「UniCoRnによるJoint Modeling of Search and Recommendations」をまとめてみた
はじめに
イタリアで開催されているRecSys24で発表されたNetflixの論文の自分用日本語まとめです。
まさに、ユニコーン級の内容です。
「統一文脈レコメンダー(UniCoRn)による検索とレコメンデーションのジョイントモデリング」
概要
検索とレコメンデーションシステムは多くのサービスにおいて不可欠であり、しばしば別々に開発されています。これにより、メンテナンスと技術的負債が複雑になります。本論文では、両方のタスクの主要な側面を効率的に処理する統一された深層学習モデルを紹介します。
イントロダクション
多くの現実世界のアプリケーションでは、チームが検索タスクとレコメンデーションタスクを解決するために別々のモデルを開発することが一般的です。これによりシステム管理のオーバーヘッドおよび技術的負債が増加します。本発表では、検索とレコメンデーションの両方のタスクに対応する単一の深層学習モデルを提案します。さらに、検索結果を大規模にパーソナライズし、レコメンデーションユースケースを向上させる方法についても述べます。
提案されたアプローチ
モデルの統一
以前は、Netflix製品では各アプリケーションに独自のモデルがありました。これらのモデルを統合し、検索やレコメンデーションのようなタスクに1つのトレーニング済みモデルを使用することにより、メンテナンスの複雑さを軽減しました。技術の統合によって、すべての異なるタイプのアプリケーションにサービスを提供できるようになります。
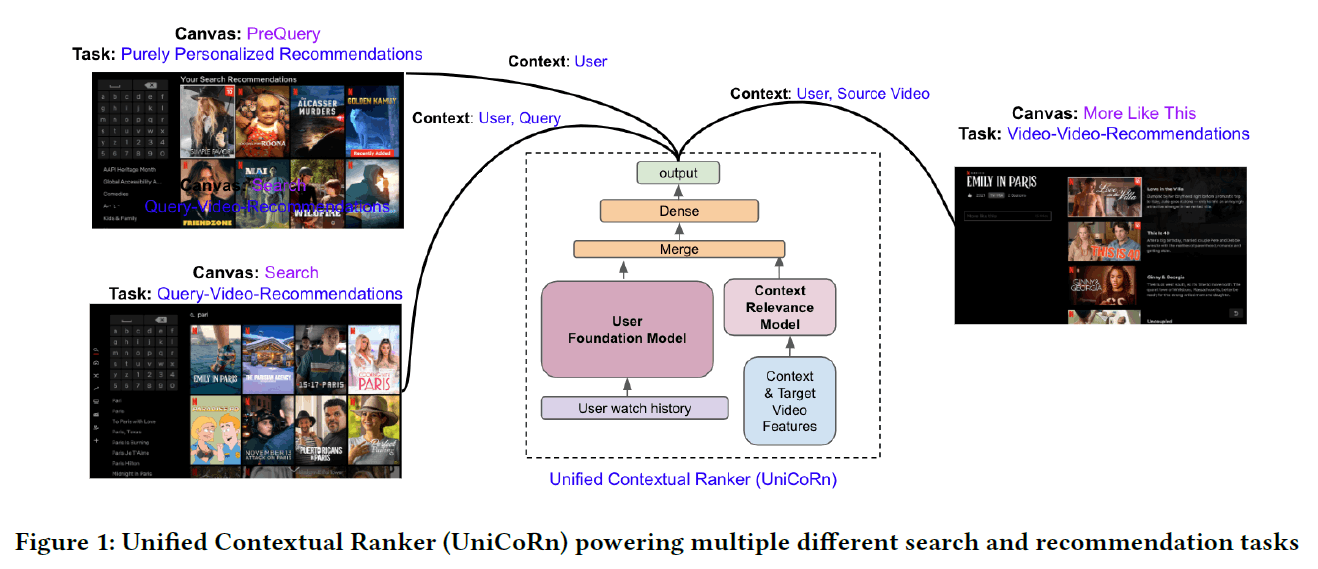
コンテキストの統一
検索とレコメンデーションの違いに留意しつつ、ユーザーID、クエリ、国、ソースエンティティID、タスクなどをコンテキストに含むモデルを開発しました。これにより、各タスク間で情報を共有でき、パフォーマンスを向上させることができます。
特徴へのアプローチ
幅広いカテゴリに分類できるいくつかの機能を使用し、カテゴリ型または実数値の量的特徴を入力層に供給しました。深層学習モデルには残差接続と特徴交差が含まれ、バイナリクロスエントロピー損失とAdamオプティマイザーを使用します。
統一文脈レコメンダー(UniCoRn)
特徴
このモデルは、異なるランク付け結果を生成できます。特定のタスク向けにトレーニングされたモデルよりも、さまざまなタスクからのデータを共有することでパフォーマンスが向上します。さらに検索タスクでレコメンデーションタスクの特有のパーソナライゼーション機能を活用するという利点があります。
段階的なパーソナライゼーション
ユーザーのクラスタリングに基づく準パーソナライズから始め、次に完全パーソナライズモデルへ移行しました。これにより、一連の実験と改善を経て、Netflixのさまざまなサービスで利用できるようになりました。
結果
単一の統一モデルが検索とレコメンデーション両方のパフォーマンスを向上させることが示されました。パーソナライゼーションを組み込むことで、両アプリケーションにメリットをもたらし、関連性とパーソナライゼーションを適切にバランスさせることが可能になりました。
ここがポイント!
ここまでが要約です。以降は、先行研究との比較や、自社で取り入れようと思った際の懸念事項など、記載していきます。
先行研究との比較
統一されたモデルの導入
