JuliaでGPTモデルを作成してみる
最近流行りのTransformerについて理解を深めたい
→ 内部構造を理解するなら一言語で完結するJuliaでしょ!
(単に研究である強化学習の実装にJuliaを使用しているだけ)
言語タスクを学習させるのは面倒だったので、算術タスクを学習させて性能を評価することにしました。2桁同士の加算、一桁同士の和積+"()"を使用した優先度付きの演算など
環境
- Windows 11
- Julia 1.9.3
- cuda 12.2
実装
まずは問題の作成
@enum MathToken begin
Pad = 1
# 演算子
Plus
Times
Equal
# 数字
Zero
One
Two
Three
Four
Five
Six
Seven
Eight
Nine
LeftParen
RightParen
End
end
const numbers = [Zero, One, Two, Three, Four, Five, Six, Seven, Eight, Nine]
const operators = [Plus, Times]
算術では数字(10個)、括弧(2個)、演算子(3個)、パディングと終端(2個)の合計17個のトークンを使用することにしました。
"""
全ての単純な式を列挙する
下記のような式を全て列挙する
8+6 = [Eight, Plus, Six]
"""
function enumerate_simple_exprs(k::Int)
res = Vector{Vector{MathToken}}()
max_num = 10^k - 1
for i in 0:max_num
for j in 0:max_num
expr = [num_to_tokens(i)..., Plus, num_to_tokens(j)...]
push!(res, expr)
end
end
res
end
これでK桁どうしの足し算を作ることができます
モデルの実装
using Lux, LuxCUDA, Random, Zygote, MLUtils, Optimisers, ProgressBars, Printf, JLD2, StatsBase, NamedTupleTools
使用するライブラリ
PositionalEncodingLayerの実装
struct PositionalEncodingLayer <: Lux.LuxCore.AbstractExplicitLayer
features::Int
seq_len::Int
end
Lux.initialparameters(rng::AbstractRNG, layer::PositionalEncodingLayer) = NamedTuple()
function Lux.initialstates(rng::AbstractRNG, layer::PositionalEncodingLayer)
features = layer.features
seq_len = layer.seq_len
pos_enc = [
i % 2 == 1 ? sin(j / 10000^(2 * i / features)) : cos(j / 10000^(2 * i / features))
for i in 1:features, j in 1:seq_len, _ in 1:1
]
(pos_enc=pos_enc,)
end
Lux.parameterlength(l::PositionalEncodingLayer) = 0
Lux.statelength(l::PositionalEncodingLayer) = l.features * l.seq_len
function (::PositionalEncodingLayer)(x, ps, st)
return x .+ st.pos_enc, st
end
位置情報の扱いについては、オリジナルそのままの正弦波を使用しました。
MultiHeadAttentionの実装
struct MultiHeadAttention <: Lux.LuxCore.AbstractExplicitContainerLayer{(:query, :key, :value, :dropout, :output)}
query
key
value
dropout
output
nheads
end
function (m::MultiHeadAttention)((x, mask), ps, st)
# x = (feature, seq_len, batch_size)
q, _ = m.query(x, ps.query, st.query)
k, _ = m.key(x, ps.key, st.key)
v, _ = m.value(x, ps.value, st.value)
st_dropout = nothing
function fdrop(x)
