序文
async/await の背後にある驚くべきエンジニアリングと,
シングルスレッドで百万並行処理に辿る道。
概要
もしあなたが大多数の Python 開発者と同じなら,おそらく日常業務で asyncio を使っているでしょう。asyncやawaitキーワードをあちこちに散りばめ,物事を「並行して」実行する必要があるときにはasyncioをインポートする。しかし,ここで不都合な真実をお伝えしましょう:私たちの多くは,非同期コードを「カーゴ・カルト・プログラミング ¹」のごとく,表面的に真似ているに過ぎないのです。
最近,昔のコードをレビューしていて,思わず背筋が凍るパターンをいくつも発見しました。async コンテキスト内でasyncio.run()を呼び出しているパターン,aiohttpの代わりにrequestsを使っているパターン,そして私一番のお気に入りは,API 呼び出しの並行性を実現するためにmultiprocessingを使い,なぜメモリ使用量が急増するのか首をひねっているパターンです。
そろそろ,私たちは asyncio を真に理解する時が来ました ― 単なる文法ではなく,その背景にある物語,哲学,そして単一スレッドで数百万の並行接続を処理することを可能にする驚くべきエンジニアリングを。
この文章は,単なる asyncio のチュートリアルではありません。これは,それを可能にするハードウェア割り込みから,それを扱いやすくするエレガントな文法まで,非同期プログラミングの進化を通した旅です。
私たちは,スクラッチから独自の event loop を構築し,どのようにして協調的マルチタスク ² が I/O バウンドなアプリケーションの秘密兵器となったのかを発見しましょう。
シートベルトを締めてください。発車します。
目次
- 1. Foundations:問題領域の理解
- 2. ハードウェアと OS の基礎
- 3. プログラミングモデルの進化
- 4. スクラッチからの旅:一歩ずつ理解を構築する
- 5. よくある Anti-Pattern とその回避方法
- 6. パフォーマンスとスケーラビリティ:百万並行処理の夢
- 7. 未来:Asyncio が向かう先
- 8. 結論:適切なツールの選択
- A. 参考資料
1. Foundations:問題領域の理解
1.1 並列性 vs 並行性:根本的な区別
Asyncio に飛び込む前に,まず用語を整理しましょう。「並列」と「並行」という用語はしばしば同じ意味で使われますが,これらは根本的に異なる概念を表しています:
- 並列性: 複数の CPU コア上での真の同時実行。コーヒーショップで複数のバリスタが,それぞれ異なる注文を同時に処理している様子を想像してください。
- 並行性: Time-slicing や協調的な譲歩を通じて,複数のタスクを一度に管理し,同時性の幻を見せること。非常に熟練した一人のバリスタが複数の注文を同時にさばく — 注文を受けながら別の人のコーヒーを淹れ,次の客を待っている間に器具を掃除する — 様子を想像してください。
これを CPU コアの観点から説明しましょう:

この区別は学術的な揚げ足取りではありません。これは,あなたがどのツールを手に取るべきかを決定します:
-
CPU バウンドなタスク: (CPU-bound) I/O 待ち時間よりも CPU 処理時間が支配的
- 👉🏻 並列性が必要(マルチプロセシング,複数コア)
-
I/O バウンドなタスク: (I/O-bound) I/O 待ち時間が CPU 処理時間を圧倒的に上回る
- 👉🏻 並行性の恩恵を受ける(asyncio,単一コアで十分)
I/O バウンドなタスクに並列性が必要ない理由は,プログラマーなら誰もが知っておくべきレイテンシの数値によって見事に説明されます。
1.2 プログラマーなら知っておくべきレイテンシ数値 ³
これらの数値を人間の時間スケールに換算して考えてみましょう:
もし 1 CPU サイクル = 1 秒なら:
| 操作 | 所要時間 | 人間の感覚的な例え |
|---|---|---|
| L1 キャッシュ参照 | 0.5 秒 | 鼓動 1 回 |
| L2 キャッシュ参照 | 7 秒 | 長いあくび |
| Mutex のロック/解除 | 25 秒 | コーヒーを淹れる |
| メインメモリ参照 | 100 秒 | 歯を磨く |
| ネットワーク経由のパケット送信 | 5.5 時間 | 昼食から仕事終わりまで |
| SSD ランダム読み取り | 1.7 日 | 普通の週末 |
| ディスクシーク | 16.5 週 | 大学の 1 学期 |
| 東京 → LA パケット送信 | 3.6 年 | 学士号取得期間 |
何か気づきませんか?ネットワーク I/O は CPU 操作よりも数百万倍も遅いのです。単一のネットワークリクエストの間に,CPU は数十億もの命令を実行できるでしょう。この莫大な速度差こそが,非同期プログラミングが存在する理由そのものです。
1.3 I/O 操作の本質⁴
