【脱LangChain】ゼロから実践するAIエージェント設計術―No Frameworkで学ぶ5つの実践パターン🚀
はじめに
「LangChain/LangGraphやAutoGen、CrewAIなしでAIエージェント開発?それって時代遅れじゃない?」
そう、これ、同僚から実際に言われました(笑) 正直、最初は私も「フレームワークを使わないなんて、車輪の再発明でしょ」と思ってました。
でも実際にフレームワークを使って、開発/本番環境でLLMアプリを開発/運用してみると...これが意外と泥臭い問題が多いんですよね。突然のバージョンアップで動かなくなるコード、謎のブラックボックス挙動、デバッグ困難なエラー...。特に大規模なLLMフレームワークは進化が速すぎて、ドキュメントより先にAPIが変わることも。
そんな経験から「待てよ、もしかして基礎的な設計パターンをきちんと理解してから使うべきなのでは?」と気づいたんです。結局、どんなに洗練されたフレームワークも、その根底にある設計思想を理解していないと、トラブル時に身動きが取れなくなります。
この記事では、あえて"素の"Azure OpenAI API呼び出しとシンプルなPythonだけを使って実装した5つの実用的なAIワークフローパターンの実装をスクラッチで書いてみて学んだ諸々のtipsなどをシェアしたいと思います。今回わかりやすい例として「レストラン予約システム」を題材として実装してみましたが、こういった実装を通して得られたノウハウは、今後のAI Agenticな業務システム開発にも応用できるはずだと思いました。この記事を読んでいただく皆様にも、「こういう実装の仕方もあるんだ」と、新しい視点が得られれば幸いです!
フレームワークを使わない理由 — ベアメタルLLMプログラミングの魅力 🔧
複雑さの排除とシンプルさの追求
「シンプルイズベスト」ってやつですよね。LangChainやAutoGenみたいなフレームワークは確かに強力なんですが、その裏には多くの依存関係や複雑さが潜んでます。
一方、スクラッチ開発なら自分が必要とする機能だけを実装すればOK。コードの動作も把握しやすいです:
# スクラッチ開発でのシンプルな例
async def process_query(query):
# 明確で制御しやすい処理フロー
intent = await analyze_intent(query)
if intent == "calculation":
result = await perform_calculation(query)
elif intent == "information_search":
result = await search_information(query)
return generate_response(result)
学習と理解の深化
AIエージェントの仕組みやLLMとのやり取りを深く理解するなら、スクラッチ開発がいちばんの近道です。フレームワークの内部を読むより、自分で根っこから組んだほうが手応えがありますよね。これができると、いざ他のフレームワークを使うときにも「下回りで何が起きているか」が見えるようになります。
カスタマイズの自由度と制御性
フレームワークは便利ですが、あくまで「決められた枠(フレーム)」内での開発が前提。特殊な要件や実験的アプローチを試したいときは、どうしても制約が気になってきます。スクラッチなら、プロンプトの書き方や応答の処理まで、自由にコントロールできます。
依存関係の最小化とメンテナンス性
フレームワークは進化が早く、ある日突然APIが非推奨になったり、後方互換性が切れたり……ということが結構あります。スクラッチ開発なら「自分のコード」だけメンテすればいいので、外部要因に振り回される頻度が減るのも大きな利点です。
パフォーマンスとコスト効率
不要な呼び出しや処理が入りにくいぶん、カスタムコードのほうがパフォーマンスとコスト効率を最適化しやすい面があります。高負荷システムやAPIの使用料が気になるケースでは見逃せないポイントですよね。
AIワークフローとエージェントの違い 🤔
近年、「AIエージェント」という言葉が盛り上がっていますが、実務の現場では「ワークフロー」で十分なケースも多いと感じます。以下のAnthropicの記事によると、ざっくりこんな違いがあるそうです:
- AIワークフロー:LLMとツールの連携を、あらかじめ定義されたコードパスで行う
- AIエージェント:LLMが自分自身でプロセスの制御とツール使用を動的に選択する
AIエージェントは夢のある仕組みですが、安定性やコスト面でまだ課題が多いのも事実。まずはがっちりと設計されたAgenticなAIワークフローを構築してみるほうが、現場では想定外を減らせるケースも多い感覚です。
実装環境 ⚙️
今回の実装例では以下を使用しています:
- Python 3.10以上
- Azure OpenAI Service(今回はGPT-4o-20241120を使用)
- Pydantic(LLMのJSON応答を綺麗に扱うため)
- asyncio(非同期処理による効率化)
これらを組み合わせると、比較的少ないコードでハイパフォーマンスなAIワークフローが実現できます。
実際のコードは以下にあります。
1. Prompt Chainingパターン ⛓️
パターン概要
Prompt Chainingパターンは、複数のLLM呼び出しを「ステップごと」に連結(チェイニング)していくシンプルな構成です。各ステップの出力を次のステップの入力として使用することで、複雑なタスクを小さな部分に分割して確実に処理します。
このパターンの強みは、各LLM呼び出しが明確に定義された責任を持ち、一連の処理を分かりやすい順序で行える点にあります。複雑なプロンプトを一度に書くよりも、小さなプロンプトに分割することで、各ステップの精度が向上し、デバッグも容易になります。いわゆる「分割統治法」をLLMの呼び出しに適用したものと考えられます。
レストラン予約システムでの適用
レストラン予約システムでは、ユーザーの自然言語入力から必要な予約情報を抽出し、適切な確認メッセージを生成するまでの一連の流れをPrompt Chainで実現します:
-
意図検出ステップ:ユーザー入力がレストラン予約の依頼なのかを判定します。このステップでは、「明日の夜7時に4人で寿司屋に予約したい」といった入力が予約リクエストであることをLLMに認識させます。
-
情報抽出ステップ:予約日時(2025-03-10 19:00など)、予約人数(4人など)、店舗名(寿司屋など)を構造化データとして抽出します。単なるテキスト分析ではなく、Pydanticモデルを活用してデータを厳密に型付けします。
-
確認生成ステップ:抽出した構造化情報を元に、「明日2025年3月10日19時に、4名様でご予約を承りました。寿司屋でお待ちしております。」といった予約確認メッセージをLLMで生成します。
各ステップは独立しており、出力の品質が次のステップに直接影響するため、段階的な処理による信頼性の向上が図れます。
処理フロー
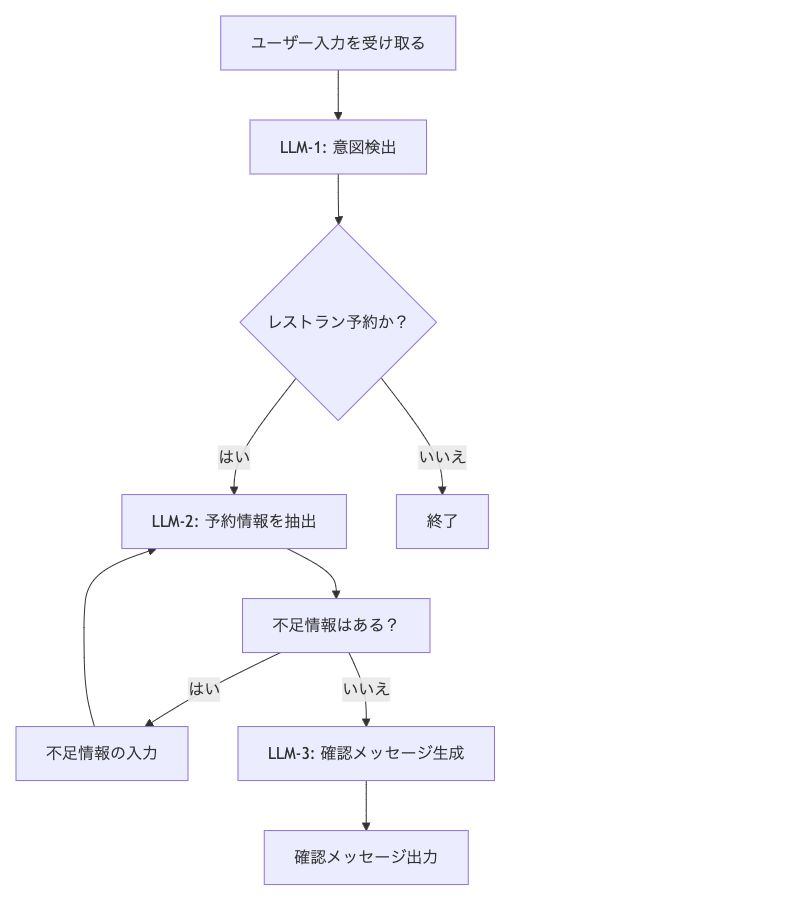
フロー図に示されているように、このパターンでは「ユーザー入力→意図検出→情報抽出→情報の検証と補完→確認メッセージ生成」という一連の流れを順序立てて処理します。特に不足情報があれば再度情報抽出に戻るところがポイントで、必要な情報が揃うまでループすることで確実な処理を実現しています。
実装イメージ
