
ちょっと株式会社 アドベントカレンダー2023 12月22日の記事です。
はじめに
どうも、デジタルネイティブ世代の息子(4歳)を持つエンジニアです。
子供の成長は日々早く、いつの間にかタブレットの使い方を覚えて、器用にスワイプしたり、YouTubeを見たりしています。
アプリで遊ぶ息子の姿を見て、「パパが作ったアプリで遊ばせてみたい」という気持ちから、
音声入力・自動出力アプリを作りました。
作ったアプリ
■mic.
■リポジトリ
■アプリイメージ(静止画)
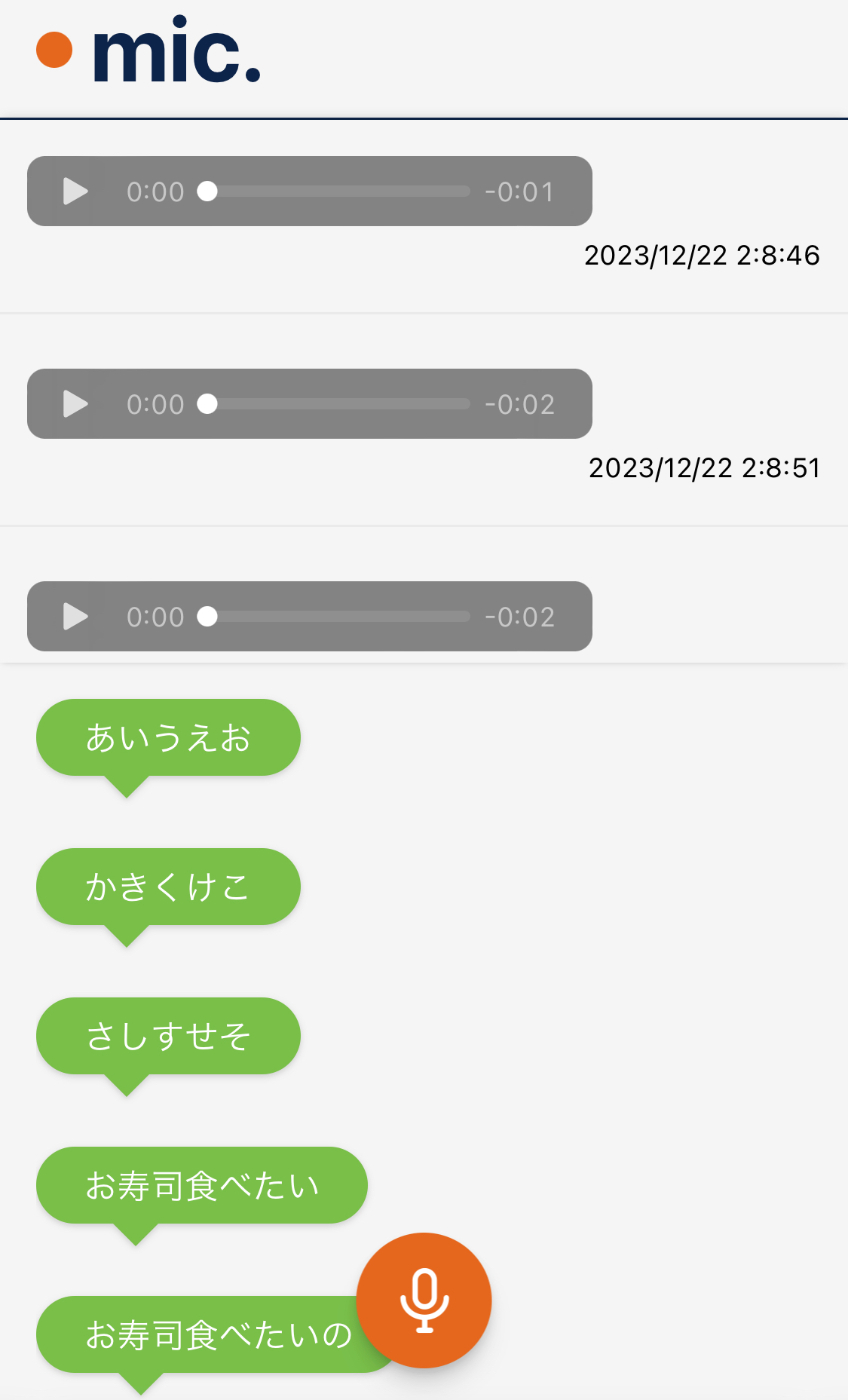
やりたいこと
- iPhone(筆者は12mini)で音声が録音できる
- 録音した音声が再生できる
- 録音した音声ないし再生した音声から自動認識でテキストを書き起こさせる
ネイティブアプリなら出来そうだなと思いましたが、
手軽に始めるならと、ブラウザAPIが生えていないか調べてみました。
音声認識API
音声認識については、SpeechRecognitionを使用することにしました。
ブラウザ対応状況を見るかぎり、ChromeをはじめSafari on iOSはPartial supportではありますが、
どうやら動きそうです。
カスタムフックを下記のように作成しました。
import { useState } from "react";
interface ISpeechRecognitionEvent {
isTrusted?: boolean;
results: {
isFinal: boolean;
[key: number]:
| undefined
| {
transcript: string;
};
}[];
}
interface ISpeechRecognition extends EventTarget {
// properties
grammars: string;
lang: string;
continuous: boolean;
interimResults: boolean;
maxAlternatives: number;
serviceURI: string;
// event handlers
onaudiostart: () => void;
onaudioend: () => void;
onend: () => void;
onerror: () => void;
onnomatch: () => void;
onresult: (event: ISpeechRecognitionEvent) => void;
onsoundstart: () => void;
onsoundend: () => void;
onspeechstart: () => void;
onspeechend: () => void;
onstart: () => void;
// methods
abort(): void;
start(): void;
stop(): void;
}
export default ISpeechRecognition;
interface ISpeechRecognitionConstructor {
new (): ISpeechRecognition;
}
interface IWindow extends Window {
SpeechRecognition: ISpeechRecognitionConstructor;
webkitSpeechRecognition: ISpeechRecognitionConstructor;
}
declare const window: IWindow;
export const useSpeechRecognition = () => {
const [transcripts, setTranscripts] = useState<string[]>([]);
const SpeechRecognition =
window.webkitSpeechRecognition || window.SpeechRecognition;
const recognition = new SpeechRecognition();
recognition.lang = "ja-JP";
/* 音声認識システムが中間的な結果を返す(true)か、最終的な結果だけを返す(false)か定義します。 */
recognition.interimResults = true;
/* 認識が開始されるたびに連続した結果をキャプチャする */
recognition.continuous = true;
const onStart = () => {
setTranscript("");
recognition.start();
};
const onStop = () => {
recognition.stop();
setTranscript("");
};
recognition.onresult = (event: ISpeechRecognitionEvent) => {
if (event.results[0].isFinal && event.results[0][0]) {
