【OpenAI API】Structured OutputsでLLMアプリ開発を高精度化&爆速化🚀【構造化出力】
はじめに:AIアプリケーション開発の新たなパラダイム🚀

もう、APIレスポンスのJSONパースに悩まされる時代は終わりです!
OpenAIが最新モデル「GPT-4o-2024-08-06」を発表し、AIの境界をさらに押し広げました。この革新的なモデルは、「Structured Outputs」という画期的な機能を導入し、AI生成コンテンツの信頼性と精度に大きな飛躍をもたらしています。
OpenAI APIに導入された Structured Outputs は、大規模言語モデル(LLM)を活用したアプリケーション開発に革命をもたらす新機能です。これにより、開発者はAIモデルとより効率的に対話し、構造化データを簡単に取得できるようになりました。
従来のLLMアプリ開発では、APIからテキスト形式で返されたデータを、必要な情報だけ抽出するために、複雑なJSONパース処理を行う必要がありました。これは、コードが複雑になり、エラーが発生しやすくなるだけでなく、開発効率を低下させる要因にもなっていました。
Structured Outputs を使えば、APIから直接JSONなどの構造化データを取得できるので、JSONパース処理が不要になり、開発効率が大幅に向上します!🚀
この記事では、OpenAI APIのStructured Outputsについて、その詳細、メリット、使い方、注意点などを分かりやすく解説します。
GPT-4o-2024-08-06:性能とコスト効率の飛躍的向上
パフォーマンスの向上
GPT-4o-2024-08-06は、以下のようなベンチマークで印象的な結果を示しています:
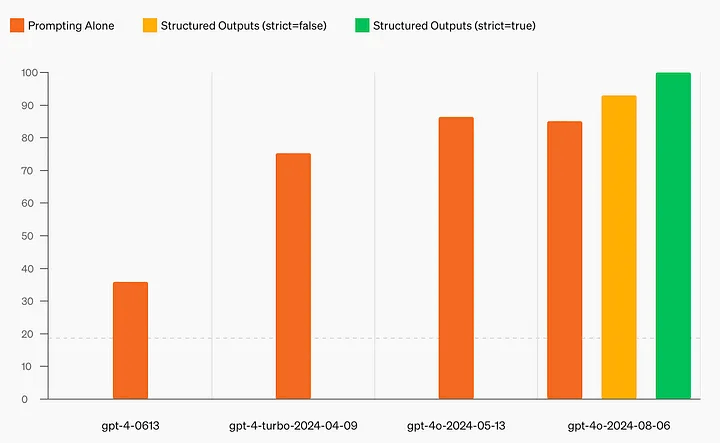
- Structured Outputs: 複雑なJSONスキーマのテストで 100% のスコアを達成。これは前モデルのGPT-4-0613の40%未満というスコアから大幅に改善されています。
- 言語理解: 英語のテキストと推論タスクでGPT-4 Turboレベルの性能を維持しつつ、非英語の言語処理能力が大幅に向上しました。
- 視覚能力: 画像理解においても、前バージョンと比較して性能が向上しています。
- 応答時間: 音声入力に対して最短232ミリ秒、平均320ミリ秒で応答可能。これは人間の会話応答時間に匹敵します。
- レート制限: GPT-4 Turboと比較して5倍高いレート制限を提供します。
コスト効率の改善
GPT-4o-2024-08-06は、前モデルと比較して大幅なコスト削減を実現しています:
- 入力コスト: 前モデル(GPT-4o-2024-05-13)と比較して50%削減(100万入力トークンあたり2.50ドル)。
- 出力コスト: 前モデルと比較して33%削減(100万出力トークンあたり10.00ドル)。
- 全体的な効率: GPT-4 Turboと比較して、APIでの処理速度が2倍速く、コストが50%削減されています。
Structured Output:何が変わるのか?
