少ないデータで動作を理解:TP-CLIPの時間プロンプティングがすごい理由
はじめに
動画から動作を理解する技術(動作認識)は、自動運転やロボディスク、監視システムなど多くの分野で重要です。しかし、従来の動作認識モデルは大規模なラベル付きデータに依存しており、データが少ない状況(ゼロショットや少ショット学習)では性能が大きく低下する課題がありました。
そこで注目を集めているのが、視覚ー言語モデル(Vision-Language Model)です。2025年4月に発表された論文「Is Temporal Prompting All We Need For Limited Labeled Action Recognition?」で提案されたTP-CLIPは、CLIPをベースに、時間プロンプティング(Temporal Prompting)とアダプター(Adapter)を導入し、少ないデータで高い動作認識性能と効率性を実現しました。
この記事では、TP-CLIPのTemporal PromptingとAdapterがなぜすごいのか、その仕組みと効果を徹底解説します。具体的には、以下のポイントを紹介します:
- TP-CLIPの概要とTemporal Prompting・Adapterの役割
- Temporal PromptingとAdapterの仕組み
- 実験結果から見るTP-CLIPのインパクト
TP-CLIPとは?Temporal PromptingとAdapterの役割
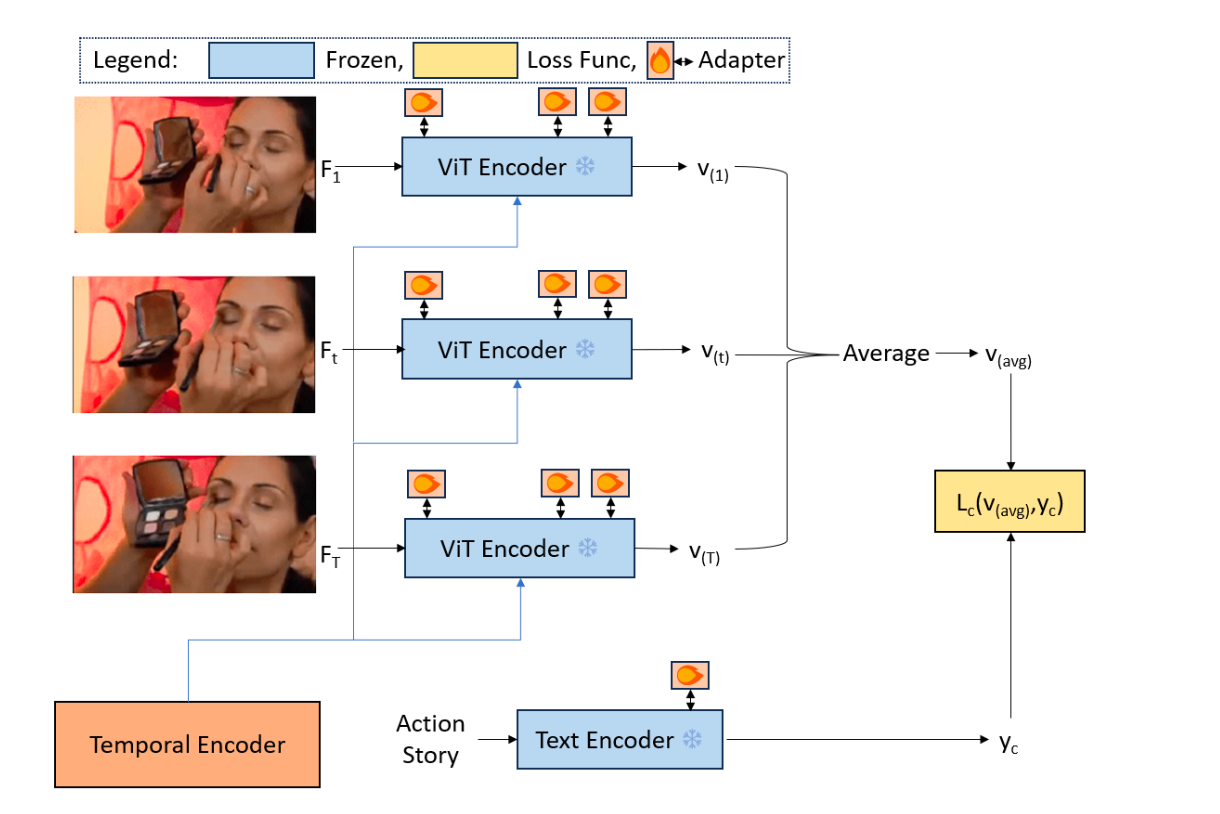
TP-CLIPの概要
TP-CLIPは、CLIPをベースにしたモデルです。CLIPは画像とテキストのペアを大規模に学習し、高い汎化性能を示すことで知られています。しかし、CLIPは元々画像向けに設計されており、動画の時間情報(フレーム間の動的変化)を直接扱うことができません。
TP-CLIPは、この課題を解決するために、以下の二つの技術を導入しました:
- Temporal Prompting:動画全体の時間情報を抽出し、各フレームに付加することで動作の動的パターンを捉える。
- Adapter:CLIPのTransformer層に挿入し、空間特徴を微調整することで、CLIPのコアアーキテクチャを凍結しながら動画タスクに適応する。
これにより、TP-CLIPはゼロショットや少ショット学習で高い性能を実現しつつ、計算コストを大幅に削減しています(GFLOPs 94、SOTAの1/3; 総可変パラメータ 4.4M、SOTAの1/28)。
Temporal Promptingの役割