setTranscripts([...transcripts, event.results[0][0].transcript]);
}
};
return {
onStart,
onStop,
transcripts,
};
};
コンポーネント側でtranscriptsを見ることで認識結果を受け取ることが出来ます。
recognition.interimResultsをtrueにしておくと、認識途中でも結果が返却されるため、
よりインタラクティブに表現したい場合に活用できそうです。
また、recognition.onresultに渡しているeventは下記のようなSpeechRecognitionResultオブジェクトです。
// SpeechRecognitionResult
{
0: {
confidence: 0.9127139449119568
transcript: "あいうえおかきくけこさしすせそ"
},
isFinal: true,
length: 1
}
isFinalが、音声の認識完了フラグなるので、それを判定材料にして認識結果をセットしています。
if (event.results[0].isFinal && event.results[0][0]) {
setTranscripts([...transcripts, event.results[0][0].transcript]);
}
isFinalがfalseの場合は認識途中の結果が格納されます。
その場合、SpeechRecognitionResultオブジェクトは、プロパティのキーが 0,1,2...と増えていきます。
録音API
録音に関するAPIはこの2つが挙げられます。
MediaStream Recording APIは、ウェブカメラやマイクからの入力をBlobファイルとして保存し、
Web Audio APIはより複雑なオーディオデータの生成・処理・分析・可視化などが可能なAPIです。
iOS Safariで録音できるように試行錯誤
音声ファイルに対して知識を持ち合わせていなかったので、
ブラウザごとに対応しているフォーマットなども複数あることを知りました。
RecordRTCを使う
結局、このライブラリを使用することで録音部分が安定しました。
RecordRTCのDemo画面はこちら
MediaStream Recording API、Web Audio APIがどちらもSafariだけでうまく動かない現象が起きてしまったので、
Web RTCを使用するライブラリの力を借りました。
RecordRTCを使ったコンポーネント(一部抜粋)
import { useState, useEffect } from "react";
import RecordRTC from "recordrtc";
import { useSpeechRecognition } from "../hooks/use-speech-recognition";
import { Microphone } from "./icon/microphone";
type Recording = {
audioURL: string;
blob: Blob;
id: string;
recDate: string;
};
export const Record = () => {
const [recorder, setRecorder] = useState<RecordRTC | null>(null);
const [isRecording, setIsRecording] = useState(false);
const [error, setError] = useState("");
const [recordings, setRecordings] = useState<Recording[]>([]);
const { onStart, onStop, transcripts } = useSpeechRecognition();
// 録音の開始
const startRecording = async () => {
try {
const stream = await navigator.mediaDevices.getUserMedia({
audio: true,
video: false,
});
const newRecorder = new RecordRTC(stream, { type: "audio" });
newRecorder.startRecording();
setRecorder(newRecorder);
setIsRecording(true);
onStart();
} catch (err) {
if (err instanceof Error) {
setError("録音の開始に失敗しました: " + err.message);
}
}
};
// 録音の停止
const stopRecording = () => {
if (recorder) {
recorder.stopRecording(() => {