x, st_dropout = m.dropout(x, ps.dropout, st.dropout)
x
end
values, _ = dot_product_attention(q, k, v; mask=mask, fdrop=fdrop, nheads=m.nheads)
output, _ = m.output(values, ps.output, st.output)
st = merge(st, (dropout=st_dropout,))
return output, st
end
NNlib.jlにあるdot_product_attentionを使用して実装しました。fropについてはもう少し良い実装があるような気がしますが、とりあえずはローカル関数でst_dropoutを取り出すようにしました。
DecoderBlockの実装
struct DecoderBlock <: Lux.LuxCore.AbstractExplicitContainerLayer{(:mha, :layer_norm1, :ffn, :dropout, :layer_norm2)}
mha
layer_norm1
ffn
dropout
layer_norm2
end
function (m::DecoderBlock)((x, mask), ps, st)
norm_out, st_layer_norm1 = m.layer_norm1(x, ps.layer_norm1, st.layer_norm1)
attn_output, st_mha = m.mha((norm_out, mask), ps.mha, st.mha)
x = attn_output + x
norm_out, st_layer_norm2 = m.layer_norm2(x, ps.layer_norm2, st.layer_norm2)
ffn_output, _ = m.ffn(norm_out, ps.ffn, st.ffn)
dropout_out, st_dropout = m.dropout(ffn_output, ps.dropout, st.dropout)
x = dropout_out + x
st = merge(st, (mha=st_mha, layer_norm1=st_layer_norm1, layer_norm2=st_layer_norm2, dropout=st_dropout,))
return (x, mask), st
end
Decoderの実装
struct Decoder <: Lux.LuxCore.AbstractExplicitContainerLayer{(:embedding, :positional_encoding, :blocks, :output)}
embedding
positional_encoding
blocks
output
end
function (m::Decoder)((x, mask), ps, st)
# x = (token_size, seq_len, batch_size)
x, _ = m.embedding(x, ps.embedding, st.embedding)
x, _ = m.positional_encoding(x, ps.positional_encoding, st.positional_encoding)
# x = (features, seq_len, batch_size)
(x, _), st_blocks = m.blocks((x, mask), ps.blocks, st.blocks)
x = flatten(x)
output, st_out = m.output(x, ps.output, st.output)
# output = (token_size, seq_len, batch_size)
st = merge(st, (blocks=st_blocks, output=st_out))
return output, st
end
パディングマスクの作成
function create_mask(x)
# x shape: (seq_len, batch_size)
mask = (x .== 1)
# Expand mask dimensions to shape (seq_len, 1, 1, batch_size)
mask_expanded = reshape(mask, 1, size(mask, 1), 1, size(mask, 2))
mask = repeat(mask_expanded, size(mask, 1), 1, 1, 1)
return mask
end
これにより、Padに対して注意しなくなる。
学習
Transformerの効果を確認するために比較モデルとしてただのDNN層であるシンプルモデルも用意しました。
(モデルのパラメータはチューニングしていないので、あまり意味のあるものではないですが...)
