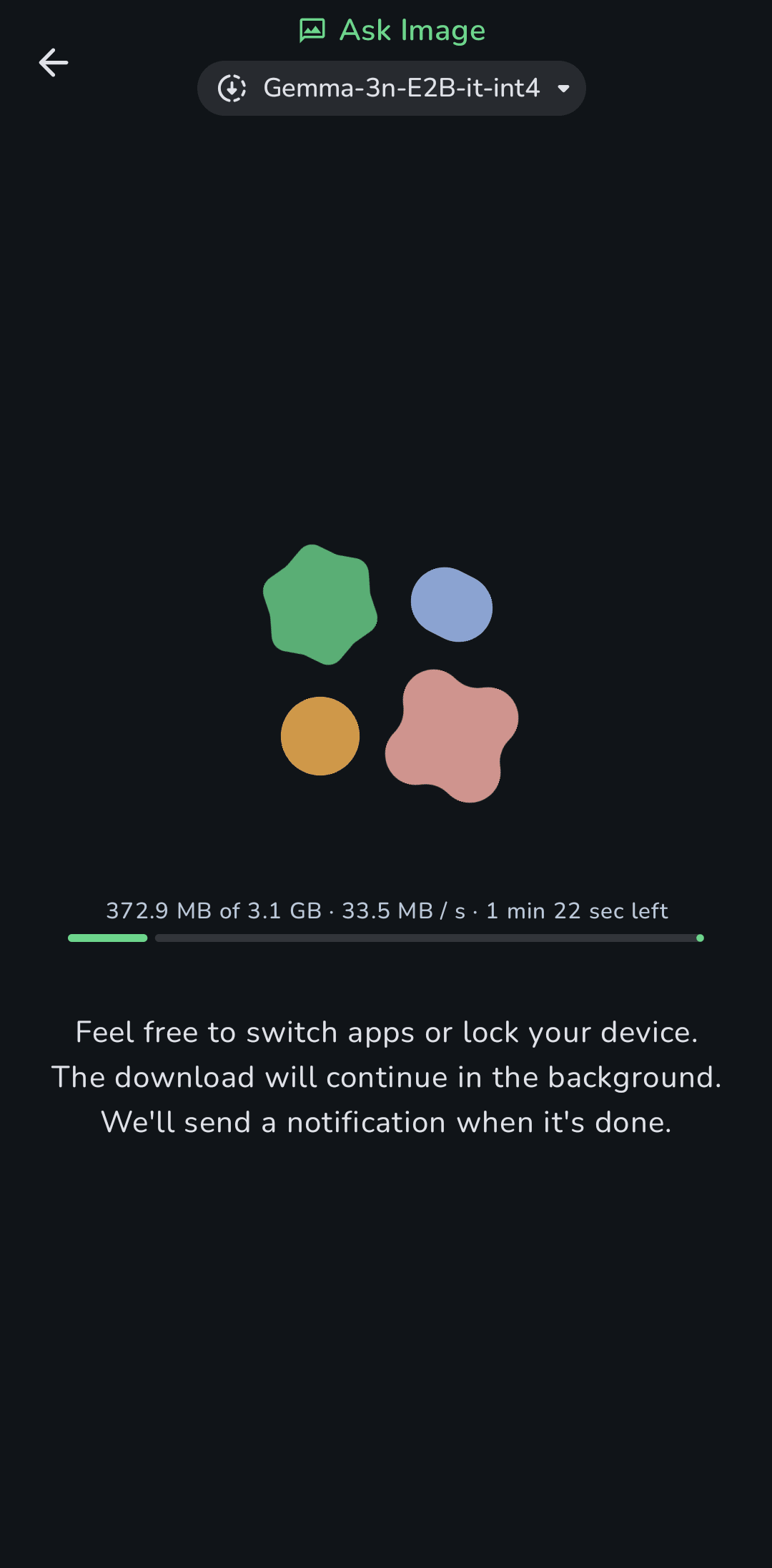
Ask Imageモデルとして Gemma-3n-E2Bをダウンロードしてみた例。数分でダウンロード完了。
機能を試してみた
画像認識タスク
Ask Imageモードで回転寿司の手を洗うところお湯を注ぐところの画像を見せてみて、何をするものなのかを尋ねてみました。もはや定番ですね。

結果としては認識できていませんが、20秒ほどで回答し終わり、十分ローカルでモデルが動く様子の確認としては十分だと思います。
コーディングタスク
Prompt Labでコードを作成することもできます。
試しにTransformerの基本であるScaled Dot-Product AttentionGemma-3n-2Bに書かせてみました。
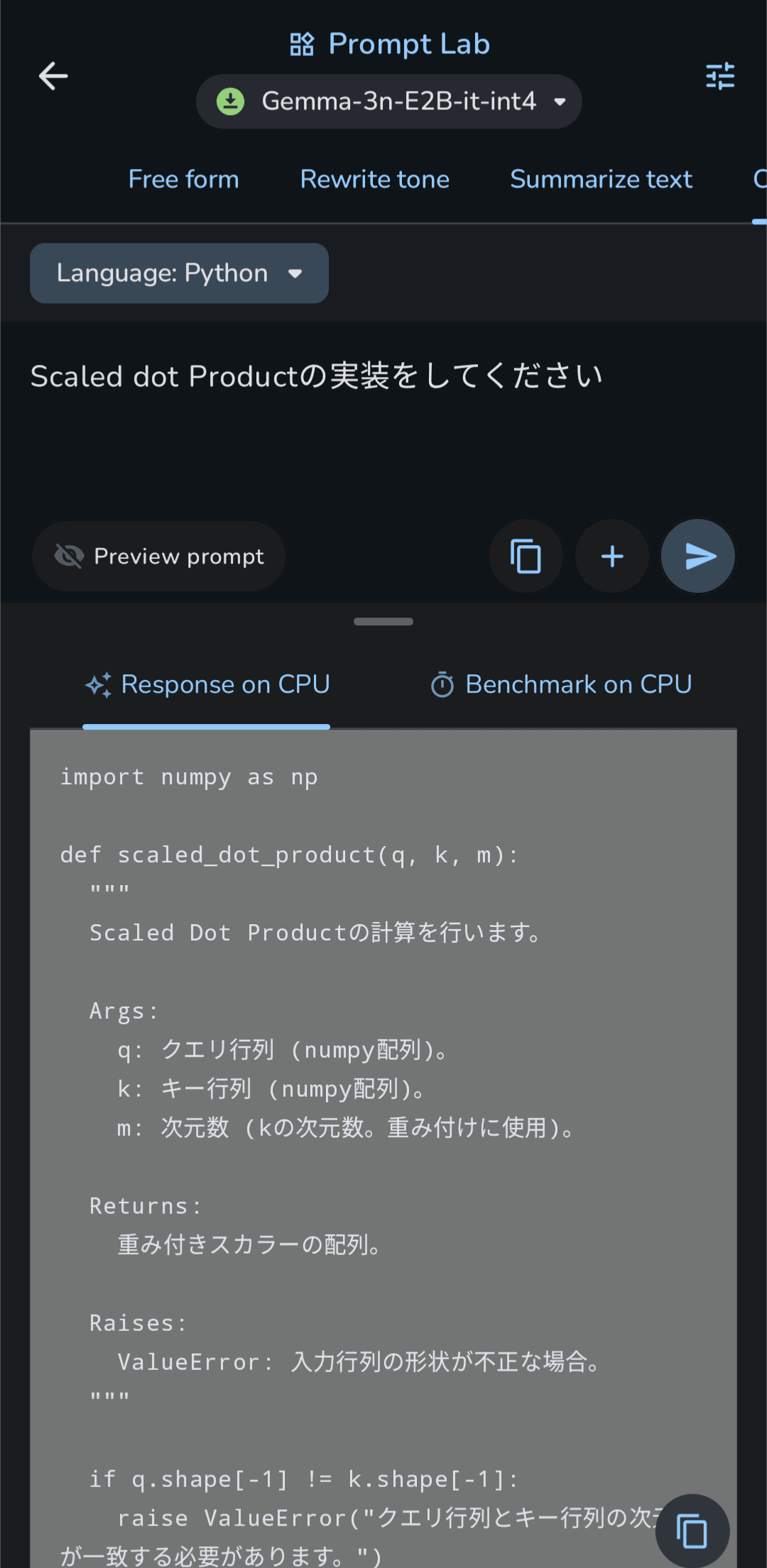
生成した全量
import numpy as np
def scaled_dot_product(q, k, m):
"""
Scaled Dot Productの計算を行います。
Args:
q: クエリ行列 (numpy配列)。
k: キー行列 (numpy配列)。
m: 次元数 (kの次元数。重み付けに使用)。
Returns:
重み付きスカラーの配列。
Raises:
ValueError: 入力行列の形状が不正な場合。
"""
if q.shape[-1] != k.shape[-1]:
raise ValueError("クエリ行列とキー行列の次元数が一致する必要があります。")
# ドット積を計算
dot_product = np.matmul(q, k.T)
# 次元数によるスケーリングと重み付けを適用
scaled_dot_product = dot_product / np.sqrt(m)
return scaled_dot_product
if __name__ == '__main__':