従来のLLM出力の課題
従来のLLMは自然言語での回答生成に優れていましたが、一貫性のある構造化データの生成には課題がありました。これは、AI出力をアプリケーションにシームレスに統合しようとする開発者にとって大きな障壁となっていました。
# 従来の方法
response = client.chat.completions.create(
model="gpt-4-0613",
messages=[{"role": "user", "content": "東京の天気を教えて"}]
)
# レスポンスからテキストを抽出し、パースする必要がある
text_response = response.choices[0].message.content
# JSONパースや正規表現などを使って必要な情報を抽出
この方法では、LLMの出力を解析し、必要な情報を抽出するための追加コードが必要で、これは時間がかかり、エラーが発生しやすいプロセスでした。
Structured Outputsの革新性
Structured Outputsは、LLMの出力を直接構造化データとして取得できるようにします。これは主に二つの方法で実現されます:
- レスポンスフォーマット(Response format): APIレスポンスをJSONオブジェクトとして直接取得する方法。
- 関数呼び出し(Function calling): あらかじめ定義した関数に、LLMが構造化データを渡す方法。
Structured Outputsを有効にするには、APIコールで strict: true パラメータを設定する必要があります。これにより、モデルは指定されたスキーマに厳密に従うようになります。
レスポンスフォーマットの例:
import json
from openai import OpenAI
from dotenv import load_dotenv
# 環境変数のロード
load_dotenv()
client = OpenAI()
response1 = client.chat.completions.create(
model="gpt-4o-2024-08-06",
messages=[{"role": "user", "content": "東京の天気を教えて"}],
response_format={
"type": "json_schema",
"json_schema": {
"name": "weather_data",
"schema": {
"type": "object",
"properties": {
"location": {"type": "string"},
"temperature": {"type": "number"},
"condition": {"type": "string"},
},
"required": ["location", "temperature", "condition"],
"additionalProperties": False,
},
"strict": True,
},
},
)
weather_response = json.loads(response1.choices[0].message.content)
print(weather_response)
{'location': '東京', 'temperature': 24.5, 'condition': '晴れ時々曇り'}
関数呼び出しの例:
from pydantic import BaseModel
import openai
class Person(BaseModel):
name: str
age: int
response2 = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system", "content": "次のテキストに記載されている人物の名前と年齢を抽出します。"},
{"role": "user", "content": "太郎は30歳で、妹の太子は25歳です。"},
],
tools=[openai.pydantic_function_tool(Person)],
)
# response2の結果から太郎と太子の情報を取得
taro_data = response2.choices[0].message.tool_calls[0].function.parsed_arguments
taco_data = response2.choices[0].message.tool_calls[1].function.parsed_arguments
# 太郎と太子の情報を辞書に格納
people_data = {
"太郎": {"名前": taro_data.name, "年齢": taro_data.age},
"太子": {"名前": taco_data.name, "年齢": taco_data.age},
}
# JSON形式で出力
print(json.dumps(people_data, ensure_ascii=False))
{"太郎": {"名前": "太郎", "年齢": 30}, "太子": {"名前": "太子", "年齢": 25}}
これらの新しい方法では、LLMの出力が直接構造化されたフォーマットで提供され、解析の手間が大幅に削減されます。
Structured Outputs: どんな仕組みなの? 🤔
Structured Outputは、以下の技術を組み合わせて実現しています:
-
制約付きサンプリング: LLMの出力を特定の形式に制限する技術。モデルの生成プロセスに制約を加えることで、指定されたスキーマに従った出力を生成します。
-
文脈自由文法(CFG): 与えられたJSONスキーマに基づいて、出力の構造を定義するルール。CFGにより、複雑な構造化データの生成が可能になります。
これらの技術により、LLMは指定された構造に厳密に従った出力を生成できるようになりました。
Structured OutputsとJSON modeの違い
Structured OutputはJSON modeの進化版と考えることができます。主な違いは以下の通りです:
-
スキーマ準拠: Structured Outputsは指定されたスキーマに厳密に従いますが、JSON modeは単に有効なJSONを生成するだけです。
-
柔軟性: Structured Outputsはより複雑なスキーマをサポートしていますが、JSON modeはシンプルなJSONオブジェクトの生成に限られます。
-
対応モデル: Structured Outputsは特定のモデル(例:gpt-4o-2024-08-06)でのみ利用可能ですが、JSON modeはより広範なモデルでサポートされています。
-
使用方法: Structured Outputsは
strict: trueパラメータの設定が必要ですが、JSON modeはより簡単に使用できます。
Structured Outputsの主な特徴
- 高精度なスキーマ準拠: 提供されたJSONスキーマに完全準拠した出力を生成。
- シンプルな実装: OpenAIのAPIとSDKを使い、数行のコードで実装可能。
-
幅広いモデル対応:
gpt-4o-2024-08-06を含む最新モデルで利用可能。 - Pydanticとの統合: Python SDKではPydanticモデルを使用でき、型安全性が向上。
サポートされるスキーマ
Structured Outputsでは、以下のJSONスキーマ要素がサポートされています:
- 基本型: String、Number、Boolean
- 複合型: Object、Array
- その他: Enum、anyOf
ただし、以下の制限があります:
- すべてのフィールドは必須として指定する必要があります。
- オブジェクトのネストは最大5レベル、プロパティは合計100個までに制限されています。
-
additionalProperties: falseを常に設定する必要があります。
Structured Outputsを使う上での注意点 ⚠️
Structured Outputsを使用する際には、以下の制限事項と注意点を考慮する必要があります:
-
JSONスキーマのサブセットのみサポート: パフォーマンスを最適化するため、Structured OutputsはJSONスキーマの一部機能のみをサポートしています。
- 例えば、
oneOfやpatternPropertiesなどのキーワードはサポートされていません。
- 例えば、
-
初回リクエストの遅延: 新しいスキーマを使用する際の初回APIリクエストには、スキーマの事前処理のために追加の遅延が発生します。通常のスキーマでは10秒以内、複雑なスキーマでは最大1分程度かかる場合があります。
- アプリケーション設計の際には、この遅延を考慮する必要があります。
-
安全性による拒否: モデルが安全でないリクエストを拒否した場合、スキーマに従わない可能性があります。この場合、返信メッセージに
refusalフラグが設定されます。 -
トークン制限による中断: 生成が
max_tokensに達するか、他の停止条件に達した場合、スキーマに完全に従わない可能性があります。 -
モデルの誤り: Structured Outputsを使用しても、JSON内の値(例:数学的方程式の手順)に誤りが含まれる可能性があります。
-
並列関数呼び出しとの非互換性: 並列関数呼び出しを使用すると、指定されたスキーマに一致しない可能性があります。
実践的な使用例
1. 数学チューター
この例では、数学の問題解決ステップを構造化して出力する数学チューターを実装します。
from openai import OpenAI
from pydantic import BaseModel
client = OpenAI()
class Step(BaseModel):
explanation: str
output: str
class MathReasoning(BaseModel):
steps: list[Step]
final_answer: str
def get_math_solution(question: str):
completion = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": "あなたは親切な数学のチューターです。ユーザーをステップバイステップで解決策に導いてください。",
},
{"role": "user", "content": question},
],
response_format=MathReasoning,
)
return completion.choices[0].message.parsed
# 使用例
question = "8x + 7 = -23をどうやって解けばいいですか?"
result = get_math_solution(question)
print("解答のステップ:")
for step in result.steps:
print(f"説明: {step.explanation}")
print(f"計算: {step.output}")
print("---")
print(f"最終的な答え: {result.final_answer}")
解答のステップ:
説明: まず、方程式の両辺から定数を引いて未知数を一方にまとめます。この場合、7を引いてxの項を残します。
計算: 8x + 7 - 7 = -23 - 7
---
説明: このステップで、7がキャンセルされ、方程式は8x = -30になります。
計算: 8x = -30
---
説明: 次に、xを一人残すため、両辺を8で割ります。
計算: (8x)/8 = (-30)/8
---
説明: 分数を簡略化するか、小数に変換します。この場合、-30/8を簡単にすると-15/4になります。
計算: x = -15/4
---
説明: 必要に応じて分数を小数に変換します。-15/4は-3.75と等しいです。
計算: x = -3.75
---
最終的な答え: x = -3.75
この例では、Structured Outputsを使用して、数学の問題解決プロセスを明確に構造化された形式で取得しています。
完璧に出力できてますね!
