Unicode - 恩恵と厄介事
はじめに
Unicode が一般的になる以前、ベンダー依存の文字コード(IBM、JEF[富士通]、KEIS[日立]、JIPS[NEC])と、パッケージソフトが動作する環境の文字コードのデータ交換で、苦労することがありました。
そのようなことを経験したので、Unicode に関わる情報を記載しようと思います。
2025/01/23 追記
Unicode に関しての続編、Unicode - 全角半角 という記事も投稿しています。
2025/01/30 追記
本記事で軽く触れた Shift_JISとCP932 についての記事も投稿しています。
参考情報
Unicode
まずは、Unicode(ISO/IEC 10646, JIS X 0221)について記載します。
基本思想
Unicode の基本思想は、「全世界のあらゆる文字を1つの符号化文字集合の下統一する」ことで、下記内容を達成することを目的としています。
- 自国語コンテンツを Unicode で作成すれば、他言語環境のコンピュータでも、ちゃんと自国語で表示される。
- Unicode でデータを作成すれば、他言語環境でもデータ交換ができる。
表意文字
「全世界のあらゆる文字を1つの文字コード」を行う上で、コード空間(格納できる文字数)には限りがあるし、複数言語でのコミュニケーション性(語彙に重きを置いています)が必要なため「表意文字」という概念で統一(Unified)を行いました。
- 似たような字形でも別の意味や使われ方をするものは別の文字として区別されています。
このため ハイフン/マイナス/ダッシュ のように意味が異なる横棒文字が、100文字以上収録されています。 - CJK統合漢字(CJK Unified Ideographs)
- 中国語/日本語/韓国語の漢字を集めると膨大になってしまうため、字形ではなく、出典が同じで同一の意味を持つ文字はひとつに統一してコード化を行いました。
改版を重ねるにつれて、収録文字数が増加し、字形の軽微な相違のみの文字が多くなり、「表意文字」という基本概念は薄れていると感じています。
文字符号化方式
文字コードは、「符号化文字集合」を「文字符号化方式」でコード化したものです。
- 符号化文字集合(CCS:Coded Charcter Set)
- 字形の集合を一意の符号(区点コードなど)で定義したもの
- JIS X0201、JIS X0208、JIS X0212、Unicode(ISO/IEC 10646, JIS X 0221) など
- 文字符号化方式(CSE:Character Encoding Scheme)
- 文字集合をコード化するための一定の規則
- JIS、SJIS、EUC、UTF-8、UTF-16、UTF-32 など
Unicode は「符号化文字集合」で、対応する「文字符号化方式」として、UTF-8、UTF-16、UTF-32 が存在します。
- UTF-8
- Unicode で一番よく利用される形式
- ASCIIは1バイト、その他の部分は2~4バイトという可変長で表現
- 日本語漢字は、ほとんどが3バイトですが、第3・第4水準漢字の大半は4バイト
- UTF-16
- Unicode を 16ビットで表現
- C# string、char は UTF-16
- 収録文字数が増加し、16ビットでは表現しきれなくなり、「サロゲートペア」(一部コード領域で、2つペア[16 + 16ビット]で使って1文字を表す方法)導入
上位サロゲートのコード範囲は D800 〜 DBFF で、下位サロゲートのコード範囲は DC00 〜 DFFF
- UTF-32
- Unicode を 32ビットで表現
恩恵
「符号化文字集合」が、JIS X0201/JIS X0208 のみで構成されていた時代は、登録されている漢字が少なく、氏名などを正確な字形とする目的などで、ユーザ毎にユーザ定義文字(外字)を作成/登録することが多々ありました。
ユーザ定義文字として登録された文字を、他コンピュータで表示させるためには、同一コードに対象ユーザ定義文字を登録する必要があります。
また、ベンダー毎に、JIS X0201/JIS X0208 では足りていない字形を、拡張文字(システム外字)として標準搭載することもありました。
データ交換に携わったことがあるので、ユーザ定義文字、拡張文字の呪縛から解放されて、利便性向上したことが、Unicode 最大の恩恵と実感できています。
厄介事
基本概念「表意文字」、基本機能「合成文字」、および、後から追加された「サロゲートペア」「異体字セレクタ」に関して、手間がかかる局面があります。
表意文字
PDFからの文字抽出ソフトを利用したことがあり、取得した文字データの中に「No-Break Space(U+00A0)」「En Space(U+2002)」「Em Space(U+2003)」などが含まれていました。
これらは、日本語としてデータ処理(比較/並び替え)する上では「Space(U+0020)」に集約が必要となります。
