こんにちは。
株式会社CHILLNNという京都のスタートアップにてCTOを務めております永田と申します。
弊社では宿泊施設様向けに宿泊施設の予約管理用のSaaSを提供しており、現時点で1000近くの施設様にご利用いただいています。
現在、これまでに溜め込んだ日本最大級の宿泊コンテンツの検索エンジンを構築しており、その過程でさまざまなデータベースを探索しています。
本記事では、AWSのKVSであるDynamoDBを題材に、公式ドキュメントに書かれているキー設計のベストプラクティスの背景を理解することを目的とします。
なお、本記事の執筆にあたって、こちらの動画を大変参考にさせていただきました。
DynamoDBとは
DynamoDBとは、AWSで利用できる、あらゆる規模に対応する高速で柔軟なNoSQLデータベースサービスです。
DynamoDBが登場した背景は、アプリケーションの大規模化です。
現在の大規模サービスには以下のような特徴が挙げられます。
- 数百万ユーザー以上が利用
- データボリュームは、TB, PB, EB
- サービスを提供する地域は世界中
- パフォーマンスはmilliseconds, microseconds
- リクエスト回数は数百万req/秒以上
この規模のアプリケーション、Amazonを支えるためのデータベースとしてDynamoDBは開発されました。
DynamoDBは以下の特徴を持っています。
フルマネージドである
- メンテナンスフリー
- サーバーレス
- Auto scaling
- バックアップ / リストア
- Global tables
ハイパフォーマンスである
- 高速で一貫した性能
- 事実上無制限のスループット
- ストレージ容量も制限なし
エンタープライズに対応できる
- 通信と保存データの暗号化
- 柔軟な権限管理
- PCIなどの認証
- SLAの提供
DynamoDBのテーブル構造
DynamoDBでは、RDBと同様にTableという形でデータを分割しています。
そして、Tableの中にItemという形でデータを保持します。
Itemの中にはAttributeという形で属性をつけることが可能です。
Attributeは、Itemごとに異なる柔軟な構成を持つことができます。

各Itemは、主キー(Primary Key)として用いるPartitionKeyを持つ必要があります。
このPartition Keyがデータの分布を決定します。
また、テーブルの設定によってオプションとしてSortKeyを持つ設定にすることができます。
SortKeyをつけることによりQueryによる幅広い探索を行うことが可能になります。
SortKeyで利用可能な構文
==, <>, <, >, >=, <=
"begins with"
"between"
大小比較、完全一致、前方一致での検索が可能
SortKeyを設定した場合は、主キーは、PartitionKeyとSortKeyの複合キーとなります。

