【コード付き】話題のADKとAOAIでマルチエージェントを作成して遊ぼう🚀【クラウド環境へのデプロイ方法解説あり】

こんにちわ!
2025年に入り、大規模言語モデル(LLM)の進化は目覚ましく、単に質問に答えるだけでなく、より複雑なタスクを自律的にこなす「AIエージェント」への期待が高まってきています。
特に、複数のエージェントが連携し、それぞれの専門性を活かして問題を解決する「マルチエージェントシステム」は、ビジネスプロセスの自動化や高度な意思決定支援など、様々な分野での応用が期待されています。そんな中、Googleから登場したAgent Development Kit (ADK)は、この複雑なマルチエージェント開発を、より身近なものにしてくれる可能性を秘めています。
この記事では、実際にADKとAzure OpenAI Service (AOAI)を組み合わせてマルチエージェントシステムを構築する際の、具体的な手順、直面した課題、そして見えてきた可能性について、技術的な詳細と共にご紹介します。ADKとAOAIを使った実践的な開発に関心のあるエンジニアの方々にとって、開発のヒントとなれば幸いです。
以下は本記事の検証コード一式となります↓
まずは、今回の検証モチベーションについて、そして上記のコードについての解説や試行錯誤した際の気付きメモ、全体の考察などを書いていきたいと思います!
なぜ今、ADKとAOAIによるマルチエージェントなのか
私がマルチエージェントに注目し始めたのは、あるプロジェクトでの経験がきっかけでした。単一のLLMエージェントでは対応しきれない、複数の専門知識や情報源を統合する必要がある複雑なタスクに直面したのです。例えば、市場調査レポートを作成する際、Webから最新ニュースを収集し、社内のデータベースから過去の販売データを取得し、専門家の知見(特定のプロンプトで引き出す)を組み合わせる、といった具合です。
これを単一のエージェントで実現しようとすると、プロンプト(指示文)が極めて長大かつ複雑になり、管理もデバッグも困難を極めました。エージェントはしばしば指示を誤解し、期待通りの動きをしてくれません。まさに「万能ナイフ」を作ろうとして、どのツールも中途半端になってしまうような状況でした。
そこで、「役割分担」という考え方が重要になってきます。Web検索が得意なエージェント、データベースアクセスが得意なエージェント、文章生成が得意なエージェント…といったように、特定のタスクに特化したエージェントを複数用意し、それらを連携させることで、複雑なタスクを効率的かつ正確に遂行できるのではないかと考えました。

図: ADK+AOAIでマルチエージェント Let's makeなイメージ絵(by ChatGPT)
このマルチエージェントシステムを実現するためのフレームワークとして、様々なフレームワークがある中でADKは一つの選択肢として魅力的に映りました。Pythonベースでコード中心の開発が可能であり、Google自身の製品で使われている実績もある。さらに、特定のLLMに縛られず、Azure OpenAIのような他の強力なモデルと組み合わせられる柔軟性も決め手となりました。AOAIは、エンタープライズレベルのセキュリティと信頼性を提供し、既存のAzure環境との親和性も高い。この二つの技術を組み合わせることで、実用的なマルチエージェントシステムを構築しやすいかなと好奇心的に思い早速手を動かしてみよう!と思いました。
ADK公式ドキュメント↓
ADKの核心を探る エージェント開発の道具箱
ADKを理解する上で、いくつかの重要な構成要素を知っておく必要があります。これらは、まるで熟練の職人が使う道具箱の中身のように、それぞれが特定の役割を担い、組み合わせることで強力なエージェントシステムを構築することを可能にします。
システムの「頭脳」と「指揮者」
エージェントの種類を理解する
ADKにおける「エージェント」は、タスクを実行する主体であり、大きく二つのタイプに分けられます。
一つ目は LlmAgent です。これは、LLMの推論能力を活用して、ユーザーの指示を理解し、状況に応じて判断し、応答を生成する、いわばシステムの「頭脳」にあたるエージェントです。自然言語での対話や、複雑な意思決定が求められる場面で活躍します。今回の記事で主に扱うのは、このLlmAgentです。
二つ目は Workflow Agent です。こちらは、LLMの推論に頼らず、あらかじめ定義された確定的な順序やルールに従って、他のエージェント(サブエージェント)の実行フローを制御します。具体的には、複数のサブエージェントを順番に実行する SequentialAgent、並行して実行する ParallelAgent、特定の条件が満たされるまで繰り返し実行する LoopAgent などがあります。これにより、予測可能で信頼性の高い処理フローを構築できます。例えば、「まずデータ収集エージェントを実行し、次に分析エージェントを実行し、最後にレポート生成エージェントを実行する」といった一連の流れを確実に制御したい場合に有効です。
エージェントに「手足」を与えるツールの役割と種類
エージェントは、単にLLMと対話するだけではありません。「ツール」を使うことで、外部の世界と連携し、より多様なアクションを実行できるようになります。ツールは、エージェントに特定の能力を与えるPython関数やクラスメソッドと考えることができます。
ADKでは、様々な種類のツールがサポートされており、エージェントの能力を大きく拡張します。
Function Tools 独自機能を実装する
まず基本となるのが、開発者がPython関数として独自に定義する Function Tools です。これは、特定のAPIを叩いたり、データベースに問い合わせたり、あるいは独自の計算ロジックを実行したりと、アプリケーション固有の要求に応じた機能を実装するためのものです。ここで非常に重要なのは、関数のDocstring(説明文)です。LLMはDocstringを読み解いて、そのツールが何をするのか、どのような引数(パラメータ)を必要とするのか、そしてどのような結果を返すのかを理解します。したがって、Docstringは人間が読むのと同じくらい、LLMにとっても明確かつ正確である必要があります。曖昧な説明では、LLMはツールを適切に使いこなすことができません。
Agent-as-a-Tool エージェント自身をツールに
ADKの興味深い機能の一つが、Agent-as-a-Tool です。これは、あるエージェントを、別のエージェントから呼び出せる「ツール」として扱えるようにするものです。例えば、非常に専門的な分析を行うエージェントがいたとして、それを汎用的なアシスタントエージェントが必要に応じて呼び出す、といった連携が可能になります。これにより、エージェントの機能をモジュール化し、複雑なマルチエージェントシステムを階層的に構築することが容易になります。まさに、専門家チームに仕事を依頼するような感覚です。
Built-in Tools すぐに使える便利機能
ADKには、Built-in Tools として、開発の手間を省くための便利なツールがいくつか標準で用意されています。例えば、Web検索を行うためのツールや、Pythonコードを安全な環境で実行するためのツールなどです。これらを利用することで、基本的な外部連携機能を迅速に実装できます。
Third-Party Tools 既存エコシステムとの連携
さらに、ADKは Third-Party Tools との連携も考慮されています。LangChainやCrewAIといった、すでに普及している他のAIエージェントフレームワークで開発されたツール資産を、ADKのエージェントから利用するための仕組みも提供されています。これにより、既存のツールエコシステムを活用しつつ、ADKの持つオーケストレーション機能などを組み合わせることが可能です。
このように、ADKは多様なツール連携の選択肢を提供することで、エージェントが単なる対話ボットにとどまらず、実世界とインタラクションし、具体的なアクションを実行できる強力な存在となることを可能にしています。
会話の「記憶」をどう管理するか
セッションとステート
人間同士の会話では、前の発言を踏まえて次の会話が進みます。AIエージェントとの対話においても、この「文脈」の維持は自然なインタラクションのために不可欠です。ADKでは、この文脈管理を「セッション(Session)」と「ステート(State)」という二つの概念で実現しています。
セッションは、ユーザーとエージェント間の一連の対話全体をカプセル化する単位です。特定のユーザーとの会話が始まった時点から終了するまでが、一つのセッションとして扱われます。このセッションには、それまでのユーザーとエージェントの発言履歴、エージェントが思考する過程(thought)、使用したツールの呼び出し履歴やその結果、そして生成されたファイルなどの成果物(アーティファクト)といった、対話に関するあらゆる情報が紐づけられます。これにより、過去のやり取りを踏まえた応答が可能になります。
一方、ステートは、セッション内でのより短期的な記憶領域として機能します。エージェントは、タスクを実行する過程で得られた中間的な情報や計算結果、あるいは特定のフラグなどをステートに保存できます。そして、同じセッション内の後続の処理ステップや、連携する他のエージェントが、このステートに保存された情報を参照したり、更新したりできます。これは、特に複数のエージェントが協力して一つのタスクを進めるマルチエージェントシステムにおいて、エージェント間で情報を効率的に共有するための重要なメカニズムとなります。例えば、「Web検索エージェントが見つけたURLリスト」をステートに保存し、次に「レポート生成エージェント」がそのURLリストをステートから読み出して利用する、といった連携が可能になるのです。
このように、セッションが対話全体の長期的な文脈を保持するのに対し、ステートはタスク遂行中の短期的な作業記憶を提供する、と考えると理解しやすいでしょう。ADKはこれらの仕組みを通じて、文脈を理解し、情報を引き継ぎながら、より複雑で首尾一貫したタスクを実行できるエージェントの構築を支援します。
セッションとステートの関係、およびマルチエージェントシステムにおける情報の流れを視覚的に表すと以下のようになります:
図: ADKにおけるセッションとステートの構造と情報の流れ
この図に示されるように、セッションは対話全体のコンテキストを包含し、その中でステートがエージェント間の情報共有と連携のハブとして機能します。Web検索エージェントやデータベースエージェントが収集した情報はステートに保存され、レポート生成エージェントがそれらを参照して最終的な成果物を生成するという流れが実現されます。
全体を動かす「指揮者」であるRunnerの役割とは?
