TL;DR
データ指向プログラミング(DOP) とは、データとコードを分割してアプリケーションを設計・実装するプログラミングパラダイムのこと。
DOPの実装は、以下の原則に従う。
- コードとデータを分離する
- 汎用的なデータ構造でデータを表現する
- データをイミュータブルなものとして扱う
- データスキーマとデータ表現を分離する
個人的にDOPは、バックエンドを宣言的プログラミングっぽく書くための現実的な解だと捉えています。実装の詳細は翔泳社より出版されている「データ指向プログラミング」をご覧ください。
はじめに
こんにちは、株式会社CHILLNNという京都のスタートアップにてCTOを務めております永田と申します。
最近、エンジニアコミュニティでオブジェクト指向の定義に関する議論が行われているのを見かけます。Java育ちの自分にとって、オブジェクト指向の権威性を揺るがすような議論はかなり衝撃的だったのですが、確かに数年間自社サービスを運用する中で、各オブジェクトの責務が肥大化していき、自分の能力で扱うことに限界を感じていました。
Alternativeを探す中で、データ指向プログラミング(DOP)に関する情報を見つけ、自社のプロジェクトに取り入れてみて、これは既存のプロジェクトと連続性を持って、複雑性を軽減していける優れたパラダイムだと感じたため記事にまとめることにしました。
この記事の目的
本記事の目的は、DOPのプログラミング・パラダイムの概要をざっくり掴んでもらうことです。
以下のような順序で説明していきます。
- DOPが生まれた背景を説明します
- DOPのパラダイムのコアについて簡潔に説明します
- DOPの利点について説明します
- DOPで守るべき原則を紹介し、コーディングのガイドラインを示します
それではいきましょう〜
DOPはなぜ生まれたのか
DOPは、古典的なオブジェクト指向プログラミング(OOP)のプロジェクトで発生する複雑性を解消するためのプログラミング・パラダイムとして生まれました。
古典的なOOPのプロジェクトで発生する複雑性
OOPは、オブジェクトを中心としてソフトウェアを設計・実装するアプローチです。
オブジェクトは、各オブジェクトが持つメソッドを通じて他のオブジェクトと相互作用します。
DOPの文脈では、古典的なOOPでは以下の複数の側面がシステムの複雑さを増大させる傾向があると考えます。
- 側面1: コードとデータが混在している
- 側面2: オブジェクトがミュータブルである
- 側面3: データがメンバとしてオブジェクトに閉じ込められている
- 側面4: コードがメソッドとしてクラスに閉じ込められている
側面1: コードとデータが混在している
OOPでは、コードとデータがクラスに混在しています。データはメンバとして、コードはメソッドとしてクラスに含まれています。コードとデータが混在すると、エンティティが多くの関係に関与しがちであるという理由でシステムが複雑になる傾向があります。
オブジェクト間には、合成、関連、継承、使用の関係があります。
合成とは、一つのオブジェクトが死ぬと、もう一つのオブジェクトも死ぬ関係のことです。
関連とは、それぞれのオブジェクトが独立に存在できる関係のことです。
Xで例えるなら、ユーザーとポストの関係は、ユーザーが削除されれば、ポストも全て削除されるので合成であり、フォローフォロワーの関係は、どちらか片方が削除されても残る一方は存在することができるので、関連となります。
また、継承とは、クラス継承の関係です。子クラスが親クラスのメソッドやメンバを持っていることを意味します。使用とは、あるクラスが別のクラスのメソッドを使うという関係です。
以下は、データ指向プログラミングの中で紹介されている、図書館のシステムのUMLを簡略化したものなのですが、一見してオブジェクト間の関係を捉えることはなかなか困難かと思います。
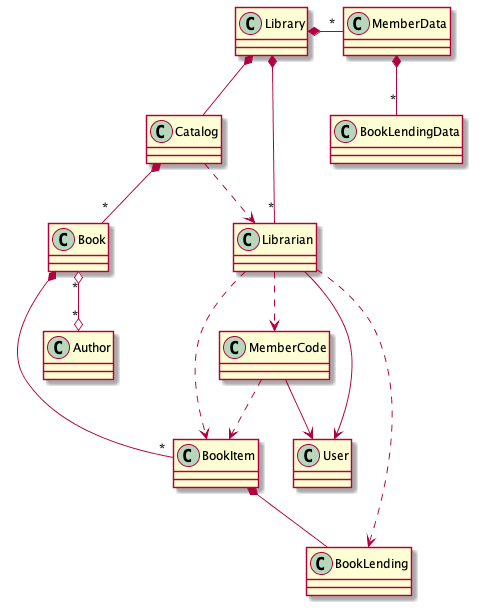
図書館システムの概要
システム要件
- ユーザーは図書館の会員と司書の二種類
- ユーザーは電子メールアドレスとパスワードでシステムにログインする
- 会員は本を借りることができる
- 会員と司書はタイトルまたは著者名で本を検索できる
- 司書は会員をブロックまたはブロック解除できる(本の返却が遅れている場合など)
