はじめに
最近ジブリ風画像で話題ですが、
「4o image generation」とは何か、そしてそれが DALL·E(ダリ) とどう関係しているのか、理解のために整理してみます。
1. 「4o image generation」とは?
「4o image generation」は、OpenAIが提供する GPT-4o(フォーオー) モデルで可能な画像生成機能を指します。
- GPT-4o(oは"omni"=万能の意) は、テキスト・画像・音声・動画のマルチモーダル対応モデル。
- GPT-4oでは、テキストから画像を生成する機能(=image generation)が内包されており、これが「4o image generation」と呼ばれているわけです。
✅ つまり
- 「4o image generation」=GPT-4oによって行われる画像生成機能のこと。
- ユーザーが自然言語で指示すると、その内容に基づいた画像を生成します。
2. DALL·Eとの関係性
🧠 DALL·Eとは
- OpenAIが開発した、テキスト→画像のAIモデルシリーズ。
- 現在主流はDALL·E 3。
- MidjourneyやStable Diffusionなどと同様に、プロンプトに応じた画像生成が可能。
🔁 GPT-4oとのつながり
実は、GPT-4oのimage generation機能は内部的にDALL·E 3を使用している可能性が高いです。
| 比較項目 | DALL·E 3(ChatGPT組込) | GPT-4o image generation |
|---|---|---|
| 利用インターフェース | 主にChatGPT経由(Plusのみ) | GPT-4o経由、プロンプトで直接生成可能 |
| 画像生成エンジン | DALL·E 3 | おそらくDALL·E 3を利用(内部統合) |
| 日本語対応 | 最近対応強化 | 日本語も画像内に高精度で反映可能 |
| 特徴 | 高精細でリアル寄り | 指示への忠実度が高く、柔軟性あり |
OpenAIは明確に「GPT-4o自身が画像生成モデルを内包している」とは言っておらず、実際の動作としては以下のような仕組みになっています
✅ 事実と推定の整理
| 項目 | 内容 |
|---|---|
| ChatGPT(GPT-4o)での画像生成 | テキストプロンプトから画像を生成可能。これは DALL·E 3エンジンを使っていると明言されている。 |
| GPT-4oの役割 | 画像生成プロンプトの解釈・構造化、画像生成の指示をDALL·E 3に送信する“橋渡し”を行う。 |
| 裏側の実装(推定) | GPT-4oのimage generation機能は、内部的にDALL·E 3 APIまたは類似エンジンを呼び出して実行。 |
🔧 技術的に言えば…
GPT-4o自体はマルチモーダルでありながら、「画像生成」専用のニューラルネット構造を持っているわけではなく、従来のDALL·E 3などの画像生成モデルと連携して画像を生成しています。
これは以下と似ています
- ChatGPTがコードを書くとき → GPTがコードを生成して実行はしない(実行は別環境)
- ChatGPTが画像を作るとき → GPT-4oがプロンプトを整え、DALL·Eが生成を担う
🔎 補足:画像の編集機能(Inpainting)
ChatGPTで画像編集(例:「この画像の背景を変えて」)ができる場合も、その処理は DALL·E 3の編集機能(inpainting) を使って実行されていると見られます。
✅ 結論
GPT-4oはプロンプトの理解・変換を行い、実際の画像生成処理はDALL·E 3が担当していると考えられそうです。
3. 「日本語テキストが画像内に含まれる」背景
以前の画像生成モデル(例:DALL·E 2や初期のDALL·E 3)では、画像内の文字(特に非英語)が崩れることが多かったですが、
GPT-4oでは、日本語や韓国語、中国語などを含んだ画像も正しく生成されることが確認されており、これは大きな進化です。
✅ 日本語が出力できるようになった理由は?