# テスト例
q = np.array([[1, 2], [3, 4]])
k = np.array([[5, 6], [7, 8]])
m = 2 # 次元数
result = scaled_dot_product(q, k, m)
print("Scaled Dot Product Result:
", result)
#別の例
q2 = np.array([[1, 0, 0], [0, 1, 0]])
k2 = np.array([[1, 1, 1], [1, 1, 1]])
m2 = 3
result2 = scaled_dot_product(q2, k2, m2)
print("Scaled Dot Product Result 2:
", result2)
# エラーケースのテスト
try:
q3 = np.array([[1, 2], [3, 4]])
k3 = np.array([[5, 6], [7, 8]])
m3 = 3
scaled_dot_product(q3, k3, m3)
except ValueError as e:
print("ValueErrorが発生しました:", e)
このコードの説明:
-
scaled_dot_product(q, k, m)関数:-
q: クエリ行列を引数として受け取ります。 -
k: キー行列を引数として受け取ります。 -
m: 次元数です。この値は、スケーリングの係数に使用されます。 -
エラーチェック: まず、クエリ行列とキー行列の次元数が一致していることを確認します。一致していない場合は、
ValueError例外を発生させます。 -
ドット積:
np.matmul(q, k.T)を使用して、クエリとキーのドット積を計算します。k.Tでキー行列を転置させています。 -
スケーリングと重み付け: 次に、ドット積を
np.sqrt(m)でスケーリングして調整し、結果のベクトルを返します。 -
戻り値:
scaled_dot_productの結果を返します。