Get/Put/Update/Deleteは、PartitionKeyとSortKeyを指定して、対象Itemを決定します。
QueryはPartitionKeyのみを指定し、Sort Keyは条件指定に利用します。
Queryを行う際には、この他にLocal Secondary IndexとGlobal Secondary Indexという、2種類のIndexを利用することができます。
Global Secondary Index
PartitionKeyおよびSortKeyをもつIndexです。ベーステーブルのKeyとは異なるものを設定できます。後ほどさらに詳しく述べますが、Global Secondary Indexは、ベーステーブルとは異なる独自のパーティション領域に保存され、ベーステーブルとは別でスケーリングします。また、Global Secondary Indexデフォルトでスパースであり、設定したKeyが空であるItemは、独自のパーティション領域には含まれません。
Local Secondary Index
PartitionKeyはベーステーブルと同じで、SortKeyが異なるIndexです。
全てのインデックス付き項目の合計サイズが10GB以下である必要があります。
Itemの物理的な配置
DynamoDBでは、スケールのために、パーティションという単位でデータを分散して保持しています。RDBのシャーディングにおける水平分散をイメージしていただければ良いかと思います。
Itemをどこのパーティションで保持するかは、ItemのPartitionKeyの値によって決定されます。
例を見ていきましょう。
Partition Key
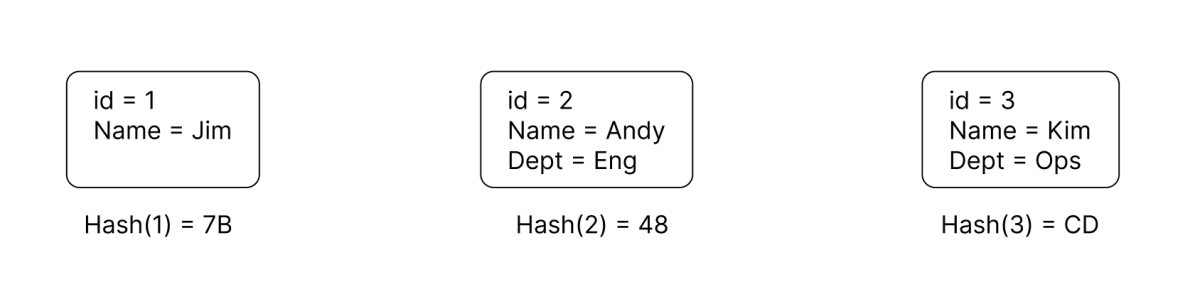
簡単な3つのItemについて考えます。
以下のItemでは、idというAttributeをPartitionKeyとして設定しているとします。

PartitionKeyの値は、DynamoDBの内部でハッシュ関数を利用して分散されます。
仮に返り値が00からFFをとりうるハッシュ関数を想定し、ハッシュ関数にidを渡した時の返り値が以下になったとします。
ハッシングにより、規定される空間の中でItemは以下のように分散されます。
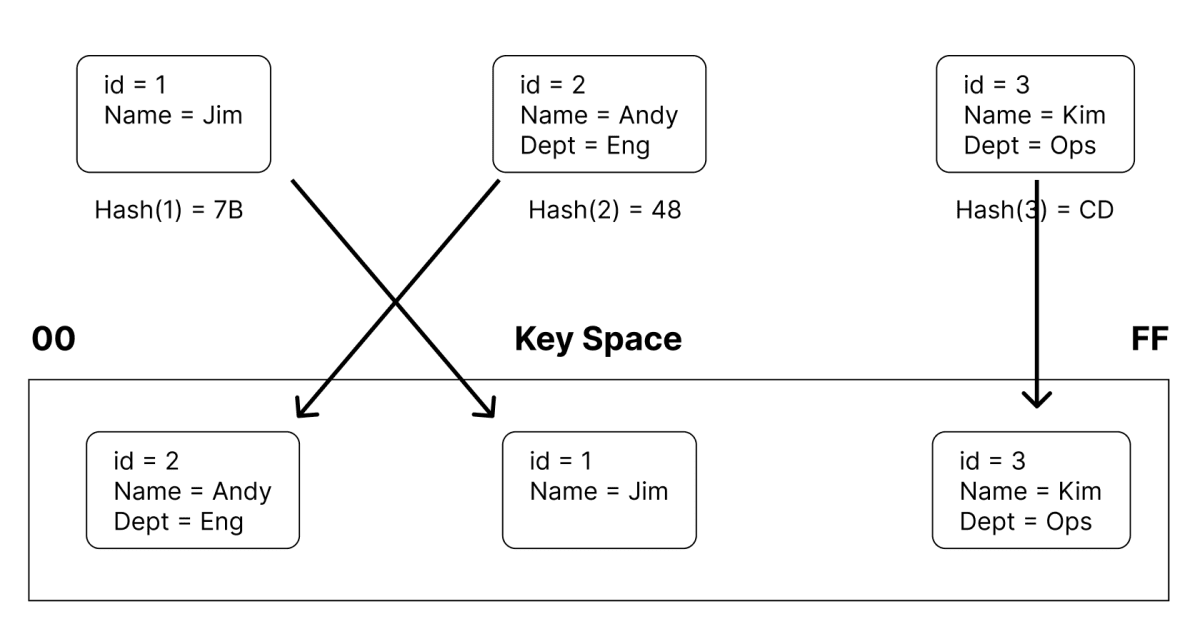
分散されたItemは、この例では、パーティションごとに保持するItemが均等になるように分割されるので、以下のようなパーティションに分けられます。
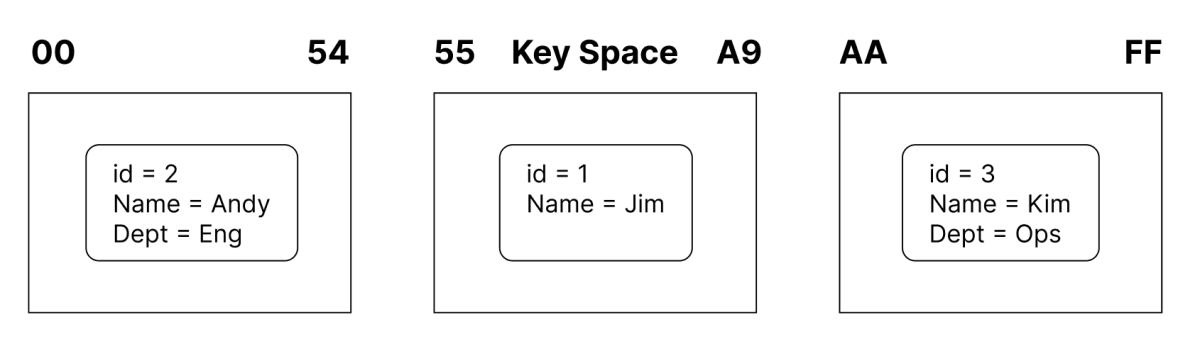
こういった仕組みのおかげで、DynamoDBは高頻度のトラフィックが行われる場合も、多くのストレージ容量が必要になった場合にも対応が可能になっています。
Sort Key
同一パーティションの中でのItemはどのように配置されているのでしょうか?
