マイクロサービスにおけるオブザーバビリティに入門してみた(Prometheus + Grafana ハンズオン付き)
はじめに
この記事はリクルート ICT統括室 Advent Calendar 2023 8日目の記事です。
今年の6月にリクルートへ中途入社しました高井です。
普段は社内向けのWebシステムのAWS環境構築やIaC、CI/CD整備などに取り組んでいます。
AWS EC2サーバーで動作している環境をコンテナ環境へ移行したいという要件の中で、モノリシックなアプリケーションからマイクロサービスへ移行を検討する機会がありました。
その際、マイクロサービス下ではどのようにしてシステム内部の状態を把握すれば良いのかを調べるきっかけとなったため、今回はマイクロサービスにおけるオブザーバビリティに入門してみようと思います。
オブザーバビリティについて
基本概念
クラウドネイティブテクノロジーを推進する団体として、Cloud Native Computing Foundation(CNCF)があります。ここが定義している内容を参照してみます。
Observability is a system property that defines the degree to which the > >system can generate actionable insights. It allows users to understand a >system’s state from these external outputs and take (corrective) action.
引用元:https://glossary.cncf.io/observability/
オブザーバビリティとは、システムがどういった状態なのかという内部構造の把握ができることであり、それを元に修正的なアクションを取れることとあります。