class BookingInterface:
def __init__(self):
self.booking_service = RestaurantBookingService()
def handle_booking_process(self, user_input):
"""
Prompt Chainingパターンを使用して予約処理を行います。
"""
# ステップ1: 意図検出
intent_result = self.booking_service.detect_intent(user_input)
# レストラン予約リクエストでない場合は終了
if not intent_result.is_restaurant_booking:
return "申し訳ありませんが、これをレストラン予約リクエストとして処理できませんでした。"
# ステップ2: 情報抽出
booking_info = self.booking_service.extract_booking_info(user_input)
# ステップ3: 不足情報の入力促進
if booking_info.reservation_datetime is None:
datetime_input = input("予約日時が見つかりませんでした。日時を入力してください(例: 2025-03-10 19:00): ")
enhanced_input = f"{user_input} {datetime_input}に予約したいです。"
booking_info = self.booking_service.extract_booking_info(enhanced_input)
if booking_info.number_of_people is None:
people_input = input("予約人数が見つかりませんでした。人数を入力してください: ")
enhanced_input = f"{user_input} {people_input}名で予約したいです。"
booking_info = self.booking_service.extract_booking_info(enhanced_input)
# ステップ4: 確認メッセージ生成
if booking_info.reservation_datetime and booking_info.number_of_people:
confirmation = self.booking_service.generate_confirmation(
booking_info.reservation_datetime,
booking_info.number_of_people,
booking_info.location_or_restaurant_name,
)
return confirmation.confirmation_message
else:
return "必要な情報が不足しているため、予約を完了できませんでした。"
入出力例
このパターンのポイント
- 各ステップが単純明快なので、デバッグ
- がしやすい
- ステップ間のデータ構造を統一すると汎用性が増す
- 一度に大きなタスクをやらせるより成功率が高い(分割統治)
やってみた感想 💭
複雑なタスクは細かく分解したほうがうまくいきます。一度のLLM呼び出しで「全部やって!」と頼むより、シンプルなステップに分けるほうが成功率が上がるんですよね。まさに「分割統治法」の実践です。
2. Routingパターン 🧭
パターン概要
Routingパターンは、ユーザー入力を分析して適切な処理フローに振り分ける「インテリジェントな交通整理」の役割を果たします。従来のif-elseによる分岐ではなく、LLMの自然言語理解能力を活用して意図を解析し、動的に適切な処理経路に振り分けるのが特徴です。
このパターンでは、入力テキストから「何をしたいのか」を抽出し、事前に定義された複数の処理フローのうち最適なものを選択します。単純な単語マッチングではキャッチできないニュアンスや文脈の理解が可能で、曖昧な表現や複合的な要求にも対応できる点が強みです。
レストラン予約システムでの適用
レストラン予約システムではユーザーの要求が多岐にわたります。Routingパターンではまず、ユーザー入力を大きく以下のようなカテゴリに分類します:
-
新規予約フロー:「明日の夜7時に4人で予約したい」のような新規予約の依頼に対しては、日付、時間、人数、レストラン名などの必要情報を抽出して新しい予約を作成します。このフローでは、抽出→検証→確定という一連の処理が必要です。
-
既存予約変更フロー:「予約番号12345の時間を8時に変更したい」のような既存予約の変更リクエストに対しては、予約IDをキーにして既存データを取得し、指定された属性のみを更新します。このフローでは、ID検証→変更内容特定→更新という異なる処理が求められます。
両者では必要な情報と処理手順が大きく異なるため、最初の段階で適切に振り分けることで、その後の処理を最適化できます。LLMには「新規」か「変更」かの判断だけでなく、変更の場合は「どの予約をどう変更したいのか」まで解析させることが可能です。
処理フロー

フロー図が示すように、Routingパターンのコアは「インテント検出によるルート分岐」です。最初のLLM呼び出しでユーザーの意図を解析し、その結果に基づいて「新規予約処理」か「予約変更処理」のどちらかに振り分けます。これにより、両方のケースに対応するための複雑なロジックを一つにまとめる必要がなく、それぞれに最適化された処理を実行できます。
実装イメージ
class BookingInterface:
def __init__(self):
self.booking_service = RestaurantBookingService()
async def handle_booking_process(self, user_input):
"""
Routingパターンを使用して予約処理を行います。
"""
# ステップ1: 意図検出(Routingの起点)
intent_result = await self.booking_service.detect_intent(user_input)
# レストラン予約リクエストでない場合は終了
if not intent_result.is_restaurant_booking:
return "申し訳ありませんが、これをレストラン予約リクエストとして処理できませんでした。"
# ステップ2: 意図に基づいて適切なハンドラーにルーティング
if intent_result.new_or_modify == "new":
# 新規予約フローを処理
booking_info = await self.booking_service.extract_booking_info(user_input)
# 不足情報の入力促進
if booking_info.reservation_datetime is None:
datetime_input = input("予約日時が見つかりませんでした。日時を入力してください: ")
enhanced_input = f"{user_input} {datetime_input}に予約したいです。"
booking_info = await self.booking_service.extract_booking_info(enhanced_input)