従来は検索とレコメンデーションのタスクが個別のモデルで処理されていましたが、今回の研究では両方のタスクを統一して扱う深層学習モデルが導入されました。これにより、システム管理のオーバーヘッドや技術的負債の削減が可能となりました。
異なるタスク間でのデータ共有と補完
複数のタスクが同じデータセットを共有することで、個々のタスクが他の補助タスクから恩恵を受けることができました(クロスドメイン学習)。これにより、パフォーマンスの向上が見られた点は従来の個別モデルでは難しかった点です。
パーソナライゼーションの強化
統一されたモデルのパーソナライゼーション機能を活用し、検索とレコメンデーションの両方でパーソナライゼーションのメリットが得られました。また、段階的なアプローチにより、必要に応じてパーソナライゼーションの精度を適切に制御することが可能になりました。これにより、検索結果の関連性とパーソナライゼーションのバランスを最適化することができました。
柔軟なコンテキスト処理
複数の異なるコンテキスト(ユーザーID、クエリ、国、タスクなど)を同時に扱うことができ、それに基づいて適切な検索結果やレコメンデーションを生成することが可能になりました。これにより、欠落したコンテキストをヒューリスティックで補完し、広範なコンテキストを利用することでモデルの精度を高めることができました。
方法とアプローチ
両方のタスクを統一して扱う深層学習モデルを実現するために、以下の方法とアプローチが採用されました:
-
共通のコンテキストの利用:
- モデルは、ユーザーID、クエリ、国、ソースエンティティID、タスクといった共通のコンテキスト情報を入力として使用します。これにより、検索とレコメンデーションの両方のタスクで必要な情報を一つのモデルが同時に処理できるようになります。
-
入力層の工夫:
- すべてのコンテキスト情報がモデルの入力層に供給されます。カテゴリ型特徴は対応する埋め込み層を学習し、量的特徴はそのまま処理されます。これにより、異なる種類のデータを同時に扱うことが可能になります。
-
ヒューリスティックによる欠落コンテキストの補完:
- 検索タスクやレコメンデーションタスクで特定のコンテキスト情報が欠落している場合、それをヒューリスティックにより補完します。たとえば、検索タスクでは欠落するソースエンティティIDにnull値を代入し、レコメンデーションタスクでは表示されているエンティティのトークンを利用して欠落したクエリコンテキストを推定します。
-
特長交差と残差接続の利用:
- モデルアーキテクチャには、特徴量間の関係性を学習するために特徴交差(feature crossing)と残差接続(residual connections)が含まれています。これにより、さまざまなコンテキストに対する相互関係を効果的に捉え、多様なタスク間での相乗効果を引き出しやすくします。
-
バイナリクロスエントロピー損失とAdamオプティマイザー:
- モデルのトレーニングにはバイナリクロスエントロピー損失関数とAdamオプティマイザーが使用されました。これにより、効率的かつ効果的な学習が行われ、モデルの最適化が図られました。
-
段階的パーソナライゼーション:
- 初めは完全にパーソナライズされたモデルではなく、クラスタリングに基づく準パーソナライズされたモデルから始め、次第に完全なパーソナライズへと移行する段階的なアプローチを採用しました。この方法により、ユーザーごとのパーソナライズ度合いを適宜調整することができます。
統一モデルの導入が少なかった理由