オブザーバビリティを考える上で大切なこととしては、データを収集することを目的とするのでなく、データから容易に状況や事象を正確に把握できるかです。
なぜオブザーバビリティが重要なのか?
マイクロサービスアーキテクチャでは、アプリケーションを複数の小さなサービスに分割させることにより、システム全体の柔軟性や保守性を向上させています。一方で、各サービスの状態やパフォーマンスを追跡することが難しくなってしまいます。
ここで、必要になるのがオブザーバビリティであり、内部状態や動作を監視し、理解するための手段を提供します。
リリースすれば終わりではなく、そこからプロダクトやサービスを継続的に育て上げるためには必要不可欠な要素です。
オブザーバビリティが高いと何が良いのか?
わかりやすいところで言うと、システムの異常や障害が早期に検知できることにより、迅速な対応と障害の復旧が可能となり、サービスの可用性が向上します。
また、メトリクスやログを分析して、不要なリソースの特定や最適化が行えることにより、コスト節約と効率的な資源利用が可能になります。
DevOps文脈でも、パフォーマンスの問題や障害の原因を素早く特定できるため、開発及び運用チームは素早く継続的な改善が促進されていきます。
オブザーバビリティの3要素
オブザーバビリティを構築するためには、主にログ、メトリクス、およびトレーシングといった手段が活用されます。
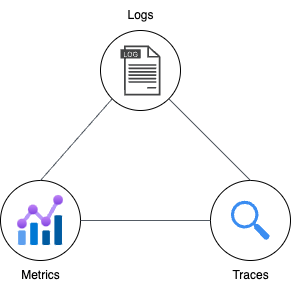
- ログ
イベントやエラーの詳細な記録。ログは問題のトラブルシューティングに役立ちます。 - メトリクス
システムのパフォーマンスを数値で測定。CPU使用率、レスポンス時間などが含まれます。 - トレーシング
リクエストの流れを追跡し、各サービスの相互作用を理解。分散システムでの問題追跡に有効です。
オブザーバビリティを実現するための技術
上記で述べたように、オブザーバビリティを構成する要素としては、ログ・メトリクス・トレーシングがありました。