# 確認メッセージの生成
if booking_info.reservation_datetime and booking_info.number_of_people:
confirmation = await self.booking_service.generate_confirmation("new", booking_info)
return confirmation.confirmation_message
else:
return "必要な情報が不足しているため、予約を完了できませんでした。"
elif intent_result.new_or_modify == "modify":
# 予約変更フローを処理
booking_id = self.extract_booking_id(user_input)
# 予約IDが見つからない場合は入力を促す
if booking_id is None:
booking_id = input("予約IDを入力してください: ")
# 予約の存在確認
all_bookings = load_bookings()
if booking_id not in all_bookings:
return f"申し訳ありませんが、予約ID {booking_id} の予約が見つかりませんでした。"
# 予約変更情報の抽出
modified_booking_info = await self.booking_service.modify_existing_booking(user_input, booking_id)
confirmation = await self.booking_service.generate_confirmation("modify", modified_booking_info)
return confirmation.confirmation_message
else:
return "リクエストを処理できませんでした。もう一度お試しください。"
このパターンのポイント
- 意図判定をLLMに任せることで柔軟なルーティングを実現
- オムニチャネル対応(チャット、音声、メールなど)に拡張しやすい
- シンプルに見えて意外と拡張性がある
- 同じデータモデルでも処理フローごとに最適化できる
試してみての印象 💭
このパターンは「if/else」の進化形みたいなものですが、条件分岐をLLM自身に判断させるところがミソ。従来のif文では捉えきれないニュアンスや意図も、LLMの言語理解力で振り分けられるのが魅力です。「怒ってる顧客」「急いでる人」みたいな感情ベースの振り分けもできるようになりますよ。
3. Parallelizationパターン 🔀
パターン概要
Parallelizationパターンは、互いに依存関係のない複数のタスクを並列(非同期)に実行することで、全体の処理時間を短縮する手法です。特にLLM呼び出しのような「待ち時間の長い」処理を複数行う場合、直列に処理すると全体の所要時間が各処理の単純合計になってしまいますが、並列化することでほぼ最長の処理時間だけまで短縮できます。
このパターンはPythonのasyncioライブラリを活用し、複数のコルーチンを同時に実行することで実現します。処理速度の向上だけでなく、各サブタスクの独立性と責任範囲を明確にできる設計上のメリットもあります。
レストラン予約システムでの適用
レストラン予約システムでは、ユーザー入力からさまざまな情報を抽出する必要がありますが、それらの多くは互いに依存せず並列処理が可能です:
-
基本情報の抽出:予約日時、人数、レストラン名といった予約の基本項目を抽出するタスク。これは予約登録に最低限必要な情報です。
-
特別要望の抽出:アレルギー情報、席の希望(窓際、個室など)、特別な機会(誕生日など)といった付加的な情報を抽出するタスク。これらは任意の追加情報です。
これらは互いに独立しており、同時に処理することが可能です。さらに、確認メッセージの生成も複数のLLM呼び出しに分割できます:
- 基本確認メッセージの生成:予約の基本情報に関する確認文を生成
- 特別対応確認の生成:特別要望への対応を説明する確認文を生成
これらを並列処理し、最後に統合することで、ユーザー体験を損なわずに応答時間を短縮できます。
処理フロー

フロー図に示されているように、Parallelizationパターンの特徴は「同時に複数の処理を実行する」点にあります。基本情報と特別リクエストの抽出を並行して行い、さらに確認メッセージの生成も並列化しています。特に「LLM-1: 基本情報を抽出 & LLM-2: 特別リクエストを抽出」や「LLM-3: 基本的な確認メッセージを生成& LLM-4: 特別な確認メッセージを生成」の部分が並列処理を表しており、これらの処理が同時に進行することで全体の処理時間が短縮されます。
実装イメージ
class ParallelBookingService:
async def process_booking_parallel(self, user_input):
"""並列処理で予約を処理"""
logger.info(f"ユーザー入力を並列処理しています: {user_input}")
# 基本情報と特別要望を並列で抽出
basic_info, special_requests = await asyncio.gather(
self.extract_basic_info(user_input),
self.extract_special_requests(user_input)
)
# 不足情報の入力促進
if basic_info.reservation_datetime is None:
datetime_input = input("予約日時が見つかりませんでした。日時を入力してください(例: 2025-03-10 19:00): ")
enhanced_input = f"{user_input} {datetime_input}に"
basic_info = await self.extract_basic_info(enhanced_input)
if basic_info.number_of_people is None:
people_input = input("予約人数が見つかりませんでした。人数を入力してください: ")
enhanced_input = f"{user_input} {people_input}名で"
basic_info = await self.extract_basic_info(enhanced_input)
# 必須情報が揃っているか確認
if not (basic_info.reservation_datetime and basic_info.number_of_people):
return "必要な情報が不足しているため、予約を完了できませんでした。"
# 確認メッセージを並列で生成
basic_confirmation, special_confirmation = await asyncio.gather(
self.generate_basic_confirmation(basic_info),
self.generate_special_confirmation(special_requests)
)
# 確認メッセージを統合
combined_confirmation = await self.combine_confirmations(
