Hono.jsを利用したブラウザプラグインログイン認証サーバーの構築
はじめに
最近、自分で開発した日本語学習サイトに、日本語文の出典にワンクリックで戻れる機能を追加しました。

カードの右上のYoutubeアイコンをクリックすると、この文に対応する動画の再生位置をすぐ戻ることができます。
それを実現した仕組みは簡単です。自分で開発したブラウザプラグインを利用し、日本語字幕をついているYoutube動画を見るとき、ctrl+cを押して、当時画面のキャプチャをAIに転送して、AIから字幕の文字をもらいます。
そして、再生位置の情報と字幕の文字をJSONの形式でクリップボードに置きます。
その後、自分の日本語学習サイトのインプットでctrl+vすれば、出典情報を記載するカードを作成できます。
ここでのポイントは、AIを使って動画のスクリーンショットから字幕を取得することです。AIを利用する際に、API KEYが必要です。ユーザーから提供することがもちろんいいんですが、計画としては、アプリとプラグインに有料のプランを導入し、課金ユーザーは無制限にアプリとプラグインを利用することができます。この計画を実現するために、プラグインに対してのログイン認証サーバーを構築することが必要です。アプリの方は当然ログイン認証APIがありますが、それはAuthJSを用いてNextJSアプリ専用のサービスなので、プラグインに対しての改造は難しいだけではなく、おかしいかもしれません。この場合、独立なバックエンドプロジェクトを作る方が自然だと思います。
技術選定としては、最近流行ってるHono.js+Cloudfare Workersを採用しました。Authについて、Auth.jsなどライブラリーを利用しなくて、自分で主なロジックを書います。
Authライブラリを利用しない理由は二つあります:
- Authの基本的な仕組みがある程度理解できます
- Auth.jsなどAuthライブラリはCloudfare Workers環境では利用できない可能性が高い
(Cloudfare WorkersはV8に基づいているため、NodeJS APIには完全にサポートしていません)
ブラウザプラグインでのSSOの仕組み
主な流れとしては以下です:
- popup画面でGoogleログインボタンを押す
- 新しく構築したバックエンドサーバーの/auth/google/loginにリクエスト
- サーバーからauthorizationUriをもらいます(authorizationUriはGoogleのauth画面)
- popup画面で新しいタブを開く、Googleのauth画面を表示します
- ユーザーが認証した後、自動的に新しく構築したサーバーの/auth/google/callbackルートにリダイレクトされます
- /auth/google/callbackルートのリクエストのpayloadで、Googleからのユーザー情報(ユーザー名、プロファイル、メールアドレス、ユーザーID)がもらいます
- GoogleのユーザーIDを利用して、うちのシステムで存在するかどうかをチェックします。もし存在しないなら、自動的に登録します。存在するの場合、ユーザー情報を取得し、暗号化した後にJWTを作成し、レスポンスヘッダーにSet-Cookieディレクティブを追加して、クライアントにJWTをクッキーに保存させます
- クライアントはレスポンスをもらったら、ディレクティブに従ってユーザー情報を含んでいるJWTをクッキーに保存します
- クライアントは/api/user/infoルートにリクエストする時、Cookieは自動的に付いているから、サーバー側はJWTを取得できます
- サーバー側はJWTを復号してユーザー情報を取り出し、クライアントに返します
- プラグイン側はユーザーの課金状況を取得できてます
結構長いプロセスですね。それに、いくつか細かいところを理解することが必要です。
loginリクエストでは、何の処理を行われていますか