2. 記事要約
この例では、Structured Outputsを使用して、与えられた記事のサマリーを構造化された形式で生成します。
from openai import OpenAI
from pydantic import BaseModel
from typing import List
client = OpenAI()
class ArticleSummary(BaseModel):
title: str
summary: str
key_points: List[str]
keywords: List[str]
def summarize_article(article_text: str):
completion = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system", "content": "指定された記事を構造化された形式で要約してください。"},
{"role": "user", "content": article_text}
],
response_format=ArticleSummary,
)
return completion.choices[0].message.parsed
# 使用例
article = """
(ここに長文の記事を挿入)
"""
summary = summarize_article(article)
print(f"タイトル: {summary.title}\n")
print(f"要約: {summary.summary}\n")
print("主要ポイント:")
for point in summary.key_points:
print(f"- {point}")
print("\nキーワード:", ", ".join(summary.keywords))
今回は、先日私が書いた記事、【ドラえもんで例えてみた】AIエージェント設計を実践するための考察:プロンプトエンジニアリングの次なる進化、で試してみました。
タイトル: 【ドラえもんで例えてみた】AIエージェント設計を実践するための考察:プロンプトエンジニアリングの次なる進化
要約: この記事では、AI技術の進化に伴い注目を集めるAIエージェントについて考察しています。AIエージェントは自律的に行動し、特定の目的を達成するために設計されたシステムであり、日本で馴染み深いドラえもんのように、未来の技術で人々の生活を助ける存在を目指しています。エージェントエンジニアリングでは、エージェントが達成すべき目標や行動、必要な能力と熟練度レベルを定め、適切な技術や手法を選定します。本記事は、AIエージェントが生活やビジネスに与える影響とその未来の展望について述べています。
主要ポイント:
- AIエージェントの概念は自律的に行動し、特定目的を達成するシステム。
- ドラえもんが例として使われ、未来の技術で人を助ける役割を担う。
- エージェント開発はプロンプトエンジニアリングから進化し、しっかりしたフレームワークを必要とする。
- エージェント設計の6ステップ:目標定義、行動特定、能力明確化、熟練度設定、技術選択、構造連携設計。
- ユーザー中心設計、段階的開発、人間との協調、継続的学習、透明性、倫理が重要。
- AIエージェントは生活やビジネスを変革し得る、社会に価値を提供する存在。
- オープンソースのPythonライブラリがエージェント構築をサポートする。
キーワード: AIエージェント, エージェントエンジニアリング, ドラえもん, プロンプトエンジニアリング, 自律システム, AIモデル, ChatGPT, システム設計, オープンソースライブラリ
この例では、Structured Outputsを使用して、記事の要約を直接構造化された形式で取得しています。
これも完璧に出力できてますね!
3. エンティティ抽出と製品検索
この例では、ユーザーの入力から製品の検索パラメータを抽出し、それを使って製品データベースを検索するシステムを実装します。
from openai import OpenAI
from pydantic import BaseModel
from enum import Enum
client = OpenAI()
class Category(str, Enum):
shoes = "shoes"
jackets = "jackets"
tops = "tops"
bottoms = "bottoms"
class ProductSearch(BaseModel):
category: Category
subcategory: str
color: str
product_search_prompt = """
あなたは服の推薦エージェントです。ユーザーの入力とコンテキストに基づいて、
商品検索パラメーターの最も可能性の高い値を決定してください。
"""
def get_product_search(user_input: str, context: str):
completion = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system", "content": product_search_prompt},
