Meta Feature とは(Kaggle Amex 振り返り)
本記事について
最近まで Kaggle の Amexコンペに参加していた。結果は4875位中51位の銀メダルだった。公開された解法を見ていたところ、上位解法の多くが Meta Feature という特徴量生成の手法を用いていた。
これらの解法を見るまで自分はこの手法を知らなかったので、本記事でコンペの振り返りの一部として Meta Feature の概要をまとめる。
Amex コンペのタスクとデータ
Meta Feature とは何かを説明する前に、今回の Amex コンペにおけるタスクとデータを簡単に説明する。
- タスク
- 各ユーザのクレジットカードに関する履歴データから、そのユーザが支払不履行となるか否かを予測する二値分類タスク
- データ
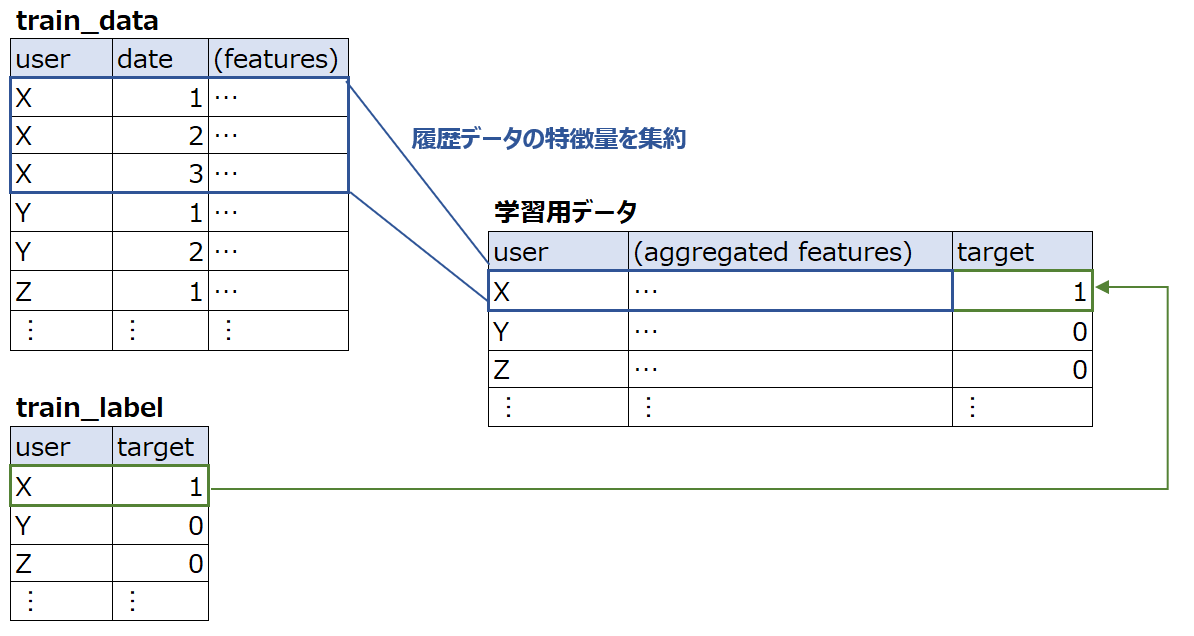
- 各ユーザの履歴データ(train_data)
- 各ユーザが支払不履行となったか否かのラベルデータ(train_labels)
モデルの訓練用データは、以下のようにユーザごとの履歴データを何らかの形で集約(平均、最大、直近データ、、、など)したうえ、与えられたラベルを付与することで作成することになる。
Meta Feature(メタ特徴量)とは
「あるモデルによる予測値」を最終的な予測を行うモデルの特徴量とするとき、その特徴量は Meta Feature(メタ特徴量) と呼ばれる。
今回の Amex コンペのデータでは「個別の履歴データに対するラベルの予測値」を Meta Feature として用いるケースが多かった。以下ではその具体的な作成手順を示す。
-
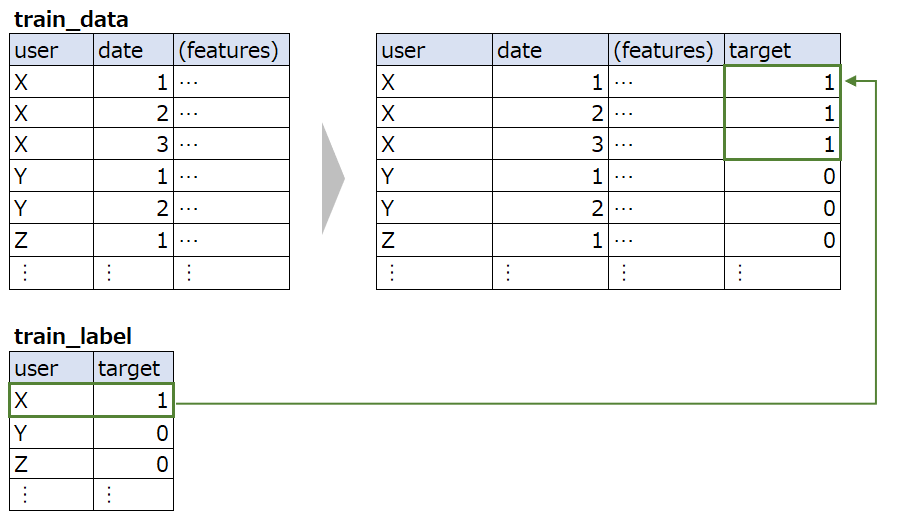
集約する前の履歴データに、ラベルデータを付与する
-
履歴データに付与されたラベルを予測するモデルを学習し、予測値を得る

-
得られた予測値を集約し(平均など)、特徴量として使う

ポイントは、個別の履歴に付与したラベルを予測するモデルの予測値を、最終的な予測を行うモデルの特徴量として使用している点である。
使用上の注意点
Meta Feature を使用する際は、Meta Feature を介して正解ラベルの情報がリークしないように学習を行うよう注意する必要がある。
例えば、以下のような手順は NG である。
- クロスバリデーションなどで学習データを分割することなく、学習データ全体で Meta Feature を作成するモデルを学習する
- そのモデルの予測値を Meta Feature として学習データに付与する
- Meta Feature を付与したデータを用いて、最終的な予測を行うモデルを学習する
この方法では3.でモデルを学習させる際、予測するラベルを Meta Feature を介して「既に知っている」状態になってしまう。この結果、学習では異常に高い精度が出るが、テストデータに対する予測は悪化することが予想される。
これを避けるために、Meta Feature を作成する際は、学習データをクロスバリデーションの fold で分けたうえ、Out of Fold のデータに対する予測値を最終的な予測を行うモデルのインプットとする。
Meta Features が有効だった過去コンペ
Amex 以外のコンペでも Meta Feature が有効だったコンペがあるのか気になったので、Kaggle の Discussion を漁ってみたところ、例えば以下に挙げるコンペの上位ソリューションの中で使われていたことが分かった。
- Home Credit Default Risk の8位解法
- 2019 Data Sciece Bowl の2位解法
- Elo Merchant Category Recommendation 7位解法
まとめ
Amex コンペ開催中にこの手法を使うことができなかったのは、完全に自分の無知とリサーチ不足によるものだった。今回の Amex コンペでも過去のコンペでも実績のある手法なので、同様のコンペが開催されたり業務で使えそうな場面があれば、ぜひ試してみたいと思う。
Discussion