- 新しい画像生成アルゴリズムの改善
- GPT-4oによりプロンプト理解能力の向上
- 背後で動いているDALL·E 3が強化されている、もしくはGPT-4oのマルチモーダル設計での高度な連携処理によるもの
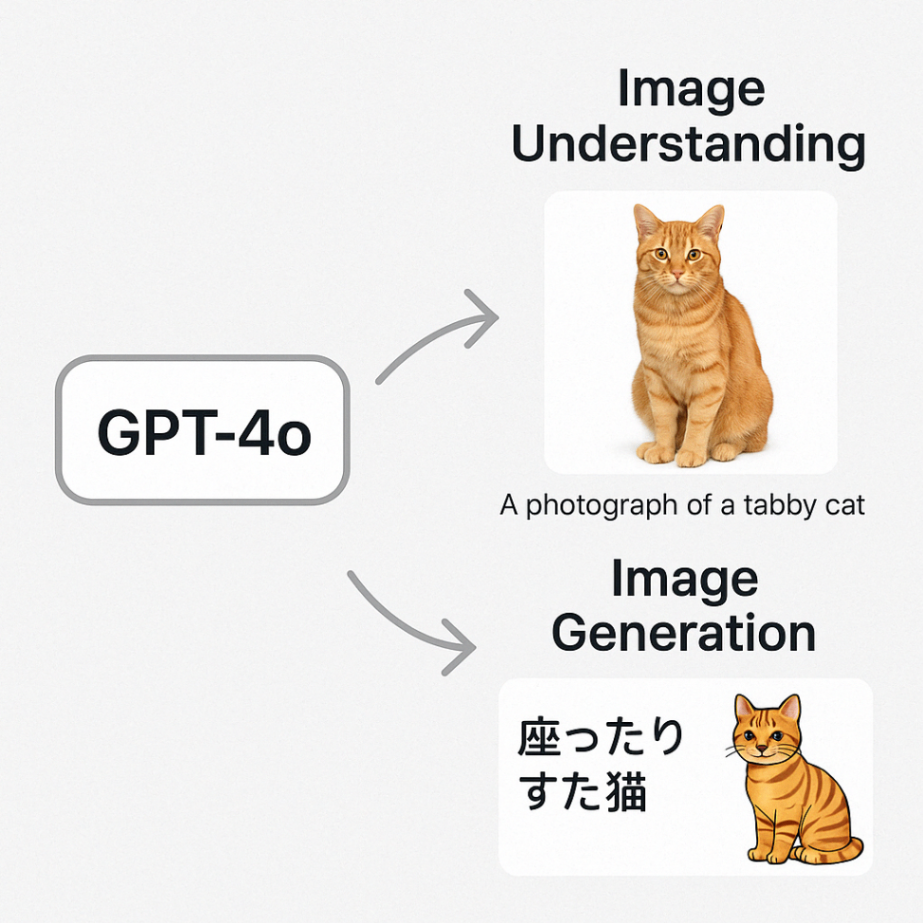
4. GPT-4oには画像認識・生成両方の機能がある
| 機能 | 説明 | GPT-4oでの対応状況 |
|---|---|---|
| 画像認識(Image Understanding) | 画像を入力して、その内容を理解・説明する(例:画像の中に何が写っているかを説明する) | ✅ 可能 |
| 画像生成(Image Generation) | テキストから新たな画像を生成する | ✅ 可能(制限あり) |
🔍 画像生成の制限について
現在のChatGPT(GPT-4o)では以下のように画像生成機能に制限があります
- APIでは現時点で画像生成はまだ未対応(もしくはベータ段階)
- ChatGPTの画像生成は、DALL·E 3ベースで提供されており、GPT-4oの内部統合の一部
つまり
- 画像認識はGPT-4o自身のマルチモーダル処理で直接対応している
- 画像生成は、GPT-4oの一部機能としてDALL·E 3を呼び出している(中身は別モジュール)
🧠 理解の整理
| 理解 | 実際の仕様 | コメント |
|---|---|---|
| GPT-4oは画像認識のみで、生成はできない | ❌ 正確ではない | GPT-4oには画像生成機能も統合されている(ただしDALL·E 3ベース) |
| 画像生成機能はDALL·Eでしかできない | ⭕ ある意味正しい | GPT-4oの画像生成機能の中身はDALL·E 3が担っている |
| GPT-4oはマルチモーダル | ✅ 正しい | テキスト、画像、音声を扱える万能モデルです |
🎨 補足:画像生成はどこから使える?
| 方法 | 対応 | 備考 |
|---|---|---|
| ChatGPT Web UI(Plusユーザー) | ✅ 画像生成OK | GPT-4o経由でDALL·E 3が使われている |
| ChatGPT API(GPT-4o) | 🔜 制限あり・一部非対応 | 画像生成エンドポイントは未公開または限定的 |
| Playground | ❌(画像生成非対応) | 主にテキスト・画像認識のみ |
5. まとめ
表にまとめます。
| 項目 | 内容 |
|---|---|
| 「4o image generation」とは? | GPT-4oモデルで実現される画像生成機能 |
| 中核となる技術 | DALL·E 3と推定(OpenAIによる統合型実装) |
| 特徴 | マルチモーダルに対応・高い指示理解力・多言語(日本語含む)にも対応 |
| 日本語の画像化はなぜ進化した? | モデルの改善とDALL·E 3統合による |
補足:GPTsの状況
2025/04/16現在
GPTs(カスタムGPT)ではまだ4o image generationによる画像生成は未対応でしたが、対応予定だそうです。


chameleonmeme.com/ ビジネスのすべての工程を自分たちの手で行い、 気の合う仲間と楽しく仕事をすることで熱中するためにチームをスタートしました。 お仕事のご相談・お誘いはお気軽にお問い合わせください。 コーポレートサイトのWEBフォームから随時受け付けております🙆
Discussion