Temporal Promptingは、動画全体の時間コンテキストを抽出し、各フレームの埋め込みに付加する技術です。これにより、フレーム間の動的情報(例えば、手の動きの連続性)を捉え、動作の全体的なパターンを理解します。ゼロショットや少ショットタスクにおいて、unseen classesをテキスト記述だけで認識する能力を強化します。
Adapterの役割
Adapterは、CLIPのTransformer層に挿入される軽量なモジュールです。主な役割は以下の通りです:
- 空間特徴の微調整:CLIPの画像ベースの特徴を動画タスクに適応させる。
- 汎化能力の維持:CLIPのコアパラメータを凍結し、Adapterのみを訓練することで過学習を防ぐ。
- 効率的な学習:Adapterのパラメータは非常に少なく、全体のわずか5%にとどまる。
Temporal PromptingとAdapterの仕組み
Temporal Promptingの生成プロセス
TP-CLIPのTemporal Promptingは、時間エンコーダ(Temporal Encoder)によって実現されます。以下のステップで時間プロンプトを生成し、各フレームに付加します。
1、フレーム埋め込みの生成
各フレーム(
2、フレーム埋め込みの連結
全てのフレームの埋め込みを時間軸に沿って連結し、2次元テンソルにします:
3、Conv1Dで時間パターンを抽出
連結した埋め込みに1次元畳み込み(
4、全結合層(
5、時間プロンプトの付加
生成した
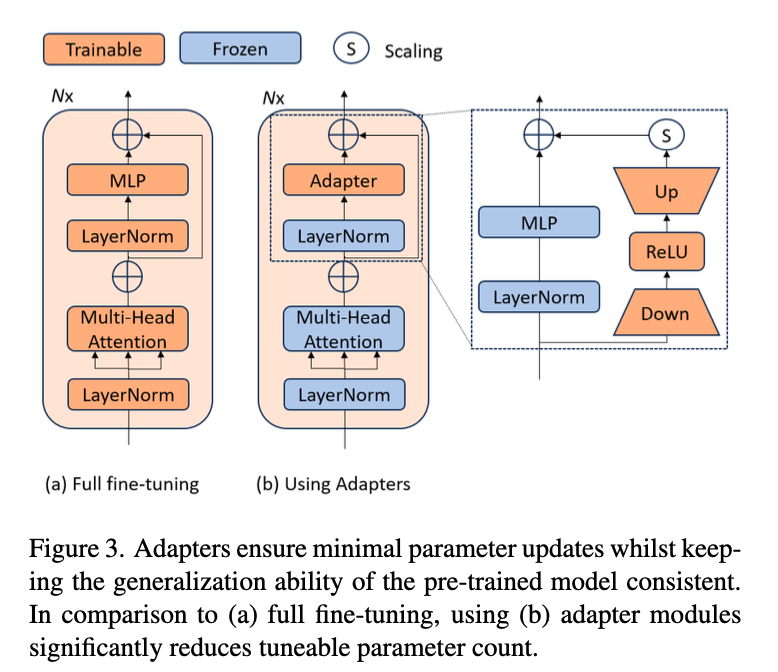
Adapterの仕組み
Adapterは、CLIPのViT Encoder内のTransformer層に挿入される軽量なモジュールです。
構造:
- Down:入力次元を低い次元に圧縮。
- ReLU:非線形性を導入。
- Up:元の次元にも戻す。
- 残差接続:入力にAdapterの出力を加算。
\text{Output}=\text{Input} + S \cdot {\text{Adapter(\text{Input})}}
S
実験結果
TP-CLIPは、ゼロショット、少ショット、Base-to-Novelタスクで優れた性能を示しました。以下に、論文の主要な結果を紹介します。
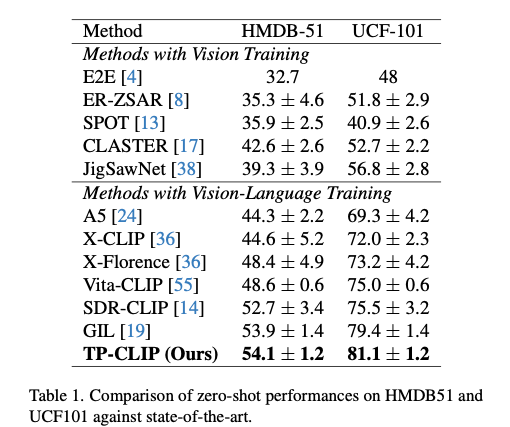
ゼロショット
Temporal PromptingとAdapterにより、未見のカテゴリをテキスト記述だけで正確に認識できました。
- UCF-101:81.1%(SOTA比+1.7%)
- HMDB-51:54.1%(SOTA比+0.2%)
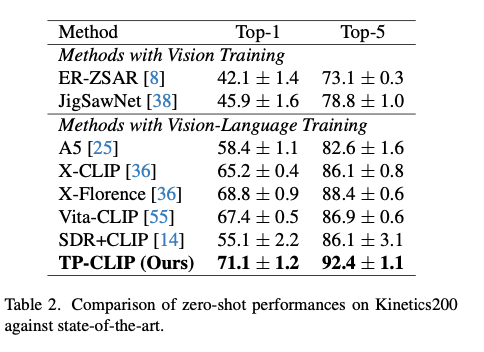
- K600(Top-1):71.1%(SOTA比+2.3%)
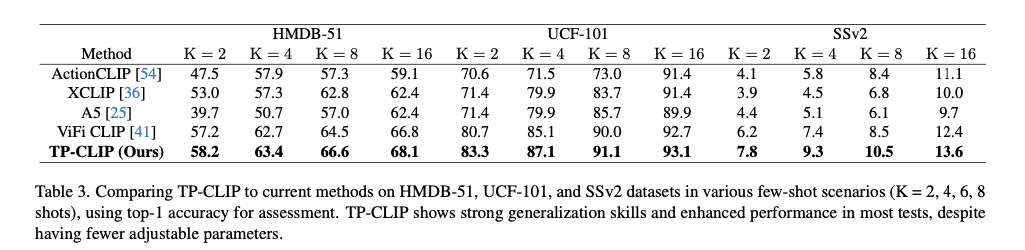