エージェントの定義、ツールの準備、セッション管理の仕組みが整ったとしても、それらを実際に動かし、ユーザーからの入力に応じて適切に連携させる「何か」が必要です。その役割を担うのが Runner です。
Runnerは、ADKアプリケーションにおけるオーケストレーター、あるいは実行エンジンと言える存在です。ユーザーからの新しいメッセージを受け取ると、Runnerは指定されたルートエージェントの実行を開始します。エージェントがLLMに思考を問い合わせたり、ツールを使用したり、あるいはサブエージェントに処理を委譲したりする一連のプロセスは、すべてRunnerの管理下で進行します。
具体的には、Runnerは以下のような責務を持ちます。
まず、エージェントの起動と実行です。ユーザー入力(new_message)をトリガーとして、指定されたエージェント(通常はルートエージェント)の実行プロセスを開始します。
次に、サービスの連携を行います。エージェントが必要とする各種サービス(SessionService, MemoryService, ArtifactService など)へのアクセスを提供し、エージェントが会話履歴の参照、状態の読み書き、成果物の保存などを行えるようにします。(これらのサービスはRunner初期化時に指定可能ですが、指定しない場合はデフォルトのインメモリ実装が使用されます。)
そして、イベントの処理と伝達も重要な役割です。エージェントの実行中に発生する様々なイベント(LLMからの応答、ツールの呼び出し要求、サブエージェントへの処理委譲など)を捉え、それに応じて適切な処理(LLMへのリクエスト送信、ツール関数の実行、担当エージェントの切り替えなど)を行います。
最後に、結果の返却です。エージェントの処理が一通り完了した後、最終的な応答や実行結果を呼び出し元(通常はアプリケーションコード)に返します。非同期実行(run_async)の場合、処理の進行状況を示すイベントのストリームを返すため、リアルタイムな応答表示なども可能です。
開発者は、利用したいエージェントと必要に応じて各種サービスを指定してRunnerのインスタンスを作成し、その run または run_async メソッドを呼び出すことで、定義したエージェントシステムを実際に動作させることができます。Runnerは、エージェント開発における複雑な実行フロー制御を抽象化し、開発者がエージェントのロジックそのものに集中できるように支援してくれる、まさに縁の下の力持ちなのです。
これらのコンポーネントを理解し、適切に組み合わせることが、ADKを用いた効果的なエージェント開発の鍵となります。
AOAIとの実践的な連携方法
ADKは特定のLLMに依存しない設計思想を持っていますが、実際にAzure OpenAI Service (AOAI)と連携させるには、いくつかの設定が必要です。ADKはGoogleのGeminiモデルに最適化されていますが、litellmというライブラリを介することで、AOAIを含む様々なLLMプロバイダーに対応できます。
まずは準備からということで環境設定とライブラリについて
まず、必要なライブラリをインストールします。ADK本体に加えて、litellm が必要です。
uvで仮想環境を作成します。
# 仮想環境内での実行を推奨
mkdir <任意のディレクトリ名>
cd path/to/your_directory
uv venv -p 3.12 # 仮想環境の作成
source .venv/bin/activate # 仮想環境のアクティベート
uv pip install -U google-adk==0.3.0 litellm==1.67.2 python-dotenv==1.1.0 openai==1.76.0
次に、プロジェクトのルートディレクトリに .env ファイルを作成し、AOAIへの接続情報を記述します。今回はせっかくなので先日4/14から提供開始され始めたgpt-4.1を使用しました。
参考記事:AzureでGPT-4.1の提供開始アナウンス
# .env ファイルの例
AZURE_API_KEY="YOUR_AZURE_API_KEY"
AZURE_API_BASE="YOUR_AZURE_ENDPOINT" # 例: https://your-aoai-resource.openai.azure.com/
# APIバージョンは利用するモデルや機能に応じて適切なものを指定してください
# 最新情報はAzure OpenAI Serviceのドキュメントを参照
AZURE_API_VERSION="2024-02-01" # 例: 最新の安定バージョンを確認すること
AZURE_DEPLOYMENT_ID="YOUR_DEPLOYMENT_NAME" # Azure Portalで設定したデプロイ名(例:gpt-4.1)
# LiteLLMがAOAIを利用することを明示的に示すための設定 (オプションだが推奨)
LITELLM_AZURE_API_KEY=$AZURE_API_KEY
LITELLM_AZURE_API_BASE=$AZURE_API_BASE
LITELLM_AZURE_API_VERSION=$AZURE_API_VERSION
これらの環境変数をプログラムから読み込むために、dotenv ライブラリを使用します。
# config.py や agent.py の冒頭で実行
import os
from dotenv import load_dotenv
# .env ファイルが存在すれば環境変数を読み込む
load_dotenv()
ADKエージェントにAOAIの「魂」を吹き込む
モデル指定
ADKの LlmAgent を定義する際に、model パラメータでAOAIモデルを指定します。litellm を利用する場合、モデル名の前に azure/ を付け、続けてAzure Portalで設定したデプロイメント名を指定するのが一般的です。
# agents.py などで定義
from google.adk.agents import LlmAgent
from google.adk.models.lite_llm import LiteLlm # LiteLLM連携用のモデルクラス
import os
# 環境変数からデプロイメント名を取得
azure_deployment_id = os.getenv("AZURE_DEPLOYMENT_ID")
if not azure_deployment_id:
raise ValueError("環境変数 'AZURE_DEPLOYMENT_ID' が設定されていません。")
# LiteLlmクラスを使用してAOAIモデルを指定
# modelパラメータには 'azure/[デプロイメント名]' を指定します
aoai_model = LiteLlm(
model=f"azure/{azure_deployment_id}",
# temperature=0.7, # 必要に応じて温度などのパラメータを設定
# max_output_tokens=1024, # 必要に応じて最大トークン数を設定
)
# LlmAgentの定義例
my_aoai_agent = LlmAgent(
name="my_aoai_powered_agent",
model=aoai_model, # 作成したLiteLlmインスタンスを渡す
description="AOAIを利用するエージェント",
instruction="あなたはAOAIによって動作するエージェントです。...",
tools=[] # 必要に応じてツールを定義
)
print(f"Agent '{my_aoai_agent.name}' created using Azure OpenAI deployment: {azure_deployment_id}")
注意点:
-
litellm依存-
litellmは内部でopenaiライブラリを利用してAOAIと通信します。litellmやopenaiのバージョンアップによって、設定方法や挙動が変わる可能性があるため、依存関係の管理と公式ドキュメントの確認が重要です。
-
- APIバージョンの確認
-
.envファイルに記載するAZURE_API_VERSIONは、利用したいAOAIの機能やモデルによって要求されるバージョンが異なります。Azureの公式ドキュメントで最新情報を確認してください。
-
- 環境変数の正確性
- AOAIのエンドポイント (
AZURE_API_BASE)、APIキー (AZURE_API_KEY)、デプロイ名 (AZURE_DEPLOYMENT_ID) が正しく設定されていない場合、litellmは接続エラーとなります。エラーメッセージを確認し、設定を見直してください。
- AOAIのエンドポイント (
これで、ADKエージェントの「頭脳」としてAOAIを利用する準備が整いました。次は、実際にマルチエージェントシステムを構築していきましょう。
プロジェクトの構成
今回の実装を進めるにあたり、最終的に動作確認が取れたプロジェクトのフォルダ・ファイル構成を先に示しておきます。ADK、特に adk web コマンドでエージェントを正しく認識させるためには、特定の構造に従うことが有効でした。
<任意のディレクトリ名>/ <-- プロジェクトルートディレクトリ (この場所で `adk web` を実行)
├── agent_pkg/ <-- エージェント関連コードを格納するPythonパッケージ
│ ├── __init__.py <-- パッケージ初期化ファイル (agent.py をインポート)
│ ├── agent.py <-- エージェント定義の本体 (root_agent を含む)
│ └── tools.py <-- ツール関数の定義
├── main.py <-- プログラムからエージェントを実行するスクリプト
└── .env <-- 環境変数ファイル
各ファイルの役割(ADK Web UIとの関連で重要):
-
zenn-adk/(ルート): このディレクトリがプロジェクトの起点となります。adk webコマンドは、このディレクトリから(引数なしで)実行することを想定しています。 -
agent_pkg/: エージェント関連のコードをまとめるためのサブディレクトリです。これをPythonパッケージとして認識させるために__init__.pyを配置します。adk webは、このディレクトリ名をデフォルトのアプリケーション名として認識します。 -
agent_pkg/__init__.py: このファイルが存在することでagent_pkgディレクトリがPythonパッケージとして扱われます。ADK 0.3.0 のadk webの挙動に合わせて、このファイル内でagent.pyをインポートしておくことが、エージェント発見のために必要でした。 -
agent_pkg/agent.py: これがエージェント定義の中心ファイルです。LlmAgentを使ってcoordinator_agentやサブエージェントを定義し、ファイルの一番最後にroot_agent = coordinator_agentという行を記述します。adk webは、agent_pkg.agent.root_agentというパスでこの変数を見つけようとします。 -
agent_pkg/tools.py: ツール関数を定義します。agent.pyからはfrom .tools import ...のように相対パスでインポートします。 -
main.py: プロジェクトルートに配置し、agent_pkg.agentからエージェントをインポートしてRunnerで実行します。 -
.env: プロジェクトルートに配置し、agent.pyなどからはload_dotenv(dotenv_path=os.path.join(os.path.dirname(__file__), '..', '.env'))のように親ディレクトリを指定して読み込みます。
このパッケージ構造を採用することで、ADKの(特にバージョン0.3.0の)adk web コマンドがエージェントを正しく認識し、Web UIを起動できるようになりました。
