最低限のコードで 1時間の音声ファイルをOpenAI に自動要約・翻訳させる(Node.js)



はじめに
海外Podcastを聞くのが好きなのだが、「聞く前に先に要約をテキストで読みたいなー」と思ったので作ってみた。OpenAI周りのドキュメントは Python ばかりで、Javascript のものが少なかったのでまとめてみる。
先に断っておくと、これは海外の方の実装法を徹底的にマネしたものである。英語がわかる人はこちらを参照してほしい。元動画は 15分以下の音声メモを Notion に要約してまとめる、という実装。元動画のコードでは1時間の音声ファイルは対応できないので注意(同じ方のこの記事も主に参考)。個人的に動かすのに苦労したポイントを日本語で纏めてみる。
ちなみに最低限のコードというタイトルだが、それでもコードは結構書いた。笑
使用したツール
・Pipedream https://pipedream.com/
・Google Drive
・Node.jsとJavaScript
・Whisper APIおよびOpenAI API
Pipedream は、ノーコードでのワークフロー自動化を実現するためのツールだ。類似製品では、Zapierがあるが、無料で結構な複雑なフローを組めるのと、OpenAI API をGUIで呼び出せるので、コード量を減らすのに大きく貢献してくれた。
大体のサービスとワンクリックで繋がる
組んだワークフロー全体
- Google Drive に音声ファイルを upload することをトリガーにする
- Pipedream が Google Drive にアクセスし、音声ファイルを取得
- Whisper API で文字起こししてもらう
- 3 の出力結果を(プロンプト上限にひっかからないよう)複数チャンクに分けて、OpenAI に要約させる
- 複数チャンクに分けた文章を再度一つのテキストデータにまとめる
- 5.をOpenAIで翻訳
- 4,6 をメールに結果を出力
コードが必要かつ難しかったのが、4,5 だ。
音声ファイルをテキストに変換
Pipedream ではOpenAIはネイティブに繋がる。エンドポイントと API Key を入力し、MP3などのファイル形式を指定して"Create_Transcription"を選択すれば自動で Whisper API が呼ばれて文字起こしができる。
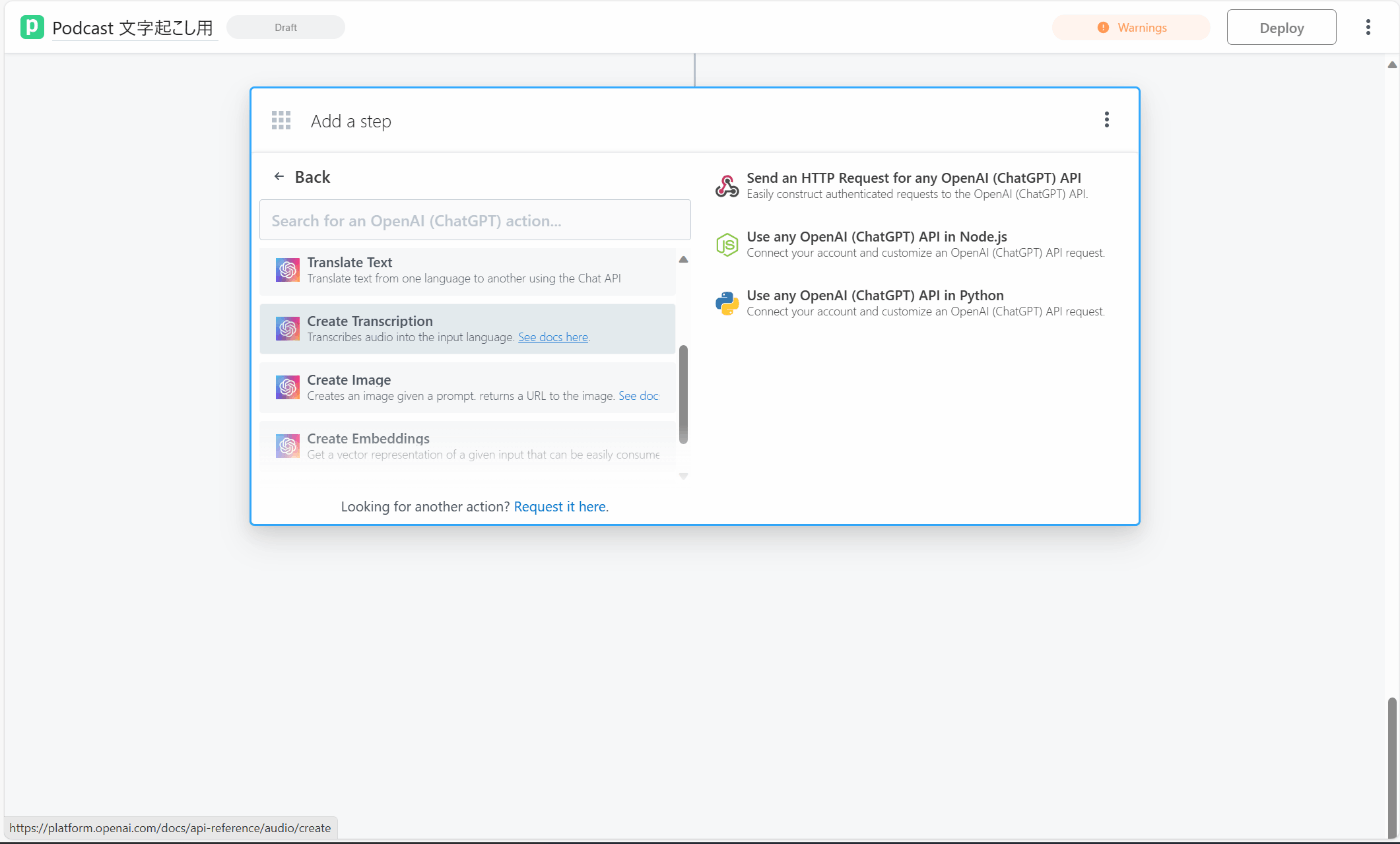
Create_Transcription を選択すると Pipedream側でデフォルトで設定されている文字起こしのプロンプトを使える