basic_confirmation[0], special_confirmation, basic_confirmation[1]
)
return combined_confirmation.combined_message
このパターンのポイント
- API呼び出しやLLM呼び出しが多いときに有効
- ただし依存関係があるタスクは無理に並列化しないほうが混乱を招かない
- asyncioのgatherメソッドを使うことで簡潔に実装可能
- 各タスクの責任範囲が明確になり、コードの保守性も向上する
実装して思ったこと 💭
並列処理は諸刃の剣です。使いどころを間違えると、かえって複雑になっちゃうこともあります。個人的な教訓は「並列化できるものと、順次処理すべきものを見極める」こと。処理の依存関係を明確にしてから並列化を検討するといいですよ。
4. Orchestrator-Workerパターン 🤹♂️
パターン概要
Orchestrator-Workerパターンは、複雑なタスクを「全体の統括役(オーケストレーター)」と「専門的作業の実行役(ワーカー)」に役割分担する設計手法です。オーケストレーターはワークフロー全体を理解し、適切なワーカーに仕事を割り振る責任を持ちます。一方、各ワーカーは特定の専門領域に特化した処理だけに集中することで、高い精度と保守性を実現します。
このパターンはマイクロサービスアーキテクチャに近い考え方で、「単一責任の原則」を徹底し、各コンポーネントの役割を明確に分離します。複雑なシステムを管理可能な単位に分割することで、スケーラビリティとメンテナンス性が向上します。
レストラン予約システムでの適用
レストラン予約システムでは、ユーザー入力から必要な情報を抽出し、適切に処理する一連の流れをOrchestrator-Workerパターンで構造化できます:
-
オーケストレーター:ユーザー入力を最初に受け取り、どのような予約処理が必要かを判断し、計画を立てます。その計画に基づいて、必要なワーカーに作業を割り振ります。オーケストレーターは「全体を見る目」を持ち、予約プロセス全体の調整役を果たします。
-
専門ワーカー群:
- 日時ワーカー:「明日の夜7時」「来週の金曜」などの自然言語表現から、正確な日時(2024-03-10 19:00など)を抽出します。曜日や祝日の考慮も可能です。
- 人数ワーカー:「家族4人と友人2人」「大人3人と子供2人」といった表現から、正確な予約人数を算出します。
- レストランワーカー:店名や場所の情報を特定し、曖昧な表現を正規化します。
- 特別要望ワーカー:アレルギー情報、席の希望、特別な機会などの情報を詳細に分析します。
各ワーカーは高度に専門化されており、自身のドメインのみに集中することで精度の高い情報抽出が可能になります。オーケストレーターはこれらの結果を集約し、最終的な予約確認を生成します。
処理フロー

フロー図に示されているように、Orchestrator-Workerパターンの特徴は「計画と実行の分離」です。まずオーケストレーターが全体の処理計画を立て、それに基づいてタスクを各ワーカーに分配します。特に注目すべきは、各ワーカーが独立して並列処理されるにもかかわらず、オーケストレーターがそれらを適切に調整している点です。ワーカーの処理結果はオーケストレーターに集約され、最終的な確認メッセージの生成に活用されます。
実装イメージ
class RestaurantBookingOrchestrator:
async def process_booking_request(self, user_input):
"""
レストラン予約リクエストをオーケストレーター・ワーカーパターンで処理するメイン関数
"""
# ステップ1: オーケストレーターが予約計画を作成
booking_plan = await self.create_booking_plan(user_input)
# 予約リクエストでない場合は終了
if booking_plan.booking_type not in ["new", "modify"]:
return "申し訳ありませんが、これをレストラン予約リクエストとして処理できませんでした。"
# 既存予約情報を取得(変更の場合)
existing_booking_info = None
if booking_plan.booking_type == "modify":
booking_id = booking_plan.booking_id or self.extract_booking_id(user_input)
if not booking_id:
booking_id = input("予約IDを入力してください: ")
if booking_id in self.bookings:
existing_booking_info = self.bookings[booking_id]
else:
return f"申し訳ありませんが、予約ID {booking_id} の予約が見つかりませんでした。"
# ステップ2: 必要なタスクを特定し、適切なワーカーに分配
tasks = []
task_mapping = {}
for task in booking_plan.required_tasks:
if task.task_name == "date_time":
coro = self.analyze_date_time(user_input, booking_plan.booking_type, existing_booking_info)
task_mapping["date_time"] = coro
tasks.append(coro)
elif task.task_name == "party":
coro = self.analyze_party(user_input, booking_plan.booking_type, existing_booking_info)
task_mapping["party"] = coro
tasks.append(coro)
elif task.task_name == "restaurant":
coro = self.analyze_restaurant(user_input, booking_plan.booking_type, existing_booking_info)
task_mapping["restaurant"] = coro
tasks.append(coro)
elif task.task_name == "special_requests":
coro = self.analyze_special_requests(user_input, booking_plan.booking_type, existing_booking_info)
task_mapping["special_requests"] = coro
tasks.append(coro)
# ステップ3: すべてのワーカーの分析結果を並列で取得
results = await asyncio.gather(*tasks)
# 結果を整理
task_results = {}
for (name, coro), result in zip(task_mapping.items(), results):
task_results[name] = result
# ステップ4: オーケストレーターが最終的な予約確認を生成
booking_id = booking_plan.booking_id or None