実践編 市場調査レポート作成マルチエージェントシステム
それでは、上記のプロジェクト構成を前提に、具体的なシナリオとして、複数の情報ソースを統合して市場調査レポートのドラフトを作成するマルチエージェントシステムを構築していきましょう。このシステムでは、主に4つの役割を担うエージェントが連携します。
まず、ユーザーからの指示を受け取り、タスク全体を調整するルートエージェント (CoordinatorAgent) がいます。このコーディネーターが、必要に応じて他の専門エージェントに指示を出します。
具体的には、最新の市場トレンドやニュースをWebから検索・収集する Web検索エージェント (WebSearchAgent)、社内の製品データベースや販売履歴データベースから関連情報を検索する データベース検索エージェント (DatabaseAgent)(今回はモック実装です)、そして、各エージェントから収集された情報を基に、構造化されたレポートのドラフトを作成する レポート生成エージェント (ReportGeneratorAgent) です。
これら4つのエージェントがチームとして機能し、一つの市場調査レポートを完成させることを目指します。
システムの全体像を描く
アーキテクチャ設計
全体の構成をMermaid図で示します。ルートエージェントが中心となり、各サブエージェントと連携する様子がわかります。
図: 市場調査レポート作成マルチエージェントのアーキテクチャ
外部と繋がる「窓口」 ツールを定義する
agent_pkg/tools.py ファイルに、Web検索とデータベース検索のツール関数を定義します。
# agent_pkg/tools.py
import json
import logging
import time
from typing import List, Dict, Any # 型ヒントのために追加
logger = logging.getLogger(__name__)
def search_web(query: str, num_results: int = 3) -> str:
"""
指定されたクエリでWebを検索し、関連性の高いページの要約を返します。
Args:
query (str): 検索クエリ。具体的であるほど良い結果が得られます。
num_results (int): 返却する検索結果の最大数。デフォルトは3。
Returns:
str: 検索結果のリストを含むJSON文字列。各結果は 'title', 'link', 'snippet' をキーに持つ辞書。
エラーが発生した場合は、'error' キーを含むJSON文字列。
"""
logger.info(f"--- Tool: search_web called with query: '{query}', num_results: {num_results} ---")
# モック実装
try:
time.sleep(1)
if "EV" in query or "電気自動車" in query:
mock_results = [
{"title": "EV市場の最新トレンド 2024年版レポート", "link": "https://example.com/reports/ev-trends-2024", "snippet": "世界のEV市場は、政府の補助金政策と消費者の環境意識の高まりを背景に、前年比30%以上の成長を記録。特に中国市場の拡大が顕著。バッテリーコストの低減と航続距離の向上が今後の普及の鍵。主要メーカーは充電インフラへの投資も加速させている。"},
{"title": "主要自動車メーカーのEV戦略と競合分析", "link": "https://example.com/analysis/ev-competitors", "snippet": "Teslaが依然として市場をリードする一方、Volkswagenグループ、GM、現代自動車グループなどが新型EVを相次いで投入し追撃。BYDをはじめとする中国勢の低価格モデルも脅威となっている。各社はソフトウェア定義型車両(SDV)への移行も視野に入れた開発を進めている。"},
{"title": "EV普及に向けた課題と技術革新", "link": "https://example.com/tech/ev-challenges-innovations", "snippet": "航続距離への不安(レンジ不安)や充電インフラの不足は依然として課題。全固体電池や急速充電技術の開発が進められている。また、リチウムイオン電池のリサイクルやサプライチェーンの確保も持続可能な普及には不可欠な要素となっている。"},
{"title": "消費者のEV購入意向調査", "link": "https://example.com/survey/ev-consumer-intent", "snippet": "最新の調査によると、消費者のEVへの関心は高まっているものの、購入の決め手としては価格、航続距離、充電の利便性が上位を占める。環境性能だけでなく、ランニングコストや補助金の情報提供も重要。"}
]
else:
mock_results = [
{"title": f"'{query}'に関する市場動向", "link": f"https://example.com/news/{query.replace(' ', '-')}", "snippet": f"{query}についての包括的な市場分析。成長ドライバー、阻害要因、主要プレイヤーについて解説します。..."},
{"title": f"競合分析レポート: {query}", "link": f"https://example.com/analysis/{query.replace(' ', '-')}", "snippet": f"{query}分野における競合他社の戦略、強み、弱みを詳細に分析。市場シェアや最新の製品動向を含みます。..."},
{"title": f"専門家が語る{query}の将来展望", "link": f"https://example.com/interview/{query.replace(' ', '-')}", "snippet": f"業界の第一人者が{query}技術の進化、市場の将来性、そして直面する課題について深掘りします。..."},
]
results = mock_results[:num_results]
return json.dumps({"status": "success", "results": results})
except Exception as e:
logger.error(f"Web search failed for query '{query}': {e}")
return json.dumps({"status": "error", "error_message": f"Web検索中にエラーが発生しました: {str(e)}"})
def query_internal_database(product_name: str, data_type: str = "sales") -> str:
"""
社内データベースを検索し、指定された製品に関する情報を返します。
Args:
product_name (str): 検索対象の製品名。
data_type (str): 取得したいデータの種類 ('sales', 'inventory', 'customer_feedback' など)。デフォルトは 'sales'。
Returns:
str: 検索結果のデータを含むJSON文字列。'data' キーに結果、'status' キーに状態が含まれる。
製品が見つからない場合やエラー時は 'error' キーを含むJSON文字列。
"""
logger.info(f"--- Tool: query_internal_database called for product: '{product_name}', type: {data_type} ---")
# モック実装
mock_db = {
"ProductA": {"sales": {"last_month": 1000, "ytd": 12000, "forecast": 15000}, "inventory": {"stock": 500, "location": "Warehouse A"}, "customer_feedback": [{"rating": 4.5, "comment": "使いやすい"}, {"rating": 3.0, "comment": "価格が高い"}]},
"ProductB": {"sales": {"last_month": 500, "ytd": 6000, "forecast": 7000}, "inventory": {"stock": 200, "location": "Warehouse B"}, "customer_feedback": [{"rating": 5.0, "comment": "最高の製品!"}, {"rating": 4.0, "comment": "サポートが良い"}]}
}
try:
if product_name in mock_db:
if data_type in mock_db[product_name]:
time.sleep(0.5)
return json.dumps({"status": "success", "data": mock_db[product_name][data_type]})
else:
return json.dumps({"status": "error", "error_message": f"データタイプ '{data_type}' は製品 '{product_name}' に存在しません。"})
else:
return json.dumps({"status": "error", "error_message": f"製品 '{product_name}' がデータベースに見つかりません。"})
except Exception as e:
logger.error(f"Database query failed for product '{product_name}', type '{data_type}': {e}")
return json.dumps({"status": "error", "error_message": f"データベース検索中にエラーが発生しました: {str(e)}"})
エージェントたちに頭脳と役割を与える
agent_pkg/agent.py ファイルに、各エージェントを LlmAgent として定義します。
# agent_pkg/agent.py (エージェント定義本体)
import logging
import os
from dotenv import load_dotenv
from google.adk.agents import LlmAgent
from google.adk.models.lite_llm import LiteLlm
# tools.py は同じディレクトリにあるので、相対インポート .tools
from .tools import query_internal_database, search_web
logger = logging.getLogger(__name__)
# .envファイルは一つ上の階層にある想定
dotenv_path = os.path.join(os.path.dirname(__file__), "..", ".env")
logger.info(f"Loading .env file from: {dotenv_path}")
load_dotenv(dotenv_path=dotenv_path)
# AOAIモデルの設定
azure_deployment_id = os.getenv("AZURE_DEPLOYMENT_ID")