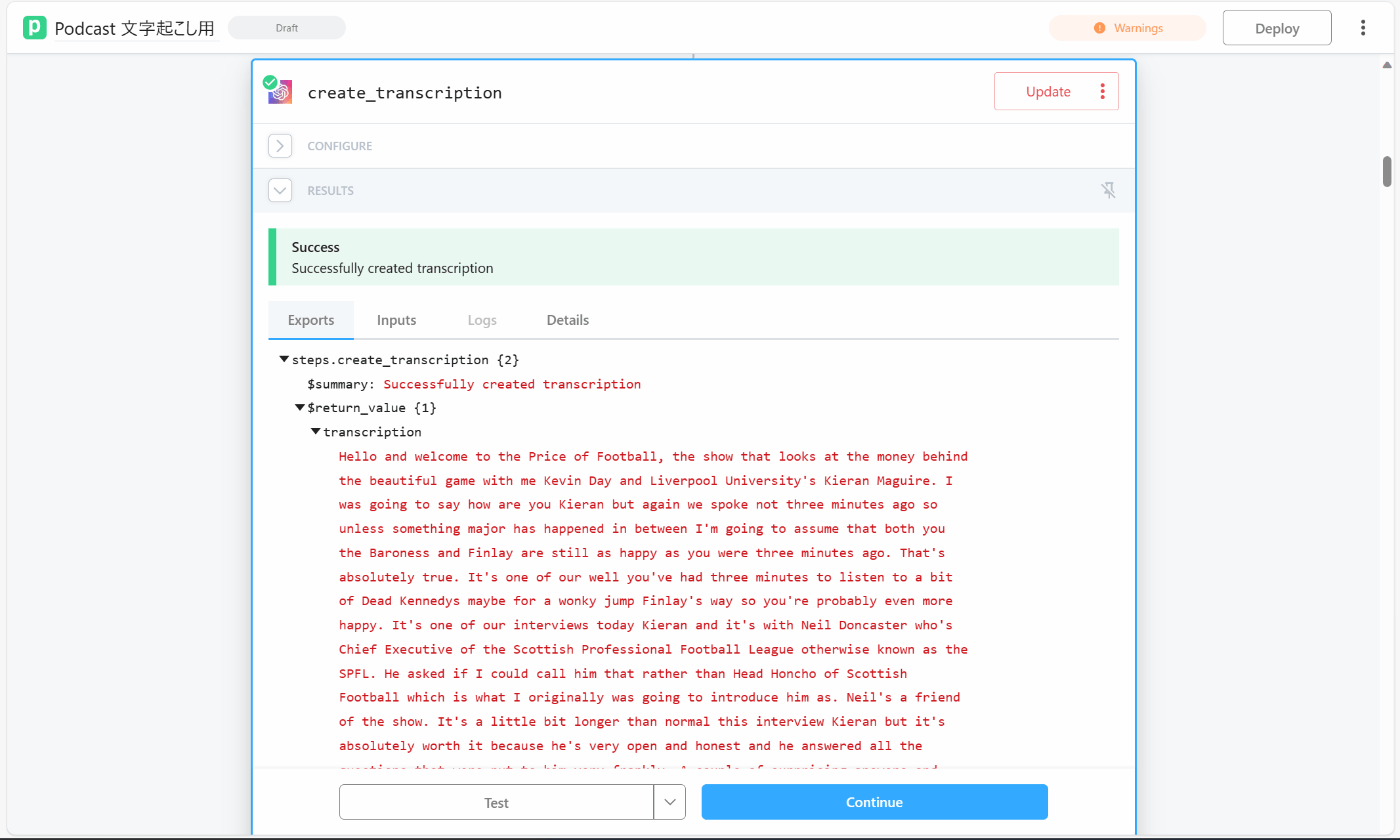
問題なく動いたらこのように文字起こしが出力される。ここまでコード無し。
(コード)OpenAI APIを使用してテキストを要約する
15分のPodcastならこのままChatGPTに要約してもらって問題ないのだが、自分が聞く1時間のPodcastは文字数が9000文字強。APIのトークン上限にひっかかってしまう。そのため、文字起こしを
上限ギリギリの文字数に分割し、ChatGPTへのリクエストを複数回に分けることでその制約を突破する。
ざっくりやることとしては、
・文字起こしをインポート
・トークン上限を指定
・文字起こしを指定トークン数以下になるよう分割。配列形式で保存。
・分割した要素をプロンプトと共に OpenAI に送信・要約してもらう。
・ChatGPTからの応答をJSON形式の文字列で受け取る
・ChatGPTからの各応答を配列に格納
再掲だが英語がわかる人はこちらを参照してほしい。
async run({steps, $}) {
// 前ワークフローで出力した文字お越しデータのパスを指定
const transcript = steps.create_transcription.$return_value.transcription
// トークン上限にひっかからないようMAX Tokenを指定
const maxTokens = 2500
// 文字起こしを指定した上限を基に分割する関数を作成
function splitTranscript(encodedTranscript, maxTokens) {
const stringsArray = []
let currentIndex = 0
while (currentIndex < encodedTranscript.length) {
let endIndex = Math.min(currentIndex + maxTokens, encodedTranscript.length)
// 次のピリオドを見つけるまで分割する
while (endIndex < encodedTranscript.length && decode([encodedTranscript[endIndex]]) !== ".") {
endIndex++
}
if (endIndex < encodedTranscript.length) {
endIndex++
}
// 分割した文章チャンクを配列に追加
const chunk = encodedTranscript.slice(currentIndex, endIndex)
stringsArray.push(decode(chunk))
currentIndex = endIndex
}
return stringsArray
}
const encoded = encode(transcript)
const stringsArray = splitTranscript(encoded, maxTokens)
const result = await sendToChat(stringsArray)
return result
// 文字おこしをChatGPTに送る
async function sendToChat (stringsArray) {
const resultsArray = []
for (let arr of stringsArray) {
// プロンプトをテキストでベタ打ち
const prompt = `(プロンプト)`
// OpenAI ChatCompletion API にプロンプトを送る
let retries = 5
while (retries > 0) {
try {
const completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [{role: "user", content: prompt}, {role: "system", content: "You are an assistant that only speaks JSON. Do not write normal text."}],
temperature: 0.2
});
resultsArray.push(completion)
break
}
}
}
return resultsArray
}
},
})
プロンプトはこんな感じ
Analyze the transcript provided below, then provide the following:
Key "title:" - add a title.
Key "summary" - create a summary. Limit the summary to 100 words.
Key "main_points" - add an array of the main points. Limit each item to 50 words, and limit the list to 5 items.
