CatBoostの推論が速い理由を理解する
本記事について
CatBoostの特徴として、その推論の速さがある。推論が速い事自体は以前から経験的に知っていたが、その理由については「何か特徴的な木構造を使っているから」というくらいの理解で人に説明できるレベルではなかったので、自分の理解のために記事としてまとめるもの。
なおこの記事を書くにあたり、CatBoostの公式ドキュメントに加えて以下の記事を参考にさせて頂いた。
CatBoostとは?
CatBoostはYandex社(ロシアの検索エンジン、ポータルサイトの会社)によって開発された勾配ブースティング木のアルゴリズムである。XGBoostやLightGBMに並んで、Kaggleなどのデータ分析コンペでよく使用されている印象がある。
CatBoostは以下に挙げるような特徴を持つ。本記事では3つめの「推論速度の速さ」に注目したい。
- カテゴリ特徴の処理の工夫
- GPUによる学習の高速化
- 推論速度の速さ
以下の表はCatBoost公式によるXGBoostとLightGBMとの推論速度の比較である。XGBoostやLightGBMと比較して数十倍の推論速度であることが分かる。

CatBoostはどのようにしてこの推論速度を実現しているのだろうか?
CatBoostの木構造
CatBoostはベースとなる予測器として Oblivious Trees(または Symmetric Trees) [1]という決定木を使用しており、この木の構造がCatBoostの高速な推論の鍵である。推論の説明に入る前にOblivious Treesの説明をしておく。この木構造は以下のような特徴を持つ。
- 完全二分木[2]である
- あるレベルにおいて同一の分岐条件が使われる
言葉で説明するよりも実際に決定木を見てみたほうがイメージがしやすいので、可視化して確認してみる。下記は3つの説明変数(x1, x2, x3)から分類タスクを解くモデルをCatBoostで学習させ、そのうちの1つの木を可視化したものである。
from sklearn.datasets import make_classification
from catboost import CatBoostClassifier, Pool
# 分類問題用の人工データを作成
X, y = make_classification(
n_samples = 100,
n_features = 3,
n_informative = 3,
n_redundant = 0,
random_state = 42,
)
# CatBoostの分類器を学習
model = CatBoostClassifier(iterations=3, depth=3, learning_rate=0.1, loss_function='Logloss')
pool = Pool(X, y, feature_names=["x1", "x2", "x3"])
model.fit(pool)
# index=2のtreeを可視化
model.plot_tree(
tree_idx=2,
pool=pool
)
出力:

決定木は「完全二分木」であり「あるレベルにおいて同一の分岐条件が使われる」ことが分かる。
CatBoostの推論はなぜ速いか?