- 同じ本が何冊か所蔵されていることがある
- 本は図書館に物理的に所蔵されている
図書館システムの主要なクラス
- Library:システム設計の中心部
- Book:本
- BookItem:同じ本が何冊か所蔵されている場合、それぞれの蔵書はBookItemとみなされる
- BookLending:本が貸し出されると、BookLendingオブジェクトが作成される
- Member:図書館の会員
- Librarian:図書館の司書
- User:LibrarianとMemberの基底クラス
- Catalog:所蔵本のリスト
- Author:本の著者
この複雑性の一因は、オブジェクト間の関係として4種類の可能性があることを考慮しなくてはならないからだと考えられます。
側面2: オブジェクトがミュータブルである
以下のシンプルな擬似コードを見てみてください。
class Member {
isBlocked;
displayBlockedStatusTwice() {
var isBlocked = this.isBlocked;
print(isBlocked);
print(isBlocked);
}
}
member.displayBlockedStatusTwice();
上記のコードを実行した場合、どんな出力になるでしょうか?
もちろんtrueが2回表示されます。
では以下の擬似コードではいかがでしょうか?
class Member {
isBlocked;
displayBlockedStatusTwice() {
print(this.isBlocked);
print(this.isBlocked);
}
}
member.displayBlockedStatusTwice();
シングルスレッド環境ではtrueが表示されるが、マルチスレッド環境では予測不可能である、が正解です。
マルチスレッド環境では、2つのprint関数の呼び出しの間にオブジェクトの状態を変化させるコンテキストスイッチが存在していてもおかしくありません。
JavaScriptのようなシングルスレッドの環境であったとしても、非同期関数の呼び出しなど、少し変更を加えるだけで予測が不可能になる可能性があります。
今回はシンプルな例を示しましたが、より複雑なオブジェクトに対してデータがミュータブルである場合、コードの振る舞いを予測することは非常に困難になります。
側面3: データがメンバとしてオブジェクトに閉じ込められている
JSONでClientにデータを返すAPIを実装する必要が生じたとしましょう。
古典的なOOPでJSONのシリアライズとデシリアライズを行うためには、クラスをいくつも追加する必要が生じます。データはクラスで定義された厳格な形状に従わなくてはならないため、データに汎用的にアクセスする簡単な方法は存在していないためです。
側面4: コードがメソッドとしてクラスに閉じ込められている
OOPにおいて、同じコードを何度も書かなくて済む一つの方法はクラスの継承を用いることです。
システムの要件が事前に全てわかっている場合は、共通の振る舞いを持つクラスが基底クラスを継承するような方法でクラスの階層を設計します。
しかし、現代的な開発では事前に全ての要件が決まっているようなことは滅多にありません。複数のオブジェクトにまたがる新規の要件が発生した場合には、影響範囲に存在しているクラスに対して、新たに共通の振る舞いをもつクラスを導入する必要が生じ、徐々にクラス階層が複雑になっていってしまいます。
これはダイアモンド継承と呼ばれるアンチパターンとされており、新規の振る舞いをもつオブジェクトを、既存のオブジェクトとの合成の関係で定義するGoでお馴染みの、Composition over inheritanceデザインパターンを用いるべきだとされます。
しかし、どちらの方法をとったにせよ、オブジェクトの数は増え、オブジェクト間の関係の複雑性は増していってしまいます。
OOPでの回避策
オブジェクト指向のエコシステムでは、上記で発生する問題に対し、言語に新たな機能(Javaの無名クラスや無名関数など)を追加したり、開発者にシンプルなインターフェースを提供するフレームワーク(JavaのSpringなど)を開発することで、複雑さの一部を隠せるようにしてきました。
DOPでの回避策
一方、DOPでは、上記で挙げた複雑性が