Example formatting:
{
"title": "Football Mania",
"summary": "A collection of Topics for this week's football",
"main_points": [
"item 1",
"item 2",
"item 3"
]
}
Transcript:
${arr}`
これで無事にチャンクに分かれたレスポンスValueが出力され、文章が分かれた形でPodcast全文が要約できた。

Warningが出るけど動作への影響は観測していない
(コード)複数チャンクに分けた文章を一つのテキストデータにまとめる
さて、OpenAIへのリスエストを複数回に分けたので、別々のオブジェクトからAPIからのレスポンスが来ている。最終結果を出力する前に、再度単一のオブジェクトにChatGPTからの回答をまとめる。
ざっくりやることは下記
・各JSON文字列が正しくフォーマットされているかをチェック。
・戻り値オブジェクトを構築。
・各JSONオブジェクトから取得した各要素を最終オブジェクトに追加。
export default defineComponent({
async run({ steps, $ }) {
const resultsArray = []
for (let result of steps.openai.$return_value) {
let jsonObj
try {
jsonObj = JSON.parse(cleanedJsonString)
}
const response = {
choice: jsonObj,
usage: !result.data.usage.total_tokens ? 0 : result.data.usage.total_tokens
}
resultsArray.push(response)
}
const chatResponse = {
title: resultsArray[0].choice.title,
summary: [],
main_points: []
}
for (let arr of resultsArray) {
chatResponse.summary.push(arr.choice.summary)
