GPT-4o:より強く、より使いやすく、よりユーザーフレンドリーに、AIツールの新時代をリードする



2024年5月14日:OpenAIが最新のフラッグシップモデルGPT-4oを正式に発表しました。このモデルは、音声、視覚、およびテキストを横断してリアルタイム推論を行う能力を備えています。
GPT-4o(「o」は「omni」を意味する)は、より自然な人間と機械のインタラクションを実現する大きな進歩を示しています。このモデルはテキスト、音声、画像の任意の組み合わせを入力として受け取り、同様に多様な組み合わせを出力できます。音声入力には最短232ミリ秒、平均応答時間320ミリ秒で反応し、人間の対話における反応時間に似ています。英語およびプログラミング処理においてGPT-4 Turboと同等の性能を持ち、非英語のテキスト処理においては著しい向上が見られます。さらに、GPT-4oはAPIでの実行速度が速く、コストが50%削減されました。視覚および音声の理解能力において、GPT-4oは既存のモデルを明らかに上回っています。
GPT-4oの前には、ユーザーはChatGPTと対話するための音声モードを使用できましたが、平均遅延時間はGPT-3.5で2.8秒、GPT-4で5.4秒でした。この音声モードは、音声をテキストに転写するシンプルなモデル、テキストを受け取ってテキストを出力するGPT-3.5またはGPT-4、そしてテキストを再度音声に変換するシンプルなモデルの3つの独立したモデルを統合していました。このプロセスにより、GPT-4はイントネーション、複数の話者の声、バックグラウンドノイズなどの情報を直接理解できず、笑いや歌、感情の表現なども出力できませんでした。
現在、OpenAIはエンドツーエンドでトレーニングされた新しいモデルGPT-4oを導入し、テキスト、視覚、および音声をカバーしています。これにより、すべての入力および出力が同じニューラルネットワークによって処理されます。GPT-4oはこれらのすべてのモーダリティを統合した最初のモデルであるため、チームはモデルの能力と限界をまだ探求中です。
モデル評価
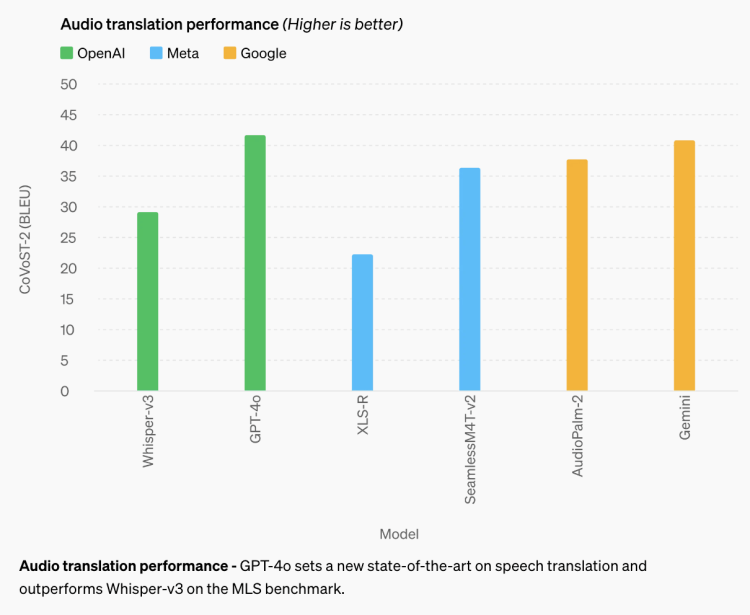
従来のベンチマークテストによると、GPT-4oはテキスト、推論、およびプログラミングのインテリジェンスにおいてGPT-4 Turboレベルのパフォーマンスを達成し、マルチリンガル、音声、および視覚能力において新たな高基準を設定しています。
改良された推論能力:GPT-4oは、MMLU(多肢選択汎知識問題テスト)の5回の試行で87.2%の新記録を達成しました。
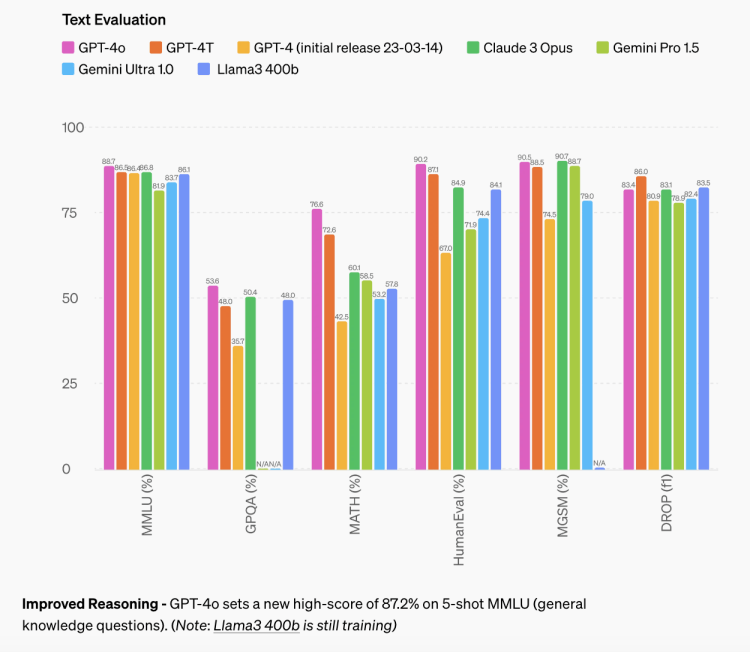
音声ASRパフォーマンス:GPT-4oはすべての言語で音声認識性能を著しく向上させ、特に資源が乏しい言語においてWhisper-v3よりも大幅に改善されました。
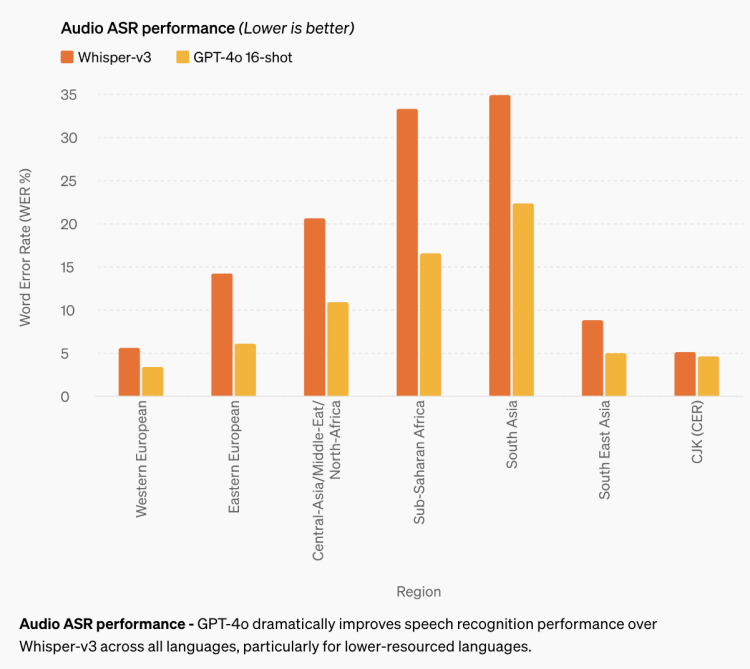
音声翻訳性能:GPT-4oは音声翻訳において新たな業界標準を設定し、MLSベンチマークテストでWhisper-v3を上回るパフォーマンスを示しました。
M3Exam評価:M3Examベンチマークは、多言語および視覚評価を同時にカバーし、他国の標準化テストからの多肢選択問題を含み、時には図表や示意図も含まれます。すべての言語において、GPT-4oはこのベンチマークでGPT-4を上回るパフォーマンスを示しました。
視覚理解評価:GPT-4oは視覚認識ベンチマークで業界最高のパフォーマンスを達成しました。
言語トークナイザ

