kaggle Commonlit2 上位解法まとめ

ゆめねこさんが行っている上位解法まとめが素晴らしくこれに習い私もCommonlit2のまとめを行いました。LLMが流行り始めてから初めてのNLPコンペで、新たなモデルを用いた解法が出てくると参加前は思ってましたが蓋を開けてみると今まで通りdeberta-v3-largeが最強でした。
ただ、1stのチームはデータの増強目的でLLMを活用しておりこのテクニックのみで優勝しているのでこれからの戦い方を大きくかえるかも知れません。
(ルールの確認はしっかりと行う必要がありそう)
ちなみに弊チームは2106チーム中61thでした。(※スコア確定前)
一緒に戦ってくれたチームメイトに感謝です🙇♂️

コンペ概要
※コンペでは要約前の文章をprompt_textと表しておりここでもそのように記載します。
- 海外の学生(3~12年生)が書いた要約文の質を評価するコンペティションです
- prompt_textの主要なアイデアと詳細をどの程度うまく表現しているか、また要約で使用されている言葉の内容と言い回しを評価するモデルを構築します
- 要約にはcontentとwordingの両方についてスコアが割り当てられておりこのコンペティションの目的は、未知のトピックに関するcontentとwordingの予測です
- データ概要
- 提供データ
- 原文(prompt_text)
- 原文タイトル
- 質問文(=要約指示文)
- 学生の書いた要約文
- 要約の内容の質を表すscore(目的変数)
- content : 内容
- wording : 言葉遣い
- 提供データ
- 評価指標
- MCRMSE (Mean Columnwise Root Mean Squared Error)
- 回帰タスクでおなじみのRMSEの2カラムバージョンです
コンペに概要については、有益なNotebookを公開されていたnogawanogawaさんが上手にまとめてくれています。
prompt_textと要約文の関係性
本コンペではprompt_textは4つあり、1つのprompt_textにつき1000~2000程度の要約文が合計7165あります。
要約文は1人につき1つで、複数のprompt_textに同じ生徒がまたがっているということはなく単純な構成になっています。
ほとんどのチームがprompt_textでのGroupKFoldを採用しておりとくにリークは気にしなくてもよいデータでした。
| prompt_text id | 要約文の数 |
|---|---|
| 814d6b | 1103 |
| ebad26 | 1996 |
| 3b9047 | 2009 |
| 39c16e | 2057 |

上位チーム解法まとめ
prompt_textは500単語以上で構成されいているため長い文章をうまく扱えるモデルを作ったチームが上位となりました。modelは相変わらずdeberta-v3が最強でこれを使っていないチームはありませんでした。
今回は要約文の評価を行うタスクなのでprompt_textタイトル + 質問文 + prompt_text + [SEP] + 要約文のようにprompt_textと要約文の両方をinputさせて学習を行うのが一般的だと思いますが、この入力よりも要約文 + [SEP] + prompt_textタイトルのようにprompt_textを使わない入力のほうがCV/LBともにスコアが良くprompt_textの扱いに苦しめらた参加者が多かったと思います。
deberta-v3-largeでmax_lenを1500以上に長めにとりSpecial tokenを入れたり、loss関数に工夫を加えるとprompt_textを組み込んでもうまく学習できたようです。
また本コンペはCVもLBもどちらも信用しきれずrobust性を高める工夫を盛り込んだチームがPrivateで上位となりました。