chatResponse.main_points.push(arr.choice.main_points)
}
function arraySum (arr) {
const init = 0
const sum = arr.reduce((accumulator, currentValue) => accumulator + currentValue, init)
return sum
}
const finalChatResponse = {
title: chatResponse.title,
summary: chatResponse.summary.join(' '),
main_points: chatResponse.main_points.flat(),
}
return finalChatResponse
},
})
翻訳・メールで出力
残りはGUIベースで設定できたので、スクショを貼っておく
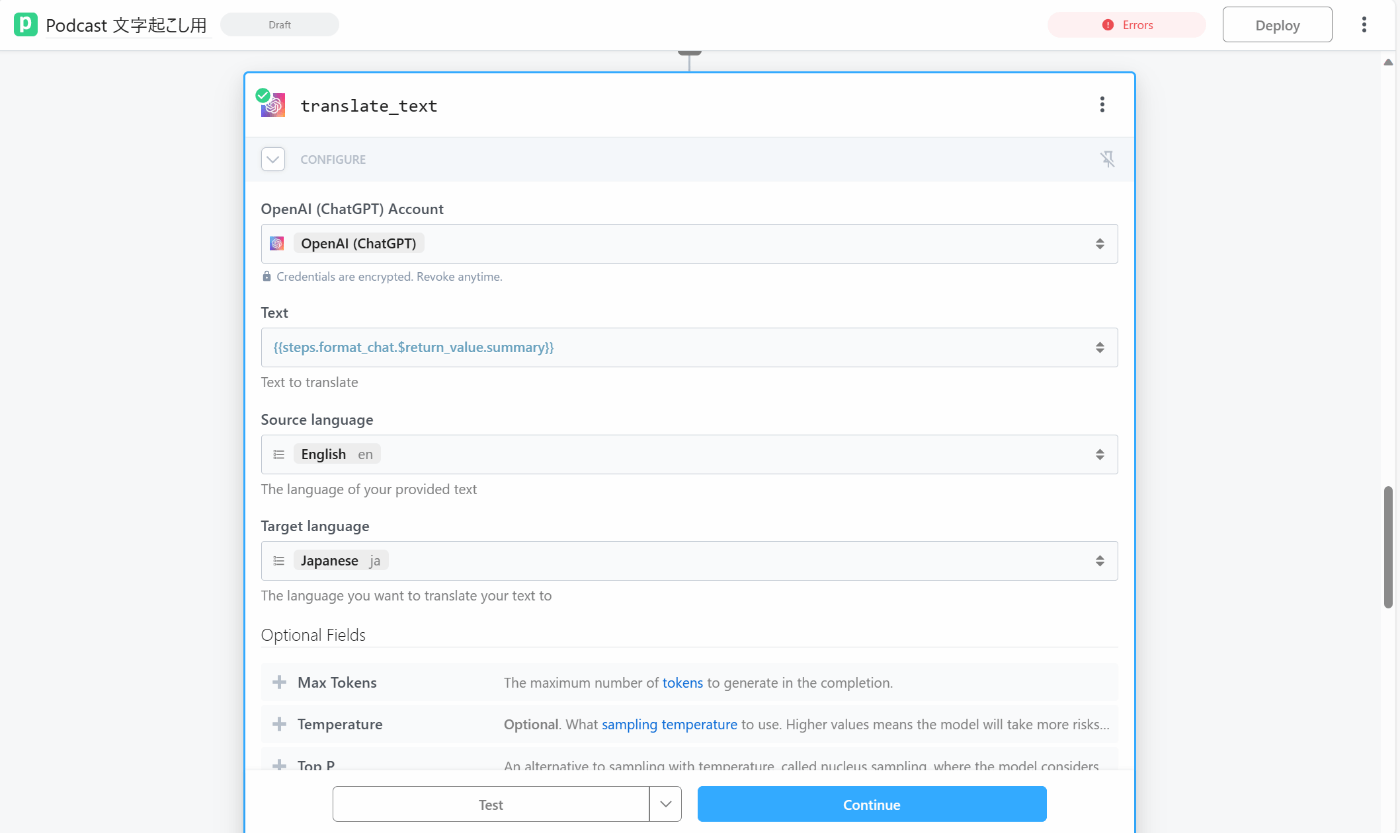