少ショット
少ないデータでも高い性能を発揮しました。
- HMDB-51(16-shot):68.1(SOTA比+1.3%)
- UCF-101(16-shot):93.1%(SOTA比+0.4%)
- Sv2(16-shot):13.6%(SOTA比+1.2%)
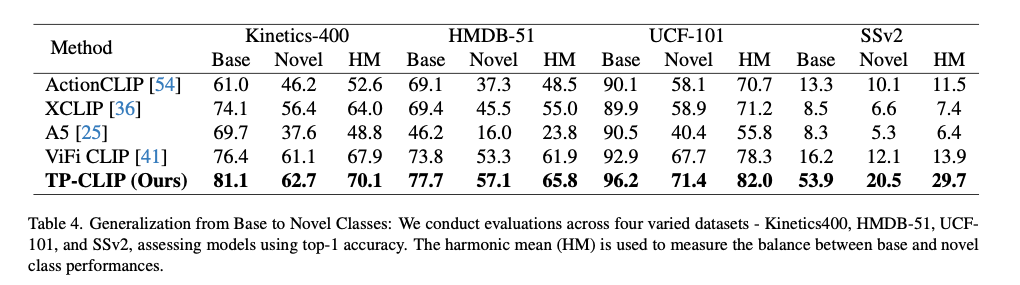
Base-to-Novel
Base-to-Novelタスクでは、訓練済みカテゴリ(base classes)から未見カテゴリ(unseen classes)への汎化能力を評価します。SSv2での大幅な性能向上は、Temporal PromptingとAdapterが動作の動的パターンを捉えるのに有効であることを示しています。
- Kinetics-400:HM 70.1%(SOTA比+2.2%)
- HMDB-51:HM 65.8%(SOTA比+3.9%)
- UCF-101:HM 82.0%(SOTA比+3.7%)
- SSv2:HM 29.7%(SOTA比+15.8%)
結論
TP-CLIPは、Temporal PromptingとAdapterを活用することで、少ないデータでも動作を理解する能力を獲得しました。
- 少ないデータで動作を理解
Temporal Promptingは動画全体の時間情報を各フレームに付加し、Adapterは空間特徴を微調整することで、動作の動的パターンを効率的に捉えます。これにより、ゼロショットや少ショットのようなデータが限られた状況でも高い性能を発揮します。たとえば、UCF-101でゼロショット81.1%を達成し、従来手法を大きく上回りました。 - 効率性と性能の両立
Temporal PromptingとAdapterは軽量な設計でありながら、動作認識の精度を飛躍的に向上させます。TP-CLIP全体の計算コストも低く、GFLOPsはSOTAの1/3、可変パラメータは1/28、実用性が高いです。 - 汎化能力の強化
Temporal PromptingとAdapterの協調により、未見のカテゴリへの汎化能力が強化されます。Base-to-NovelタスクでSSv2のHMが29.7%(SOTA比+15.8%)に達したのは、時空間情報を統合した埋め込みが新クラスの動作パターンを捉えるのに有効だったためです。
論文
Gowda, S.N., Gao, B., Gu, X. and Jin, X., 2025. Is Temporal Prompting All We Need For Limited Labeled Action Recognition?. arXiv preprint arXiv:2504.01890.
Discussion