検索とレコメンデーションの両方のタスクを単一の深層学習モデルで統一して扱うというコンセプトが以前には少なかった理由として、いくつかの懸念や課題が存在しました。具体的には以下の点が挙げられます:
-
タスクの性質の違い:
- 検索とレコメンデーションは入力データと出力目標が異なり、単一のモデルで統一的に扱うのは複雑であると考えられていました。
-
コンテキストの多様性:
- 各タスクに必要なコンテキスト情報が異なるため、すべての情報を統一的に扱うためのモデル設計が難しいとされていました。
-
パフォーマンスおよびリソースの管理:
- 単一のモデルで両方のタスクを処理する場合、モデルの規模が大きくなり、計算リソースやメモリ使用量が増加することが懸念されました。
-
ペナルティやトレードオフの管理:
- 検索とレコメンデーションは異なる評価指標や成功基準を持ち、単一のモデルで両方を同時に最適化することはトレードオフが伴うと考えられていました。
-
技術的複雑さ:
- 機械学習モデルを設計・トレーニングする際の技術的課題も予想されました。異なる入力形式や出力形式に対応させるためのアーキテクチャの設計が困難であると考えられていました。
-
チームや組織の壁:
- 実際の企業や研究機関では、検索システムとレコメンデーションシステムは別々のチームが開発・運用していることが多く、統一モデルを構築するには組織的なハードルも存在しました。
これらの懸念があるため、従来は検索とレコメンデーションの両方のタスクを別々にモデル化するアプローチが多く採用されてきました。しかし、本研究はこれらの課題に対する解決策を提示し、単一のモデルで両タスクを効果的に統合する方法を示しました。
自社で取り入れるためのステップ
-
タスクの理解:
- まず、自社の検索タスクとレコメンデーションタスクを詳細に理解し、共通するコンテキスト情報を特定します。
-
データの整理と統合:
- すべての関連するデータ(ユーザーID、クエリ、国、エンティティIDなど)を統合し、統一されたデータセットを作成します。
-
モデルアーキテクチャの設計:
- 共通コンテキストを入力データとして活用する深層学習モデルを設計します。特徴交差や残差接続を活用し、複雑な相関関係を捉えるようにします。
-
ヒューリスティックの設定:
- 欠落するコンテキストを補完するヒューリスティックルールを設定・実装します。これにより、すべてのタスクが完全なコンテキスト情報を使用して学習できるようになります。
-
段階的パーソナライゼーションの実施:
- 初めはユーザークラスタリングを用いた準パーソナライズモデルを構築し、次第に完全パーソナライゼーションへと移行します。ユーザーとアイテムの表現学習モデルも導入します。
-
オフラインとオンラインの評価:
- 開発したモデルをオフラインで評価し、パフォーマンスを測定した後、A/Bテストなどを用いてオンラインで実際のユーザーに対する効果を検証します。
-
継続的な改善:
- モデルのパフォーマンスを定期的にモニタリングし、改善が必要な箇所を特定して継続的にチューニングを行います。
難しそうなポイントとその乗り越え方
-
高い計算リソースの要求
難しそうなポイント:
- 単一のモデルで検索とレコメンデーションの両タスクを処理するため、モデルの規模が大きくなることが予想されます。このため、計算リソースやメモリ使用量が増え、高性能なインフラが必要になるかもしれません。
乗り越え方:
- モデルの最適化: モデルのパラメータを削減し、軽量化を図る。例えば、蒸留学習(Knowledge Distillation)などを使ってモデルのサイズを小さくすることができます。
- 分散学習の活用: データと計算を複数のマシンに分散させ、計算リソースの負荷を分散させます。
-
データ品質と統合の問題
難しそうなポイント:
- 各タスクで利用されるデータが異なり、欠損値やデータの不整合が発生する可能性があります。これを無視すると、モデルのパフォーマンスが低下します。
乗り越え方:
- データ前処理とクリーニング: データ品質を高めるために、データクリーニングと前処理を徹底します。欠損値の補完、異常値の処理、データのノーマライズなどを行います。
- 一貫したデータフォーマットの設計: 各タスクで使われるデータフォーマットを一貫性のあるものに統一し、データの不整合を減らします。
- 定期的なデータ検証: データが正しくインテグレーションされているかどうかを定期的に検証し、問題を早期に発見・修正します。
-
モデルの複雑さとトレードオフの管理
難しそうなポイント:
- 単一のモデルで異なるタスクを同時に最適化する際、トレードオフが発生し、一方のタスクのパフォーマンスが向上すると、他方のタスクのパフォーマンスが低下することがあります。
乗り越え方:
- マルチタスク学習技術の採用: タスク間の競合を最小限に抑え、全体のパフォーマンスを均衡させるためのマルチタスク学習技術を活用します。たとえば、タスク特有のヘッドを設計し、共通部分とタスク特有部分を分離して学習させる方法があります。
- モデルのパフォーマンスモニタリング: 定期的に各タスクのパフォーマンスをモニタリングし、必要に応じてハイパーパラメータの調整やアーキテクチャの改善を行います。
-
組織の意識改革と協力体制の確立
難しそうなポイント:
- 検索タスクとレコメンデーションタスクは、通常、別々のチームが担当している場合が多く、統一モデルを導入するには組織的な協力が必要とされます。
乗り越え方:
- クロスファンクショナルチームの構成: 検索チームとレコメンデーションチームからメンバーを集め、クロスファンクショナルチームを構成します。共通の目標と目的を共有することが重要です。
- コミュニケーションの促進: チーム間のコミュニケーションを円滑にする手段を講じる。定期的なミーティング、ワークショップ、共同作業スペースの設置などを行います。
- パイロットプロジェクトの実施:小規模なパイロットプロジェクトから始め、成功事例を作ることで、組織全体の理解と支持を得る。
-
モデルのインプリメンテーションと運用の複雑さ
難しそうなポイント:
- 新しい統一モデルを実装し、運用に乗せる際のスムーズな移行が必要です。既存システムに与える影響を最小限に抑えながら、新しいシステムに移行することが重要です。
乗り越え方:
- インクリメンタルな導入: 一度にすべてを切り替えるのではなく、インクリメンタルに導入していくことで、リスクを最小限に抑えます。部分的に新しいモデルを導入し、その効果を検証しながら段階的に移行します。
- バックアップとテスト環境の構築: 導入前に充分なテストを行い、バックアップシステムを準備することで、スムーズな移行をサポートします。ステージング環境を用意し、影響を検証してから本番環境に投入します。
おわりに
検索とレコメンド両方に単一の統合モデルを活用して精度を向上させるという合体技は、多くの障壁があったと思われますが、勇気をもらえる発表でした。
Discussion