ここから話の本筋に入る。まずは上記のOblivious Treeを用いてCatBoostがどのように推論をするかを説明する。
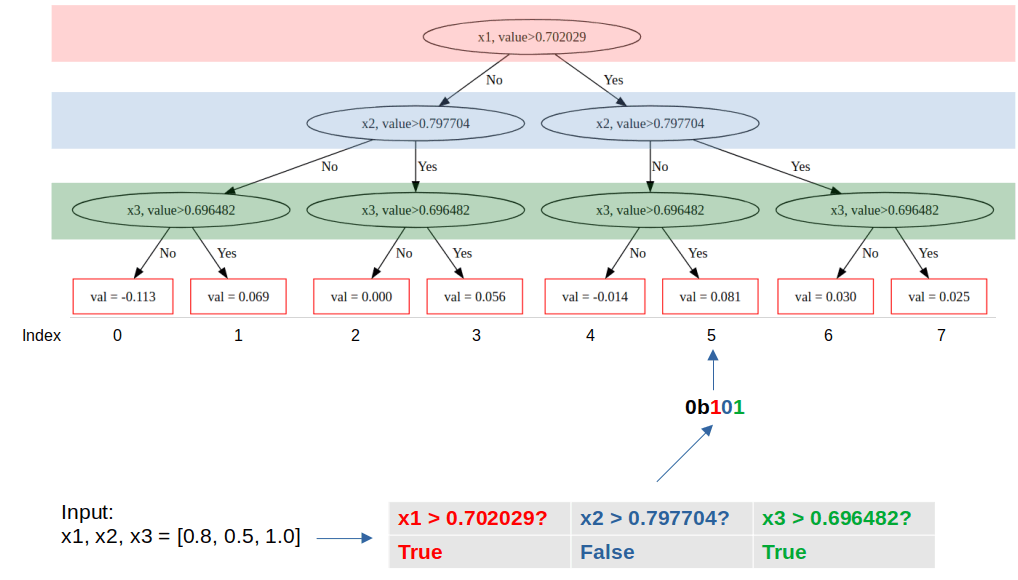
上の図はOblivious Treeを用いた推論のイメージを描いたものである。CatBoostでは入力値に対して割り当てられる葉を以下のように決定する。
- それぞれの葉にインデックスを振る。Oblivious Treeは完全二分木であるため、木の深さを
k 2^k - 入力値に対して各レベルにおける分岐条件を適用する。図の例では入力値が[x1, x2, x3] = [0.8, 0.5, 1.0]であるため、各レベルにおける条件の結果は[True, False, True]である。
- 各レベルで条件を適用したbooleanの結果を、木の深さに等しい長さのbinary vectorとして表現する。図の例では木の深さが3であり、条件判定の結果が[True, False, True]であったため、3ビットの2進数で0b101と表現できる。
- binary vectorに対応するインデックスの葉の値を取得する。図の例では0b101なので対応する葉のインデックスは2進数の101=10進数の5である。従ってこの予測器による予測値は0.081となる。
このようにCatBoostは、Oblivious Treeの各レベルの分岐条件に対するビット演算から葉を特定している。そして上記手順の2.は「木のあるレベルにおいては分岐条件が同一」というOblivious Treeの特徴により並列化による高速化が可能[3]である。図の例だと、x1が0.702029より大きいか?x2が0.797704より大きいか?...という判定をそれぞれのサンプルに対し並列して処理することが可能である。この並列処理による高速化がCatBoostの高速な推論を実現している。
対比のために、Oblivious Treeでない一般的な決定木を考えてみる。
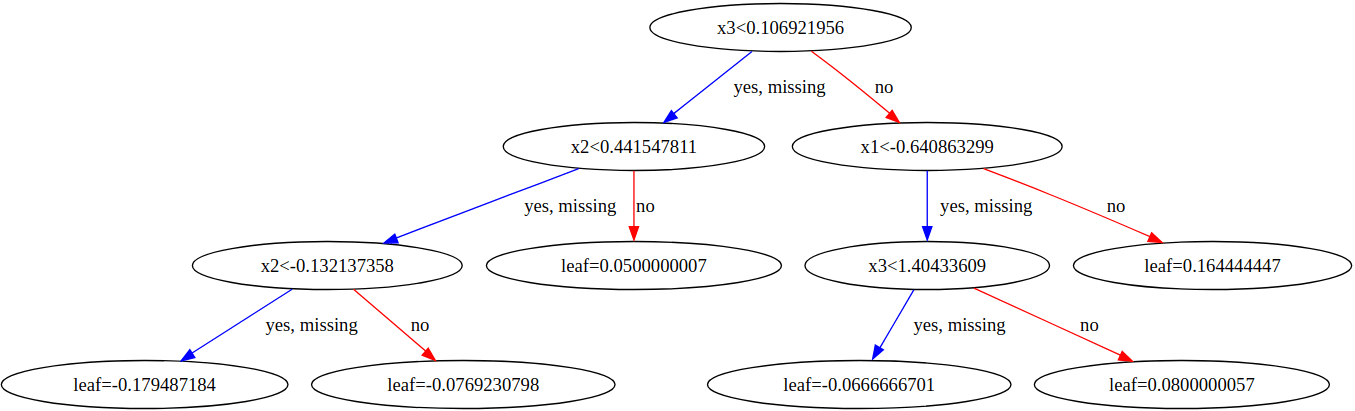
上の図は同様のデータに対してXGBoostで学習した場合の1つの決定木を可視化したものである。CatBoostのOblivious Treeと異なり、各レベルにおける分岐条件は同一でないため、基本的には根のほうから順々に条件判定を行って葉までたどり着く必要がある。従ってCatBoostのような条件判定の並列処理による恩恵は得られづらいと考えられる。
まとめ
CatBoostはOblivious Treeという決定木を用いてモデルの学習・推論を行っており、この木の構造的な特徴により分岐の計算を並列化して高速な推論を実現している。
-
Cambridge Dictionaryによると"oblivious"とは「周りで起きていることに無関心である」という意味を持つ。各レベルでの条件判定が別のレベルでの条件判定の結果に依存しない、すなわち別のレベルでの条件判定結果に「無関心である」ことから、このような命名がされていると考えられる。 ↩︎
-
2分木の木構造のうち、頂点(根)から最底辺(葉)に至る全てのノードが2つの子ノードを持ち、また、すべての葉が根から等しい距離にある構造のこと(引用:ZDNET Japanより) ↩︎
Discussion