[TensorFlowDeveloper]#3 C1W3_Improve MNIST with convolutions
week3はconvolutions(畳み込み)を利用した画像認識処理にチャレンジします。
ちなみに、アサインメントは下記でgitにて公開されてますので誰でも自由にチャレンジすることできます。
TensorFlow Developer Certification C1W3アサインメント
今回の学習では画像認識を効率的に行うための重要な方法であるConvolution(畳み込み) とPooling(プーリング) の利用方法について学びます。
Convolution(畳み込み)
Convloutionとは日本語だと畳み込みと呼ばれてて、とある画像に対してフィルターを使って画像から特徴を抽出する操作です。文章で書いてもいまいちピンとこないと思うので図で表してみます。
元の画像5×5の画像に対し、3×3のフィルターを用いて元の画像に対して3×3のフィールド毎に乗算した結果を足し合わせていき、特徴量マップを生成します。
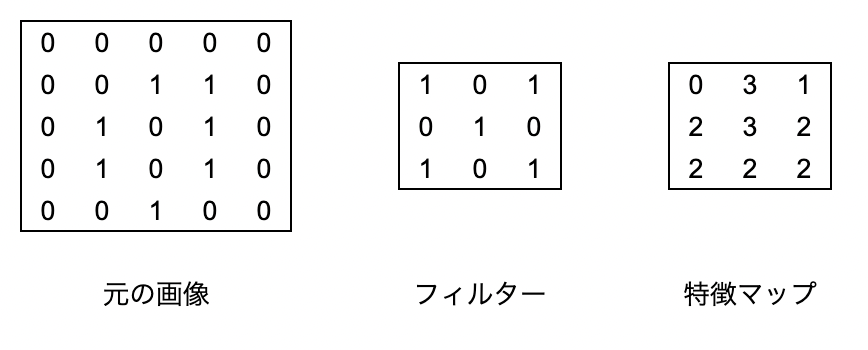
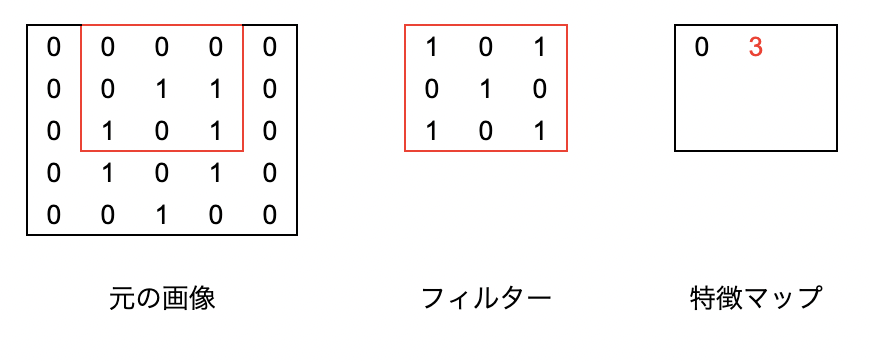
例えば特徴マップの一番上の行の真ん中の3を算出するには下記のようなイメージです。
元の画像の赤い部分とフィルターの各フィールドの乗算の結果を足し合わせて3が算出されます。
下記のサイト等を見るとさらにわかりやすく解説されています。
畳み込みの説明
Pooling(プーリング)
Poolingは情報を圧縮しデータ処理の効率をあげられるようにする処理です。
Convolutionの後に適用されることが多いです。
このアサインメントのではMaxPoolingという、評価する範囲で最も大きい値を採用します。
こちらも文字だとピンとこないと思うので、図にしてみます。
下記のように4×4のデータあった場合に2×2でMaxPoolingを行うと、2×2の中で最も大きい値を採用して、4×4のデータを2×2に圧縮します。
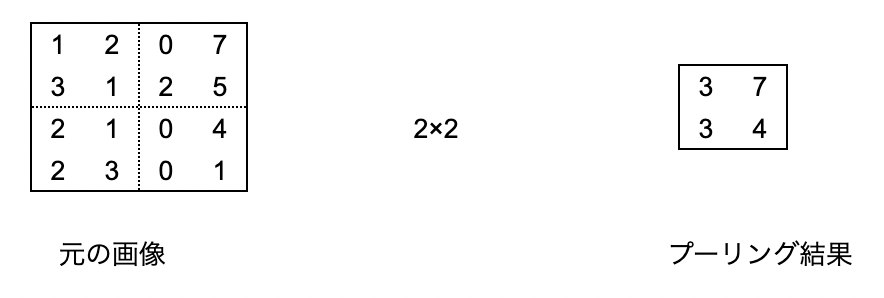
可視化
画像処理においてはその画像、およびフィルタリングした画像がどのような画像かを描写して確認することがよくあります。そこで可視化のためのライブラリをMatplotlibの利用について簡単に説明します。
plt.subplots()
複数のグラフを描画したいという時に使うメソッドです。
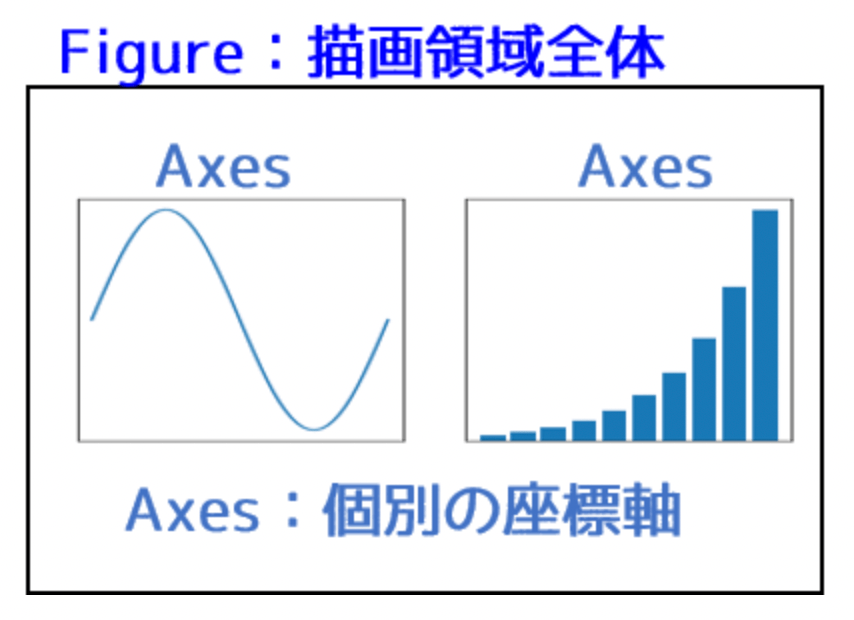
Matplotlibでグラフを描画する際の基本パーツとして、Figure と Axes があります。
下記のようなイメージです。
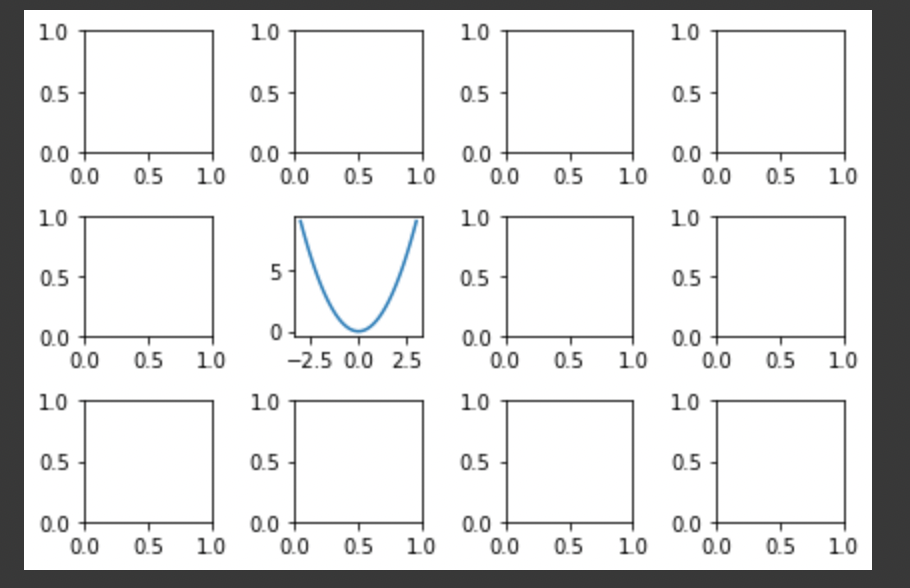
下記のように記載するとnrows×ncolsのグラフが描画でき、FigureとAxesが同時にインスタンス化できます。引数を省略すると1つのサブプロット(グラフ)が描画されます。
fig, axes = plt.subplots(nrows, ncols)
axesは3×4の配列となっており、axesの各配列に描画したいグラフの値を設定することで複数のグラフを描画することができます。
例えば、3×4のグラフ群のうち1,1(右から2番目、上から2番目)の位置に二次曲線をプロットしたい場合は下記のような感じです。
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
fig, axes = plt.subplots(3,4, tight_layout=True)