confirmation = await self.generate_confirmation(booking_plan.booking_type, booking_id, task_results)
return confirmation.confirmation_message
このパターンのポイント
- ドメインごとの知識を「ワーカー」に分離でき、テストもしやすい
- チーム開発に向いている(ワーカー単位で担当者を分けられる)
- 個々のワーカーは再利用性が高い
- 専門ワーカーの追加・変更が容易で拡張性に優れている
- オーケストレーターが全体の流れを調整するため、複雑なワークフローでも管理しやすい
使ってみて感じたこと 💭
このパターンのいいところは「専門性と全体観のバランス」です。各ワーカーは自分の担当領域だけに集中できるので高い精度を発揮できますし、オーケストレーターは全体を俯瞰できます。
個人的には再利用性が高いと感じています。「日時分析ワーカー」は他のシステムでも使えるし、新しい専門ワーカーを追加するのも簡単。拡張性の高さが魅力ですね。
5. Evaluator-Optimizerパターン 🔄
パターン概要
Evaluator-Optimizerパターンは、「一度で完璧を目指すよりも、継続的な改善サイクルで品質を高める」という考え方に基づいたパターンです。最初に生成された出力(Generator)を評価し(Evaluator)、その評価結果に基づいてフィードバックを与えて再生成(Optimizer)するループを繰り返すことで、品質を段階的に向上させます。
このパターンは「人間の校正プロセス」に似ており、最初のドラフトを作成し、レビューして改善点を見つけ、それを元に修正するというサイクルをLLMで自動化します。特に高品質な出力が求められる場面や、重要な判断を含む出力において効果的です。
レストラン予約システムでの適用
レストラン予約システムでの最終出力は「顧客への予約確認メッセージ」です。このメッセージは正確さと丁寧さの両方が求められる重要な要素です。Evaluator-Optimizerパターンでは以下のように実装します:
-
Generator(生成):予約情報を元に、初期の確認メッセージを生成します。このステップでは、基本的な予約情報(日時、人数、場所など)を含んだ確認文を作成します。
-
Evaluator(評価):生成された確認メッセージを評価し、問題点や改善点を特定します。評価基準としては:
- 必要な情報(予約ID、日時、人数、レストラン名)が含まれているか
- 文章の明確さと読みやすさ
- 丁寧さと適切なトーン
- 特別要望への対応が記載されているか
- その他の品質基準
-
改善サイクル:評価結果に基づき、フィードバックを含めて再度メッセージを生成します。例えば「予約日時の記載が不明確です」「特別要望への対応が書かれていません」といったフィードバックを与え、それを踏まえたメッセージを再生成します。
このサイクルは、評価が十分な品質(PASS)に達するか、最大繰り返し回数に到達するまで継続されます。各サイクルで確認メッセージの品質が向上していくことが期待できます。
処理フロー

フロー図に示されているように、Evaluator-Optimizerパターンのコアは「LLM-Generator:確認メッセージを作成→LLM-Evaluator:確認メッセージを評価→品質チェック→フィードバックを生成→LLM-Generator:確認メッセージを作成」という改善ループです。LLMが生成した確認メッセージを別のLLMが評価し、その評価結果に基づいてフィードバックを生成して再度LLMに渡すというサイクルを繰り返します。この改善ループが評価で「合格」と判定されるまで、または最大試行回数に達するまで続きます。
実装イメージ
class EvaluatorOptimizerService:
async def optimize_confirmation(self, booking_type, booking_info):
"""
予約確認メッセージを最適化します(Evaluator-Optimizerサイクル)。
"""
logger.info("Evaluator-Optimizerパターンで確認メッセージを最適化しています")
# 予約IDが存在しない場合は生成
if not booking_info.booking_id:
booking_info.booking_id = str(random.randint(10000, 99999))
# 初回生成
confirmation = await self.generate_confirmation(booking_type, booking_info)
iteration_count = 0
max_iterations = self.iteration_limit
feedback_text = None
while iteration_count < max_iterations:
evaluation = await self.evaluate_confirmation(
booking_type, booking_info, confirmation.confirmation_message
)
if evaluation.evaluation_result == "PASS":
logger.info(f"確認メッセージが合格しました。繰り返し回数: {iteration_count + 1}")
break
# 改善用フィードバックを作成
feedback_text = evaluation.feedback
if evaluation.missing_information:
feedback_text += "\n\n欠けている情報: " + ", ".join(evaluation.missing_information)
if evaluation.improvement_suggestions:
feedback_text += "\n\n改善提案: " + ", ".join(evaluation.improvement_suggestions)
# 再生成
logger.info(f"確認メッセージを改善します({iteration_count + 1}回目)")
confirmation = await self.generate_confirmation(booking_type, booking_info, feedback_text)
iteration_count += 1
# 予約情報を保存
datetime_str = ""
if booking_info.reservation_datetime:
datetime_str = booking_info.reservation_datetime.strftime("%Y年%m月%d日 %H:%M")
reservation_details = {
"booking_id": booking_info.booking_id,
"booking_type": booking_type,
"reservation_datetime": datetime_str,
"number_of_people": booking_info.number_of_people,
"location_or_restaurant_name": booking_info.location_or_restaurant_name,