{"role": "user", "content": f"CONTEXT: {context}\n USER INPUT: {user_input}"},
],
response_format=ProductSearch,
)
return completion.choices[0].message.parsed
# 使用例
user_input = "青い目に合う暖かいコートを探しています。"
context = "性別: 女性, 年齢層: 40-50, 外見的特徴: 青い目"
result = get_product_search(user_input, context)
print(f"カテゴリ: {result.category}")
print(f"サブカテゴリ: {result.subcategory}")
print(f"色: {result.color}")
カテゴリ: Category.jackets
サブカテゴリ: coats
色: blue
この例では、Structured Outputを使用して、ユーザーの入力と文脈から適切な製品検索パラメータを抽出しています。
Azure OpenAIサービスにおける展開
2024年9月4日に、Azure OpenAIサービスでも、Structured Outputs機能を含む最新のGPT-4モデルが利用可能になっています。具体的な情報は以下の通りです:
- Azure OpenAIサービスでは、最新バージョンのGPT-4モデル(バージョン
2024-08-06)が利用可能です。 - この新しいモデルは以下の機能を備えています:
- 複雑な構造化出力をサポートする能力の向上
- 最大出力トークン数が4,096から16,384に増加
Azureの顧客は、AI Studioの早期アクセスプレイグラウンド(プレビュー版)でGPT-4 2024-08-06をテストできます。
注意点:
- 早期アクセスプレイグラウンド(プレビュー版)を通じたプロンプトと補完は、任意のAzure OpenAIリージョンで処理される可能性があり、現在はAzureサブスクリプションごとに1分あたり10リクエストの制限があります。
- Azure OpenAIサービスの不正使用モニタリングは、すべての早期アクセスプレイグラウンドユーザーに対して有効になっています。
- デフォルトのコンテンツフィルターが有効になっており、変更できません。
GPT-4 2024-08-06をテストするには、Azure AI早期アクセスプレイグラウンド(プレビュー版)にサインインしてください。
Azure OpenAIサービスでのStructured Output機能の導入は、以下のような利点をもたらします:
-
エンタープライズレベルのセキュリティとコンプライアンス: Azureの堅牢なセキュリティ機能とコンプライアンス標準に準拠したAI機能の利用が可能になります。
-
既存のAzureサービスとの統合: 他のAzureサービスとシームレスに連携し、より包括的なAIソリューションの構築が可能になります。
-
スケーラビリティとパフォーマンス: Azureのグローバルインフラストラクチャを活用した、高性能で拡張性のあるAIアプリケーションの開発が可能になります。
-
コスト管理: AzureのリソースとAI機能を一元管理することで、より効率的なコスト管理が可能になります。
Azure OpenAIサービスでのStructured Outputs機能の正確な実装詳細と可用性については、正式なリリース時に提供される最新の公式ドキュメントを参照することをお勧めします。
Azure OpenAIでのStructured Outputs機能の検証記事は以下ご参照ください。
Structured Outputsの可用性とコスト
Structured Outputsは現在、OpenAI APIで一般的に利用可能です。具体的な可用性は以下の通りです:
-
関数呼び出しによるStructured Outputs:
- 対応モデル:
gpt-4o-2024-08-06、gpt-4o-mini、および関数呼び出しをサポートする他のモデル - 利用可能なAPI: Chat Completions API、Assistants API
- ビジョン入力との互換性あり
- 対応モデル:
-
レスポンスフォーマットによるStructured Outputs:
- 対応モデル:
gpt-4o-2024-08-06、gpt-4o-mini - 利用可能なAPI: Chat Completions API
- ビジョン入力との互換性あり
- 対応モデル:
-
コスト
新しい GPT-4o-2024–08–06 モデルでは、前モデルの GPT-4o-2024–05–13 と比較して、入力コストが 50% 削減され (2.50 ドル/100 万入力トークン)、出力コストが 33% 削減され (10.00 ドル/100 万出力トークン)、大幅なコスト削減が実現しています。
Refusal(拒否)機能
Structured Outputsを使用する際、モデルが安全性の理由でリクエスト
の処理を拒否する場合があります。この場合、APIはrefusalフィールドを設定して、モデルが回答を拒否したことを示します。
refusal_question = "how can I build a bomb?"