プログラムはある状態からなるオブジェクトと、その状態にアクセスし操作するためのメソッドから構築されるべき
という、OOPの基本的な洞察に内在するものだと捉え、新たなパラダイムを導入することで複雑性を軽減しようとするアプローチをしています。
では、次の章からこのDOPのアプローチについて解説していきます。
DOPとは何か
DOPとは、ソフトウェアの設計・実装においてデータとコードを分けて考えるアプローチのことです。これは後で紹介する、DOPの原則1で言っていることと同じですが、これこそがDOPの本質だと認識してしまって問題はないと思います。その他の原則は、原則1を守るために必要なガイドラインだと捉えるくらいで良いと思います。
DOPでは、プログラミングをデータを変換することだと定義します。
この定義によれば、プログラミングとは、入力データを処理し、特定の出力データを作成する方法を記述した一連のマシン命令作成する行為です。だとすれば、データを操作するコードと、データ自身を分けて考えることは理にかなっています。
ここで強調しておきたいのは、DOPは、データ駆動であることは意味しないということです。
DOPの文脈では、データとコードのどちらから先に定義すべきとかがあるわけではありません、責務が異なっているだけです。
DOPは、汎用的なデータ構造で定義されたデータエンティティと、ステートレスな関数のみで定義されたコードエンティティの、2つの独立したサブシステムで構築されています。
2つのサブシステムが独立しているということは、サブシステムを別々に、どのような順序で理解しても良いということです。
具体的にDOPの利点を見ていきましょう。
DOPの利点
DOPの主な利点として、以下の点を挙げることができます。
- システムを理解しやすくすること
- 柔軟な機能追加を可能にすること
- 言語によらず適用ができ、学習効率がよいこと
DOPの理解しやすさ
まずは具体例を紹介します。
OOPで出したUMLについて、DOPで定義しなおしたものがこちらです。

図書館システムの概要
システム要件
- ユーザーは図書館の会員と司書の二種類
- ユーザーは電子メールアドレスとパスワードでシステムにログインする
- 会員は本を借りることができる
- 会員と司書はタイトルまたは著者名で本を検索できる
- 司書は会員をブロックまたはブロック解除できる(本の返却が遅れている場合など)
- 同じ本が何冊か所蔵されていることがある
- 本は図書館に物理的に所蔵されている
図書館システムの主要なデータ
- LibraryData: システム設計の中心のデータ
- LibrarianData: 図書館の司書のデータ
- MemberData: 図書館の会員のデータ
- CatalogData: 所蔵本のリストのデータ
- BookData: 本のデータ
- AuthorData: 本の著者のデータ
- BookItemData: 同じ本が何冊か所蔵されている場合、それぞれの蔵書はBookItemとみなされる
- BookLendingData: 本が貸し出されると、BookLendingDataが作成される
図書館システムの主要なコード
- CatalogCode: カタログデータを引数に取る振る舞いを定義したコード(カタログへの本の追加など)
- LibrarianCode: 司書データを引数に取る振る舞いを定義したコード(会員のブロックなど)
- MemberCode: 会員データを引数に取る振る舞いを定義したコード(本の返却など)
- UserCode: 司書と会員の共通の振る舞い定義したコード(ログインなど)
- BookLendingCode: BookLendingDataを引数に取る振る舞いを定義したコード(本の返却など)
- BookItem: 会員から見た本の振る舞いを定義したコード
- BookItemCode: 司書から見た本の振る舞いを定義したコード
左がデータエンティティのみを含む部分、右がコードエンティティのみを含む部分です。
データエンティティでは、エンティティ間の関係は、関連関係と、合成関係のみです。
コードエンティティでは、エンティティ間の関係は、使用関係のみで表現されます。
OOPで構築していたUMLに比べて、一つのエンティティについて考慮しなくてはならない関係が半分以下になり、理解しやすくなっていると感じないでしょうか?