"special_requests": booking_info.special_requests,
"created_at": datetime.now().isoformat(),
}
save_booking(booking_info.booking_id, reservation_details)
return BookingResult(
booking_id=booking_info.booking_id,
confirmation_message=confirmation.confirmation_message,
booking_details=reservation_details,
optimization_iterations=iteration_count + 1,
)
このパターンのポイント
- 「自動校正」の仕組みを入れることで、出力精度を底上げ
- 呼び出し回数が増えるためコストが高くなりがちだが、高品質を求める場面で威力を発揮
- 評価基準を明確にしておくことで、より効果的な改善ループが実現できる
- 「評価」と「生成」で異なるLLMやパラメータを使い分けると効果的
試してみての印象 💭
このパターンはAPI呼び出しコストが高めですが、絶対に品質を確保したい場面では必須です。顧客向けメールや公式文書の生成に向いています。
面白いのは、「評価者」と「生成者」に異なるモデルを使うと効果が高まること。評価にはロジック重視のモデル(温度設定を低く)、生成には創造性のあるモデル(温度設定を少し高く)を使い分けると相性がいいですよ。
各パターン実装プログラム実行例
では次に、実装した5つのパターンにおいて、このレストラン予約システムの実行例を紹介します。main.pyを実行すると、5つのパターンから選択できます。
メイン実行画面
$ python main.py
実行するパターンを選択してください:
1. Prompt Chainingパターン
2. Routingパターン
3. Parallelizationパターン
4. Orchestrator-Workerパターン
5. Evaluator-Optimizerパターン
選択 (1-5):
1. Prompt Chainingパターンの実行例
選択 (1-5): 1
レストラン予約のリクエストを入力してください: 明日の夜7時に、友人4人と一緒に「鉄板焼き山田」に予約したいです。
入力がレストラン予約リクエストであるかを確認中
レストラン予約意図の検出結果: True
レストラン予約情報を抽出しています
予約情報抽出結果: 日時=2025-03-06 19:00, 人数=5, 場所=鉄板焼き山田
予約確認メッセージを生成しています
確認メッセージの生成に成功しました
ご予約を承りました。
予約ID: 45678
日時: 2025年03月06日 19:00
人数: 5名
レストラン: 鉄板焼き山田
当日は、お時間に余裕をもってお越しください。
ご来店をお待ちしております。
2. Routingパターンの実行例
選択 (1-5): 2
レストラン予約のリクエストを入力してください: 予約ID:12345の時間を明日の19:30に変更してください。
入力がレストラン予約リクエストであるかを確認中
レストラン予約意図の検出結果: 予約=True, タイプ=modify
予約変更フローを処理しています
既存予約(ID: 12345)の変更情報を抽出しています
変更情報抽出結果: 日時=2025-03-06 19:30, 人数=None, 場所=None
予約確認メッセージを生成しています
確認メッセージの生成に成功しました
ご予約の変更を承りました。
予約ID: 12345
日時: 2025年03月06日 19:30 (変更されました)
人数: 5名 (変更なし)
レストラン: 鉄板焼き山田 (変更なし)
ご変更いただきありがとうございます。新しい時間でお待ちしております。
ご不明点がございましたらお気軽にお問い合わせください。
3. Parallelizationパターンの実行例
選択 (1-5): 3
レストラン予約のリクエストを入力してください: 明日19時に和食レストラン「さくら」に4人で予約したいです。窓際の席を希望します。私は海老アレルギーがあります。
ユーザー入力を並列処理しています: 明日19時に和食レストラン「さくら」に4人で予約したいです。窓際の席を希望します。私は海老アレルギーがあります。
基本予約情報を抽出しています
特別要望を抽出しています
基本情報抽出完了: 日時=2025-03-06 19:00, 人数=4
特別要望抽出完了: 食事制限=海老アレルギー, 席希望=窓際の席
基本予約情報の確認メッセージを生成しています
特別要望の確認メッセージを生成しています
基本確認メッセージの生成に成功しました
特別要望確認メッセージの生成に成功しました
確認メッセージを統合しています
確認メッセージの統合に成功しました
【ご予約確認】
いつもレストラン「さくら」をご利用いただき、誠にありがとうございます。
以下の内容で予約を承りました。
予約ID: 34567
日時: 2025年03月06日 19:00
人数: 4名
レストラン: さくら
特別なご要望:
・窓際の席をご用意いたします
・海老アレルギーについて厨房に伝達いたします
当日は、ご予約時間の5分前までにお越しいただけますようお願いいたします。
ご来店を心よりお待ちしております。
4. Orchestrator-Workerパターンの実行例
選択 (1-5): 4
レストラン予約のリクエストを入力してください: 次の土曜日19時に、2人でイタリアンのブォーノに予約お願いします。記念日なので雰囲気のいい席がいいです。
ユーザー入力を処理しています: 次の土曜日19時に、2人でイタリアンのブォーノに予約お願いします。記念日なので雰囲気のいい席がいいです。
予約計画を作成しています
予約計画の作成が完了しました: new
予約日時を分析しています
予約人数を分析しています
レストラン情報を分析しています
特別要望を分析しています
日時分析が完了しました: True, 2025-03-08 19:00
人数分析が完了しました: True, 2
レストラン情報分析が完了しました: True, ブォーノ
特別要望分析が完了しました: 0.9
予約確認を生成しています
予約確認の生成が完了しました: 23456
【レストラン「ブォーノ」ご予約確認】
お客様の記念日のお祝いにレストラン「ブォーノ」をお選びいただき、誠にありがとうございます。
下記の内容でご予約を承りました。
◆予約ID: 23456
◆日時: 2025年03月08日(土) 19:00
◆人数: 2名様
◆お席: 雰囲気の良い席(窓際のカップルシートをご用意いたします)
記念日のお祝いとして、乾杯用のスパークリングワインを1杯サービスさせていただきます。
特別な日のお手伝いができることを、スタッフ一同大変嬉しく思います。
当日は、ご予約時間の10分前のご来店をお勧めいたします。
ご質問やご要望がございましたら、お気軽にお電話ください。
心よりご来店をお待ちしております。
5. Evaluator-Optimizerパターンの実行例
選択 (1-5): 5
レストラン予約のリクエストを入力してください: 今週の金曜日、イタリアン「ラ・ベルタ」に夜8時から友人と3人で予約したいです。駐車場はありますか?