では、それぞれに関わる技術やツールはどういったものがあるのでしょうか。
CNCFのカオスマップを見てみます。
メトリクス・モニタリング

ログ

トレーシング
引用元:
PrometheusとGrafanaでオブザーバビリティを体験してみる
色々書きましたが、実際に手を動かした方が理解できると思うので、体験してみます。
今回は、CNCF Graduated ProjectでもあるPrometheusとGrafanaでメトリクスを収集しモニタリングするところまでをやってみます。
OSレベルのメトリクスとデータベースのメトリクスを監視対象として、メトリクスを収集しようと思います。
構成
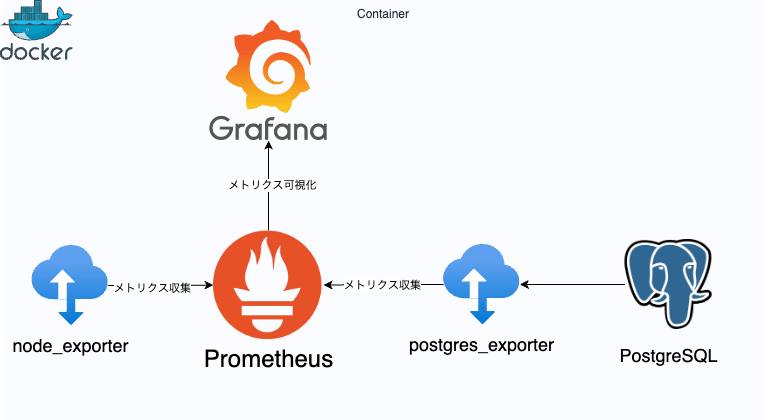
exporterとは、Prometheusが収集できるように、他のシステムやサービスからメトリクスをエクスポートする役割を担っています。今回は、OSレベルのメトリクスを収集するためのエクスポーターであるnode_exporterとpostgresからのメトリクスを収集するためのエクスポーターであるpostgres_exporterを使用します。
上記の構成をDocker composeで構築します。
ファイル構成
.
├── compose.yml
├── grafana
│ └── grafana.env
└── prometheus
└── prometheus.yml
prometheusとgrafanaの構築
以下にならってcompose.ymlを作成します。
compose.yml
version: '3'
services:
prometheus:
image: prom/prometheus
ports:
- 9090:9090
volumes:
- ./prometheus:/etc/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