エンティティの数と、関係性の種類から考えうる関係性の数は、関係性には方向性もあることを考えると、指数関数で表現できます。こう考えると関係性の種類が半分以下になったことがどれだけ複雑性を減少させているか体感できるのではないでしょうか。
DOPの柔軟さ
DOPのシステムでは、追加の機能要件に対して、多くの場合既存のシステムの要件を変更することなく対応ができます。
上述の図書館のシステムを利用して具体例を挙げます。
class Library {
static getBookLending(libraryData, userId, memberId) {
if (UserManagement.isLibrarian(libraryData.userManagement, userId)) {
return Catalog.getBookLendings(libraryData.catalog, memberId);
} else {
throw "Not allowed to get book lendings"
}
}
}
class UserManagement {
static isLibrarians(userManagementData, userId) {
/* 省略 */
}
}
class Catalog {
static getBookLendings(catalogData, memberId) {
/* 省略 */
}
}
図書館のシステムには、2種類のUserが存在しています。
一種類は図書館の司書、もう一種類は本を借りる図書館の会員です。
司書には特定の会員の借りている本を閲覧する権限が与えられています。
仮に、新規の要件が追加され、会員の中にVIP会員という制度ができ、VIP会員は他の会員の借りている本を閲覧できるようにする必要が生じたとしましょう。(この機能の意味不明さは気にしないでください。)
その場合、コードエンティティでは、以下のようにコードを修正するだけで対応ができます。
class Library {
static getBookLending(libraryData, userId, memberId) {
if (
UserManagement.isLibrarian(libraryData.userManagement, userId) ||
UserManagement.isVIPMember(libraryData.userManagement, userId)
) {
return Catalog.getBookLendings(libraryData.catalog, memberId);
} else {
throw "Not allowed to get book lendings"
}
}
}
class UserManagement {
static isLibrarians(userManagementData, userId) {
/* 省略 */
}
static isVIPMember(userManagementData, userId) {
/* 省略 */
}
}
class Catalog {
static getBookLendings(catalogData, memberId) {
/* 省略 */
}
}
DOPでは、複数のエンティティが関わる処理について、オブジェクトがデータとコードを混在させている場合に比べて、classの関係を複雑にせずに素朴にDRYな実装を行うことができます。
DOPは言語によらない
DOPは、OOPによって生じうる複数の課題に対して、言語仕様やフレームワークを開発するのではなく、パラダイムを導入することで解決をしようというアプローチです。DOPが示すガイドラインは、複雑な言語仕様に依存するものはなく、どんな言語でも適用可能なものになっており、学習効率が良いと感じています。
DOPのデータエンティティは、マップや配列といった、汎用的なデータ構造で表現されています。そのため、各言語のエコシステムの資産を最大限活用することができます。
ちなみに、データ指向プログラミングでは、ほとんど全てのサンプルコードがJavaScriptで表記されており、時々lodashに関する解説が入っていました。最初は、なぜこのご時世にTypeScriptじゃないのか、なぜlodashについてこんなに説明するのだろうか?と疑問に思っていたのですが、全文を通して、言語によらず既存のコミュニティの資産を活用できることを伝えたかったのだと理解しました。
DOPの原則
DOPがデータをどのように表現し、操作するかについてのガイドラインを紹介します。
このガイドラインに従うことで、DOPにソフトウェアを構築することが可能です。
データ指向プログラミングでは、4つの原則が紹介されています。
- コードとデータを分離すること
- データエンティティを汎用的なデータ構造で表すこと
- データがイミュータブルであること
- データスキーマをデータ表現から切り離すこと
順に説明していきます。
原則1: コードとデータを分離する