PDF作成ソフト、もしくは、PDFからの文字抽出ソフトでの不具合かもしれませんが、横棒文字、スペースなどが「表意文字」として多数存在する故に発生しています。
合成文字
Unicode では、複数の文字からひとつの文字を合成するしくみがあります。
- 「ポ」U+30DD は、「ホ」に半濁音を合成済みの文字です。
- 「ホ」U+30DB と半濁音 U+309A を連続させると1文字として合成されて表示されます。
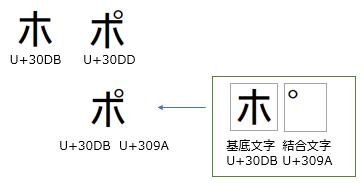
- Unicode のコンセプトとしては「合成済み文字と合成文字(基底文字+結合文字)は等価」というスタンスですが、現実には、そのままだとデータ処理(比較/並び替え)で等価にすることはできず、以下の何れかの正規化が必要となります。
- 合成(合成文字を合成済み文字に揃える)
- 分解(合成済み文字を合成文字に揃える)
C# での振舞いを確認した結果を記載します。
string hoge = "\u30DB\u309A"; // ホ + 半濁音合成文字
// 文字列の長さ
int n1 = hoge.Length; // 2
// 文字数(合成文字を1文字として判断)
System.Globalization.StringInfo si = new System.Globalization.StringInfo(hoge);
int n2 = si.LengthInTextElements; // 1
// サロゲートペア、合成文字、IVS のインデックス取得 → idx.Length = 1, idx[0] = 0
int [] idx = System.Globalization.StringInfo.ParseCombiningCharacters(hoge);
文字列の長さ取得と文字数取得は使い分けが必要で、場合によっては合成文字確認も必要になります。
サロゲートペア
C# での振舞いを確認した結果を記載します。
string hoge = "\uD842\uDF9F"; // 叱 UTF-16で(16 + 16ビット)ペアで1文字
// 文字列の長さ
int n1 = hoge.Length; // 2
// 文字数(サロゲートペアを1文字として判断)
System.Globalization.StringInfo si = new System.Globalization.StringInfo(hoge);
int n2 = si.LengthInTextElements; // 1
// サロゲートペア1文字目、2文字目確認
bool b1 = Char.IsHighSurrogate(hoge, 0); // true
bool b2 = Char.IsLowSurrogate(hoge, 1); // true
// サロゲートペア、合成文字、IVS のインデックス取得 → idx.Length = 1, idx[0] = 0
int [] idx = System.Globalization.StringInfo.ParseCombiningCharacters(hoge);
文字列の長さ取得と文字数取得は使い分けが必要で、場合によってはサロゲートペア確認も必要になります。
異体字セレクタ
日本語、特に人名に使用される漢字には、細かなデザイン違いの異体字が多く存在します。
このように字形の相違がある異体字全てに、文字コードを付与することは無理があります。
このため、親字の後ろに異体字セレクタ(U+E0100~)と呼ばれるコードを付加して字形を表現する手法(IVS:Ideographic Variation Sequence)が導入されました。

C# での振舞いを確認した結果を記載します。
string hoge = "葛\U000E0100"; // "葛\uDB40\uDD00" と等価
// 文字列の長さ
int n1 = hoge.Length; // 3(UTF-16としての文字列の長さ)
// 文字数(IVSを1文字として判断)
System.Globalization.StringInfo si = new System.Globalization.StringInfo(hoge);
int n2 = si.LengthInTextElements; // 1
// サロゲートペア1文字目、2文字目確認
bool b1 = Char.IsHighSurrogate(hoge, 1); // true
bool b2 = Char.IsLowSurrogate(hoge, 2); // true
// サロゲートペア、合成文字、IVS のインデックス取得 → idx.Length = 1, idx[0] = 0
int [] idx = System.Globalization.StringInfo.ParseCombiningCharacters(hoge);
文字列の長さ取得と文字数取得は使い分けが必要で、場合によってはIVS確認も必要になります。
出典
本記事は、2025/01/10 Qiita 投稿記事の転載です。
Discussion