はじめに
アニメや映画など「作品」を検索するときに、以下のようなことで困ったことはないですか?
- 昔見た作品をもう一度見たいけどタイトルを覚えていない
- 好きなジャンルで検索しても見たいと思うものがなかなか見つからない
例えば、「昔見たアニメで、主人公が料理を通じて人と繋がっていく話」をGoogleで検索しようとしても、なかなかその作品をピンポイントで見つけることは難しいです。
「同じ感じの作品が見たい!」と思って同ジャンルで調べても「あれ、なんか思った内容と違う」となることが結構多いと思います。

類似検索なら、自分の言葉で探せる
もし「心温まる家族の絆を描いた作品」と検索するだけで、ピッタリのアニメが見つかったらどうでしょう。
タイトルを覚えていなくてもその作品の特徴を文章で入力することでその作品を見つけることができれば嬉しくないですか?
これが類似検索の魅力です。
従来の絞り込み検索では「アクション」「ファンタジー」のような決まった分類でしか探せなかったけど、ベクトル検索なら自分の言葉で、自分の感じたままに検索できます。
ベクトル検索の仕組みをざっくり理解しよう
どうやって「自然な言葉」で検索できるのでしょうか?
仕組みはこうです。Embeddingモデル(OpenAI Embeddings APIなど)でテキストを数値の配列に変換します。これを「ベクトル化」と言います。
例えば「心温まる家族の絆」というテキストは、[0.023950735107064247, 0.05722671374678612, -0.04965493455529213, ...] のような1536個の数値の配列になります(モデルによって保存される数は違います)。
このEmbeddingモデルは、大量のテキストデータから事前学習されています。
その結果、意味が近い文章は、数値的にも近いベクトルになります。例えば、「家族の絆」と「家族愛」のベクトルは、数値の距離が近くなるはずです。
つまり、テキスト同士がどれくらい似ているかを数値化して、数字同士の距離を比較するということです。計算の結果、距離が近ければ類似度は高いということになります。
この計算をするために、まずは集めたデータをベクトルに変換してDBに保存しておく必要があります。そしてユーザーの質問もベクトル化して、保存されたデータと比較することで、質問に近い作品を返すことができます。
データにユーザーからの単語が含まれているかどうかではなく、「ユーザーが言っていることに近いコンテンツ」を提供できます。この仕組みのおかげで検索のUXがかなり向上します。
検索の流れはシンプルです:
- ユーザーのクエリをベクトル化
- DBに保存されているアニメの説明文のベクトルと距離を計算(今回はこれをpgVectorで対応しました。)
- 距離が近いもの(=意味が似ているもの)を返す