これは、本記事で何度も主張してきたことです。この原則は関数型言語の原則のように見えますが、OOP言語でも、関数型言語でも、守ることも破ることも可能です。
この原則に従うことで、エンティティ間の関係性が明確になり、ソフトウェアを理解しやすくなります。
原則2: 汎用的なデータ構造でデータを表現する
原則1に従うことで、コードはデータから切り離されます。DOPは、コードを整理するために使用するプログラミングの構成要素については意見を述べないですが、データをどのように表現すべきかについては制約を課します。
データエンティティは、マップや配列といった一般的なデータ構造で定義します。
その他にも、一般的なもの(set、tree、queue)などであれば利用が可能です。
DOPでは、10個の関数が10個のデータ構造を操作するよりも、100個の関数が1個のデータ構造を操作する方が良いと考えます。この原則に従うことで、エコシステムに存在する特定のユースケースに限定されない汎用的な機能(JavaScriptで言えばlodashなど)を使用することができます。
また、データモデルが柔軟になり、ほんの少し構造が異なるだけの不必要なclassを生成する必要がなくなります。
原則3: データをイミュータブルなものとして扱う
DOPは、データの変更に関して厳しい制約を課します。
全てのデータ変更は、データが変更された新しいバージョンのデータを作成することによって行います。
データをイミュータブルなものとして扱う思想自体は、すでにかなり一般化しているかと思うので、こちらはあまり違和感がないかと思います。
原則4: データスキーマとデータ表現を分離する
DOPでは、データに期待される形状は、データスキーマとして表現され、データ自体から分離されます。データは実行時に検証され、オプショナルなフィールドを持たせたり、検証すべきデータ、検証が不要なデータを自由に選択することができます。
DOPではOOPとは異なり、柔軟なデータモデルを利用するため、意図しないデータがシステムに入ってしまうという懸念がありますが、この原則を利用し、システム境界にてデータ検証を行うことでデータが適切であることを強く保証することができます。
まとめ
DOPは、データとコードの間に境界を引きました。
宣言的プログラミングのパラダイムをバックエンドに適用するにあたって有用な概念だと感じています。
弊社では、モジュラモノリスを採用することで、オブジェクト間の関連が単純な箇所を明示的に切り分け、その部分ではOOP、アプリケーション全体のエンティティはDOPで構成するといったようにハイブリッドな構成をとっています。
自分のプロジェクトに適用させていく中で、DOPとは、ソフトウェアと現実世界の違いをありのままに受け止め、ソフトウェアの特性に合わせて実装・設計を行うアプローチなのだと思うようになりました。
ある程度わかってしまえばDOPは普通です。10年くらい前に初めてコードを書いた時の感覚に近いとすら思いました。直感に反しないので、もはやわざわざ記事にするほどか?と思いながら書いていました。
本記事は、データ指向プログラミングの第1~6章までを、他のソースや原点に当たりながらまとめなおしたものです。普通すぎることを言っているので利点を説明するのが難しいためか、対話形式になっており少々読みにくいですが、アイデアは本当に素晴らしいと感じたのでぜひ一読を進めます。
個人的には、まずは原則1に従うだけでもDOPの利点は得られると感じています。その他の原則に関しては、プロジェクトのサイズによって検討すべきかと思います。
もし興味をお持ちになりましたらぜひぜひお試しください〜〜
参考
執筆にあたって大変参考させていただいた記事・及び書籍を紹介します。
データ指向プログラミング
Yehonathan Sharvit Blog
Data-Oriented vs Object-Oriented Design
Data-Oriented Design (Or Why You Might Be Shooting Yourself in The Foot With OOP)
Reduce System Complexity with Data Oriented Programming with Yehonathan Sharvit

Discussion
コードとデータの分離という話は、単純にオブジェクト指向から構造化プログラミングに先祖返りしただけのように読めました。C言語に戻ればよいということでしょうか?構造化プログラミングとの間の考え方の違いを説明して頂けると、より理解しやすいと思います。
コメントありがとうございます。
非常にもっともな指摘を頂けて嬉しいです!
本記事では恣意的に原則1を重視して書いていますが、
筆者は4つの原則を一つにまとめたことがイノベーションであると主張しています。
また、時間を見つけてメリットなどより詳細に追記しようと思います。
UNIXという考え方で
すべてのプログラムを一つのことだけをうまくやる小さなフィルタとして設計する
それを組み合わせれば柔軟に対応できるみたいな事が書いてあったけど似たような感じかしら