x = np.linspace(-3,3) #xの配列に-3〜3までの値を設定
y = x**2 #二次曲線を定義
axes[1,1].plot(x,y) #3×4のグラフ群のうち1,1(右から2番目、上から2番目)の位置にプロット
plt.show()
アサインメントの内容
Improve MNIST with Convolutions(畳み込みによるMNISTの改善)
28×28のファッションに関する60,000枚の画像の識別を行うモデルの作成を行う。
単層の畳み込みレイヤーとマックスプーリングにより識別モデルの精度改善を行い、10回未満のエポック(試行回数)により99.5%の精度を達成し、一度でも99.5%の精度を上回ったらトレーニングをストップする。
1.次元の追加と正規化
アサインメントのnotebookの記載に沿って、次元の追加と正規化を行うメソッドを定義する。
def reshape_and_normalize(images):
### START CODE HERE
# Reshape the images to add an extra dimension
images = training_images.reshape(60000, 28, 28,1)
# Normalize pixel values
images = images/255.0
### END CODE HERE
return images
2.コールバック関数の定義
accuracyが99.5%以上になった場合にトレーニングをストップするようにコールバック関数を定義する。
week2で実施した内容とほぼ同様でOK。
class myCallback(tf.keras.callbacks.Callback):
# Define the method that checks the accuracy at the end of each epoch
def on_epoch_end(self, epoch, logs={}):
if(logs.get('accuracy') > 0.995):#accuracyで判定する場合
# Stop if threshold is met
print("\nReached 99.5% accuracy so cancelling training!")
self.model.stop_training = True
pass
3.モデルの定義
モデルの定義を行います。
これまで作ったモデルのレイヤーの前にConvolutionとMaxpoolingのレイヤーを追加します。
# Define the model
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),#隠れ層
tf.keras.layers.Dense(10, activation='softmax')#識別するラベルの数
])
tf.keras.layers.Conv2Dの引数は下記の通りです。
1.作成したい畳み込みの数、この数値は任意の数でよいが32以上の2の累乗であることを推奨
2.畳み込みのサイズ、このケースだと3×3
3.利用するアクティベート関数、このケースだとReLU(x>0の場合はxを返し、それ以外の場合は0を返す)
4.最初のレイヤーにおけるインプットデータのshape、今回の場合は28×28×1
次にMaxPooling2Dで2×2でMaxPoolingを実施してデータを圧縮します。
今回判別する画像データは28×28なので最初のConv2Dのフィルタ処理で26×26(3×3でフィルタしていくので両端と上下の1行が削減される)となり、次のMaxPoolingで2×2で圧縮するので、この時点で13×13のデータとなってます。