restart: always
grafana:
image: grafana/grafana
ports:
- 3000:3000
hostname: grafana
env_file:
- ./grafana/grafana.env
restart: always
prometheusのジョブを以下のファイルで設定します。
targetsに指定したエンドポイントを監視対象として設定します。
prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
grafanaの環境変数を設定します。
grafana.env
GF_SERVER_DOMAIN=localhost
GF_SERVER_HTTP_PORT=3000
GF_SERVER_PROTOCOL=http
exporterの設定
node_exporterとpostgres_exporterを構築していきます。postgresも含めて構築します。
compose.yml
version: '3'
services:
prometheus:
image: prom/prometheus
ports:
- 9090:9090
volumes:
- ./prometheus:/etc/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
restart: always
grafana:
image: grafana/grafana
ports:
- 3000:3000
hostname: grafana
env_file:
- ./grafana/grafana.env
restart: always
+ node_exporter:
+ image: prom/node-exporter:v1.7.0
+ ports:
+ - 9100:9100
+
+ postgres:
+ image: postgres:14
+ restart: always
+ ports:
+ - 5432:5432
+ environment:
+ - POSTGRES_USER=root
+ - POSTGRES_PASSWORD=password
+ - POSTGRES_DB=dev
+
+ postgres_exporter:
+ image: quay.io/prometheuscommunity/postgres-exporter:v0.15.0
+ ports:
+ - 9187:9187
+ restart: always
+ depends_on:
+ - postgres
+ environment:
+ - DATA_SOURCE_NAME=postgresql://root:password@postgres:5432/dev?+sslmode=disable
prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
+ - job_name: 'node'
+ static_configs:
+ - targets: ['node_exporter:9100']
+
+ - job_name: 'postgres'
+ static_configs:
+ - targets: ['postgres_exporter:9187']
上記まで記述できましたら、docker composeで起動します。
docker compose up -d --build
全てのコンテナが正常に起動していれば、prometheusの画面を確認します。
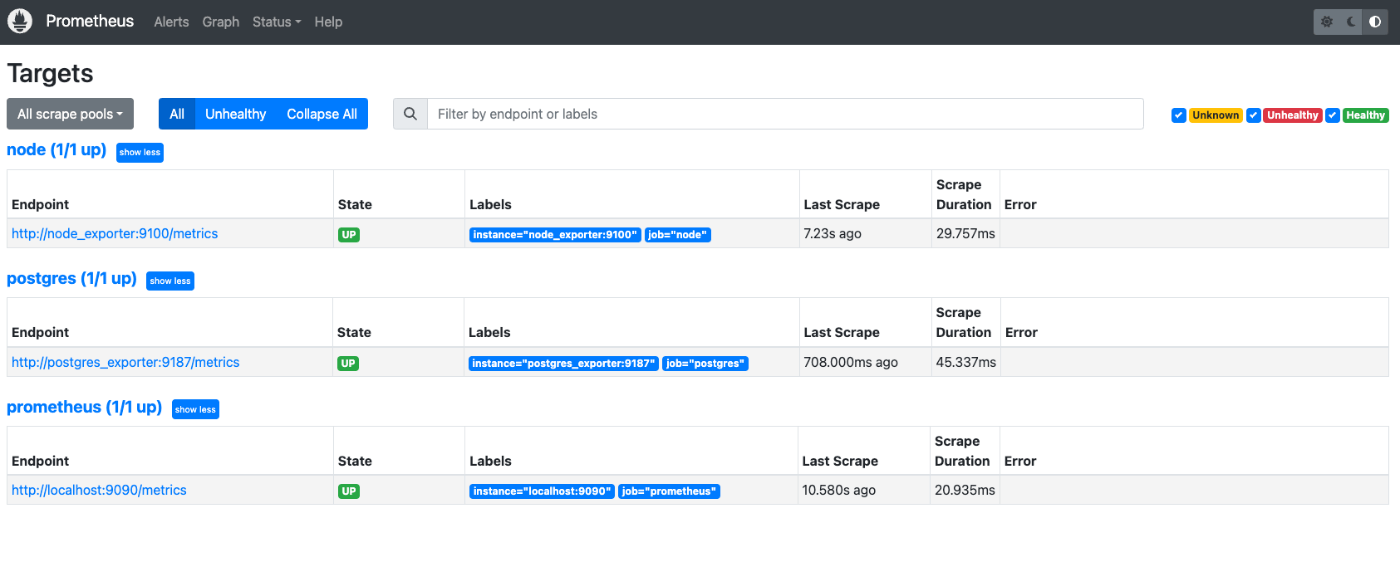
prometheusの画面を確認
以下のURLへアクセスし、監視対象一覧を確認してみます。
http://localhost:9090/targets
監視対象に登録した3つのエンドポイントが表示されていることがわかります。