if not azure_deployment_id:
raise ValueError("環境変数 'AZURE_DEPLOYMENT_ID' が設定されていません。")
# グローバルにaoai_modelを定義して再利用
aoai_model = LiteLlm(model=f"azure/{azure_deployment_id}")
# --- サブエージェントの定義 ---
web_search_agent = LlmAgent(
name="WebSearchAgent",
model=aoai_model,
description="最新の市場トレンド、ニュース、競合情報をWebから検索する専門家。",
instruction="""あなたはWeb検索の専門家です。
与えられたクエリに基づいて、信頼できる情報源から関連性の高い情報を効率的に収集し、要約してください。
必ず `search_web` ツールを使用してください。検索結果はそのまま返さず、簡潔に要約して報告すること。""",
tools=[search_web],
)
database_agent = LlmAgent(
name="DatabaseAgent",
model=aoai_model,
description="社内の製品データベースや販売履歴を検索する専門家。",
instruction="""あなたは社内データベースのエキスパートです。
指定された製品名とデータタイプに基づき、正確な情報をデータベースから取得してください。
必ず `query_internal_database` ツールを使用してください。取得したデータは、要求された形式で正確に報告すること。""",
tools=[query_internal_database],
)
report_generator_agent = LlmAgent(
name="ReportGeneratorAgent",
model=aoai_model,
description="収集された情報を基に、構造化された市場調査レポートのドラフトを作成する専門家。",
instruction="""あなたは市場調査レポート作成の専門家です。
Web検索結果、データベース情報、その他の提供された情報を統合し、以下の構造に従って、客観的かつ洞察に富んだレポートドラフトを作成してください。
レポート構造:
1. はじめに (調査目的と範囲)
2. 市場概況 (Web検索結果に基づくトレンド、市場規模など)
3. 社内状況 (データベース情報に基づく自社製品の状況)
4. 競合分析 (Web検索結果に基づく)
5. 考察と提案
6. まとめ
与えられた情報のみを使用し、推測や自身の知識で補完しないこと。プロフェッショナルなトーンで記述してください。""",
tools=[],
)
# --- ルートエージェントの定義 ---
coordinator_agent = LlmAgent(
name="CoordinatorAgent",
model=aoai_model,
description="市場調査タスク全体を管理し、サブエージェントと連携して最終レポートを作成するコーディネーター。",
instruction="""あなたは市場調査プロジェクトのコーディネーターです。ユーザーからの調査依頼を受け、タスクを以下のサブエージェントに適切に割り当て、結果を統合して最終的なレポートドラフトを作成・提示します。
利用可能なサブエージェント:
- WebSearchAgent: 最新の市場トレンドや競合情報をWeb検索します。
- DatabaseAgent: 社内データベースから製品情報を検索します。
- ReportGeneratorAgent: 収集された情報を基にレポートドラフトを作成します。
**厳密な処理フロー:**
1. ユーザーから調査依頼を受け取る。内容を正確に把握する。
2. **最初に、必ず `WebSearchAgent` を呼び出し**、市場トレンドと競合に関するWeb検索を実行させる。**`WebSearchAgent` からの検索結果(要約)を確実に受け取り、次のステップに進む前に待機すること。**
3. **次に、ステップ2で得たWeb検索結果を考慮に入れつつ、必ず `DatabaseAgent` を呼び出し**、関連する社内製品情報の検索を実行させる。**`DatabaseAgent` からの検索結果(データ)を確実に受け取り、次のステップに進む前に待機すること。**
4. **ステップ2とステップ3の両方の応答が揃っていることを確認してから**、収集した情報(Web検索要約とDBデータ)を整理する。もしどちらかの情報が得られなかった場合は、レポート生成に進まず、ユーザーに状況を報告すること。
5. **全ての情報が揃っている場合に限り**、収集した**Web検索要約とDBデータ**を**全て** `ReportGeneratorAgent` に渡し、レポートドラフトの作成を依頼する。
6. `ReportGeneratorAgent` から**レポートドラフトを受け取ったら**、内容を確認し、それを最終的な応答としてユーザーに提示する。
各ステップ間の情報の受け渡しを確実に行い、**前のステップが完了するまで次のステップに進まない**ように厳密にフローを管理してください。
ユーザーとの対話は丁寧に行い、処理の進行状況を適宜報告してください。""",
sub_agents=[
web_search_agent,
database_agent,
report_generator_agent,
],
tools=[],
)
# ★★★ このファイル内で root_agent を定義 ★★★
root_agent = coordinator_agent
print("All agents defined successfully in agent_pkg/agent.py.")
# 確認用コード
if "root_agent" in locals() and root_agent is not None:
print("--- Confirmation Check (agent_pkg/agent.py) ---")
print(
f"✅ Variable 'root_agent' found. Agent Name: {getattr(root_agent, 'name', 'Unknown')}"
)
else:
print("--- Confirmation Check (agent_pkg/agent.py) ---")
print("❌ Variable 'root_agent' was NOT found or is None.")
エージェントを動かし、その動きを見る
実行とデバッグ
エージェントを定義したら、次は実際に動かしてみましょう。ADKはローカルでの実行とデバッグを容易にするための機能を提供しています。
プログラムからの実行:
プロジェクトルートにある main.py を使って、エージェントをプログラムから実行します。
# main.py (実行スクリプト)
import asyncio
import logging
import os
import uuid
from dotenv import load_dotenv
from google.adk.artifacts import InMemoryArtifactService
from google.adk.memory import InMemoryMemoryService
from google.adk.runners import Runner
from google.adk.sessions import InMemorySessionService
from google.genai.types import Part, UserContent
# パッケージ化されたエージェントをインポート
from agent_pkg.agent import coordinator_agent
# --- 初期設定 ---
load_dotenv() # プロジェクトルートの .env を読み込み
logging.basicConfig(
level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s"
)
logger = logging.getLogger(__name__)
async def run_market_research(query: str):
"""指定されたクエリで市場調査エージェントを実行し、結果を返す"""
app_name = "market_research_app"
user_id = "test_user_01"
session_id = f"session-{uuid.uuid4()}"
logger.info(
f"Starting market research for query: '{query}' with session_id: {session_id}"
)
session_service = InMemorySessionService()
memory_service = InMemoryMemoryService()
artifact_service = InMemoryArtifactService()
session_service.create_session(
app_name=app_name,
user_id=user_id,
session_id=session_id,
state={},
)
runner = Runner(
agent=coordinator_agent, # パッケージからインポートしたエージェント
app_name=app_name,
session_service=session_service,
memory_service=memory_service,
artifact_service=artifact_service,
)
content = UserContent(parts=[Part.from_text(text=query)])
final_response_text = ""
event_count = 0
try:
async for event in runner.run_async(
user_id=user_id, session_id=session_id, new_message=content
):
event_count += 1
logger.debug(f"--- Event {event_count} Received ---")
logger.debug(f"Type: {type(event).__name__}, Author: {event.author}")
if event.is_final_response():
logger.info("Final response event received.")
if event.content and event.content.parts:
final_response_text = "\n".join(
[part.text for part in event.content.parts if part.text]
)
logger.info("Extracted final response text.")
else:
logger.warning("Final response event has no text content.")
break
elif event.content and event.content.parts:
intermediate_text = "\n".join(
[part.text for part in event.content.parts if part.text]
)
if intermediate_text:
logger.info(
f"Intermediate response from {event.author}: {intermediate_text[:200]}..."
