🚀
【続き】古いパソコンで、Llama4 maverickを動かす。
【続き】古いパソコンで、Llama4 maverickを動かす。
前回:古いパソコンで、Llama4 Scoutを動かす
今回は前回に引き続き、Llama4 maverickを動かしていきたいと思います。
Llama4 maverickとは
Llama4 maverickとは、Meta社が開発した、Scoutと同じく"MoEアーキテクチャ"を採用したモデルです。
モデルサイズは脅威の"400B"そして、アクティブパラメータはScoutと同じく17Bですが、エキスパート数においては、Scoutと異なり、"128エキスパート"あります。
実際に動かしてみた
モデルダウンロード
-
unsloth/Llama-4-Maverick-17B-128E-Instruct-GGUF/Q2_K_XL
今回はこのモデルを使用します。 - llama.cppで実行
llama-server -m .\llama\models\Unsloth\Llama-4-Maverick-17B-128E-Instruct-GGUF\Llama-4-Maverick-17B-128E-Instruct-UD-Q2_K_XL\Llama-4-Maverick-17B-128E-Instruct-UD-Q2_K_XL-00001-of-00004.gguf -ngl 999 -ot ".*ffn_.*_exps.*=CPU"
実行するときは、4つ分割されている中の一番初めのファイルを実行すると自動的にすべて読み込まれる
結果
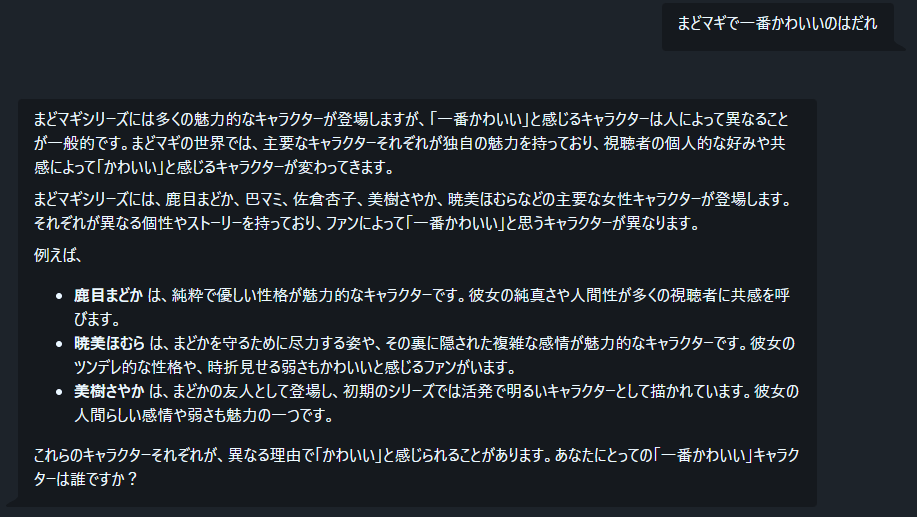
prompt eval time = 5297.22 ms / 17 tokens ( 311.60 ms per token, 3.21 tokens per second)
eval time = 1390670.06 ms / 359 tokens ( 3873.73 ms per token, 0.26 tokens per second)
total time = 1395967.27 ms / 376 tokens
考察
- 結果としては、生成トークン速度は、0.26と規模にしては早いが、非実用的な生成速度になった。
- 総メモリ量72G(vram8G+Ram64)に対して、モデルの容量151Gと訳1:2の割合になってしまったので、記事程の速度は出なかったのだと予想、次はもっと量子化されたモデルを実験してみたい。
- また、生成された品質としては、Scoutにあったような、低規模LLMによくみられるたどたどしい感じが感じられず、自然な日本語を使えていると感じた。
Discussion