参考リンク:
- OpenAI Embeddings API公式ドキュメント
- OpenAI 開発者ブログ - 最新Embeddingモデルに関する記事
- OpenAI 開発者ブログ - Embedding技術に関する説明
PostgreSQL + pgvectorで実装してみた
PostgreSQL + pgvectorを使えば、このベクトル検索が簡単に実装できます。
テキストのベクトル化自体は他の技術を使う必要がありますが、PostgreSQL上でベクトルデータを保存し、検索できることは実装コストも下がるし、結構便利だと思います。
こちらが今回作ったものです。(質問のベクトル化にはお金がかかるため、アプリケーション自体ではなくgifのみの共有になります🙏)
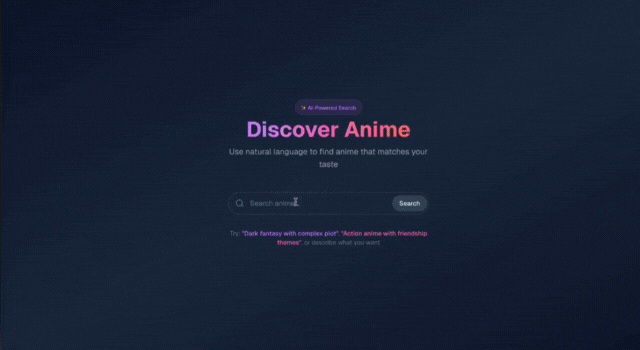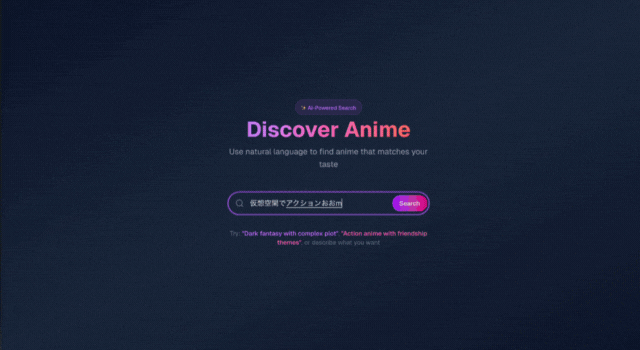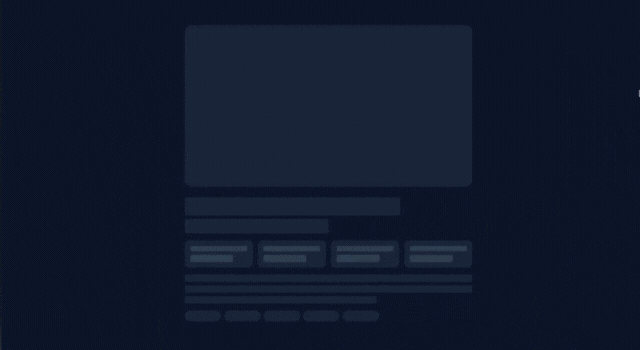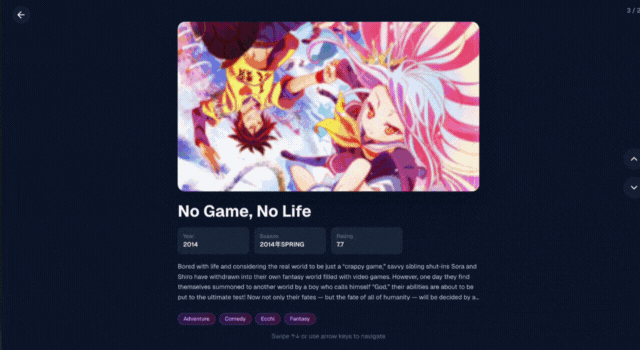
↑の例では「Sword art online」をイメージし「仮想空間でアクション多めのアニメ」と検索し、求めていた「Sword art online」が返ってくることを確認できました。
使った技術スタック
今回使用した技術は以下です。(試すことが目的なのでなるべく早く開発できるものにしました。)
- PostgreSQL(Neonを使用):ベクトルデータの保存と検索
- OpenAI Embeddings API(text-embedding-3-small):テキストのベクトル化
- Next.js + Vercel:フロントエンドとAPIをvercelにデプロイ
参考リンク:
実装は7ステップ
実装は7ステップです。
1. Neonでプロジェクト作成
Neonのダッシュボードで新規プロジェクトを作成します。無料プランで十分です。
2. pgvector拡張を有効化
SQL Editorで一行実行するだけです。
CREATE EXTENSION IF NOT EXISTS vector;
3. テーブル作成
VECTOR型のカラムを含むテーブルを作成します。embeddingカラムに1536次元のベクトルを保存します。
CREATE TABLE anime (
id SERIAL PRIMARY KEY,
title_en TEXT NOT NULL,
description TEXT,
embedding VECTOR(1536), -- ここにベクトルデータが入る
created_at TIMESTAMP DEFAULT NOW(),
updated_at TIMESTAMP DEFAULT NOW()
);
VECTOR形式の数字はモデルの仕様に合わせる必要があります。
今回使用する text-embedding-3-smallモデルは1536次元をサポートしているのでその通りに入力します。
4. HNSWインデックスを作成
ベクトル検索を高速化するためのインデックスを作成します。今回はhnsw方式です。
CREATE INDEX ON anime USING hnsw (embedding vector_cosine_ops);
参考リンク:
5. OpenAI APIでテキストをベクトル化
アニメの説明文をOpenAI APIに送って、ベクトルに変換します。
const response = await openai.embeddings.create({
model: "text-embedding-3-small",
input: animeDescription,
});
const embedding = response.data[0].embedding;
6. データをDBに保存
ベクトル化したデータをPostgreSQLに保存します。
ここは自分でデータを用意するかAPIから取得する必要があります。
annictというサイトでAPIを提供しているのでここで取得して試すのも良いと思います。
7. 検索クエリを実行
ユーザーのクエリをベクトル化して(アニメデータをベクトル化すると同じ処理)、類似度の高いアニメを取得します
SELECT title_en, description
FROM anime
ORDER BY embedding <=> $1
LIMIT 10;
<=> はコサイン距離を計算する演算子です。クエリのベクトル($1)に近いものを返します。
今後改善したい内容
検索機能自体は実装できましたが、まだまだ改善が必要です。現状だと関連度の低いコンテンツが表示されたりするのでユーザーにとってはノイズになると思います。ここは他のアプリケーションを参考に改善を行っていきたいと思います。
また、vectorデータにユーザーからのレビューをより多く含めることで感情的な文章でも満足度の高い結果が得られるようになると思います。
まとめ
pgvectorを使えば、自然言語検索が思ったより簡単に実装できます。
PostgreSQLの知識があればすぐに始められるし、セットアップも一瞬です。AIをうまく使えば30分ほどで動くものとして動作確認もできます。
アニメ検索で試してみたけど、この仕組みはカフェ、本、音楽、レシピなど、あらゆる「テキストで説明できるもの」に応用できます。
皆さんもぜひこの技術を使って、ユーザーが「自分の言葉で検索できる」体験を提供し、サービスのUX向上に貢献しませんか?

ちょっと株式会社(chot-inc.com)のエンジニアブログです。 フロントエンドエンジニア募集中! カジュアル面接申し込みはこちらから chot-inc.com/recruit/iuj62owig
Discussion