プログラムがネットワークリクエストを行ったり,ディスクから読み取ったりするとき,実際には以下のことが起こっています:
- System call: プログラムがカーネルに I/O 操作の実行を要求する
- カーネルによる委譲: カーネルがハードウェア(ネットワークカード,ディスクコントローラ)に処理を委譲する
- ハードウェア操作: 物理的操作が行われる(電磁波の発生,ディスクヘッドの移動)
-
割り込み: 操作が完了すると,ハードウェアは割り込みを発生させて CPU に通知し,CPU はカーネルの割り込みハンドラに jump する
(👉🏻ハードウェアは,物理的な配線を通して,CPU の pin を物理的に引っ張るようなシーンを想像してください) - 復帰: カーネルが必要なデータを準備し,プログラムに制御を戻す
ステップ 2〜4 の間,プログラムのスレッドはブロックされています — アイドル状態で座り,メモリを消費し,CPU よりも文字通り数百万倍遅い何かを待っているのです。これが asyncio が解決する根本的な問題です。

上のステップ 4 では,ハードウェアが完了を通知するために CPU を割り込みます(画像の No.1)。
その後,カーネルが割り込みを処理します(画像の No.2〜No.4)。
2. ハードウェアと OS の基礎
2.1 ハードウェアの内部:割り込みと System Call
ここで重要な洞察があります:ステップ 2〜4 の間,スレッドは存在する必要がありません。ハードウェアは準備ができたら CPU を割り込みます。従来のブロッキング I/O は,スレッドを生存させたまま待機させることで,この時間を無駄にしています。
2.2 オペレーティングシステムの解決策:I/O 処理の進化
オペレーティングシステムは,I/O を効率的に処理するために洗練されたメカニズムを進化させてきました:
select() (1983): 元祖 multiplexing⁵
使い方⁶:
// これは,file descriptor を監視するための基本的な select() パターンを示しています
fd_set read_fds; // 監視したい file descriptor を保持するセットを作成
FD_ZERO(&read_fds); // セット内のすべてのビットをクリア(空で初期化)
FD_SET(socket_fd, &read_fds); // ソケット file descriptor を監視セットに追加
// select() 呼び出しは,少なくとも 1 つの fd が I/O の準備ができるまでブロックする
// (ハードウェア割り込みが発生すると,select() 呼び出しが戻る)
int ready = select(max_fd + 1, &read_fds, NULL, NULL, &timeout);
// select() が戻った後,どの file descriptor が準備できているかをチェックする
if (ready > 0) {
if (FD_ISSET(socket_fd, &read_fds)) {
// ここで「コールバック」が発生する - 準備のできたソケットを処理する
handle_socket_data(socket_fd); // このソケットのデータを処理
}
// セット内の他の file descriptor をチェック。..
}
select()はポーリングベースの system call です。これを呼び出すと,カーネルはセット内の各 file descriptor をチェックし,I/O の準備ができているかどうかを確認します。どれも準備できていない場合,いずれかが準備できるまでブロックし,その後制御を戻します。
プログラムがselect()をどのように利用するかは,効率に大きく影響します。プログラムは,他の作業を処理するか,単にselect()が戻るまで待つかを選択できます。次のセクションで,threading と asyncio がselect()をどのように異なる方法で使用するかについて議論します。
注:select()自体は直接コールバックを使用しません。「コールバックパターン」は,select()を file descriptor をハンドラ関数にマッピングする event loop でラップするときに現れます。これは,後述の Python のイベント駆動の例で示されます。
epoll⁷/kqueue⁸ (2002/2000): 現代的なソリューション
macOS で Gradio を開発した方は,ログの中に KqueueSelector という単語が出てくるのを見たことがありませんか? これは,macOS がselect()の代わりに kqueue を使用しているためです。
io_uring⁹ (2019): 最新の進化
3. プログラミングモデルの進化
何千もの HTTP リクエストを並行して行うサービスを構築していると想像してください。あなたならどう設計しますか?