StateがUPと表示されており、各サーバーが起動している状態です。
続いて、メトリクスを確認してみます。
http://localhost:9090/graph
PromQLを入力して、メトリクスを確認できます。実際に、pg_up == 1と入力し実行してみると、postgresが1件表示されました。
これは、postgresが正常に起動していれば、1として設定されており、異常であれば0となります。

grafanaの画面を確認
以下のURLへアクセスします。
http://localhost:3000/
以下の画面が表示されるので、初回はどちらもadminでログインします。
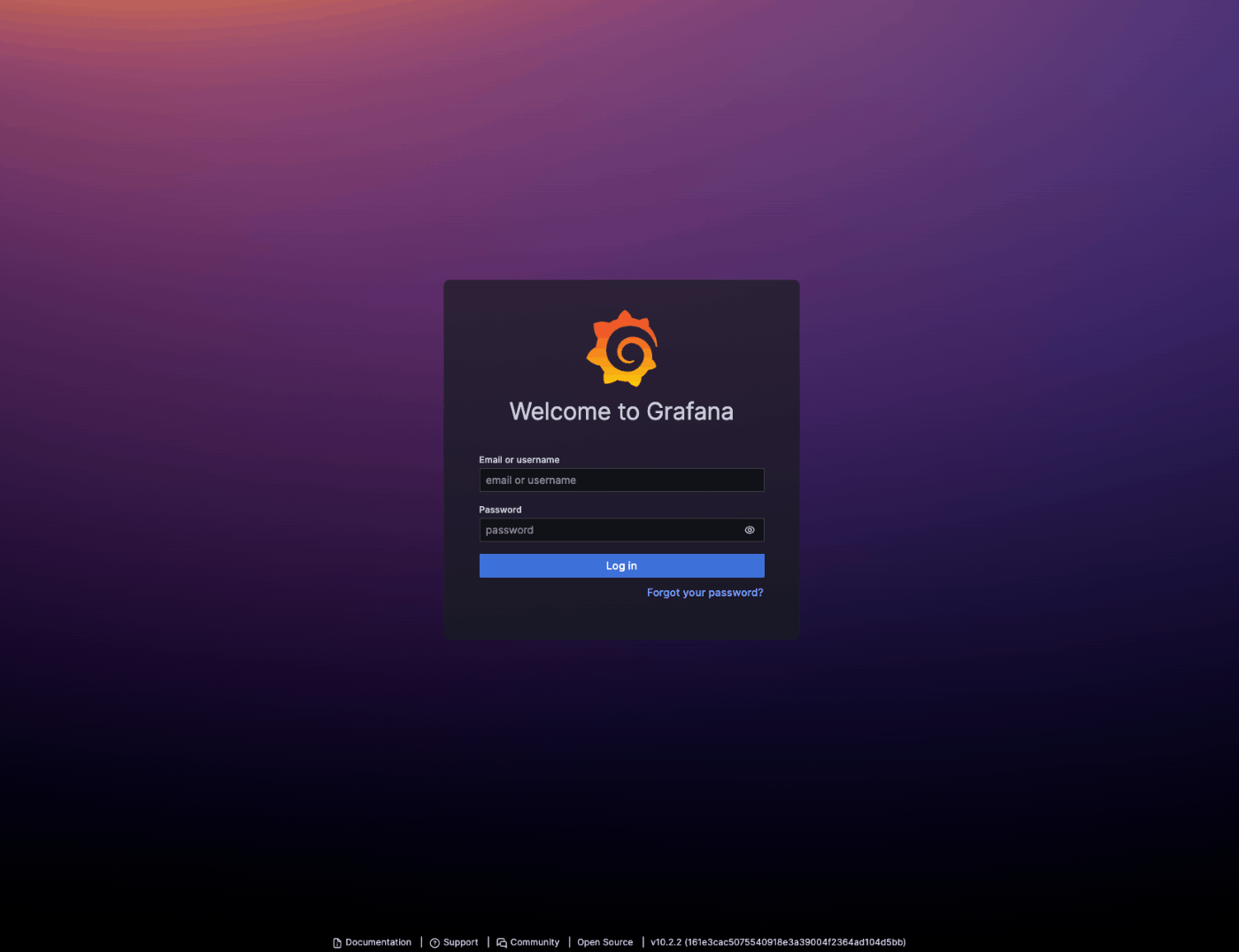
ログイン後、DATA SOURCESを選択します。
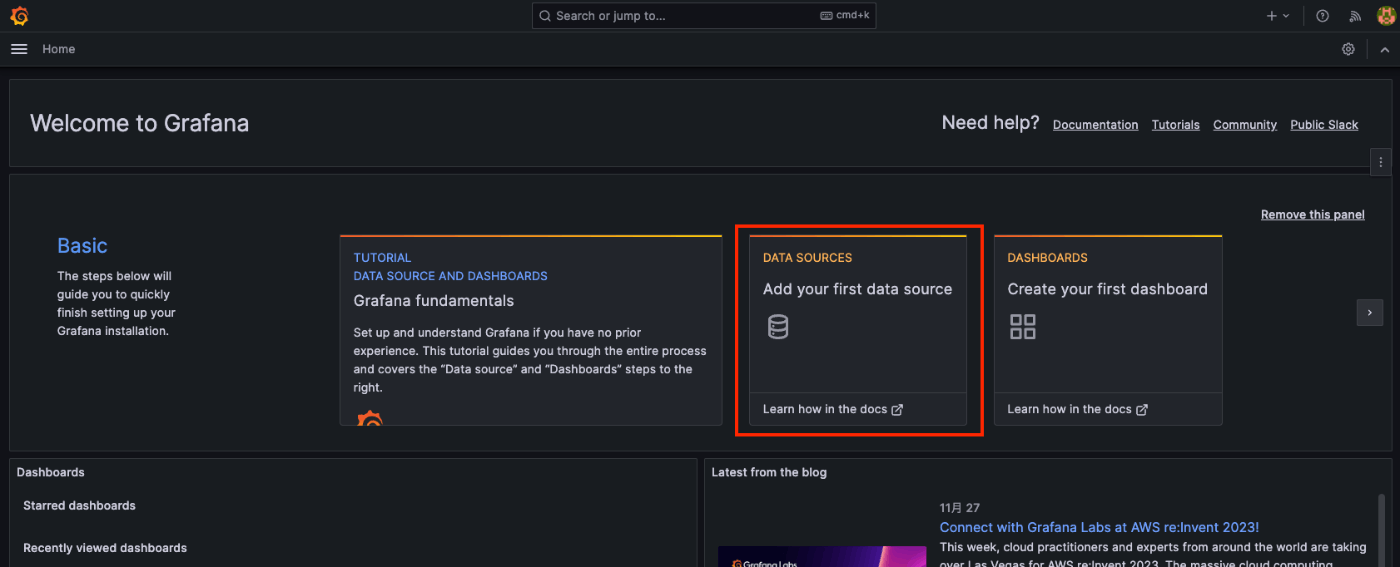
データソースにPrometheusを選択します。

先ほど立てたPrometneusのエンドポイントを登録します。
設定値は、http://prometheus:9090とします。
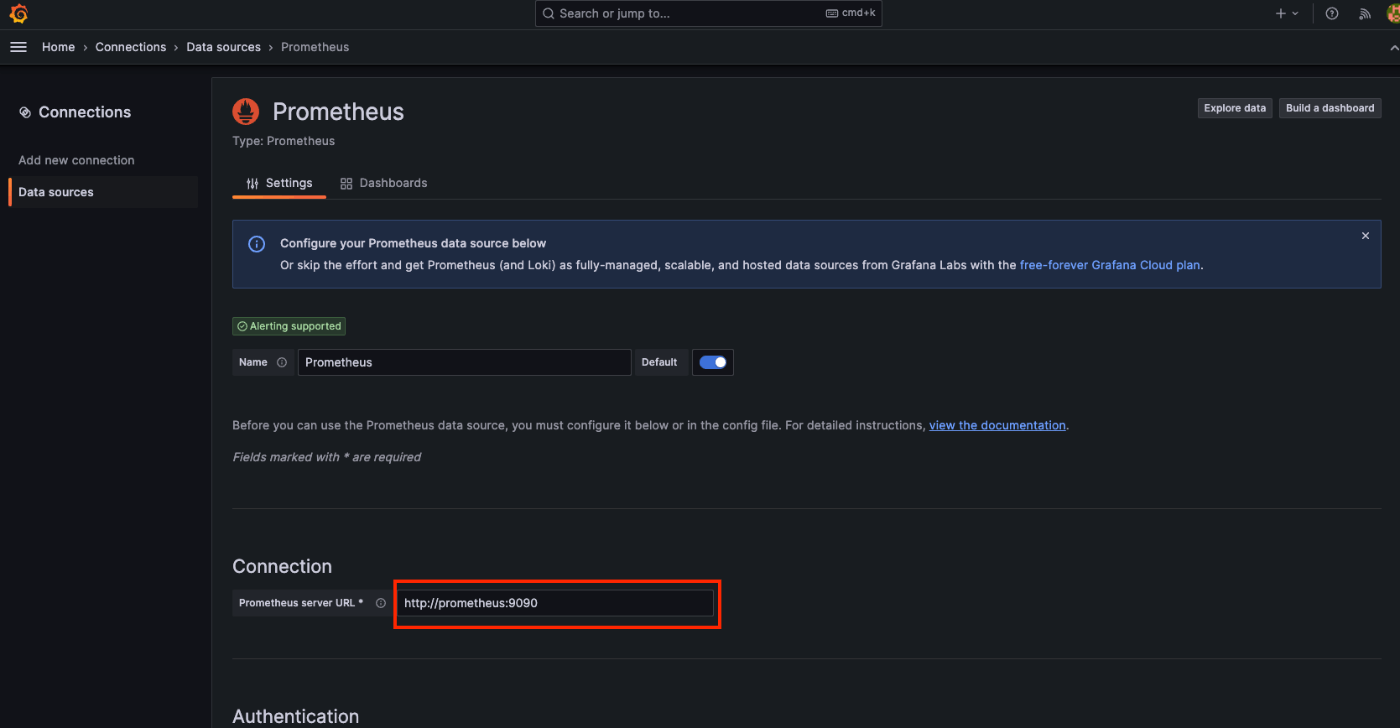
画面下部のSave & testボタンを押下すると、Successfulyという表示が出てくるとOKです。

Home画面へ戻り、ダッシュボードを作成していきます。
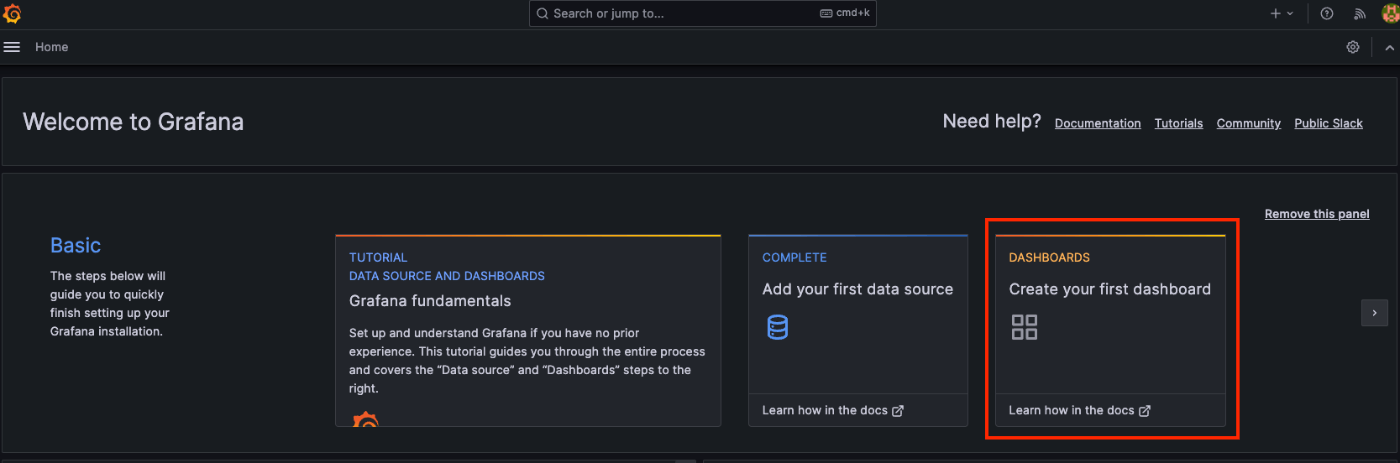
Add visualizationから新しいダッシュボードを作成します。
QueryタブのMetricから監視対象した各種メトリクスが選択できるようになっていますので、任意のメトリクスを選択し、Run queriesを実行します。
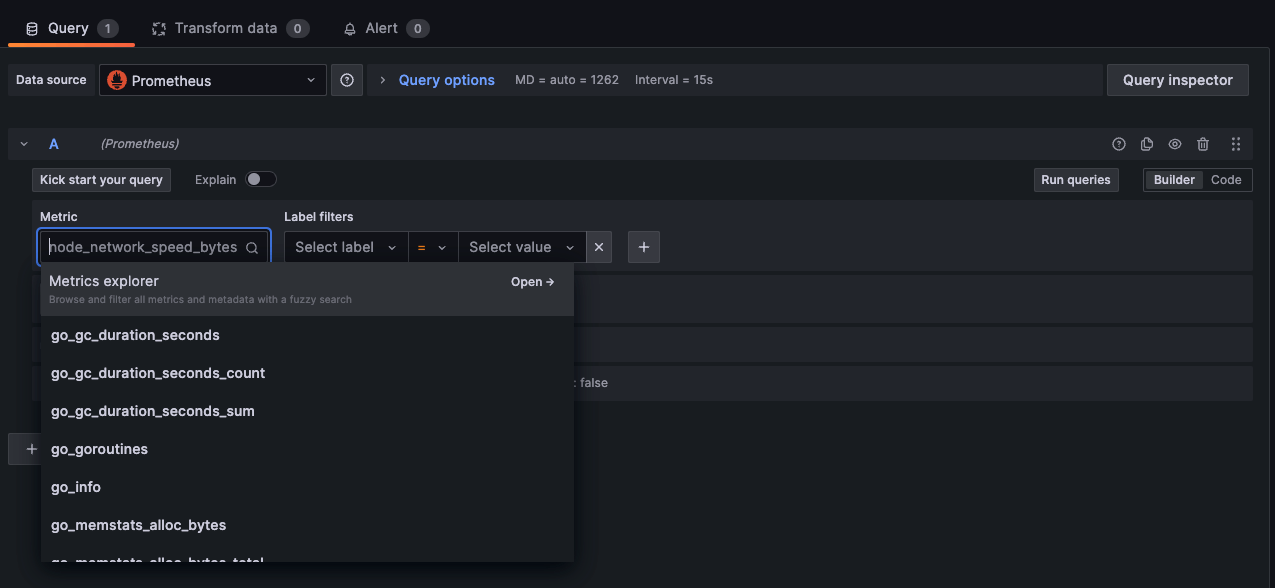
無事にメトリクスのモニタリングができました!