簡単に言えば、GOOGLE_CLIENT_ID・GOOGLE_CLIENT_SECRET・redirectUriを利用してauthorizationUriを生成します。
authorizationUriはGoogleの認証画面です。
GOOGLE_CLIENT_IDとGOOGLE_CLIENT_SECRETについて、Google Cloud ConsoleのAPIとサービスの認証情報画面で、認証情報を作成ボタンをクリックし、OAuth クライアント ID の作成を選択して、自分のアプリ情報を入れば取得できます。

こちらで注意することが必要な部分は「承認済みの JavaScript 生成元」と「承認済みのリダイレクト URI」の設定です。
「承認済みの JavaScript 生成元」は認証サービスのドメインです。「承認済みのリダイレクト URI
」はcallback APIのアドレスです、自分でAPIを実装する場合はもちろん自分で決めますが、AuthJSを使う場合はデフォルトでアプリのドメイン+/api/auth/callback/google になります。
最初に言ったredirectUriと「承認済みのリダイレクト URI」は同じものです。
今、入力はすでにわかっている状態で、authorizationUriを出力するコードはAIに任せればいいと思います。このへんの仕組みについて筆者は特に調べていません、知る限りはsimple-oauth2というライブラリーを利用するだけです。
もしコードを参考したいなら、筆者のコードは以下です(/auth/github/loginを検索してください)
もう一つは、Googleはそういう風に設定していますが、異なるプラットフォームは設定方法は異なります。
例えば、GithubではGoogleのような一つアプリで複数のドメインを対応させることはできません。そのため、せめてローカル環境に一つアプリ、本番に一つアプリを申請することが必要です。もちろん、テスト環境や他の認証サーバーがあれば、それに対応するアプリを申請しなければならないです。
あと、Githubでは具体的なcallbackパスを指定しなくてもいいし、ドメインだけを入力すればいいです。
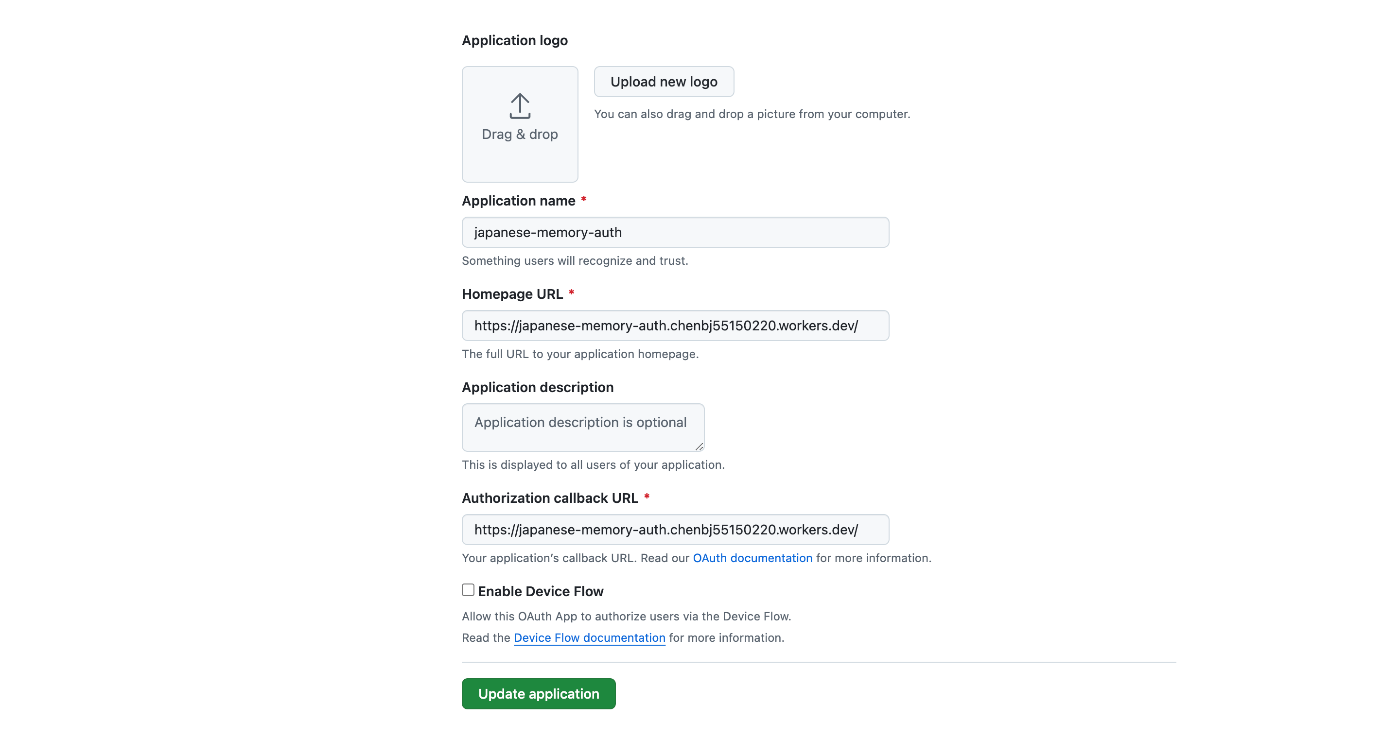
設定画面はこちら
callbackリクエストでは、何の処理を行われていますか
callbackに到達したということは、authorizationUriの生成やGoogleなどでの認可処理が問題なく完了したことを示しています。
もしこの前のステップで問題が発生した場合、原因は以下と考えられます:
- GOOGLE_CLIENT_IDやGOOGLE_CLIENT_SECRETの環境変数を正しく読み取れない
- コードの中のredirectUriの設定が実際のcallbackサービスのパスと一致していない
- Google Cloud Consoleでの設定が違ってます
全部あってる場合は、callbackフローは進行します。
前にcallbackの三つの役割について述べました:
- Googleユーザー情報を取得する
- ユーザー情報を暗号化してJWTを作成する
- レスポンスにSet-Cookieディレクティブを追加して、クライアントにJWTをCookieに保存させます
しかし、Googleユーザー情報の取得は直接行われるではなく、重要な中間プロセスがあります:
- Google認証画面で認証成功したあとは、自動的にcallbackパスにアクセスします。このリクエストのクエリでcodeを付いています。
- GoogleのAPIを呼び出し、codeを使ってトークンを交換します。
- GoogleのAPIを呼び出し、トークンを認証情報として使用し、Googleユーザーデータを取得します。
以上のプロセスはAuthJSが全て処理してくれますが、AuthJSはCloudflare Workersの現時点(2025年2月)未対応のNode.js APIを使用しているため、Cloudflare Workers にはデプロイできません。