3.1 Threading アプローチとその限界
I/O 並行性に対する従来の解決策は threading でした — 複数のスレッドを作成し、それぞれがselect()の戻りを待つことで,全体のスループットを向上させます。以下は,並行操作のためにスレッドを使用する簡略化された例です:
import threading, requests
def handle_request(url):
response = requests.get(url) # このスレッドをブロックする
return process(response)
# 1000 の並行リクエストのために 1000 のスレッドを作成
threads = []
for i in range(1000):
thread = threading.Thread(target=handle_request, args=(f"http://api.example.com/{i}",))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
このアプローチは,「普通の人」が遭遇するほとんどのケースでうまく機能し,直感的です — 各スレッドが独自の処理を行います。もっと並行性が必要ですか? もっとスレッドを立てましょう!
しかし,この方法は,数千の高頻度接続(私の Mac では約 10,000)にスケールしようとすると突然破綻します。この規模に達すると,スレッドを追加しても役に立たず,実際には事態を悪化させます。なぜなら,それらのスレッドが CPU 時間を争い,OS は実際の作業よりもスレッド間の context switch により多くの時間を費やすからです。
この問題の一つの解法は,preemptive multitasking(強制的な横取り)ではなく,協調的マルチタスク(coroutine)を使用することです。Coroutine が自発的に制御を譲ることにより,スレッド切り替えのオーバーヘッドがなくなります。
3.2 イベント駆動プログラミングの誕生
イベント駆動プログラミングはエレガントな解決策を提供しました:各操作にスレッドを専念させる代わりに,すべての I/O 操作を管理する単一のスレッドと event loop を使用するのです。
このアイデアは単純な事実から来ています:プログラムは常に他の作業を行い,後でselect()呼び出しを再訪することができます。
処理が I/O より数百万倍速いことを思い出してください。I/O の完了を待っている間,プログラムは他のタスクを処理できます。タスクが終わってからselect()に戻っても遅くはありません。
これが協調的マルチタスクの核心となる考え方です。
下記のプログラムは,イベント駆動を用いた TCP で送られてきたデータをそのまま返すシンプルのサーバーです。
import selectors
import socket
selector = selectors.DefaultSelector()
fd_sock_map = {}
def accept_connection(server_sock):
client_sock, addr = server_sock.accept()
client_sock.setblocking(False)
selector.register(client_sock.fileno(), selectors.EVENT_READ, handle_client)
fd_sock_map[client_sock.fileno()] = client_sock
def handle_client(client_sock_fd):
client_sock = fd_sock_map[client_sock_fd]
data = client_sock.recv(1024)
if data:
client_sock.send(data) # エコーバック
else:
selector.unregister(client_sock)
client_sock.close()
# メイン event loop
while True:
events = selector.select() # I/O の準備ができるまでブロック
for key, mask in events:
callback = key.data
callback(key.fileobj)
このイベント駆動アプローチは,コーヒーショップを経営するようなものです。客が来たら,彼らをテーブルに案内し,彼らの注文を待つ間も他の客にサービスを提供します。注文の準備ができたら,それを提供し,次の注文を受けます。コーヒーが抽出されるのを待っている間でも,注文を受け取るのを決して止めません。待っている時間があっても,他にすることがないときにだけ待つので,まだ仕事をこなしていることになります。
言い換えれば,threading は各客を処理するために複数のバリスタを雇うようなものです — 最初はより多くの仕事をこなせます。しかし,何千もの客がいるとき,何千ものバリスタを雇っても役に立ちません。なぜなら,彼らは同じリソース(コーヒーマシン,カウンタースペースなど)を争い,彼らを管理するオーバーヘッドが実際に行われている作業を超えてしまうからです。
asyncio アプローチは,大規模なスケーラビリティの改善を約束しました:
- 数千の接続を処理する単一スレッド
- Context switch のオーバーヘッドなし
- 最小限のメモリフットプリント
- 同期プリミティブが不要
しかし,asyncio は大量な計算を必要とするタスクには適していません。店員が大掃除に没頭している間,誰もサービスを受けられないのと同じです。