robust性を高めるにはbackboneを変えたりinputを変えたりlossを変えたりmodelの多様性を持たせることが重要ですがmax_lenを1500以上に伸ばすと推論時間が長くなりアンサンブルに組み込めるモデルが少なくなるため推論時間を短くする工夫を入れることも重要でした。
CVもLBもどちらも信用しきれない理由としては以下になります。
- 学習データのprompt_textは4つしか提供されてないが、Privateでは122のprompt_textで評価が行われる
- Publicでは1つのprompt_textでしか評価されない
- fold(prompt_textでGroupKFold)ごとでscoreのばらつきが大きい
※Testデータは非公開なのでproving勢のdiscussion情報です
公開Notebookではdeberta-v3での予測値とprompt_textと要約文の単語マッチ数などの特徴量をGBDTに入れる2stageのpipelineが非常に強力で銀圏下位未満の参加者のおおくはこのテクニックを使用していると思われます。ただしdebertaで既に良いスコアが出ている場合は逆に悪化するらしくこのテクニックだけて金に届かせるのは難しかったようです。
12th place solutionでGBDTとweighted avarageの比較をしてくれてました。
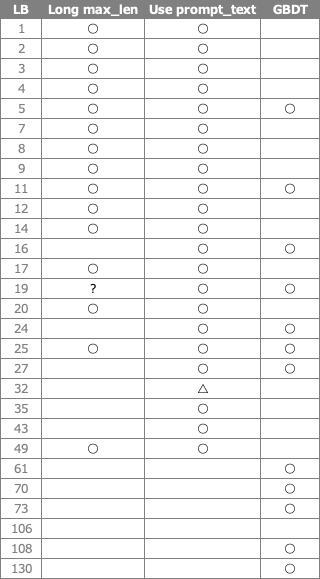
他にもlossに工夫を加えたりするテクニックを加えたり様々な工夫がありましたが以下の3つに絞ってまとめてみると表のようになり銀圏上位以上とそれ以外とで戦略が異なることが明らかになりました。
- max_lenを長くする
- prompt_textを加える
- GBDT
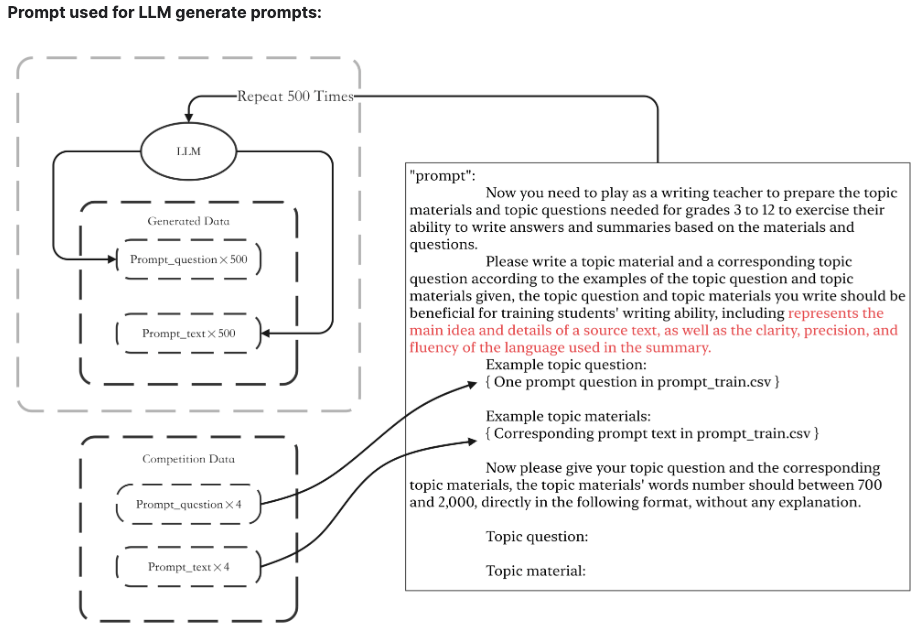
LLMによるデータ増強
1stのソリューションです。
本コンペではprompt_textが4つしか提供されておらず学習データの多様性を上げる目的でデータの増強を行っております。
添付のようなLLMへの指示でprompt_textと要約文を生成し、疑似ラベルを加えたものを学習データに加えています。
※どのLLMを使用したのかは執筆時点では不明
LLMでのデータ増強がルール的に問題なければ今後のコンペの戦い方が大きく変わるかも知れません。

inputの工夫
LLMで使わているようなpromptを追加する
LLMっぽいpromptを入力に加えているチームがいくつかあり、今どきの解法だと思いました。
※ただしこれ単品でどのくらいのgainがあったのかは正確には分からず追試が必要そうです。
2thの入力方法
'Think through this step by step : ' + prompt_question + [SEP] + 'Pay attention to the content and wording : ' + text + [SEP] + prompt_text
4thの入力方法(アンサンブルのうちの一つ)
self.text = "Evaluating the summarized text and calculating content and wording score : " + self.df["text"].values
self.prompt = prompt_title + [SEP] + prompt_question + [SEP] + prompt_text
tokens = tokenizer.encode_plus(
self.text,
self.prompt,
・・・
)
special token
8thのソリューションです。
通常の[SEP]トークンではなく、<question>,<summary>,<text>を追加
"<question> The prompt question text here. <summary> The student summary text here. <text> The original prompt text here."