新しいトークナイザの圧縮改良の代表として、20の言語が選ばれました。(以下に中国語の圧縮パフォーマンスを含む)

モデルの安全性と限界
GPT-4oは様々なモダリティにおいて安全性を内蔵するよう設計されており、トレーニングデータのフィルタリングや後トレーニングによるモデルの行動改善技術を採用しています。OpenAIはまた、音声出力に保護対策を提供する新しいセキュリティシステムを構築しました。

OpenAIは「準備フレームワーク」と自発的なコミットメントに基づいてGPT-4oを評価しました。サイバーセキュリティ、化学・生物・放射線・核(CBRN)、説得力、およびモデルの自律性に関する評価は、これらのカテゴリにおけるリスクレベルが中程度を超えないことを示しています。この評価には、モデルトレーニング中に一連の自動および手動評価が含まれています。チームはまた、モデルの安全対策前後のバージョンをテストし、カスタムの微調整およびプロンプトを使用してモデルの能力をより良く誘導しました。
GPT-4oはまた、社会心理学、偏見と公正、および誤情報などの分野で70人以上の外部専門家による広範な外部レッドチームテストを受け、新しく追加されたモダリティによって引き起こされるまたは拡大されるリスクを特定しました。そして、これらの学習成果を利用して、安全介入策を確立し、GPT-4oとのインタラクションの安全性を向上させました。
チームはまた、GPT-4oの音声モダリティが複数の新しいリスクをもたらす可能性があることを認識しています。本日、OpenAIはテキストおよび画像の入力とテキスト出力を公開しました。今後数週間および数ヶ月にわたり、技術インフラストラクチャ、後トレーニングによる使用性の向上、および必要な安全性を確保するために取り組み、他のモダリティをリリースする予定です。例えば、リリース時には音声出力は一組のプリセットされた声に限定され、既存の安全ポリシーに従います。OpenAIは、今後リリースされるシステムカードで、GPT-4oの様々なモダリティに関する詳細を共有する予定です。
モデルのテストと反復を通じて、モデルのすべてのモダリティに存在するいくつかの制限が観察されました。
OpenAIは、ユーザーからのフィードバックを歓迎し、GPT-4 TurboがGPT-4oを上回るタスクを特定し、モデルを継続的に改善していくために役立てます。
モデルの可用性
GPT-4oは、OpenAIが深層学習分野で実用性の限界を押し広げる最新のステップです。過去2年間、チームは技術スタックのあらゆるレイヤーで大規模な効率改善作業を行ってきました。この研究の最初の成果として、より広範にGPT-4レベルのモデルを提供することが可能になりました。GPT-4oの機能は段階的に展開されます(本日より拡張されたレッドチームアクセスを提供)。
GPT-4oのテキストおよび画像機能は本日よりChatGPTで提供されます。GPT-4oはすべての無料ユーザーに提供され、Plusユーザーには最大5倍のメッセージ制限が適用されます。今後数週間以内にChatGPT Plusで新しい音声モードがアルファ版で提供されます。開発者は今すぐAPIでGPT-4oをテキストおよびビジュアルモデルとして利用できます。
GPT-4oはGPT-4 Turboより2倍速く、価格は半分、速度制限は5倍です。OpenAIは、今後数週間内に信頼できるパートナーの小グループにGPT-4oの新しい音声およびビデオ機能を提供する予定です。
Discussion