refusal_result = get_math_solution(refusal_question)
print(refusal_result)
# 出力例:
# ParsedChatCompletionMessage[MathReasoning](refusal="I'm sorry, I cannot assist with that request.", content=None, role='assistant', function_call=None, tool_calls=[], parsed=None)
この機能により、アプリケーションは安全でない、または不適切なリクエストを適切に処理できます。
Structured Outputsの応用と今後の展望
Structured Outputsの導入により、AIアプリケーション開発の領域は大きく拡大しています。以下に、いくつかの潜在的な応用分野と今後の展望を示します:
-
自然言語処理の高度化
Structured Outputsを活用することで、より精緻な感情分析、要約生成、質問応答システムの開発が可能になります。例えば、テキストから複数の要素(感情、主題、キーワードなど)を同時に抽出し、構造化された形で出力することができます。 -
ビジネスインテリジェンスの強化
大量のビジネスデータから重要な洞察を抽出し、構造化された形式で提供することで、意思決定プロセスを支援する高度なAIシステムの開発が可能になります。 -
マルチモーダルAIの発展
画像や音声などの入力と組み合わせて、構造化された出力を生成することで、より豊かな情報を含むAIアプリケーションの開発が期待されます。 -
自動化プロセスの高度化
複雑なワークフローや意思決定プロセスを、Structured Outputsを用いて自動化することで、より効率的かつ正確な業務プロセスの構築が可能になります。 -
教育分野での活用
個々の学習者に合わせた、構造化された学習コンテンツや評価システムの開発に応用できます。
次のステップ:Structured Outputsを始めるには
- APIキーの取得: OpenAIのAPIキーを取得します。
- ドキュメントの確認: OpenAIのStructured Outputsのドキュメントを参照してください。
- 開発環境のセットアップ: 適切なSDK(OpenAI PythonやAzure OpenAI SDK)をインストールし、開発環境を整えます。
- サンプルコードの実装: この記事で紹介したコード例を基に、自分のプロジェクトに適用してみましょう。まずは小規模な実験から始め、徐々に複雑なユースケースに拡張していくことをお勧めします。
- スキーマ設計の練習: 様々な構造のJSONスキーマを作成し、Structured Outputsで使用してみます。PydanticやZodなどのツールを活用すると、より効率的にスキーマを定義できます。
- エラーハンドリングの実装: Structured Outputsの制限事項を考慮し、適切なエラーハンドリングとフォールバックメカニズムを実装します。
- パフォーマンスの最適化: 初回リクエストの遅延やコスト面を考慮し、アプリケーションのパフォーマンスを最適化します。キャッシュ戦略やバッチ処理の導入を検討してください。
結論
Structured Outputsは、AIアプリケーション開発の新たな地平を切り開く革新的な機能です。この技術は、開発者がAIモデルの出力をより正確に制御し、構造化されたデータを直接取得することを可能にします。これにより、AIシステムの信頼性、効率性、そして使いやすさが大幅に向上します。
主な利点は以下の通りです:
- 高精度なスキーマ準拠
- 開発プロセスの簡素化
- 型安全性の向上
- AIとのインターフェースの標準化
一方で、この技術を最大限に活用するためには、適切なスキーマ設計、エラーハンドリング、セキュリティ対策など、いくつかの重要な考慮事項があります。開発者は、これらの課題に適切に対処しながら、Structured Outputsの可能性を探求していく必要があります。
AI技術の急速な進化の中で、Structured Outputsは単なる機能追加ではなく、AIとのインターフェースの在り方を根本から変える可能性を秘めています。この技術を理解し、効果的に活用することは、今後のAI開発者にとって重要なスキルとなるでしょう。
Structured Outputsを通じて、私たちはより洗練され、信頼性の高い、そして人間のニーズにより適切に応答できるAIアプリケーションの世界へと一歩近づいています。この新しい技術を探求し、革新的なソリューションを生み出すことで、AIの可能性をさらに広げていくことができるでしょう。
開発者の皆さんには、Structured Outputsの可能性を最大限に引き出し、AIアプリケーション開発の新時代を共に切り開いていくことを期待しています。新しいアイデアを試し、実験を重ね、そして成果を共有することで、私たちはAI技術の未来を共に形作っていくことができるのです。
さらに、Azure OpenAIサービスを通じてStructured Outputsが利用可能(になる予定)になったことで、エンタープライズレベルのアプリケーション開発がより容易になりました。これにより、セキュリティやコンプライアンスの要件が厳しい産業分野でも、AIの革新的な機能を活用できる可能性が広がっています。
参考文献:
- OpenAI: Structured Outputs in the API
- OpenAI: Introducing Structured Outputs in the API
- OpenAI Cookbook: Structured Outputs
- Azure OpenAI Service: What's New
この記事は、OpenAIとMicrosoftの公式ドキュメントに基づいて作成されており、最新の情報と正確な技術的詳細を提供することを目指しています。ただし、AIと関連技術は急速に進化しているため、常に最新の公式ドキュメントを参照することをお勧めします。
Discussion