ユーザー入力を処理しています: 今週の金曜日、イタリアン「ラ・ベルタ」に夜8時から友人と3人で予約したいです。駐車場はありますか?
入力がレストラン予約リクエストであるかを確認中
レストラン予約意図の検出結果: 予約=True, タイプ=new
レストラン予約情報を抽出しています
予約情報抽出結果: 日時=2025-03-07 20:00, 人数=3, 場所=ラ・ベルタ
Evaluator-Optimizerパターンで確認メッセージを最適化しています
予約確認メッセージを生成しています
確認メッセージの生成に成功しました
予約確認メッセージを評価しています
確認メッセージの評価に成功しました: NEEDS_IMPROVEMENT
確認メッセージを改善しています(繰り返し回数: 1)
予約確認メッセージを生成しています (フィードバックあり)
確認メッセージの生成に成功しました
予約確認メッセージを評価しています
確認メッセージの評価に成功しました: PASS
予約処理が完了しました: 予約ID 78901, 最適化繰り返し回数 2
【ご予約確認 - イタリアン「ラ・ベルタ」】
この度は「ラ・ベルタ」をご利用いただき、誠にありがとうございます。
下記の内容でご予約を承りました。
■ご予約情報■
予約ID: 78901
日時: 2025年03月07日(金) 20:00
人数: 3名様
レストラン: イタリアン「ラ・ベルタ」
■その他のご案内■
◇駐車場について
当店には10台分の専用駐車場をご用意しております。
満車の場合は、徒歩2分の場所に提携コインパーキングがございます(2時間無料券を差し上げます)。
ご来店の際は、予約IDをお伝えください。
ご質問やご変更などございましたら、お気軽にお電話くださいませ。
心よりご来店をお待ちしております。
イタリアン「ラ・ベルタ」
TEL: 03-XXXX-XXXX
プログラム終了時
プログラムが終了すると、restaurant_bookings.jsonファイルに予約情報が保存されます:
{
"45678": {
"booking_id": "45678",
"reservation_datetime": "2025年03月06日 19:00",
"number_of_people": 5,
"location_or_restaurant_name": "鉄板焼き山田",
"created_at": "2025-03-05T14:32:15.123456"
},
"12345": {
"booking_id": "12345",
"reservation_datetime": "2025年03月06日 19:30",
"number_of_people": 5,
"location_or_restaurant_name": "鉄板焼き山田",
"created_at": "2025-03-05T14:35:22.654321"
}
// 他の予約情報...
}
これらの例からわかるように、各パターンは同じ基本機能(レストラン予約)に対して異なるアプローチを提供します。パターンによって処理フローや出力結果の質、応答時間が異なることが確認できます。
パターン選択と組み合わせのガイドライン 🧩
「どのパターンが最適なの?」と迷うときは、以下の観点が目安になります:
| パターン | 最適な使用場面 | 主な特徴 | 複雑さ | 処理時間 | お勧め度 |
|---|---|---|---|---|---|
| Prompt Chaining | シンプルな多段階処理 | 実装容易、直線的処理 | 低 | 中 | ★★★★☆ 入門に最適 |
| Routing | 多様なユーザー要求 | 動的分岐、柔軟性 | 中 | 中 | ★★★★★ 実用性抜群 |
| Parallelization | 処理時間短縮が重要 | 並列処理、効率性 | 中 | 低 | ★★★☆☆ 使いどころを選ぶ |
| Orchestrator-Worker | 複雑タスクの専門化 | 役割分担、精度向上 | 高 | 中~高 | ★★★★★ 拡張性の王様 |
| Evaluator-Optimizer | 高品質出力が必要 | 自己改善、品質保証 | 高 | 高 | ★★★★☆ コスト高だけど価値あり |
実務ではこれらを組み合わせることが多いです。個人的におすすめなのはRouting + Orchestrator-Workerの組み合わせ。
最初にユーザーの要望を仕分け(Routing)し、その後に専門ワーカーに処理させる(Orchestrator-Worker)、という流れ。これって「総合病院モデル」みたいなもので、最初に受付で症状を聞いて(Routing)、適切な診療科に案内し、専門医たちが診療する(Orchestrator-Worker)というイメージです。
実装のベストプラクティスと個人的な学び 💡
1. 明確なデータモデルが安定性の鍵
Pydanticモデルを活用してデータ構造を明確に定義することで、LLMとの連携が劇的に安定します:
class RestaurantBookingInformation(BaseModel):
"""レストラン予約に関する詳細情報を格納するモデル"""
reservation_datetime: Optional[datetime] = Field(
default=None,
description="予約日時(解析できない場合はNone)"
)
number_of_people: Optional[int] = Field(
default=None,
description="予約人数(解析できない場合はNone)"
)
location_or_restaurant_name: Optional[str] = Field(
default=None,
description="指定された場所またはレストラン名(解析できない場合はNone)"
)
実装を通じて学んだポイント:
-
descriptionフィールドはLLMへの重要な指示になる - 必須フィールドと任意フィールドを適切に区別する
- オブジェクト間の関係性を明確にモデル化すると全体設計が見えやすくなる
- JSONスキーマとして自動的に変換できるのが強み
Pydanticはただのバリデーションライブラリではなく、LLMとのインターフェース設計ツールとしての価値が大きいです。
2. 多層防御のエラーハンドリングが必須
LLMは予測不能な応答をすることがあり、それを前提とした堅牢な設計が必要です:
try:
content = await self.openai_service.call_llm_with_json_output_async(
system_prompt,
user_input,
RestaurantBookingInformation.model_json_schema()
)
parsed = json.loads(content)
# 必須キーがなければ埋める
if "reservation_datetime" not in parsed:
parsed["reservation_datetime"] = None
# ... その他のキーも同様に確認 ...
result = RestaurantBookingInformation.model_validate(parsed)
return result
except (ValidationError, json.JSONDecodeError) as e:
logger.error(f"予約情報の抽出に失敗しました: {str(e)}")
# デフォルト値または空のオブジェクトを返す
return RestaurantBookingInformation()
実装から得た教訓:
- LLMの応答は常に疑ってかかる(特にJSON形式が崩れる可能性がある)
- 例外の種類ごとに対応を変える(ValidationErrorとJSONDecodeErrorで別々の対応)
- ロギングを徹底する(デバッグの命綱)
- デフォルト値を用意して処理を継続できるようにする
これは「過剰」と思えるかもしれませんが、プロダクション環境では必須の考え方です。
3. サービス層による抽象化の価値
全パターン実装を通じて感じたのは、共通処理の抽象化がいかに重要かということ。common.pyに実装したOpenAIServiceがその好例です:
class OpenAIService:
def __init__(self, endpoint=ENDPOINT, api_key=API_KEY, model_name=MODEL_NAME, api_version=API_VERSION):
self.endpoint = endpoint
self.api_key = api_key
self.api_version = api_version
self.model_name = model_name
self.client = AzureOpenAI(azure_endpoint=endpoint, api_key=api_key, api_version=api_version)
self._async_client = None
async def call_llm_with_json_output_async(self, system_prompt, user_input, json_schema, temperature=0):
# LLM呼び出しロジックが集約されている
実装を通じた気づき:
- API呼び出しの詳細を隠蔽することでビジネスロジックが明確になる
- モデル名やパラメータを一箇所で管理できる
- 同期版/非同期版の両方を提供することで柔軟性が増す
- ロギングや例外処理を共通化できる
もしAzure OpenAIから他のLLMプロバイダーに切り替えたくなっても、このサービス部分だけ修正すればOKというのは大きな強みです。
4. パターンを組み合わせる発想が実用の鍵
実際の実装を通して最も価値を感じたのは、これらのパターンを状況に応じて組み合わせる柔軟性です:
# 実装例:Routing→Orchestrator-Worker→Evaluator-Optimizer の連携
async def complex_booking_flow(user_input):
# STEP 1: Routing - ユーザー入力を分析して適切な処理を選択
intent = await analyze_intent(user_input)
if intent.is_booking_request:
# STEP 2: Orchestrator-Worker - 専門ワーカーによる情報収集
booking_plan = await create_booking_plan(user_input)
worker_results = await dispatch_to_workers(booking_plan)
# STEP 3: Evaluator-Optimizer - 出力品質の確保
confirmation = await optimize_confirmation(worker_results)
return confirmation
else:
# 予約以外の処理...
実装から学んだ考え方:
- 各パターンの長所を組み合わせることで弱点を補える
- 問題を「レイヤー」で考えると設計が明確になる
- 処理フローの見通しが良くなると保守性が向上する
- 再利用性の高いコンポーネントが自然と生まれる
理論より実践を通じて、これらのパターンを「積み木」のように組み合わせる感覚が身につきました。
まとめ:フレームワークの先へ、そして原点回帰 📝
フレームワークは確かに便利です。でも、自分で基礎から作り上げる楽しさは格別ですし、何よりどう動いているのかを体感しながら学べるのが大きなメリット。特に大規模言語モデルとの対話設計はまだまだ模索段階です。フレームワークに過剰適応してしまうより、根本的な「設計パターン」の理解を身につけておくほうが、中長期的には絶対に強い。
料理に例えると、レシピ本を見ながら作るのも良いけど、基本の調理法を身につけておけば、冷蔵庫にある材料で臨機応変に料理できるようになりますよね。それと同じです。
いずれにしても最終的には「要件に合わせて柔軟にパターンを組み合わせる」ことが大切。ぜひあなたの開発に合ったやり方を試してみてください。No Frameworkでも十分戦えますよ!(多分。しらんけど。)
最後に 📂
紹介したワークフローパターンをサンプルコードとしてまとめています。興味のある方は以下のGitHubをチェックしてみてください(再掲):
フレームワークが絶えずアップデートされる今の時代にこそ、基礎を押さえたスクラッチ開発の強みが生きてきます。一緒にAIエージェント開発の最前線を切り開いていきましょう!
【免責事項】
本記事の内容は執筆時点の情報に基づいています。製品の仕様や機能は予告なく変更される可能性があります。導入判断の際は、最新の公式情報を参照し、必要に応じて専門家に相談することをお勧めします。
Discussion