PanderaでPolarsのデータバリデーションを試す
この記事は何?
データバリデーションライブラリのPanderaがPolarsのサポートを開始したので、早速それを試してみるもの。基本的なバリデーションのやり方を確認した上で、実行速度への影響を簡単な実験で確認した。
なお2024/3/16現時点では本機能はベータ版という状態であるため、今後なんらかの大きな変更が発生する可能性がある。最新の情報を得たい場合は、公式のリリースやドキュメントを参照してほしい。
前提
Panderaとは?
Panderaは、pandas.DataFrameのような2次元の表形式の構造を持つデータ(=データフレーム)に対するバリデーションを提供するライブラリである。事前にデータフレームに対して、各カラムの型や制約をスキーマとして定義し、実行タイミングでデータがスキーマを満たすかをチェックする。チェックの結果問題がある場合はエラーを発生させる。
Panderaを使う理由
1つ目としてデータ処理のロバスト性を高められる点がある。Pythonで構造データを用いたデータ分析や機械学習を行うとき、Pandas等のデータフレームを使用してデータを加工する処理を行うことが多い。ここでデータが意図通りに処理されていなかったり、想定外のデータが入力されていたりすると、データの品質が下がる。データの品質が下がると、それを使った分析やモデルの品質も下がる。いわゆる“Garbage In, Garbage Out”である。Panderaを使ってデータのバリデーションを行うことで、データに問題があるときにそれに気づけるようになる。
2つ目として可読性が上がる点がある。Pandas等のデータフレームを使った処理では「データフレームがどのような列で構成されているか?」「各列にはどのようなデータが入っているのか?」という情報を、Pythonのコードを見るだけで読み取るのは難しく、入出力のファイルを見なければわからないことが多い。結果としてデータ処理の中身がブラックボックス化して、保守性の問題が生まれる。Panderaはデータフレームが満たす条件を、スキーマとしてコード内に記述する。これによりコードを読むことで、データフレームがどのようなデータなのか?を確認することができる。
Polarsとは?
PolarsはRustで書かれたデータ処理ライブラリである。マルチコアでの並列処理や遅延評価の仕組みによる高速なデータ処理や、メモリ効率の良さという特徴をもつ。
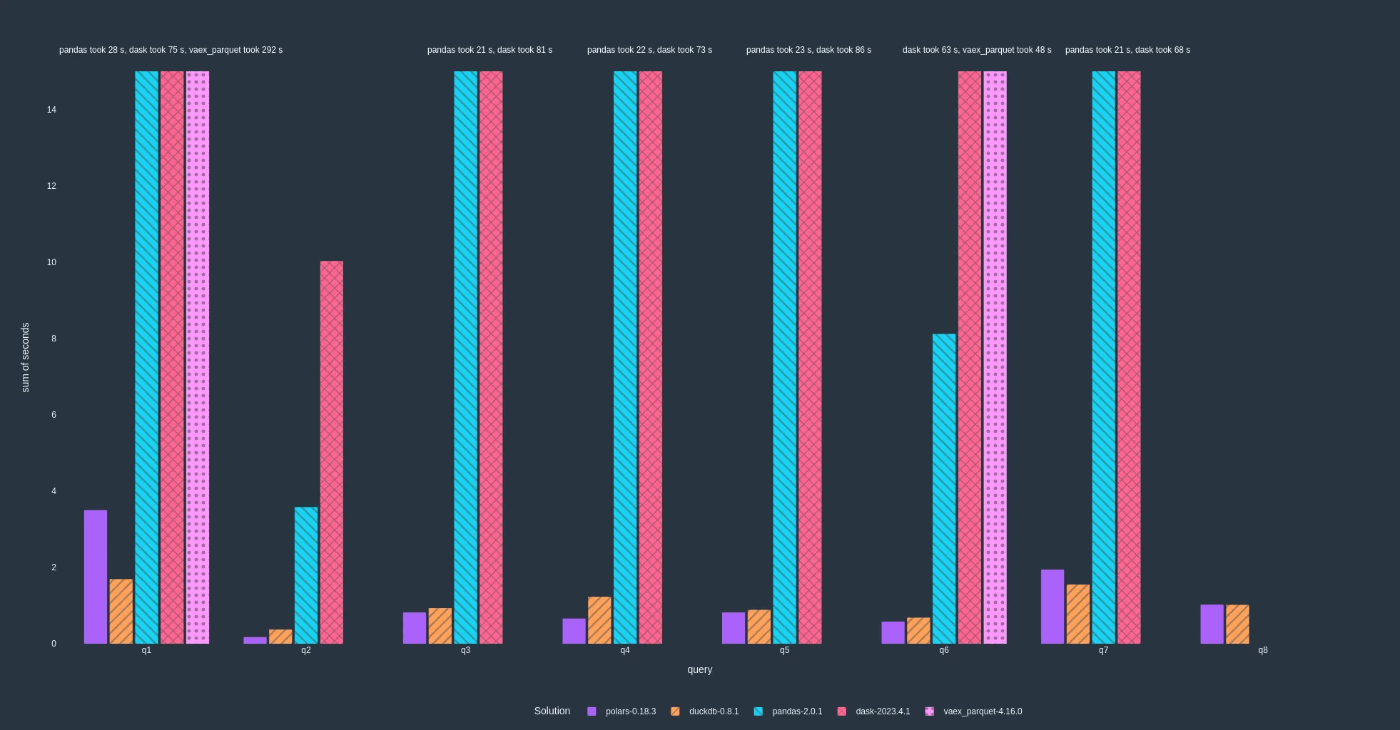
以下はPolarsの公式ブログから引用したTPCHベンチマークの結果である。多くのクエリにおいてPolars(紫色のバー)の実行時間が、Pandasを含む他のツールに比べて小さいことがわかる。
PanderaによるPolarsのデータバリデーション
セットアップ
現時点(2024/3/16)での最新バージョンをインストール
!pip install pandera==0.19.0b
Polars用の追加機能をインストール
!pip install pandera[polars]
バージョンの確認
!pip list | grep -e pandera -e polars
pandera 0.19.0b0
polars 0.20.2
実行環境
Google Colaboratory
基本的な使い方
公式ドキュメントに記載のコードサンプルを参考に、バリデーションの方法を確認していく。
class-basedなバリデーション
pandera.DataFrameModelを継承するクラスSchemaに、型や最大値/最小値といった制約を定義した上、作成したデータフレームに対してバリデーションを行う。Pythonのデータバリデーションライブラリとして有名なPydanticと似た記述の方法である。
import pandera.polars as pa
import polars as pl
class Schema(pa.DataFrameModel):
state: str
city: str
price: int = pa.Field(in_range={"min_value": 5, "max_value": 20})
lf = pl.LazyFrame(
{
'state': ['FL','FL','FL','CA','CA','CA'],
'city': [
'Orlando',
'Miami',
'Tampa',
'San Francisco',
'Los Angeles',
'San Diego',
],
'price': [8, 12, 10, 16, 20, 18],
}
)
Schema.validate(lf).collect()
制約に反するデータフレームを渡した場合は、SchemaErrorが発生する。