これ以降はこれまでのモデルのレイヤーと同様、Flattenで1次元化し、128のユニットを持つレイヤーと、最終レイヤーは判別するラベルの数とあわせて10のユニットを持つレイヤーで構成します。
4.コンパイル
コンパイルは最適化あるゴリスムにadam、損失関数にsparse_categorical_crossentropy、評価指標にaccuracyを指定してコンパイルします。
# Compile the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
5.フィッティング
モデルのフィッティングを行います。
history = model.fit(training_images, training_labels, epochs=10, callbacks=[callbacks])
6.実行結果
五回目のエポックでaccuracyが99.5%となりトレーニングを中止してます。
アサインメントの合格条件を満たすことができました!!
Epoch 1/10
1874/1875 [============================>.] - ETA: 0s - loss: 0.1402 - accuracy: 0.9582<class 'NoneType'>
1875/1875 [==============================] - 35s 19ms/step - loss: 0.1402 - accuracy: 0.9582
Epoch 2/10
1870/1875 [============================>.] - ETA: 0s - loss: 0.0490 - accuracy: 0.9847<class 'NoneType'>
1875/1875 [==============================] - 35s 19ms/step - loss: 0.0489 - accuracy: 0.9848
Epoch 3/10
1872/1875 [============================>.] - ETA: 0s - loss: 0.0312 - accuracy: 0.9902 ETA: 1s - loss: 0.031<class 'NoneType'>
1875/1875 [==============================] - 35s 19ms/step - loss: 0.0312 - accuracy: 0.9902
Epoch 4/10
1875/1875 [==============================] - ETA: 0s - loss: 0.0213 - accuracy: 0.9931 ETA: <class 'NoneType'>
1875/1875 [==============================] - 35s 19ms/step - loss: 0.0213 - accuracy: 0.9931
Epoch 5/10
1872/1875 [============================>.] - ETA: 0s - loss: 0.0156 - accuracy: 0.9950<class 'NoneType'>
Reached 99.5% accuracy so cancelling training!
1875/1875 [==============================] - 35s 19ms/step - loss: 0.0156 - accuracy: 0.9950
Discussion