シンプルモデル
Decoder(
embedding = Dense(17 => 48), # 864 parameters
positional_encoding = PositionalEncodingLayer(),
blocks = NoOpLayer(),
output = Chain(
layer_1 = Dense(912 => 912, relu), # 832_656 parameters
layer_2 = Dropout(0.2),
layer_3 = Dense(912 => 912, relu), # 832_656 parameters
layer_4 = Dropout(0.2),
layer_5 = Dense(912 => 912, relu), # 832_656 parameters
layer_6 = Dropout(0.2),
layer_7 = Dense(912 => 17), # 15_521 parameters
),
) # Total: 2_514_353 parameters,
# plus 918 states.
GPTモデル
Decoder(
embedding = Dense(17 => 48), # 864 parameters
positional_encoding = PositionalEncodingLayer(),
blocks = Chain(
layer_1 = DecoderBlock(
mha = MultiHeadAttention(
query = Dense(48 => 48), # 2_352 parameters
key = Dense(48 => 48), # 2_352 parameters
value = Dense(48 => 48), # 2_352 parameters
dropout = Dropout(0.1),
output = Dense(48 => 48), # 2_352 parameters
),
layer_norm1 = LayerNorm((48, 1), affine=true, dims=Colon()), # 96 parameters
ffn = Chain(
layer_1 = Dense(48 => 192, gelu), # 9_408 parameters
layer_2 = Dense(192 => 48), # 9_264 parameters
layer_3 = Dropout(0.1),
),
dropout = Dropout(0.1),
layer_norm2 = LayerNorm((48, 1), affine=true, dims=Colon()), # 96 parameters
),
layer_2 = DecoderBlock(
mha = MultiHeadAttention(
query = Dense(48 => 48), # 2_352 parameters
key = Dense(48 => 48), # 2_352 parameters
value = Dense(48 => 48), # 2_352 parameters
dropout = Dropout(0.1),
output = Dense(48 => 48), # 2_352 parameters
),
layer_norm1 = LayerNorm((48, 1), affine=true, dims=Colon()), # 96 parameters
ffn = Chain(
layer_1 = Dense(48 => 192, gelu), # 9_408 parameters
layer_2 = Dense(192 => 48), # 9_264 parameters
layer_3 = Dropout(0.1),
),
dropout = Dropout(0.1),
layer_norm2 = LayerNorm((48, 1), affine=true, dims=Colon()), # 96 parameters
),
layer_3 = DecoderBlock(
mha = MultiHeadAttention(
query = Dense(48 => 48), # 2_352 parameters
key = Dense(48 => 48), # 2_352 parameters
value = Dense(48 => 48), # 2_352 parameters
dropout = Dropout(0.1),
output = Dense(48 => 48), # 2_352 parameters
),
layer_norm1 = LayerNorm((48, 1), affine=true, dims=Colon()), # 96 parameters
ffn = Chain(
layer_1 = Dense(48 => 192, gelu), # 9_408 parameters
layer_2 = Dense(192 => 48), # 9_264 parameters
layer_3 = Dropout(0.1),
),
dropout = Dropout(0.1),
layer_norm2 = LayerNorm((48, 1), affine=true, dims=Colon()), # 96 parameters
),
),
output = Dense(912 => 17), # 15_521 parameters
) # Total: 101_201 parameters,
# plus 930 states.
学習パラメータ
学習率: 6e-4
オプティマイザ: AdamW(β = (0.9, 0.95), γ = 0.1, ϵ = 1e-8)
※ bias, scaleのWeightDecayは0
学習データ: 10000個の足し算式を Train:Test=1:3 に分割
学習結果
| シンプルモデル | GPTモデル |
|---|---|
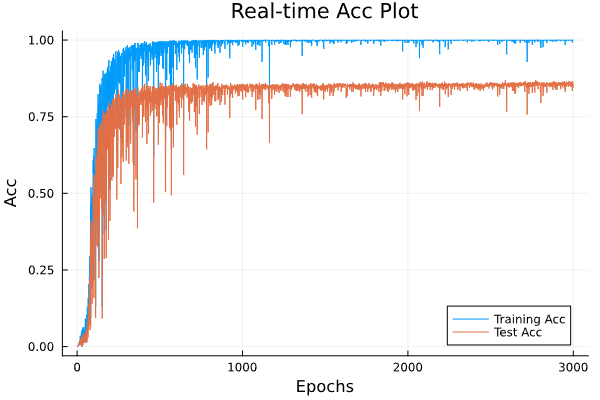 |
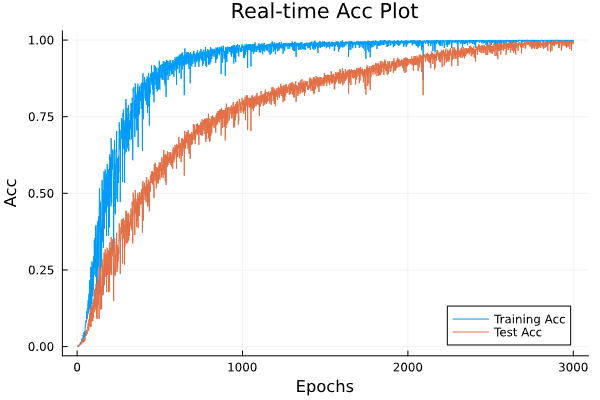 |
| 学習時間 27m | 学習時間 1h14m |
| MaxTestAcc 86.3% | MaxTestAcc 99.9% |
シンプルなDNNモデルはTrainの精度とTestの精度が連動していますが、GPTの方はTrainデータのaccが上限になってもTestデータのaccが上がり続けていますね。
感想
汎化性能の違いを明確に見ることができてよかったです。モデルサイズや学習データのTrain, Test比率などの調整にはちょっと苦労しましたが、満足な結果となりました。
Discussion