lf = pl.LazyFrame(
{
'state': ['FL','FL','FL','CA','CA','CA'],
'city': [
'Orlando',
'Miami',
'Tampa',
'San Francisco',
'Los Angeles',
'San Diego',
],
'price': [8, 12, 10, 16, 20, 25], # 20を超える値
}
)
print(Schema.validate(lf).collect())
SchemaError: Column 'price' failed validator number 0: <Check in_range: in_range(5, 20)> failure cases: shape: (1, 1)
関数実行時にバリデーション
任意の関数(ここではfunction)の実行時に、その入出力のデータフレームに対してバリデーションを行うことも可能。check_types()というデコレータを使う。
from pandera.typing.polars import LazyFrame
@pa.check_types
def function(lf: LazyFrame[Schema]) -> LazyFrame[Schema]:
return lf.filter(pl.col("state").eq("CA"))
function(lf).collect()
object-basedなバリデーション
スキーマをクラスでなくオブジェクトとして定義してバリデーションを行うことも可能である。
schema = pa.DataFrameSchema({
"state": pa.Column(str),
"city": pa.Column(str),
"price": pa.Column(int, pa.Check.in_range(min_value=5, max_value=20))
})
schema(lf).collect()
指定できるデータ型
ここまでの例ではデータ型として、intやstrといったPython組み込みの型を指定していた。これ以外にも、Polarsの型もすべて指定することができる。
class SchemaWithPolarsDataTypes(pa.DataFrameModel):
state: pl.Utf8
city: pl.Utf8
price: pl.Int64 = pa.Field(in_range={"min_value": 5, "max_value": 20})
また、ネストされた型にも対応している。
class ModelWithDtypeKwargs(pa.DataFrameModel):
list_col: pl.List = pa.Field(dtype_kwargs={"inner": pl.Int64()})
array_col: pl.Array = pa.Field(dtype_kwargs={"inner": pl.Int64(), "width": 3})
struct_col: pl.Struct = pa.Field(dtype_kwargs={"fields": {"a": pl.Utf8(), "b": pl.Float64()}})
実行速度への影響
Panderaによるデータバリデーションを入れることによって、Polarsの実行速度に影響がどの程度出るのか?というのが気になったので、簡単に確認してみる。
シナリオ
以下のシナリオのデータ操作にかかる時間を、Panderaによるデータバリデーションの有無で比較する。
- 3つのカラムを持つデータをn行準備
- id
- category
- value
- categoryの値をキーに
group_byをしてvalueの平均値を計算 - 計算した平均値を、categoryの値をキーに基のデータに
joinする - categoryの値でデータを
filterする - 以上のデータ操作の前後で、Panderaによるバリデーションを実行
実行するコード
データ準備
import numpy as np
num_rows = 1_000_000
ids = range(1, num_rows + 1)
categories = np.random.choice(['a', 'b', 'c'], num_rows)
values = np.random.rand(num_rows)
Panderaによるデータバリデーションなしのパターン
%%timeit
# without pandera validation
df = (
pl.LazyFrame(
{
"id": ids,
"category": categories,
"value": values,
}
).join(
pl.LazyFrame(
{
