Railsでトータル100万行超のCSVデータを取り込む処理の速度改善
現在参画中の案件で、顧客がアップロードするCSVデータを毎日所定の時刻に取り込む機能を作成したのですが、一度に取り込むデータ量がかなり多い中で、所定の時間内に実行完了しなければならないという制限もあり、パフォーマンス改善に苦労することとなりました。その際の対応の流れを振り返って整理したいと思います。
なお、今回はRailsのアプリケーションのお話になります。
取り込み対象のデータと、発生した問題
取り込み対象のデータは、顧客が管理する店舗ごとに、日毎もしくは時間毎の値を持つという内容でした。
ER図にすると下図のようなイメージです。
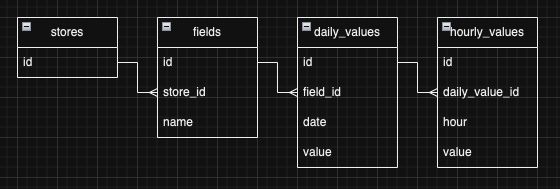
1:Nが連なっていて、かつ日次で増えていくデータなので、一度にアップされるデータ数もすごいことになっており、トータルで200万行を超えそうということがわかりました。
処理内容としてはバリデーションしてアップサートするだけみたいな感じで単純だと思っていたので、当初はそれでもなんとかなるんじゃないかと楽観していましたが、実際取り込んでみると、
- 遅延が大きく、うまくいったとしても10時間ほどかかってしまう計算
- 本番相当のデータ量で実行すると、処理が完了する前にコンテナが落ちる
- CSVとはいえ200万行ともなると、エクセルなどの表計算ソフトで開けない
といった問題が発生しました。
この問題をどうにかするべく、以下の流れで対応していきました。
対応1: ファイル、取り込みジョブの分割
上記のようにエクセルで開くことさえできないデータ量なので、全てのデータを一つのファイルにまとめることは、運用面でもリスクとなりうることがわかりました(エラー発生時とかにデータ確認する際、表計算ソフトで見れないのは辛い)。そこで、まずは顧客側でファイルを分割してアップロードしてもらうことになりました。これ以前のデータ取り込み機能は、全て1ファイルの取り込みしか行っていなかったのですが、幸い取り込みジョブの実行機構は、もとから1日の中でいくらでもスケジューリングできる仕様となっていたため、プロダクトコードはほぼ変えずに対応できました。
元々200万行超の1ファイルだったデータが、1つあたり10~20万行の10ファイル程度に分割されました。
20万行程度であればどうにかなるだろうと思って、あらためて取り込み処理を回してみたのですが、それでも1ファイルの取り込みに2時間以上かかるような状況でした。
対応2: スロークエリの改善
流石に時間がかかりすぎているので、N+1でも発生しているのかと思い調べてみたものの、ローカルで実行した限りでは怪しいクエリなどはなさそうでした。どうしたものかと悩んでいたところ、SREチームから、テスト環境で実行中に、あるクエリが数十万行のフルスキャンになっているようだと指摘をいただきました。
ちなみにこのプロジェクトではGCPを利用しているのですが、Cloud SQLのQuery Insightsを使うと、指定した期間で特に負荷が大きかったクエリがどんなものかを簡単に参照することができます。これがとても便利で、実行結果からすぐに問題のクエリを発見できました。
クエリ発行部分の処理をあらためて確認すると、IN句に大量の値がセットされる状態となっていることがわかりました。IN句の値が多すぎると、indexを貼っていてもフルスキャンされてしまいます(参考)。
そこで、IN句に渡すデータの整理(一定数毎に処理したり、重複を排除したり)を行いました。
対応3: アプリ側の処理の改善
上記の対応によりSQLクエリによる遅延はかなり改善されたものの、まだ実行中にpodが落ちてしまうことがありました。DB側の処理が改善された結果、今度はアプリサーバー側の遅延が相対的に大きくなったのではと考え、その観点で調査したところ、コードの中でかなりの数のActiveRecordインスタンスを生成している箇所がありました。
ActiveRecordインスタンスは色々な情報を内包しており、1インスタンスあたりのデータサイズが大きいため、大量に生成してしまうとメモリ負荷が高まり、動作に影響を及ぼす場合があります。
そこで、データ取得時にpluckで配列として取得し、それをHash化して保持する形に変更しました。
対応4: 時間毎の値をテーブルからJSONカラムに変更
上記の対応で十分実行可能なレベルに改善される見込みでしたが、さらにテーブル設計も見直すことになりました。
もともと時間別の値を別テーブルに保存して、日毎の値と紐づける形にしていましたが、日毎のデータにJSONカラムとして時間毎の値も保持する形に非正規化することで、DBテーブルとレコード数を削減することになりました。
前述のER図を下記の形に変更したイメージです。

テーブルからの変更でしたが、アプリ内での動作自体はほとんど変更がなく、当該クラスのActiveRecordの継承を外してDBへの書き込み部分を多少修正するだけで完了しました。
その他
上記アプリケーション側の修正の他、複数の取り込みジョブを並列に実行するための設定変更など、インフラ側でもいくつかの変更が必要でした。それらについてはSREチームが迅速に対応してくださり、こちらはアプリ側の実装に完全集中することができました。インフラをしっかり見てくれるチームがあるのは本当にありがたいです。
また、実装と並行して顧客とのすり合わせも進められていましたが、その中でデータ量が変更となり、最終的には1日あたり100万行程度となりました。都度確認しながらテストデータの作り直しなども行っていきました。
再計測
上記の対応を全て盛り込み、再計測してみた結果、最終的には全てのファイルが数分〜数十分で取り込めるようになりました!
極端に負荷が高まる部分もなくなり、途中でコンテナが落ちてしまうようなこともなくなりました。
元のパフォーマンスだと、仮に全てうまくいったとしても10時間ほどかかってしまいそうな計算でしたが、並列実行の効果もあり、想定されるデータ量に対して、2時間以内に全データ取り込めるまでに改善できました。
なお、上記は本番環境よりリソースが控えめなテスト環境での実行結果であり、その後本番で実行してみると、1時間以内に完了できていました。
振り返って思うこと
今回の対応を通して、以下のような教訓が得られました。
- データ取り込み機能の実装においては真っ先にデータ量を確認し、実行テストは本番で想定されるのと同等のデータ量、内容で行うべき
- パフォーマンス改善においては、モニタリング機能やツールで実行時の状況を確認するのが近道
- SREチームのような存在は開発においてとてもありがたい
どれも「それはそう」な内容ですが、今回あらためて大事だなと思った次第です。
また、正直なところ今回の対応以外にもまだ直せそうな点は残っていると考えており、今後も継続的な改善を行っていきたいです!
Discussion