尤度、対数尤度、負の対数尤度関数、最尤推定を整理してみた
今回は、統計学や機械学習の基礎となる重要な概念「尤度」「対数尤度」「負の対数尤度関数」「最尤推定」について、整理した内容をメモとして残します。これらは、データからモデルを学習したり、モデルのパラメータを推定したりする際に欠かせない考え方なのですが、正直人に上手く説明ができなかったので整理しようと思いました。
1. 尤度とは? データが語る「もっともらしさ」
まず「尤度(Likelihood)」とは何か?から書きます。尤度とは、「あるデータが得られたときに、そのデータが特定のモデル(確率分布)から生成されたと考えることができる度合い」 を示す指標です。
例えば、ある新製品の購買意向を調査するために、100人にアンケートを実施したところ、30人が「購入したい」と回答しました。このとき、製品の購入意向が20%の場合と30%の場合では、どちらがこのアンケート結果を「もっともらしく」説明できるでしょうか?直感的には、30%の方がより「もっともらしい」と感じると思います。この「もっともらしさ」を数値化したものが尤度です。
具体的には、データが独立に生成される という仮定のもとで、各データの確率を掛け合わせて計算されます。データが独立に生成されるとは、各データが他のデータの値に影響されないことを意味します。
※この仮定は、モデルの単純化のために行われることが多いですが、実際のデータが独立ではない場合もあります(例:時系列データなど)。そのような場合には、データの依存関係を考慮したモデルを用いる必要があります。
では、実際の例を挙げてみます。
ここで、
2. 対数尤度とは? 計算を楽にしてくれる
次に「対数尤度(Log-Likelihood)」についてです。対数尤度とは、尤度の値に自然対数(ln: logarithmus naturalis)をとったものです。なぜ対数をとるのでしょうか?
-
計算の簡略化: 尤度は複数の確率を掛け合わせて計算されるため、データ数が増えると値が非常に小さくなってしまい、計算が難しくなります。対数をとることで積が和に変換され、計算が容易になります。
- 例:
0.7 \times 0.5 \times 0.3 = 0.105
- 例:
- 数値の安定化: 小さな値を扱う際に、数値計算上の問題を避けることができます。
対数を取って計算すると、積の計算が和の計算に変換できるため、特に桁数が大きい場合や手計算の工夫をする場合に便利です。
対数を使った計算手順
1. 対数を取る(自然対数 ln
2. 近似値を利用
一般的な近似値:
これらを足し合わせると、
3. 指数関数を取って元の値に戻す
対数を使うメリット
- 積が和に変換される → 多数の積を扱う場合に計算が簡単になる
- 大きな数・小さな数の計算に便利 → オーダーを把握しやすい
- 対数表を活用できる → 昔の計算では対数表を使うことで手計算が簡単になった
※ただ、この例のように数値が小さい場合は、普通に掛け算した方が速いです
3. なぜ負の対数尤度関数を使うのか? 最適化アルゴリズムが最小化を行うため
機械学習では、対数尤度に負号をつけた「負の対数尤度関数(Negative Log-Likelihood Function)」を最小化するという形で使われることが多いです。なぜ負にするのでしょうか?
まず、対数尤度が負の値になる理由について説明します。尤度は、観測データが特定のモデルから生成される確率を示します。この確率は0から1の間の値を取ります。自然対数を取ると、1の対数は0に、1未満の数の対数は負の値になります。そのため、確率を掛け合わせて計算される尤度、そしてその対数をとった対数尤度は、多くの場合、負の値を取ります。