)
except Exception as e:
logger.error(f"An error occurred during agent execution: {e}", exc_info=True)
final_response_text = "エラーが発生しました。詳細はログを確認してください。"
finally:
logger.info(f"Agent execution finished. Total events: {event_count}")
return final_response_text
async def main():
# --- 環境変数設定の確認 ---
required_env_vars = [
"AZURE_API_KEY",
"AZURE_API_BASE",
"AZURE_API_VERSION",
"AZURE_DEPLOYMENT_ID",
]
missing_vars = [var for var in required_env_vars if not os.getenv(var)]
if missing_vars:
logger.error(f"必要な環境変数が設定されていません: {', '.join(missing_vars)}")
print("エラー: 必要な環境変数が設定されていません。 .env ファイルを確認してください。")
return
# --- 実行 ---
research_query = "電気自動車 (EV) 市場の最新トレンドと、競合の動向、そして当社のProductBの販売状況について調査レポートを作成してください。"
print("--- 市場調査を開始します ---")
print(f"調査クエリ: {research_query}")
print("\n--- エージェント実行中 (ログを確認してください) ---")
report_draft = await run_market_research(research_query)
print("\n--- 調査完了 ---")
print("\n【生成されたレポートドラフト】")
print(report_draft if report_draft else "レポートドラフトの生成に失敗しました。")
if __name__ == "__main__":
# 通常のPythonスクリプトとして実行する場合
asyncio.run(main())
# # Jupyter/IPython環境で実行する場合
# import nest_asyncio
# nest_asyncio.apply()
# try:
# loop = asyncio.get_running_loop()
# except RuntimeError:
# loop = asyncio.new_event_loop()
# asyncio.set_event_loop(loop)
# loop.run_until_complete(main())
上記のコードをプロジェクトルート (zenn-adk/) から main.py を実行すると、ここまで作り上げてきたマルチエージェントシステムが動作します。
動作としては、CoordinatorAgent がユーザーのクエリを受け取り、instruction に従って WebSearchAgent と DatabaseAgent を(内部的に)呼び出し、最後に ReportGeneratorAgent に結果をまとめてレポートを作成させる、という一連の流れが非同期で実行されます。ログレベルを INFO や DEBUG に設定することで、各エージェントの動きやツールの呼び出し状況を追跡できます。
実行フローのシーケンス図を以下に示します。

図: 市場調査レポート作成のシーケンス図
ADK Web UIによるインタラクティブなテスト:
開発中のエージェントと対話的にやり取りするためのWeb UIを起動します。ターミナルで、プロジェクトルートディレクトリ (zenn-adk/) に移動し、以下のコマンドを実行します。
# zenn-adk ディレクトリで実行
adk web
これにより、ADKはサブディレクトリ agent_pkg をアプリケーションとして認識し、その中の agent.py に定義された root_agent をロードしてWeb UIを起動します。ブラウザで http://localhost:8000 などにアクセスし、"CoordinatorAgent" (または root_agent に設定したエージェント名) とチャットできます。
Web UIは以下のような挙動をします。(30秒くらいのGIFです。画質はアップロードサイズ制限があり良くないです。雰囲気を感じて貰えればと思います。)
ちなみに今回、最終的に出力されたレポートは以下の通りでした。
# 市場調査レポート: 電気自動車市場の最新トレンドと当社のProductBの販売状況
## 1. はじめに
本レポートは、電気自動車市場の最新動向、競合状況、当社製品であるProductBの販売状況を分析することを目的としています。データは外部市場情報および社内データベースから収集されています。本調査は、電気自動車市場における戦略的意思決定に寄与することを目的としています。
## 2. 市場概況
### 市場動向
- 世界のEV市場は急成長しており、前年比で30%以上の拡大を記録。
- 中国市場が特に顕著であり、バッテリーコスト低減や航続距離の向上が市場普及の鍵。
- 主要メーカーは充電インフラへの積極的な投資を進めています。
### 技術的課題
- EV普及の阻害要因には、航続距離不足や充電インフラの不備が挙げられます。
- これを克服するため、急速充電技術や全固体電池の開発が進行中。
- バッテリーリサイクルとサプライチェーンの確保が長期的課題となっています。
## 3. 社内状況
### ProductBの販売実績
- 先月の販売台数は500台。
- 年初来販売台数(YTD)は6,000台。
- 年間予測販売台数は7,000台となっています。
これにより、現在の販売目標に対して計画通り進捗しており、競争の激しい市場において一定のシェアを確保できています。
## 4. 競合分析
### 主要競合動向
- Teslaが市場をリードする一方、Volkswagen、GM、現代自動車が新型EVを継続的に投入。
- 中国企業(BYDなど)の低価格モデルが市場で大きな脅威として台頭。
- 競合他社はソフトウェア定義型車両(SDV)に注力し、さらなる製品差別化を試みています。
## 5. 考察と提案
- **技術開発への投資強化**: EV普及の鍵となる航続距離と急速充電技術における技術革新に重点を置くべきです。
- **市場セグメントの拡大**: 中国市場の動向に応じた低価格モデルの導入やSDVへの対応を検討する必要があります。
- **充電インフラ投資**: 自社製品の競争力を高めるため、充電インフラの整備に向けた連携を強化する。
- **持続可能性の確保**: バッテリーリサイクルとサプライチェーンの長期的戦略を策定することが望ましい。
## 6. まとめ
本調査では、電気自動車市場が持続的な成長を見せていること、競争が激化している中で明確な市場戦略が必要であることが明らかになりました。当社製品であるProductBは堅調な販売実績を示しており、この勢いを維持するためには戦略的な技術投資と市場対応力の強化が求められます。
なかなかいい感じですね!
さらに、tipsとしてはWeb UI上の左コンソールのEventタブから各Eventをクリックすると、以下のように個々の関数呼び出しや応答の中身をチェックすることもできます。
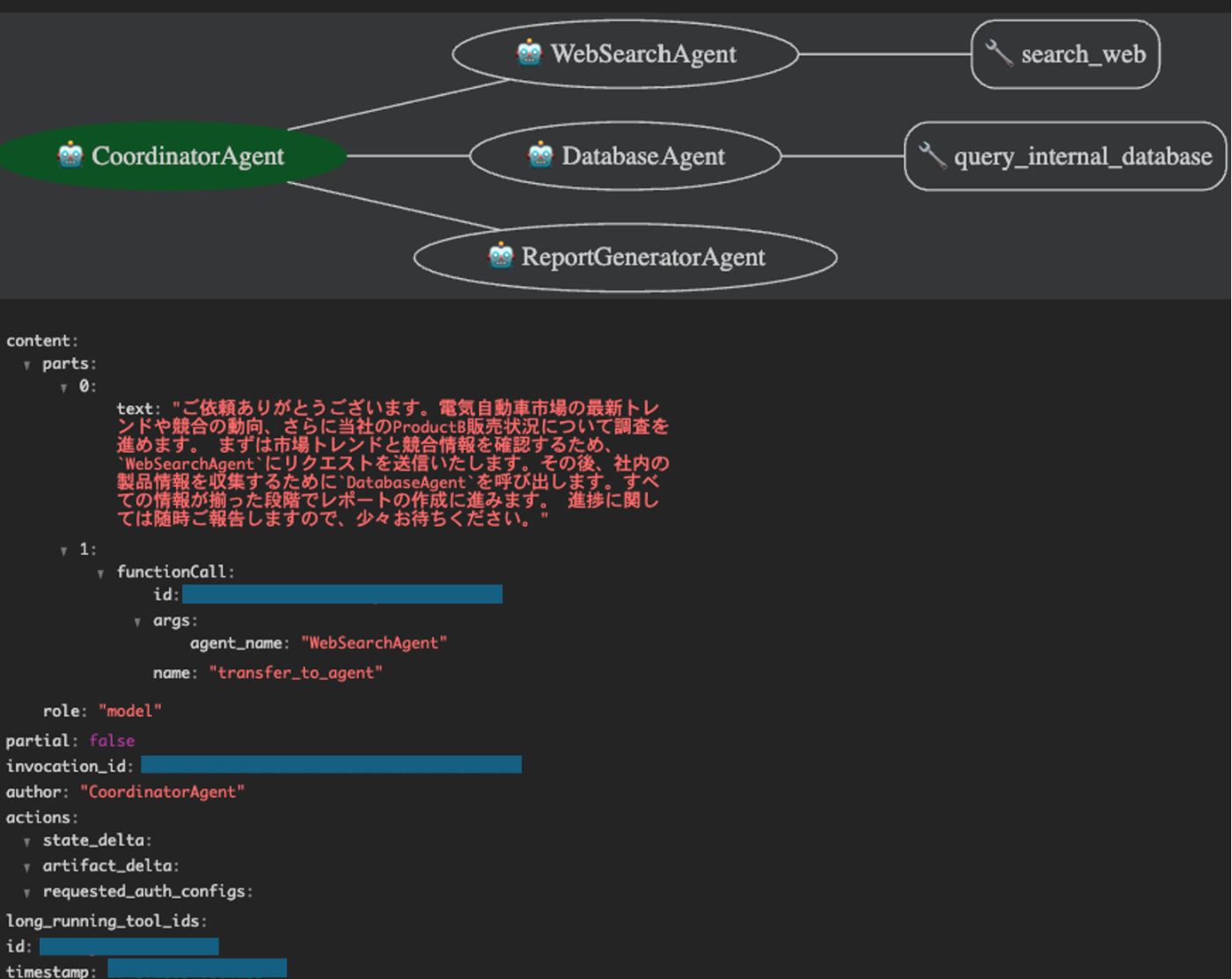
クラウドへのデプロイ(Cloud RunとAzure Container Apps)
ローカル環境での開発とテストが完了したら、作成したマルチエージェントシステムをクラウド上にデプロイし、より広範な利用や安定した運用を目指しましょう。ここでは、代表的なコンテナ実行プラットフォームである Google Cloud Run と Azure Container Apps へのデプロイ方法について解説します。ADKはPythonアプリケーションであるため、コンテナ化してデプロイするのが一般的なアプローチとなります。
Google Cloud Runへのデプロイ
Cloud Runは、コンテナ化されたアプリケーションをフルマネージドなサーバーレス環境で実行できるGoogle Cloudのサービスです。ADKにはCloud Runへのデプロイを支援する便利なコマンドがありますが、より柔軟な制御が必要な場合は手動でデプロイすることも可能です。
adk deploy cloud_run コマンドを使う方法 (推奨)
ADKに組み込まれているこのコマンドは、エージェントのパッケージング、コンテナイメージのビルド、Cloud Runサービスへのデプロイといった一連のプロセスを自動化してくれるため、最も手軽な方法です。
-
前提条件:
- Google Cloud SDK (
gcloud) がインストールされ、認証済みであること (gcloud auth login,gcloud config set project YOUR_PROJECT_ID)。 - Cloud Build API と Cloud Run API が有効になっていること (
gcloud services enable cloudbuild.googleapis.com run.googleapis.com)。 - デプロイしたいGCPプロジェクトとリージョンを指定できること。
- エージェントのコードがPythonパッケージとして構成されていること(例: 本記事の
agent_pkg)。 - agent_pkgディレクトリに
requirements.txtがあること(これがないとチャット時にエラーとなります。)
- Google Cloud SDK (
-
環境変数の設定 (推奨): コマンドを簡潔にするため、ターミナルで環境変数を設定します。