以下の例では、PartitionKeyをid, SortKeyをorderとしてそれぞれ設定しているとします。

DynamoDBでは、PartitionKeyとSortKeyの2つの属性を使ってItemを識別します。
同一のPartitionKeyを持つItemは、SortKeyによって昇順で配置されます。
また、PartitionKeyごとにSortKeyの数の制限、すなわち、Item数の制限は存在していません。
補足1: Replication
それぞれのパーティションに保存されたデータは必ず、3つ以上のAvailabilityZone(=AZ)に保存されます。また、書き込みのタイミングでは少なくとも2つのAZに書き込みが完了した時点でResponseが返されます。
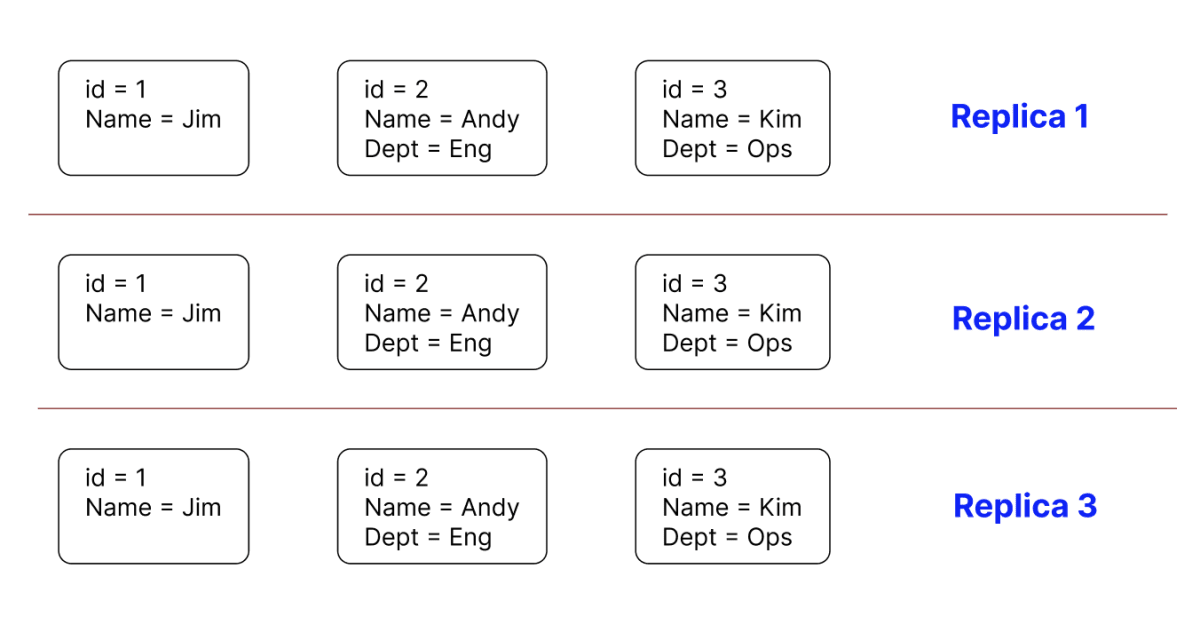
そのため、一つのパーティションに問題が発生したとしても、他のAZでデータが保持されている場合は復旧が可能です。
補足2: GSIへのデータ追加
DynamoDBの検索の柔軟性を上げるために重要なGSIですが、GSIパーティションへのデータ書き込みはベーステーブルのデータの更新が完了し、clientにResponseを返したタイミングで非同期で行われます。
DynamoDBのキャパシティチューニング
ここまでの技術的な背景を頭に入れた上で、DynamoDBのベストプラクティスについて見ていきましょう。
DynamoDBのドキュメントでは、キー設計のベストプラクティスとして、PartitionKeyごとのアクセスがある程度均等になるような設計をすることがベストプラクティスとして紹介されています。
それはなぜでしょうか?