だから筆者の場合はAIに任せました、参考したいならコードは以下です(/auth/google/callbackを検索してください)
セッション/JWT/SameSite/CORS/CSRF Token個別の役割
筆者の実装としては、ログイン状態(セッション)を暗号化してJWTに格納し、通常そのJWTをクライアントのクッキーに保存しています。
実際それは唯一の方法ではなく、セッションをRedisやDBに保存することもよくあります。もしろ、セッションをRedisやDBに保存する方が細かいところまで管理できるかもしれません。
でも、JWTに格納することは相対的に簡潔な解決策です。ここで、注目すべきポイントは、Cookieの属性設定です。
筆者の場合は以下です:
{
httpOnly: true,
secure: true,
sameSite: 'None',
maxAge: 7 * 24 * 60 * 60
}
httpOnlyを設定すると、このCookieはJSから読み取れず、対応するドメインへのリクエスト時に自動的に付与されます。この対策の意図は、JWTが第三者のスクリプトによって読み取られるのを防ぐことです。当然JWTは暗号化されており、暗号化に使うJWT_SECRETもサーバー側で保存しているし、簡単に解読できませんが、それでも取得されない方がより安全です。
secureの意味はHTTPSのみです。
sameSiteは大事なことです。この属性は三つ可能値があります:
- "Strict":
a. 認証サーバー以外のドメインからのリクエストはCookieを付与されない。
b. 他のドメインから、うちのサーバーに遷移でもCookieを付与されない。
c. 他のドメインの操作によって、新しいタブでうちのサーバーにアクセスでもCookieを付与されない。
d. でも、ユーザー自分でアドレスバーでうちのサーバーのAPIルートにアクセスする場合はCookieを付与されます。 - "Lax":
a. 認証サーバー以外のドメインからリクエストはCookieを付与されない。
b. 他のドメインから、うちのサーバーアドレスに遷移の場合はCookieを付与されます。
c. 他のドメインの操作によって、新しいタブでうちのサーバーにアクセスの場合はCookieを付与されます。
d. ユーザー自分でアドレスバーでうちのサーバーのAPIルートにアクセスする場合はCookieを付与されます。 - "None":
基本的に全てのリクエストはCookieを付与されます。
上記のまとめから、Laxは意外と厳しいかも。Laxの場合許せることは今のWebアーキテクチャではあんまり意味ないと思います。
自分の要件に対し、プラグインからajaxリクエスト形式でユーザー情報を取得することが必要だから、"None"を指定しないといけないです。
でも、"None"を指定すると、何のドメインでもログイン状態を含んでいるCookieを利用できるし、CSRF攻撃受けやすいです。
例えば、攻撃者は悪意を持ちのサイトと作って、その中にうちのサーバーへのリクエストがあります。うちのサイトにログイン済みのユーザーは騙されてその悪意サイトにアクセスすると、CSRF攻撃が実現しまいました。CookieのsameSite設定は"None"なので、悪意サイトのリクエストでも付与されます。サーバー側はCookie内のJWTを利用して身分認証を行っていますので、悪意サイトのリクエストにユーザー情報を返しまいます。
それを防ぐのもそれほど難しくはありません、CORS設定でプラグインのドメインを指定すれば済みます。
悪意サイトのドメインは当然プラグインのドメインと違いますから、ブラウザがリクエストのレスポンスを受け取るのをブロックします。
ここで大事な一点は、悪意のあるリクエストは問題なく受け取りました、サーバー側でレスポンスも正常に返されました。ブラウザはそのレスポンスを悪意サイトに渡すことをブロックしているだけです。