翻訳のプロンプトもネイティブに選択できるPipedream 優秀である
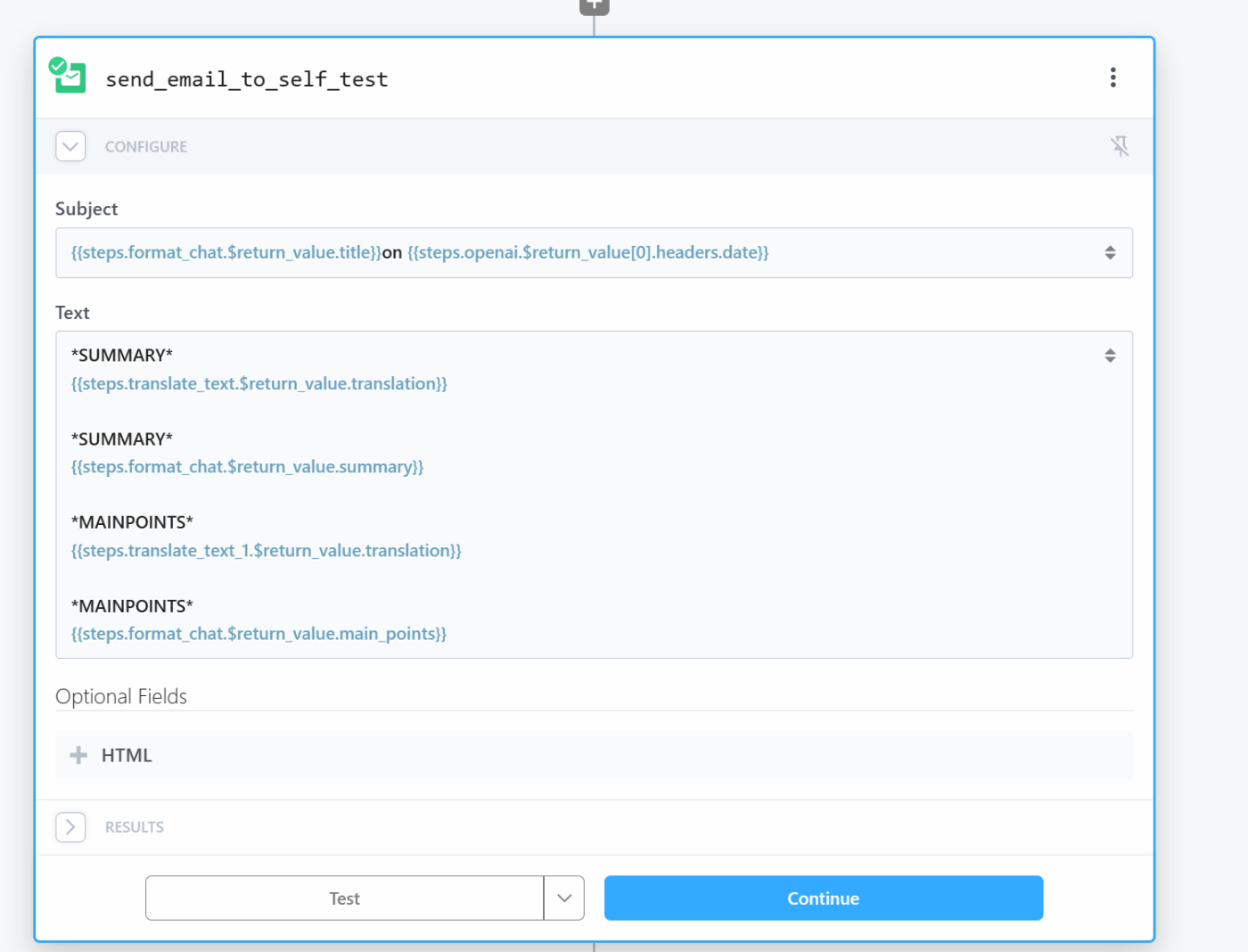
参考にした Youtuber はNotionのメモに出力していたが、自分はメールで出力することにした
実際にコードを実行して1時間の音声ファイルを自動要約・翻訳してみた
下記サイトから自分が好きな海外サッカーの番組 "Price of Football" をMP3形式でダウンロードする。Podcastは 1:00:52の長さだ。
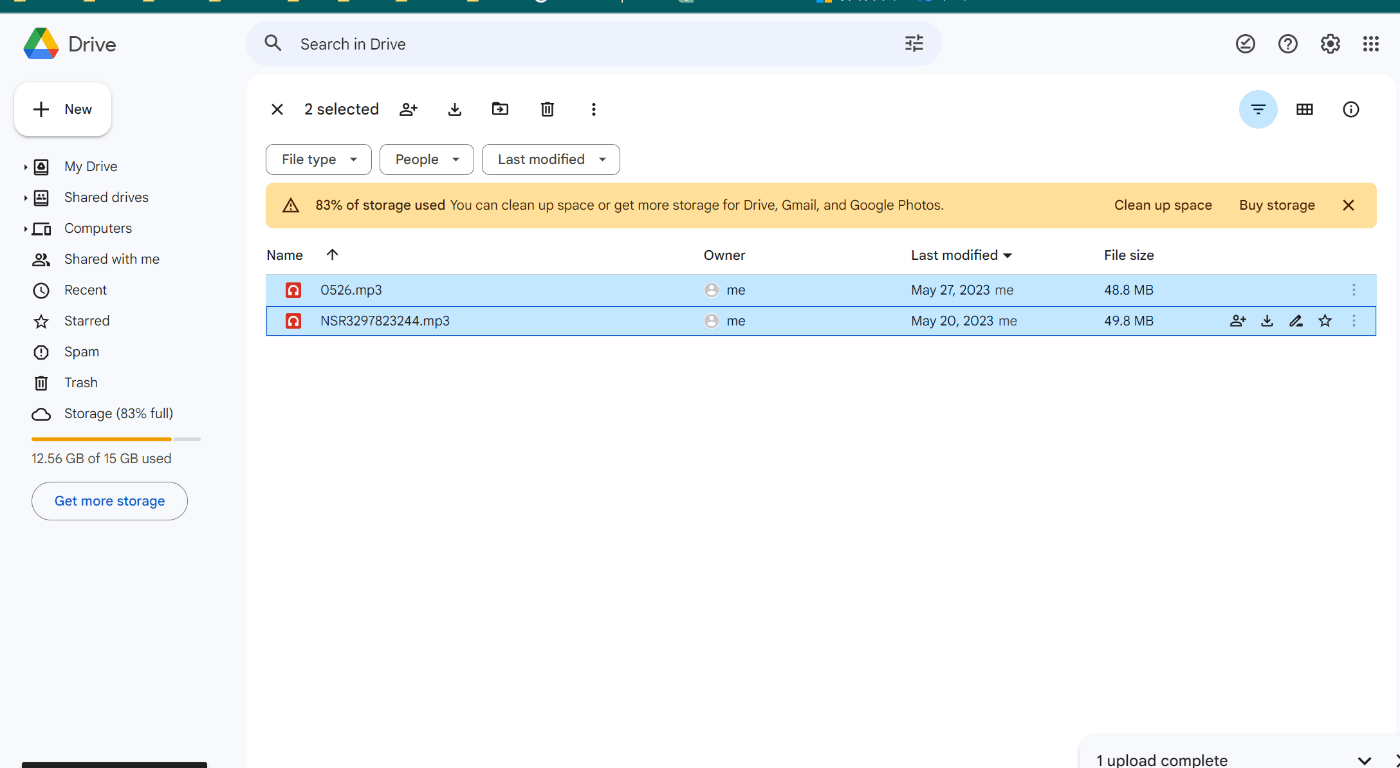
GoogleDrive の専用フォルダにアップロードすると、、
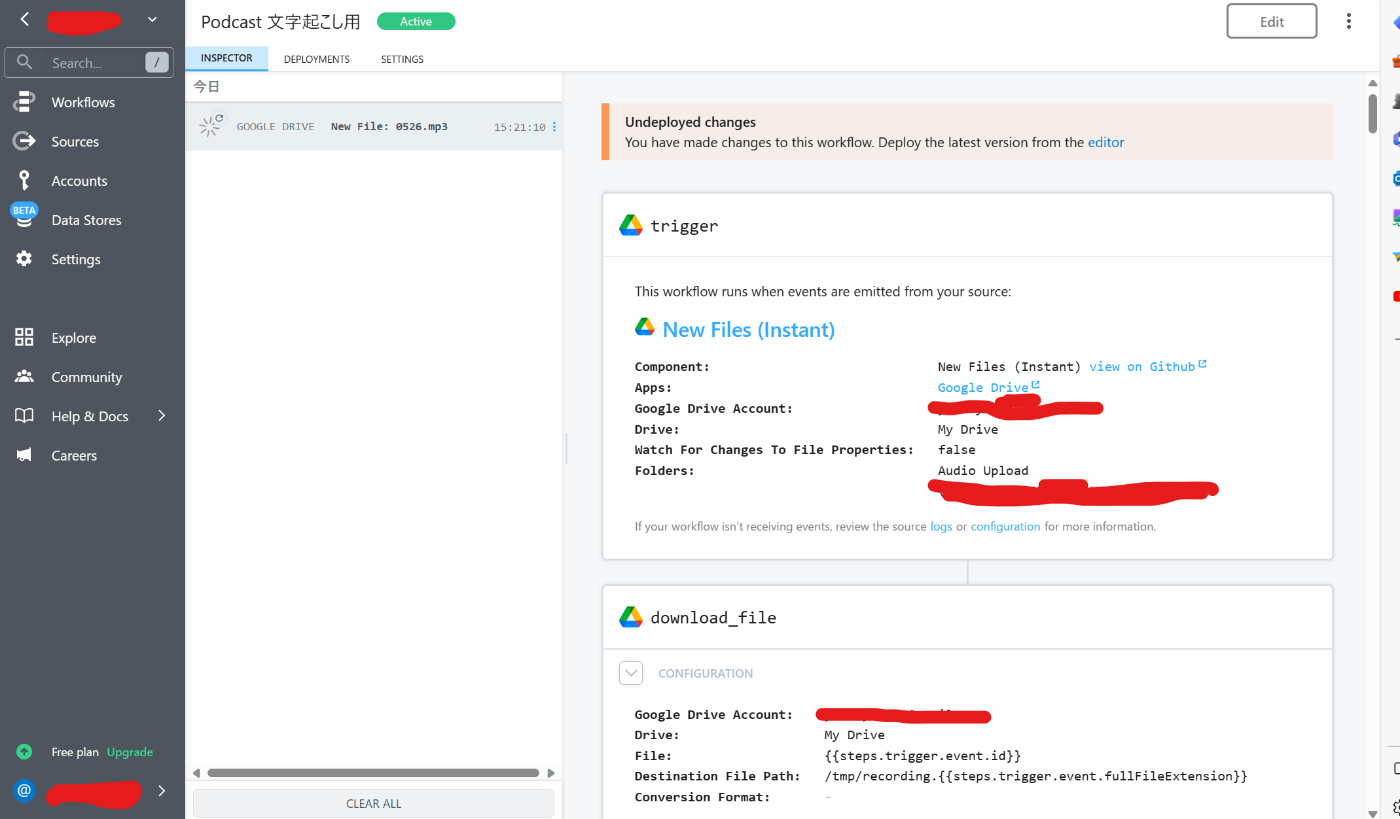
Pipedream のワークフローがキックする
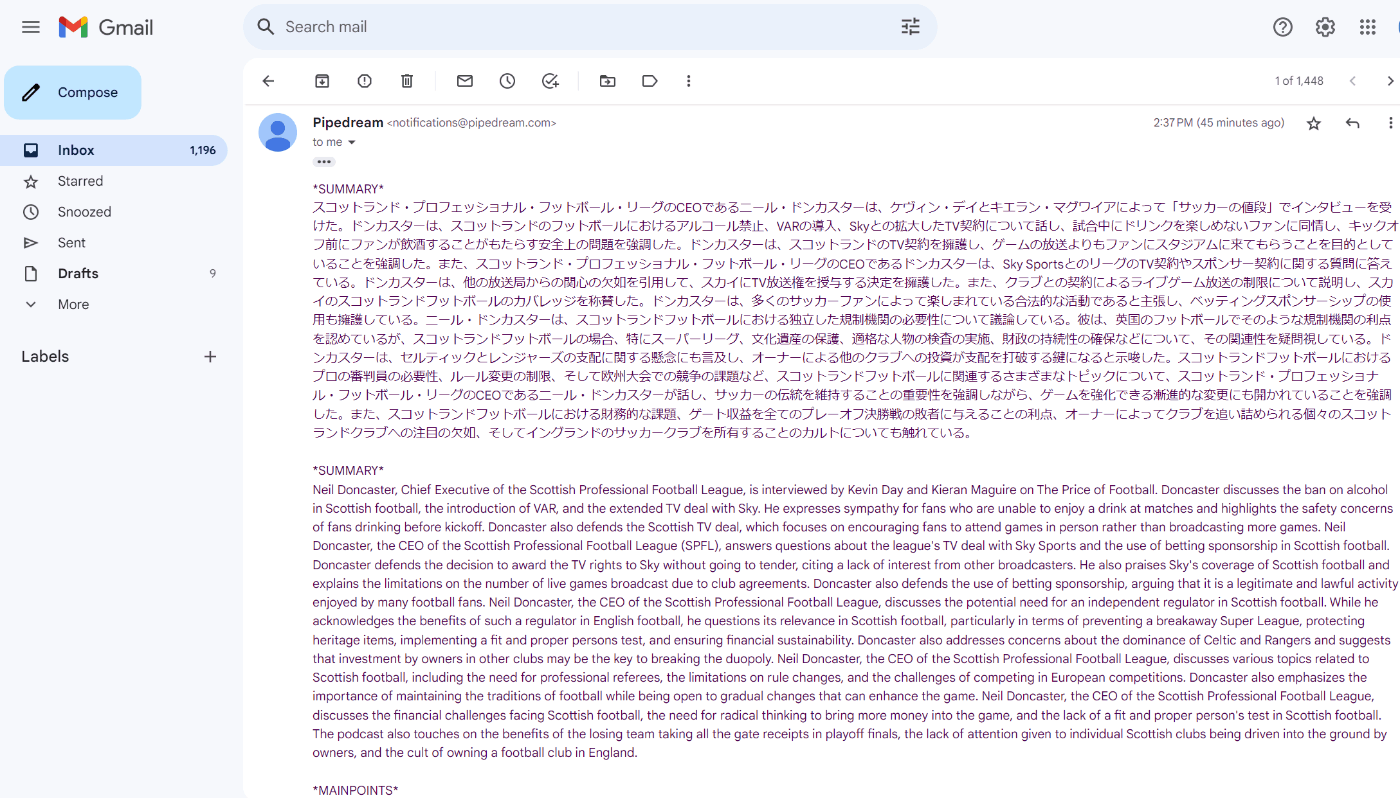
結構時間かかったが無事要約文章が自分のメールに送られた!
反省点とまとめ
- 処理に時間がかかりすぎて、タイムアウトになることがある
→ Pipedream 課金してタイムアウトになるまでの許容時間を伸ばすしかない? - 複数チャンクに分けているので、要約分の中に同じ内容が何回か繰り返される
- Podcast内のスポンサー宣伝やSNS宣伝なども含まれてしまう
→ いわゆるグラウンディングのメソッドを使って予め重複内容や宣伝は除外するような命令を組み込みたいところ - 文字量が多い。
分割しているものを再統合している都合、50文字以内でまとめてもらったものを複数組み合わせるので、どうしても長くなってしまう。しかし、チャンク毎に何を言っているかわからないと本末転倒。
今回は要約と要点を述べたが、中身のプロンプトを書き換えるだけで、例えば Next action を抽出したり、論点を抽出したり、SNS宣伝用に表現をカジュアルにしたり、色々可能性があるなーと思った。
コードは貼ったもの以外はほぼ書いていないものの、コードが必要な部分が結構難しかった。LangchainやSemantic Kernal を使えたらコード量は増えたとしてももうちょっと簡単に実装できるんだろうな、、Pythonを学ばなければ、、
Discussion