前回は、自然言語処理のspaCy,GiNZAについての概要を記載しました。
かなり時間が空いてしましましたが、今回はLanguageモデルと、ルールベースでのエンティティ抽出についてまとめていきたいと思います。
今回比較するLanguageモデル
| Languageモデル | 説明 | タイプ | 備考 |
|---|---|---|---|
| ja_core_news_sm | spaCyの日本語標準モデル(小) | 語彙、構文、エンティティ | 軽量でエンティティ注出可能なモデル。単語ベクトルはないため、類似度の算出はできない。ファイル名のnewsは、ニュース記事のデータで学習したことを示す。 |
| ja_core_news_md | spaCyの日本語標準モデル(中) 。単語ベクトル数:48万個のキー、2万個の一意のベクトル | 語彙、構文、エンティティ、ベクトル | 単語ベクトル(小)を含めたモデル。 |
| ja_core_news_lg | spaCyの日本語標準モデル(大)。 単語ベクトル数:48万個のキー、48万個の一意のベクトル | 語彙、構文、エンティティ、ベクトル | 単語ベクトル(大)を含めたモデル。 |
| ja_core_news_trf | spaCyのBERTベースのtransformer(深層学習)モデル | 語彙、構文、エンティティ | 上3つは、tokenizerで分割したTokenから特徴量を抽出する「tok2vec」を使用しているが、トレーニング済みのtransformer(深層学習)を使用したモデル。 |
| ja_ginza | GiNZA 日本語NLPライブラリ | 語彙、構文、エンティティ、ベクトル | トークン化(形態素解析)処理にSudachiPyを、単語ベクトル表現にchiVeを使用したモデル。 |
| ja_ginza_electra | GiNZA 日本語NLPライブラリ(transformerバージョン) | 語彙、構文、エンティティ、ベクトル | mC4から抽出した日本語20億文以上を用いて事前学習したモデル。 |
| spacy_stanza(jaモデル) | Stanza (StanfordNLP) 研究モデル | 構文、エンティティ | トークン化、品詞のタグ付け、形態素解析、見出し語化、および 68の言語でのラベル付けされた依存関係の解析が可能 |
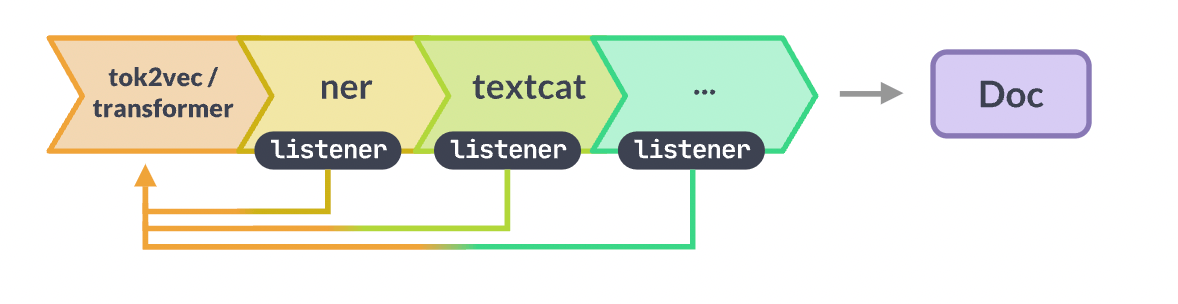
tok2vecとtransformerの処理イメージ
比較
今回は、エンティティの抽出で、各モデルの比較をしてみます。
まず、各モデルのインストールは以下で実施します。
!python -m spacy download ja_core_news_sm
!python -m spacy download ja_core_news_md
!python -m spacy download ja_core_news_lg
!python -m spacy download ja_core_news_trf
pip install ja_ginza
pip install ja_ginza_electra
pip install spacy_stanza
ja_core_news_sm
txt = ("むかし、むかし・・・・") # 桃太郎の序文を使用
nlp = spacy.load("ja_core_news_sm")
doc = nlp(txt)
displacy.render(doc, style="ent", options={"compact":True}, jupyter=True)