あとは、監視したいメトリクスをダッシュボードへ追加してやれば色々とメトリクスの監視ができそうです。
ダッシュボードについて考えてみる
さらに一歩踏み込んで、どういったメトリクスやログの情報を収集していれば、データから容易に状況や事象を正確に把握できるのでしょうか。
実際のユースケース別に考えてみます。
インフラストラクチャ
インフラ観点で発生しうる事象としては、サーバーパフォーマンスの低下やネットワーク遅延、データベースパフォーマンスなどが考えられます。
サーバーパフォーマンス
以下のようなホストメトリクスを監視して、しきい値を超えた場合にアラート通知や、OSレベルでのスケーリングを実行するといったトリガーで使用できます。
- CPU使用率
- メモリ使用率
- ディスク使用率
ネットワークトラフィック
以下のようなネットワークのメトリクスを収集し、異常な増加を検知することができれば、ネットワークの状況を把握するのに役立ちます。
- ネットワークの帯域使用率
- パケットロス率
データベースパフォーマンス
以下のようなメトリクスを収集し、可視化できればDBのパフォーマンスの低下がある場合に事象を把握できます。
- クエリ応答時間
- ディスク使用率
- 接続数
アプリケーション
マイクロサービスであれば、サービスエンドポイント毎にネットワークトラフィックが発生しうるため、アプリケーションの各エンドポイントやAPI呼び出しの応答時間やエラーレート、リソース使用状況などを監視する必要があります。
レスポンスタイム
このメトリクスにおいて、異常値がある場合は、ユーザーエクスペリエンスの低下に繋がっていきます。
根本的な原因の特定は、別のメトリクスと合わせて監視しなければいけませんが、異常な状況を把握するためには、収集して監視しておく必要があります。
- 平均応答時間
- パーセンタイル
- 応答時間の分布
エラーレート
わかりやすく、エラーとなっている割合を把握できます。
- HTTPステータスコード別のエラーレート
- リクエスト別のエラーレート
リソース使用状況
パフォーマンスに問題がある場合、キャッシュ使用率が低く、サーバーへ読み込みが発生していることも多々あります。正確にキャッシュが効いているのかを把握することで、未然にユーザーエクスペリエンスの低下を防ぐことに繋がります。また、サービス間が疎結合である場合、一部のリソースで過負荷状態となっていることがあるため、例えばサービス間でよく利用されるキューの長さを把握するといったことも必要です。
- キャッシュヒット率
- キューの長さ
さいごに
今回はマイクロサービスのオブザーバビリティについて、簡単なハンズオンも含めて書いてみました。
マイクロサービスでは、サービスが分散していることにより、従来の監視や運用方法ではうまくいかないケースもあるかと思うので、さらに深掘りして理解していきたいと思います。
ICT統括室 Advent Calendar 2023では、リクルートの社内ICTに関する記事を投稿していく予定です。もし興味があれば、ぜひ他の記事もあわせてご参照ください。
Discussion