"category": categories,
"value": values,
}
).group_by("category").mean().rename({"value":"avg_value"}),
on = "category"
)
.filter(pl.col("category").is_in(["a", "b"]))
.collect()
)
print(df.head())
Panderaによるデータバリデーションありのパターン
class SchemaBefore(pa.DataFrameModel):
id: pl.Int64
category: pl.Utf8 = pa.Field(isin=("a", "b", "c"))
value: pl.Float64 = pa.Field(in_range={"min_value": 0, "max_value": 1.0})
class SchemaAfter(pa.DataFrameModel):
id: pl.Int64
category: pl.Utf8 = pa.Field(isin=("a", "b"))
value: pl.Float64 = pa.Field(in_range={"min_value": 0, "max_value": 1.0})
avg_value: pl.Float64 = pa.Field(in_range={"min_value": 0, "max_value": 1.0})
%%timeit
# with pandera validation
df = (
pl.LazyFrame(
{
"id": ids,
"category": categories,
"value": values,
}
)
.pipe(SchemaBefore.validate) # Panderaによるバリデーションを実行
.join(
pl.LazyFrame(
{
"category": categories,
"value": values,
}
).group_by("category").mean().rename({"value":"avg_value"}),
on = "category"
)
.filter(pl.col("category").is_in(["a", "b"]))
.pipe(SchemaAfter.validate) # Panderaによるバリデーションを実行
.collect()
)
print(df.head())
結果

今回のデータ操作のケースだと、Panderaによるバリデーションによって2倍程度実行時間が増加するという結果が得られた。
公式ドキュメントにパフォーマンスについて以下のような言及があった。
Compared to the way pandera handles pandas dataframes, pandera attempts to leverage the polars lazy API as much as possible to leverage its performance optimization benefits. However, because pandera is a run-time validator, it still needs to .collect() the data values at certain points of the validation process that require operating on the data values contained in the LazyFrame. Therefore, calling the .validate() method on a LazyFrame will trigger multiple .collect() operations depending on the schema specification.
要するにPolarsのlazy APIによる遅延評価の仕組みを使っていたとしても、Panderaによる実行時バリデーションを行うタイミングで.collect()による評価が行われる、とのことである。したがってPanderaを使わない場合と比較すると、遅延評価による恩恵をフルに受けられないケースがあり、上の実験結果のように実行速度が遅くなる可能性があるようだ。
Panderaを導入を考える際は、コードのロバスト性と可読性を得られるメリットだけでなく、パフォーマンスへの影響も含めて検討する必要があるだろう。
まとめ
PanderaがPolarsのサポートを開始した。Panderaをうまく使うことで、Polarsのデータ処理のロバスト性と可読性を高めることが可能。ただしPolarsの強みである優れたパフォーマンスに影響を与えるトレードオフを考慮する必要がある。
Discussion