負の値を取る例
サンプル 1:
P(y_1 | \theta) = 0.4 P(y_2 | \theta) = 0.6 P(y_3 | \theta) = 0.5
尤度:
対数尤度:
サンプル 2:
P(y_1 | \theta) = 0.9 P(y_2 | \theta) = 0.8 P(y_3 | \theta) = 0.7
尤度:
対数尤度:
対数(log)を取るとき、引数が1未満の場合、対数の値は負になります。
これは、対数関数が次のような性質を持つからです。
\log(1) = 0 -
\log(x) < 0 x < 1
具体的な例:
\log(0.5) \approx -0.3010 \log(0.1) \approx -1
つまり、1未満の数の対数は必ず負の値になります。
そして、負の対数尤度関数を使う理由は、主に以下の2点です。
- 最適化アルゴリズムとの相性: 最尤推定は、尤度(対数尤度)を最大にするパラメータを探す問題です。しかし、多くの最適化アルゴリズムは、関数を最小化するように設計されています。そこで、対数尤度に負号を付けて、最小化問題として解くことで、尤度を最大化するパラメータを求めることができます。例えば、負の対数尤度関数の最小化には、勾配降下法(Gradient Descent) のような最適化アルゴリズムがよく使われます。
- 損失関数としての利用: 機械学習では、モデルの出力と正解との誤差を表す損失関数を最小化することでモデルを学習させます。負の対数尤度関数は、この損失関数として利用でき、モデルの出力確率と実際のデータのずれを測る尺度として解釈できます。したがって、これを最小化することで、モデルがデータをもっともらしく説明できるように学習できます。
4. 最尤推定とは? データにもっとも合うパラメータを見つける
最後に「最尤推定(Maximum Likelihood Estimation: MLE)」について書きます。最尤推定とは、「与えられたデータに対して、最も尤度(または対数尤度)が大きくなるようなモデルのパラメータを推定する方法」 です。
つまり、データをもっともらしく説明できるようなモデルのパラメータを探すために、尤度を最大化するパラメータを求めるのが最尤推定です。実際には、計算を容易にするために、負の対数尤度関数を最小化することでパラメータを推定します。
まとめ:尤度、対数尤度、負の対数尤度関数、最尤推定
- 尤度(Likelihood): あるデータが、特定のモデルから生成されたと考えることができる度合いを示す指標(「もっともらしさ」)。
- 対数尤度(Log-Likelihood): 尤度の計算を簡単にするために、尤度に自然対数をとったもの。
- 負の対数尤度関数(Negative Log-Likelihood Function): 対数尤度に負号をつけた関数。最適化アルゴリズムで扱いやすいように、最小化問題に変換するために利用される。確率モデルの学習においてパラメータを最適化する損失関数として使われる。
- 最尤推定(Maximum Likelihood Estimation: MLE): 与えられたデータに対して、最も尤度(または対数尤度)が大きくなるようなモデルのパラメータを推定する方法。負の対数尤度関数を最小化することで求められる。
流れを図式化すると、以下のようなイメージです。
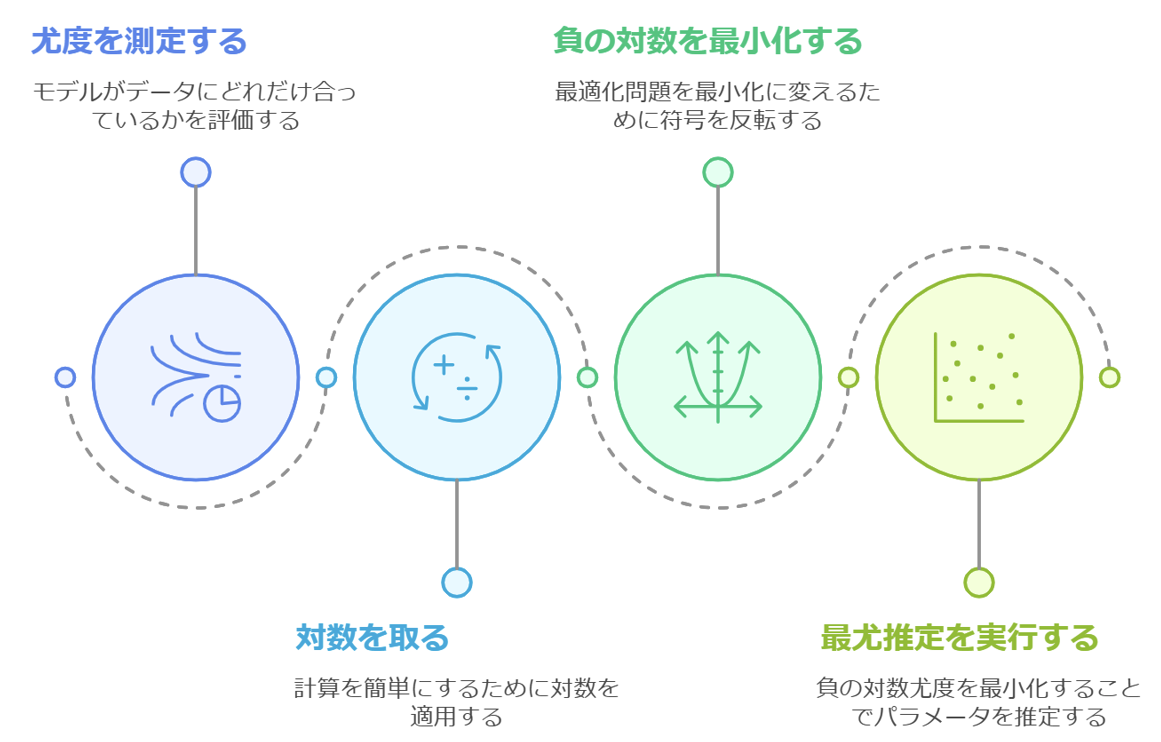
改めて、概念を単独で考えるのではなく、つながりで見ることで理解が増しました。少しでも参考になれば幸いです。
Discussion