const blob = recorder.getBlob();
setIsRecording(false);
onStop();
const id =
Math.random().toString(32).substring(2) +
new Date().getTime().toString(32);
const newRecording: Recording = {
audioURL: URL.createObjectURL(blob),
blob,
id,
recDate: getCurrentDate(),
};
setRecordings([...recordings, newRecording]);
});
}
};
// コンポーネントのアンマウント時にリソースを解放
useEffect(() => {
return () => {
if (recorder) {
recorder.destroy();
}
};
}, [recorder]);
return (
<div>
<div className="fixed bottom-0 left-1/2 -translate-x-1/2 flex flex-col justify-center items-center z-50 w-375 py-16">
<RecButton
isRecording={isRecording}
stopCallback={stopRecording}
startCallback={startRecording}
/>
</div>
<section>
<div className="flex flex-col gap-8 max-h-240 overflow-y-scroll audio-cover">
{recordings.map((recording) => (
<RecordAudioBox key={recording.id} recording={recording} />
))}
</div>
{error && <p className="text-red text-12">エラー: {error}</p>}
<div>
<div className="p-16 flex flex-col gap-32 overflow-y-scroll h-[calc(100dvh_-_61px_-_240px)] pb-140">
{transcripts.map((transcriptItem, index) => (
<TransScriptBox key={index} transcript={transcriptItem} />
))}
</div>
</div>
</section>
</div>
);
};
これでこのようなUIを表現することが出来ました。(Chromeでの例)
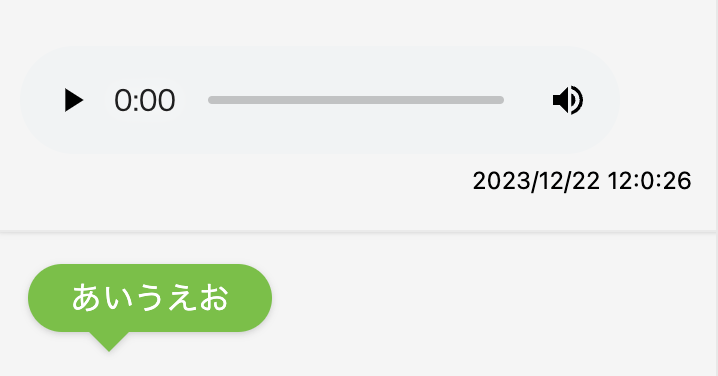
おまけ
[失敗]素直にMediaStream Recording APIを使ってみる
結論から言うと、Blobファイルは生成されるものの、
iOS Safariでは正しく認識されない形式のようで、うまくいきませんでした。
MediaStream Recording APIは、MediaRecorderと呼ばれるインターフェースを操作して音声データを取り扱うことができます。
Webkitのサンプルソースコードで書いてみましたが、壊れたaudioファイルが生成されるか、
An unexpected error has occurred. のようなエラーが発生してしまいました。
audio-recorder-polyfillというポリフィルもあるようで導入してみましたが、
10回に1回くらい正しく録音できるような不安定さが残り、導入を見送りました。
[失敗]RecorderService.jsを使ってみる
色々調べていく中、こちらのプロジェクトファイルを見つけました。
結論こちらも動作が不安定だったので見送りましたが、自身の理解のためにTypeScriptで書き直してみたりしました。
非常に多くのプロパティを搭載しているため、すぐにすべてを把握することは難しくところどころanyとしていますが、ブラウザネイティブのAPIを知るきっかけとなりました。
プロトタイプでのユーザテスト
検収してもらうためにメインターゲット(息子)にテストしてもらいました。
ケラケラ笑いながら一緒に遊んでくれていたので、満足度は高そうです。
おわりに
音声認識をしっかりやろうとするのであれば、GoogleのCloud Speech-to-Text APIなどを利用するのも手段になりそうです。
将来的には変換途中も画面に表示して、よりリアルタイムに変換しているさまを見せたり、
変換するタイムスタンプも記録しておいて、その変換過程を繰り返し見れるようにしたら楽しそうだな、と考えています。
当の息子はもう飽きてしまいました!
サービス開発は難しいですね。
参考文献

ちょっと株式会社(chot-inc.com)のエンジニアブログです。 フロントエンドエンジニア募集中! カジュアル面接申し込みはこちらから chot-inc.com/recruit/iuj62owig
Discussion