- GPE:地名
- PERSON:人名
- QUANTITY:数量
ja_core_news_md
txt = ("むかし、むかし・・・・")
nlp = spacy.load("ja_core_news_md")
doc = nlp(txt)
displacy.render(doc, style="ent", options={"compact":True}, jupyter=True)

- PERSON:人名
- QUANTITY:数量
ja_core_news_lg
txt = ("むかし、むかし・・・・")
nlp = spacy.load("ja_core_news_lg")
doc = nlp(txt)
displacy.render(doc, style="ent", options={"compact":True}, jupyter=True)

- PERSON:人名
- QUANTITY:数量
ja_core_news_trf
txt = ("むかし、むかし・・・・")
nlp = spacy.load("ja_core_news_trf")
doc = nlp(txt)
displacy.render(doc, style="ent", options={"compact":True}, jupyter=True)

- QUANTITY:数量
- PET_NAME:ペットの名前
ja_ginza
txt = ("むかし、むかし・・・・")
nlp = spacy.load("ja_ginza")
doc = nlp(txt)
displacy.render(doc, style="ent", options={"compact":True}, jupyter=True)

- Dish:料理
- Person:人名
- Flora:植物
- N_Product:製品数
ja_ginza_electra
txt = ("むかし、むかし・・・・")
nlp = spacy.load("ja_ginza_electra")
doc = nlp(txt)
displacy.render(doc, style="ent", options={"compact":True}, jupyter=True)

- Park:公園
- Flora:植物
- N_Natural_Object_Other:自然物数_その他
- Fish:魚類名
spacy_stanza(jaモデル)
import stanza
import spacy_stanza
from spacy import displacy
stanza.download("ja")
nlp = spacy_stanza.load_pipeline("ja")
txt = ("むかし、むかし・・・・")
doc = nlp(txt)
displacy.render(doc, style="ent", options={"compact":True}, jupyter=True)

- PERSON:人名
- QUANTITY:数量
- PRODUCT:製品名
比較結果
今回の7モデルを比較してみて、エンティティの抽出ということであれば、「ja_ginza_electra」がよさそうです。ただ、処理時間が少しかかるため、軽量に判定したい場合は、「ja_ginza」を使用してもよいかもしれません。
ルールベースでのエンティティ抽出
Languegeモデルを使用することで、ある程度のエンティティ抽出は可能ですが、特定の単語もエンティティとして抽出させてみたいと思います。
今回の例文の、「おじいさん」「おばあさん」を抽出してみましょう。
spaCyでルールベースのエンティティ抽出を行う場合、EntityRulerを使用します。
nlpオブジェクトのadd_pipeでEntityRulerのパイプラインを取得し、パイプラインに辞書パターンを追加します。
nlp = spacy.load("ja_ginza_electra")
# 辞書登録
patterns = [ {"label": "PERSON", "pattern": "おじいさん"},{"label": "PERSON", "pattern": "おばあさん"}]
ruler = nlp.add_pipe('entity_ruler')
ruler.add_patterns(patterns)
doc = nlp(txt)
displacy.render(doc, style="ent", options={"compact":True}, jupyter=True)
結果

まとめ
今回はLanguageモデルと、ルールベースでのエンティティ抽出について記載しました。
用途によるかと思いますが、日本語のエンティティ抽出を行う場合は「ja_ginza_electra」がよい結果となりました。次回は、単語ベクトルを使った類似度で、各モデルの比較を行なってみたいと思います。

chameleonmeme.com/ ビジネスのすべての工程を自分たちの手で行い、 気の合う仲間と楽しく仕事をすることで熱中するためにチームをスタートしました。 お仕事のご相談・お誘いはお気軽にお問い合わせください。 コーポレートサイトのWEBフォームから随時受け付けております🙆
Discussion
spacy_stanzaのjaモデルも同様に使えるので、よければ比較対象に加えて下さいね。
有益な情報ありがとうございます。
spacy_stanzaも比較対象に加えさせてもらいます。