prompt_textと要約文で一致しているフレーズをマーキング
32thのソリューションです。
prompt_textと要約文n-grams>=3のフレーズを{}でくくるという面白い工夫を入れております。今回のコンペではprompt_textを入力に含めたソリューションが強いですが{}でくくることによりprompt_textを含まなくても良いスコアが出るようです。この解法の良いところは入力を短くできるので推論時間を大幅に削減できるところです。推論時間も3hほど余っているそうで個人的に伸びしろを感じました。アンサンブルに組み込んでもrobust性上がりそうです。
modelの工夫
Head Mask
2thのソリューションです。
Tokenizerによって作成された通常のattention maskを使用する代わりに、head maskを使用し、要約部分には1、その他のトークンには0を持つhead maskを使い、mean poolingに入力。
2thソリューションでは様々な工夫がなされていますが、これが最もインパクトがあったようです。
Input : [TOKEN] [TOKEN] [SEP] [TOKEN] [TOKEN] [SEP] [TOKEN] [TOKEN]
Head Mask : [0] [0] [1] [1] [1] [0] [0] [0]
2つdeberta-v3-largeとLSTM
9thのソリューションです。
2つのdeberta-v3-largeを用意し1段目はfull text,1段目のoutputをmaskしつつ2段目に入力。2段目の出力をLSTMに入力という複雑なアーキテクチャになっています。
以下の仮説に基づいて実装されたそうです。
モデルが概要とプロンプトの関係を捉えられるようにしたいと考えすべてを入力に含めたい一方、トレーニングデータとテストデータではprompt_idが異なるため、プロンプト部分をプーリングに含めないほうが汎化性が向上する。
Since the prompt_id is different between the train data and test data, I believed that not including the prompt part in the pooling would improve generalization. So, I decided to only pool the summary part. Furthermore, by training only the summary part in a separate DeBERTa model before pooling, I believed it might lead to a better score. Hence, for the second DeBERTa model, I input only the summary part.
※私の理解が追いついておらず解釈を間違えてるかも知れないです。ありがたいことに推論コードを公開してくれているので詳しく知りたい方はcollateとcustommodelの実装を読み解くことを推奨します。
Full model train
4thのソリューションです。
max_lenを長めに設定すること推論時間が大幅に増えてアンサンブルの数が限られてしまいますが、4foldを1full trainに置き換えることにより推論時間を短縮しております。
データサイズも推論時間の短縮できそうなので実務でも重宝しそうなテクニックです。
publicにおいてモデルを増やすことはさほど重要ではなかったと思いますが、privateではinputを変えたりmax_lenを変えたりした多様性のあるモデルを増やすことが非常に重要だったとこのソリューションから学ぶことができたと思います。
類似のサンプルをマージする
3rdのソリューションです。
今回のコンペのデータでは、非常に似た要約であるのにもかかわらず、片方のwordingのスコアが高く、もう片方は低いというラベリングの不安定さがありました。
これを解決するために、レーベンシュタイン距離で類似性のあるサンプル同士を見つけ、タイプミスが少ない方を手動で選択してスコアを平均化しております。
私が過去に参加したStable Diffusionコンペにおいても類似性のあるサンプルをfilterすることにより精度が上がったので、このテクニックはいろんなコンペで応用できそうです。
またタイプミスのある単語を逆翻訳により別の単語に置き換えるaugmentationも非常に効果的だったそうです。
Other tips
- LLMを使ったprompt questionの増強(2nd)
- 1つのprompt_textにつき10個のprompt_questionを作る
- 1stはprompt_textそのものを増やしているのでこれとは異なる
- Auxiliary Classes(2nd)
- Feedback3のクラスを疑似ラベルとして加え8classのmulti targetとする
- cohesion,syntax,vocabulary,phraseology,grammar,conventions
- (loss * .5) + (aux_loss * .5) - 逆翻訳とpseudoによるaugmentation(11th)
- 全てのサンプルはドイツ語に翻訳され、その後英語に翻訳しこのデータの50%をランダムに選んでトレーニングに使用した
- RankLossとの組み合わせ(11th)
- SmoothL1Loss, RMSE Loss and RankLossを組み合わせたcostom loss
- 上記のデータ増強を行ったデータに対して行うとsingleで金券に到達するようです。
ここまで上位の解法を紹介させていただきましたが、私の解釈が間違っている可能性もあるのでオリジナルのdiscussionを読みに行くことを推奨します。(Upvoteもお忘れなく👍)
また全ての解法を紹介しきれず私が理解しやすいテクニックを中心に紹介させていただいており若干の偏りがあるためそこはご容赦ください🙇♂️
まとめ
prompt_textを入力に含めて学習を行うのは難易度が高かったですが、これをうまく組み込んで学習させたチームが上位となる結果となりました。要約タスクなので当然という気もしますが。GBDTは非常に強力でしたがSingleでの性能が高い場合は逆効果になり上位とそれ以外で使用の有無が別れました。
データ量が数が少なくタスク自体もわかりやすかったので取り組みやすいコンペではありましたが、cv/lbともに信用しきれず、その分robust性を高める工夫を凝らしたソリューションが光りました。
custom maskを入れてheadには必要情報だけを入力する技術やfull trainでの推論時間を高速化する技術など学べる要素が多くいいコンペだったと思います。
※回帰タスクは運の要素も大きくなるのでpsi氏はこのような発言をしておりましたが。
また1stではLLMと疑似ラベルを使ったデータ増強を行っておりルール的に許されるのであれば今後のNLPコンペの戦い方が大きく変わる気がします。
Discussion