DynamoDBでは、テーブル全体のキャパシティを設定します。(GSIではGSIごとにスループットを設定します。)設定したキャパシティは、上記で説明をしたパーティションに均等に分散されます。
パーティションは均等に分散されるため、特定のパーティションにトラフィックが集中(=ホットパーティション)してしまう場合には、一部のパーティションでは割り当てられたキャパシティが余っているのに、ホットパーティションではキャパシティが枯渇してしまい、スロットリングが発生してしまう可能性があります。
具体的にはSNSのようなサービスを運用している中で、特定のユーザーの情報だけが極端に多く閲覧されるような場合が考えられます。
Adaptive Capacity
上記の例でも挙げたとおり、PartitionKeyごとのトラフィックを開発段階で予想することはかなり困難です。結果的に、ホットパーティションに最適化したキャパシティを設定する必要がありました。
DynamoDBの初期実装では、この問題を回避することはできませんでしたが、2018年にAdaptive Capacityという機能が実装されました。
この機能は、特定のパーティションに割り当てられたキャパシティが枯渇した場合に、別のパーティションのキャパシティが余っていればそれをホットパーティションに割り当てることができるという機能です。

2018年のリリース段階では、発動までに5分〜30分の遅延が生じていましたが、2019年にこの遅延がなくなりました。
この機能開発によって、パーティションに対するキャパシティのダイナミックな割り当てが可能になり、事前のキャパシティプランニングが不要なRequest課金でのOn-Demandのプライシングが利用できるようになりました。
その他拡張性に関する補足
Burst Capacity
DynamoDBでは、通常、テーブルごとにキャパシティを設定します。
しかし、アプリケーションを運用していれば、突発的なトラフィックの増加により、キャパシティが意図せず枯渇してしまう場合があります。
このような場合でも、DynamoDBはキャパシティのうち利用されなかった過去300秒分のキャパシティをリザーブしておき、プロビジョニングしていたキャパシティを超えたバーストトラフィックを処理するために利用することができます。
Auto Scaling
DynamoDBでは、キャパシティの上限と下限を設定することによりオートスケーリングの設定を行うことができます。
これにより、トラフィックに応じて自動的に容量を拡大・縮小させることができ、コストを削減することができます。
まとめ
ここまで読んでいただいてありがとうございました。
今回の記事では、ベストプラクティスから、ミドルウェアの技術的詳細を探ってみました。(結果的にアプリケーションレイヤーでかなり解決されていそうで、ベストプラクティスにどの程度従う必要性があるのか疑問が生じてしまいましたが、、、)
データベースといった、複雑かつ移行コストの大きなミドルウェアでは、その特性を技術的背景から理解しておくことで適切に選定・運用を行うことができますし、今後の発展の方向性を予測することが可能です。ベストプラクティスの理由を探るというアプローチは、この観点で有用だと感じました。
ちなみに自分は、DBをdigるのが楽しすぎて現在RDBをスクラッチ実装しています。
使い慣れたツールこそ新しい発見が多いものです。寒くなってきて外に出るのが億劫な休日には積極的に車輪の再発明をしていこうと思います。
弊社では、一緒に京都で検索エンジンを作ってくれるエンジニアの方を募集しています!検索エンジンの実装経験なくても大丈夫です!一緒に学んでいきましょう。
フロントエンドのエンジニアの方も、全方位で積極的に募集しているのでご連絡お待ちしています。

Discussion