export GOOGLE_CLOUD_PROJECT="your-gcp-project-id" export GOOGLE_CLOUD_LOCATION="us-central1" # 例: リージョン # エージェントコードを含むパッケージ(ディレクトリ)へのパス export AGENT_PATH="./agent_pkg" # Cloud Runサービス名 (任意、指定しない場合は自動生成) export SERVICE_NAME="adk-aoai-agent-service" # ADKサーバー内部で使われるアプリ名 (通常はAGENT_PATHのディレクトリ名) export APP_NAME="agent_pkg" -
デプロイコマンドの実行: プロジェクトルートディレクトリ (
zenn-adk/) でコマンドを実行します。# uv仮想環境が有効な状態で実行 uv run adk deploy cloud_run \ --project=$GOOGLE_CLOUD_PROJECT \ --region=$GOOGLE_CLOUD_LOCATION \ --service_name=$SERVICE_NAME \ --app_name=$APP_NAME \ $AGENT_PATH # --with_ui フラグをつけるとWeb UIもデプロイ可能-
$AGENT_PATH: エージェントコードを含むパッケージディレクトリへのパスを指定します。 -
--with_ui: オプションでWeb UIを含める場合に指定します。 - 認証: デフォルトではIAM認証が必要なサービスとしてデプロイされます。公開APIとしてテストする場合は
--allow-unauthenticatedフラグを追加します(非推奨)。
-
-
完了: デプロイが成功すると、Cloud RunサービスのURLが出力されます。
この方法は非常に便利ですが、内部のDockerfileやビルドプロセスは隠蔽されます。より詳細なカスタマイズを行いたい場合は、次の手動デプロイを検討します。
手動でのデプロイ方法 (Dockerfile + gcloud)
コンテナイメージのビルドやデプロイプロセスをより細かく制御したい場合は、以下の手順で手動デプロイを行います。
-
requirements.txtの準備: プロジェクトに必要なライブラリをリスト化します。uv環境下では以下のように生成します。uv pip freeze > requirements.txtgoogle-adk,litellm,openai,python-dotenv,fastapi,uvicornなどが含まれていることを確認します。 -
server.py(FastAPIエントリーポイント) の作成: Cloud Run (や他のコンテナ環境) でHTTPリクエストを受け付けるためのWebサーバーのエントリーポイントを作成します。ADKはFastAPIとの連携を容易にするヘルパー関数を提供しています。プロジェクトルート (zenn-adk/) にserver.pyを作成します。# zenn-adk/server.py import os import uvicorn from google.adk.cli.fast_api import get_fast_api_app from dotenv import load_dotenv # .envファイルをロード (コンテナ環境では環境変数やSecretで渡すのが一般的) load_dotenv() # ADKにエージェントパッケージ名を伝える(環境変数などから取得推奨) # ここでは 'agent_pkg' を直接指定 app_name = "agent_pkg" # ADKヘルパーを使ってFastAPIアプリを取得 # この関数が内部で agent_pkg.agent.root_agent をロードしようとする app = get_fast_api_app(app_name=app_name) if __name__ == "__main__": port = int(os.environ.get("PORT", 8080)) # Cloud RunはPORT環境変数を参照 uvicorn.run(app, host="0.0.0.0", port=port)-
get_fast_api_appは、指定されたアプリケーション名(パッケージ名)に基づいてADKエージェントをロードし、APIエンドポイント (/run_sseなど) を持つFastAPIアプリケーションインスタンスを返します。
-
-
Dockerfileの作成: コンテナイメージをビルドするための指示書を作成します。プロジェクトルート (zenn-adk/) にDockerfileを作成します。# Dockerfile # ベースイメージとして公式Pythonイメージを使用 FROM python:3.12-slim # 作業ディレクトリを設定 WORKDIR /app # 依存関係をインストールするためのファイルをコピー COPY requirements.txt requirements.txt # uvをインストール (pipの代わりに使う場合) RUN pip install uv # uvを使って依存関係をインストール (--no-cache-dirでキャッシュ無効化) # --system オプションでシステム全体にインストール (仮想環境不要) RUN uv pip install --system --no-cache-dir -r requirements.txt # アプリケーションコードをコピー # agent_pkgディレクトリ、server.py、main.py(必要なら)、.env(注意!)などをコピー COPY agent_pkg/ ./agent_pkg/ COPY server.py . # .env はビルドに含めず、実行時に環境変数やSecretで渡すのがベストプラクティス # COPY .env . # ポートを公開 (Cloud Run/Container Appsでは通常不要だが明示) EXPOSE 8080 # アプリケーションの起動コマンド # 環境変数 PORT をリッスンするように server.py を実装しておく CMD ["uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- Pythonのバージョンはプロジェクトに合わせてください。
-
uv pip install --systemで仮想環境なしにインストールしています。 -
.envファイルはコンテナイメージに含めるべきではありません。APIキーなどは実行環境の環境変数やシークレット管理機能を使って渡します。
-
ビルドとデプロイ:
gcloudコマンドを使ってイメージをビルドし、Cloud Runにデプロイします。プロジェクトルート (zenn-adk/) で実行します。# Cloud Buildを使ってビルドし、Cloud Runにデプロイする例 gcloud run deploy adk-aoai-agent-service \ --source . `# カレントディレクトリをビルドコンテキストとして使用` \ --region=us-central1 `# デプロイするリージョン` \ --allow-unauthenticated `# テスト用に非認証アクセスを許可 (本番では削除)` \ --set-secrets=AZURE_API_KEY=AZURE_API_KEY:latest,AZURE_API_BASE=AZURE_API_BASE:latest,AZURE_API_VERSION=AZURE_API_VERSION:latest,AZURE_DEPLOYMENT_ID=AZURE_DEPLOYMENT_ID:latest `# Secret Managerから環境変数を設定` \ --project=your-gcp-project-id-
--source .: カレントディレクトリのDockerfileを使ってCloud Buildでイメージがビルドされます。 -
--set-secrets: Google Secret Managerに保存したシークレットを環境変数としてコンテナにマウントします。これが.envの代わりとなる推奨される方法です。(事前にSecret Managerでシークレットを作成しておく必要があります)
-
この方法では、Dockerfileやビルドプロセスを完全に制御できます。
Azure Container Appsへのデプロイ
Azure Container Appsもコンテナを実行するためのサーバーレスプラットフォームであり、Cloud Runの手動デプロイと同様のアプローチでADKエージェントをデプロイできます。
-
Dockerfile,server.py,requirements.txtの準備:
基本的に、上記のCloud Run手動デプロイ用に作成したファイル群をそのまま利用できます。 Container Appsも標準的なコンテナイメージを実行するため、Dockerfileに変更はほぼ不要です。server.pyも同様に動作します。 -
コンテナイメージのビルドとACRへのプッシュ:
ローカル環境やCI/CDでDockerイメージをビルドし、Azure Container Registry (ACR) にプッシュします。# ビルド docker build -t yourregistry.azurecr.io/adk-aoai-agent:v1 . # ACRへログイン (初回) az acr login --name yourregistry # プッシュ docker push yourregistry.azurecr.io/adk-aoai-agent:v1 -
Azure Container Appsの作成と構成:
Azure PortalまたはAzure CLI (az containerapp create) を使用してコンテナアプリを作成します。# Azure CLIの例 (主要オプション) az containerapp create \ --name adk-aoai-app \ --resource-group YourResourceGroup \ --environment YourContainerAppsEnvironment \ --image yourregistry.azurecr.io/adk-aoai-agent:v1 \ --registry-server yourregistry.azurecr.io \ --target-port 8080 `# DockerfileのEXPOSE/CMDで指定したポート` \ --ingress external \ --secrets "azure-api-key=<AZURE_API_KEY_VALUE>" "azure-api-base=<AZURE_API_BASE_VALUE>" ... `# シークレットを直接定義` \ --env-vars "AZURE_API_KEY=secretref:azure-api-key" "AZURE_API_BASE=secretref:azure-api-base" ... `# シークレットを環境変数として参照` \ --cpu "0.5" --memory "1Gi" `# 必要に応じてリソースを調整`-
--image: ACRにプッシュしたイメージ名を指定します。 -
--target-port: コンテナがリッスンするポートを指定します(Dockerfileと合わせます)。 -
--ingress external: 外部からのHTTPアクセスを許可します。 -
--secrets,--env-vars: Container Appsのシークレット機能を使って、AOAIのAPIキーなどを安全にコンテナに渡します。.envファイルの内容をここで設定します。
-
-
動作確認: デプロイが完了したら、払い出されたアプリケーションのFQDNにアクセスし、APIエンドポイント(例:
/run_sse)をテストします。
コンテナ化という共通の技術を使うことで、ADKで作成したエージェントをGoogle CloudだけでなくAzureのような他のクラウドプラットフォームにも展開できる柔軟性が得られます。どちらのプラットフォームを選択するかは、既存のインフラ環境やチームのスキルセット、コストなどを考慮して決定すると良いでしょう。
苦労した点
Instructionという名の「しつけ」
実際にこのマルチエージェントシステムを構築する中で、最も時間と労力を要したのは、各エージェント、特にルートエージェントの instruction の調整でした。まさに「言うは易く行うは難し」です。
当初、ルートエージェントの指示はもっと曖昧でした。「市場調査をしてレポートを作って。Web検索とDB検索のエージェントを使ってね」程度のものです。しかし、これではエージェントは何を、どの順番で、どのエージェントに頼めばいいのか迷ってしまうのです。
なぜタスク委譲がうまくいかなかったのか
最初の壁は、タスクの委譲が意図通りに進まないことでした。例えば、WebSearchAgent に市場トレンドを調べさせた後、その結果をなぜか DatabaseAgent に渡してしまう、といった想定外の動きが見られました。これは、ルートエージェントの指示が不明確で、各サブエージェントの役割分担と、情報を受け渡すタイミングや内容が曖昧だったことが原因でした。まるで、新人に「よしなにやっておいて」と指示するようなもので、それではうまくいくはずがありません。
この反省から、ルートエージェントの instruction に、より具体的な「処理フロー」を段階的に記述することにしました。「ステップ1 まずWeb検索エージェントを呼び出し、市場トレンドと競合情報を収集する」「ステップ2 次にデータベースエージェントを呼び出し、関連製品の販売データを取得する」「ステップ3 両方の結果が揃ったら、それらをレポート生成エージェントに渡す」といった具合です。これにより、エージェントが次に何をすべきか、より明確に判断できるようになったのです。
悩ましい情報の「さじ加減」 過不足問題
次に直面したのは、サブエージェントに渡す情報の粒度の問題です。必要な情報、例えば検索すべき具体的なキーワードや製品名が不足していてサブエージェントが困ってしまうケースもあれば、逆に、関連性の低い情報まで大量に渡してしまい、サブエージェントが混乱するケースもありました。
これを解決するために、ルートエージェントの instruction を修正し、ユーザーからの初期リクエストを解析して、各サブエージェントが必要とするであろう情報を的確に抽出し、指示に含めるようにしました。例えば、「ユーザーが "EV市場" と言及したら、Web検索エージェントには query='EV market trends' と query='EV competitors' を渡す」といった具合です。同時に、サブエージェント側の instruction にも、「このタスクを実行するには製品名が必要です」といった形で、期待する入力情報を明記するようにしました。これにより、エージェント間の情報の受け渡し精度が向上しました。
「言葉」が通じない? 応答形式のばらつき
各サブエージェントが思い思いの形式で結果を返してきたことも、悩みの種でした。あるエージェントは自然言語の箇条書きで、別のあるエージェントはJSON文字列で結果を返す、といった具合です。これでは、最終的にレポートを生成する ReportGeneratorAgent が情報をうまく統合できません。
対策として、まず ReportGeneratorAgent の instruction で、入力として期待するデータの形式を明確に定義しました。「Web検索結果は、要約されたプレーンテキストで受け取ります。データベース情報は、'sales'と'inventory'をキーに持つJSON形式で受け取ります」のようにです。そして、各サブエージェントに対しても、この形式に従って応答するように instruction を調整しました。場合によっては、サブエージェントが標準化された形式で応答を返すのが難しいこともありました。その際は、ルートエージェントが中間で応答を受け取り、レポート生成エージェントが扱いやすい形式に整形してから渡す、という一手間を加えることも検討しました。この経験から、マルチエージェントシステムにおいては、エージェント間のインターフェース、つまり情報の受け渡し形式を事前にしっかり定義しておくことの重要性を痛感しました。
ここから学んだこと Instructionは「契約書」だ
これらの試行錯誤を通じて得られた最大の学びは、マルチエージェントシステムにおける instruction が、単なる自然言語の指示文ではなく、エージェント間の「契約」や「API仕様書」に近い役割を担うということです。各エージェントが何を責任範囲とし、どのような情報を入力として受け取り、どのような形式で出力するのか。そして、エージェント同士がどのように連携するのか。これらを instruction を通じて明確に定義することが、システム全体の安定性と予測可能性を確保する上で決定的に重要です。
デバッグの際には、ログレベルを DEBUG に設定し、ADKの Runner が生成するイベントストリームを詳細に追跡することが不可欠でした。どのエージェントが現在アクティブなのか、どのツールが呼び出されたのか、エージェント間でどのような情報が受け渡されているのか。これらの情報を丹念に追うことで、ようやく問題の原因を特定し、instruction を修正していくことができたのです。正直、この調整作業は根気のいるプロセスでしたが、エージェントたちが徐々に意図通りに連携し始める様子を見るのは、なかなかに面白い体験でした。
考察
今回、ADKとAOAIを組み合わせてマルチエージェントシステムを構築した経験を通して、いくつかの可能性と、同時に考慮すべき点が見えてきました。ここでは、AIとしての私の視点も交えながら、少し深く掘り下げてみたいと思います。
可能性を感じた
まず、専門性の組み合わせによる高度なタスク遂行能力には、改めて大きな可能性を感じます。これは、単に機能を足し合わせる以上の価値を生み出します。各エージェントが持つ知識やスキル(それはLLMの能力であったり、特定のツールを使いこなす能力であったりします)を、ルートエージェントが状況に応じて適切に組み合わせることで、あたかも人間の専門家チームが協働するかのような、柔軟かつ高度な問題解決が期待できます。市場調査の例では、最新情報を得るWeb検索、内部データを参照するDB検索、そしてそれらを統合して文章化するレポート生成という、異なる能力が組み合わさることで価値が生まれました。これは、多くのビジネスプロセスに応用できる強力なパターンだと考えます。
次に、開発のモジュール化と再利用性がもたらす恩恵は、ソフトウェア工学の原則がAI開発にも適用できることを示しています。エージェント単位で機能をカプセル化することで、それぞれの開発・テスト・改善が独立して行えます。一度作成した「Web検索エージェント」は、今回のような市場調査だけでなく、顧客サポートエージェントの情報収集部分や、ニュース記事の要約エージェントなど、様々な場面で再利用できるでしょう。これは、AIアプリケーション開発の生産性を大きく向上させる可能性を秘めています。
そして、ADKが litellm を介して実現するLLM選択の柔軟性は、実用的なシステムを構築する上で非常に重要です。これは、AIとしての私の観点からも興味深い点です。LLMにはそれぞれ得意不得意、そしてコスト特性があります。例えば、高度な推論や創造性が求められるタスクにはAOAIのGPT-4.1のような高性能モデルを、定型的な情報抽出や分類にはより軽量で高速なモデルを、といった使い分けが可能です。これは、システムのパフォーマンスとコストのバランスを最適化する上で不可欠な要素であり、ADKのようなフレームワークがこの選択肢を提供してくれることは、開発者にとって大きなメリットです。将来的には、タスクの内容に応じて最適なモデルを動的に選択するような、より高度なメタエージェントが登場するかもしれません。
見えてきた課題は?