SameSiteの設定とCORSの設定は非常に混同しやすいです。また、両方を組み合わせて使用する必要がありますが、それぞれの役割は全く異なることを理解しておく必要があります。
SameSiteの設定は、Cookieを付与されるかどうかを決めます。CORSの設定はレスポンスをアプリに渡れますかどうかを決めます。
実際、CORSの設定は結構意味深いです。この例としては、悪意サイトは何の情報も取得できないですが、悪意リクエストは受け入れました!
このAPIは認証とユーザー情報を返すだけだから大丈夫ですが、もし支払いや注文のようなAPIの場合、悪意サイトはリクエストの結果が見えないですが、攻撃本体は成功に実施しました。
従って、CORSポリシーだけでは不十分で、CSRF攻撃を防ぐためにはCSRFトークンが必要です。
CSRFトークンを利用するプロセスは以下です:
- クライアントはCSRF token APIにリクエストする
- サーバー側はCSRF tokenを生成して、Set-Cookieディレクティブをレスポンスに追加し、同時にtokenをクライアントに返します
- ブラウザがSet-Cookieディレクティブに従って、CSRF tokenをCookieに保存します
- フロントエンド開発者はサーバーからもらったCSRF tokenを保護されているAPIへのリクエストのheadersに追加して送信します
- サーバー側はheadersに書いてあるCSRF tokenとCookieに書いてあるCSRF tokenを比較して、両方あるかつ同じの場合のみ認証成功です
それすれば、普通なCSRF攻撃は防げます。悪意サイトのドメインはCORS設定値以外なので、CSRF tokenを取得できません。そのため、保護されてるAPIへの認証が通過することができません。
Cloudfare Workersにデポロイする
HonoJSプロジェクトをCloudfare Workersにデポロイしたいなら、大体三つが必要です。
- アプリのエントリーポイントを作ります(worker.ts作成と関係の設定)
- 環境変数の設定
- swrangler.tomlを設定
Workers環境はenv.processは利用できないです。まずCloudfare Workersにプロジェクトをプッシュし、プラットフォームのWorkers & PagesのSettingsのVariables and Secretsで環境変数を設定することが必要です。
OPENAI API KEYを漏洩しないような設計
簡単に言うと、OPENAI API KEYを漏洩しないように、OPENAIへのリクエストはサーバー側で実行すれば済みます。
問題は、ログインと異なり、OPENAI APIへのリクエストの発生場所はcontent.jsです。
content.jsからのリクエストの場合、ドメイン判定結果はプラグインではなく当時の画面のドメインです。当時の画面のドメインはもちろんCORSリスト以外なので、自分のサーバーのレスポンスを取得できないです。そのため、content.jsとbackground.js間で通信を行い、background.js から自分のサーバーへのリクエストを送る必要があります。
content.jsとbackground.js間で通信する際に注意すべきのは、通信データはシリアライズされるため、渡すデータが正常にシリアライズ可能な形式であることに注意する必要があります。
ちなみに、プラグインのアイコンをクリックすると表示されるメニュー画面でのpopup.jsからのリクエストを送る場合は、プラグインのIDに対応するドメインとして判定されます。
まとめ
プラグイン向けのログインサーバーの構築は意外と知識量が多いです。この辺経験がないなら、似たようなポロジェクトを構築して経験を積むことは良い選択肢と思います。
プラグインリポジトリ:
認証サーバーリポジトリ:
Discussion