-
-
if __name__ == '__main__':ブロック:- これは、スクリプトが直接実行された場合にのみ実行されるコードです。
- テスト用のデータ (
q,k,m) を作成します。 -
scaled_dot_product関数を呼び出し、結果を出力します。
-別のテストケースも追加しました。 - エラーケースのテストも行っています。次元数が一致しない場合にエラーが発生するようにテストします。
-
ValueErrorが発生した場合に適切なメッセージを出力するようになっています。
なぜscaled dot productが必要なのか?
従来の dot product を使うと、入力の次元数が大きい場合に、勾配が小さくなりすぎることがあります。 この問題を軽減するため、scaling factor を導入します。 scaling factor は、モデルのパラメータ数によって調整します。 scaled dot productは、大規模な機械学習モデルでは非常に一般的なテクニックです。 多くの場合、ニューラルネットワークの入力変換の一部として利用します。
生成には3分強とやや時間がかかってしまっていますが、出力としては十分なものが得られました。
感想
ローカルで言語モデルを動かしてみるのに、とても簡単で試しやすいので良い機会だなと思いました。
回答精度がまだまだなケースはあるものの、おおむね基本的な会話はできており軽量モデルでここまでできるのかと関心しました!
速度的にも不自由ない程度で、Pixel 6aのような古い端末でも2年前くらいのGPT-4のときくらいの速度はでていたので、最新の端末でやってみたら十分なのではないかなと思います。
現在はまだ「実験的なアルファリリース」という位置付けですが、IOSでの展開やGoogle Play Storeでの正式公開など今後あるかもしれませんので、その際にもぜひ試してみてください!
参考セクション:
Discussion