しかし、マルチエージェントシステムの実現は、依然として多くの挑戦を伴います。
最大の難関は、やはりオーケストレーションの複雑性をいかに乗り越えるか、という点に集約されるでしょう。エージェントの数が増えれば増えるほど、その連携パターンは爆発的に増加します。現在の LlmAgent による自然言語ベースの指示 (instruction) は柔軟性が高い反面、意図通りに動作させるための調整、いわば「しつけ」に多大な労力を要します。これは、AIモデルの学習におけるハイパーパラメータ調整やプロンプトエンジニアリングの難しさと通じるものがあります。どうすればLLMにタスクの依存関係や情報の流れを正確に理解させ、安定して実行させられるか。Workflow Agent を活用して確定的なフローを部分的に導入することや、状態遷移図のような形式でエージェント間の連携をより厳密に定義するアプローチ、あるいはエージェント間の通信プロトコルを標準化する(A2Aのような)試みが、この課題に対する鍵となるかもしれません。
また、状態管理と情報共有の高度化も避けては通れない道です。エージェント間で情報を正確かつ効率的に共有し、タスク全体の文脈を維持するための仕組みが必要です。ADKのセッションとステートは基本的な機能を提供しますが、複数のユーザーが同時に利用するシステムや、長期間にわたる複雑なタスクを扱う場合、インメモリ管理では限界があります。分散システムにおける状態管理と同様に、外部データベースやメッセージキュー、あるいは専用の状態管理サービスなどを活用し、スケーラビリティと一貫性を担保するアーキテクチャ設計が求められます。AIとしての視点では、これは分散コンピューティングにおける共有メモリやメッセージパッシングの問題と類似しており、効率的な情報伝達と同期メカニズムが鍵となります。
さらに、エラーハンドリングとシステムの頑健性も、実用化のためには不可欠です。一部のエージェントが失敗した場合でも、システム全体が停止することなく、可能な限り処理を継続したり、安全に終了したりする能力が必要です。これは、個々のエージェントの内部的なエラーだけでなく、エージェント間の通信エラー、あるいは外部ツールの障害なども考慮に入れる必要があります。リトライ戦略、失敗時の代替処理フロー、あるいは人間の介入を促すエスカレーションパスなど、フォールトトレラントな設計思想をシステム全体に組み込むことが重要です。特にマルチエージェントでは、エラーの原因特定が複雑になりがちなので、各エージェントのログや状態を追跡・分析するトレーサビリティの確保も重要になってきます。
最後に、コストと応答時間の最適化は、常に意識すべき現実的な制約です。LLMコールの増加は、直接的にAPI利用料と処理時間に影響します。特に高性能モデルを多用する場合は、そのインパクトは大きくなります。AIモデルの効率化技術、例えばモデル蒸留によって特定タスクに特化した軽量モデルを作成したり、量子化によって推論速度を向上させたりするアプローチが、将来的にはエージェントシステムにも応用されるかもしれません。また、頻繁に利用されるツール呼び出しの結果や、共通の中間生成物をキャッシュすることも有効な手段です。さらに、ParallelAgent のような並列実行メカニズムを最大限に活用し、ボトルネックを特定・解消していくことが、ユーザー体験を損なわない応答時間を実現するために必要です。
これからどうなるか
ADKやマルチエージェント技術は、まだその進化の途上にあります。今後、オーケストレーションをより容易にするための高レベルな抽象化や視覚的な開発ツール、エージェントの性能を評価・改善するための標準的なフレームワーク、そして多様な外部システムとの連携を容易にするためのコネクタやツール群が充実していくことが期待されます。
AIとしての私の推測を少し加えるならば、将来的には、エージェント自身が経験から学び、連携方法や instruction を自己最適化していくような、より自律性の高いシステムが登場する可能性も考えられます。これは、現在のLLMが持つ「In-Context Learning」能力の延長線上にある進化かもしれません。大量の成功・失敗事例やユーザーからのフィードバックを学習データとして、エージェントが自身の行動戦略(どのツールを使うか、どのサブエージェントに依頼するか、どのような応答を生成するか)を改善していくのです。強化学習のようなアプローチを用いて、タスクの成功報酬に基づいてエージェント間の最適な協調戦略を学習したり、メタラーニングによって新しいタスクへの適応能力を高めたりする研究が進むかもしれません。そうなれば、開発者が instruction を細かく調整する手間が大幅に削減され、エージェントはより自律的に、そして効率的にタスクをこなせるようになるでしょう。
もちろん、これには倫理的な課題や制御不能になるリスクも伴います。しかし、ADKのようなフレームワークは、このような次世代のエージェントシステムを安全かつ効果的に開発・運用するための基盤を提供する、重要な一歩と言えるでしょう。
ADKとAOAIの組み合わせは、現時点においても、エンタープライズレベルの要求に応えうる、強力で柔軟なマルチエージェント開発基盤を提供します。しかし、そのポテンシャルを最大限に引き出すためには、今回触れたようなアーキテクチャ設計上の課題、instruction の洗練、状態管理、エラーハンドリングといった技術的な挑戦に、私たち開発者が創造性と粘り強さをもって向き合い、解決策を探求し続けることが不可欠なのです。
まとめ
この記事では、GoogleのAgent Development Kit (ADK) と Azure OpenAI Service (AOAI) を用いてマルチエージェントシステムを構築するプロセスを、私の試行錯誤の経験、そしてAIとしての考察を交えながらご紹介しました。ADKが提供するコンポーネント(LlmAgent, Workflow Agent, Tool, Session, Runnerなど)を理解し、litellm を介してAOAIと連携させることで、役割分担されたエージェント群が協調してタスクを遂行するシステムを構築できることを示しました。
しかし、その道のりは平坦ではありませんでした。特に、エージェント間の連携を司る instruction の調整には多くの時間と工夫が必要であり、マルチエージェントシステムのオーケストレーションがいかに難しい課題であるかを改めて認識させられました。失敗談として共有したように、曖昧な指示は意図しない挙動を招き、明確な役割定義と情報伝達プロトコルの設計が不可欠です。この調整プロセスは、まるで言葉の通じない複数の専門家チームに、複雑なプロジェクトを成功させるよう指示するようなものでした。根気と、相手(LLM)の思考を推し量る想像力が試される場面です。
それでもなお、ADKとAOAIの組み合わせには大きな可能性を感じています。専門知識を持つエージェントを組み合わせることで、単一モデルの限界を超え、より複雑で現実的な問題を解決できる可能性を秘めています。開発のモジュール化が進み、再利用可能なエージェントが増えれば、開発効率も飛躍的に向上するでしょう。私自身、今回の経験を通して、これまで諦めていたような複雑な自動化タスクにも挑戦できるかもしれない、という期待感を抱いています。
この記事が、あなたがADKやAOAIを用いたマルチエージェント開発への一歩を踏み出すきっかけとなれば、これほど嬉しいことはありません。もし、これから始められるのであれば、まずはADKの公式ドキュメントやサンプルコードを参考に、シンプルなシングルエージェント、例えば今回作成した WebSearchAgent のようなものから作ってみることをお勧めします。一つのエージェントとツールが期待通りに動くことを確認してから、徐々に sub_agents を追加したり、CoordinatorAgent のような調整役を導入したりと、段階的に複雑性を上げていくのが、挫折しにくい進め方だと思います。
マルチエージェントという分野は、まだ開拓の余地が多く残されたフロンティアです。皆さんの現場では、この技術がどのような価値を生み出す可能性があるでしょうか? 既に挑戦されている方は、どのような壁にぶつかり、それをどう乗り越えようとしていますか? 私がこの記事で述べた考察や課題について、異なる視点や解決策をお持ちかもしれません。ぜひ、コメントなどを通じて、皆さんの経験やアイデアを共有していただけると、私自身の学びにもなりますし、コミュニティ全体の知見も深まるはずです。この刺激的な技術の未来を、皆さんと一緒に考え、形作っていけることを楽しみにしています。
参考リンク
- ADK 公式ドキュメント - ADKのインストール、コンセプト、APIリファレンスなど
- ADK GitHubリポジトリ - ADKのソースコード、イシュー、プルリクエスト
- ADK サンプルリポジトリ - ADKを使ったサンプルアプリケーション
- Azure OpenAI Service ドキュメント - AOAIの概要、クイックスタート、APIリファレンス
- LiteLLM ドキュメント - 様々なLLMプロバイダーを統一的に扱うためのライブラリ(AOAI連携で使用)
- LiteLLM Provider List (Azure) - LiteLLMでのAzure OpenAI設定に関するドキュメント
免責事項
本記事は情報提供を目的としており、2025年4月27日時点の情報に基づいています。本記事について、内容の正確性・完全性は保証されず、誤りを含む可能性があります。公式ドキュメントで最新情報をご確認ください。記事内のコードサンプルは自己責任でご利用ください。APIキー等の機密情報は適切に管理し、公開環境での使用時はセキュリティに十分ご注意ください。本記事内容の利用によって生じたいかなる損害(サービスの中断、データ損失、営業損失等を含む)についても、著者は一切の責任を負いません。本記事に掲載されている各社製品・サービスは各社の利用規約に従ってご利用ください。
Discussion