3.3 コールバック地獄:解決策が問題になるとき
イベント駆動プログラミングはパフォーマンスの問題を解決しましたが,新たな問題を生み出しました:コールバック地獄です。以下を行う単純な HTTP リクエストの処理を考えてみましょう:
- リクエストをパースする
- データベースをクエリする
- 外部 API コールを行う
- レスポンスをフォーマットして返す
コールバックを使うと,これは以下のようになります:
def handle_request(request, callback):
parse_request(request, lambda parsed_req:
query_database(parsed_req.user_id, lambda db_result:
make_api_call(db_result.endpoint, lambda api_response:
format_response(api_response, lambda formatted:
callback(formatted)))))
このアプローチの問題点は,特殊の文法がないと,処理 A が完了した後の処理 B をコールバックで渡す必要があるため,ネストされたコードが急速に読みにくくなることです。これにより,以下のような問題が発生します:
- コールバック地獄: コードが垂直ではなく水平に成長する
- 例外処理の悪夢: 各レベルで独自の例外処理が必要
- デバッグ地獄: スタックトレースが無意味になる
- 制御の反転: 論理の自然な流れが破壊される
ここで,Python の Generator,そして最終的には async/await が救世主として登場しました。
4. スクラッチからの旅:一歩ずつ理解を構築する
asyncio を真に理解するために,私はスクラッチから段階的に洗練された event loop を構築しました。この旅を一緒にたどりましょう。
各リクエストに 5 秒かかる非常に遅いサーバーがあると仮定します。私の目標は,クライアントから 10 のリクエストをできるだけ速く送信し,合計時間を測定することです。
明らかに,リクエストを順次送信すると 50 秒かかります(10 リクエスト × 各 5 秒)。これをどう改善できるか見てみましょう。
4.1 ステージ 1:コールバック地獄を覗く
このタスクは複数のステージに分割でき,I/O 操作の境界,つまりselect()呼び出しに制御を戻す必要がある場所が境界になります。
ステップは以下の通りです:
誰もが最初に反応すること:非同期が欲しければ,コールバックを使わなければならない。各コールバックは,event loop に制御を戻すステージ境界を表します。私たちは,Selector が,ソケットが次の操作の準備ができたときに次のコールバックを呼び出すことを期待します。
まず,make_tcp_request関数です:
import selectors
import socket
selector = selectors.DefaultSelector()
data_to_send = [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
def make_tcp_request(req_id: int) -> None:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setblocking(False)
try:
sock.connect(('localhost', 8080))
except BlockingIOError:
pass
def on_connected(key: selectors.SelectorKey, mask: int) -> None:
selector.unregister(key.fd)
message = f"Request {req_id}"
sock.send(message.encode())
def on_data_received(key: selectors.SelectorKey, mask: int) -> None:
data = sock.recv(4096)
response = data.decode()
print(f"Response for Request {req_id}: {response}")
selector.unregister(key.fd)
sock.close()
data_to_send.remove(req_id)
selector.register(sock.fileno(), selectors.EVENT_READ, on_data_received)
selector.register(sock.fileno(), selectors.EVENT_WRITE, on_connected)
このコードを見ると,許容できるように思えますが,ステージは 2 つ(接続と受信)しかありませんからです。もっとステージがあったらどうなるか想像してみてください — コールバックが深くネストされ,コードはすぐに読めなくなります。
event loop のコードは以下の通りです:
def select_loop() -> None:
while data_to_send:
events = selector.select(timeout=1)
for key, mask in events:
callback = key.data
callback(key, mask)
if __name__ == "__main__":
for req_id in data_to_send:
make_tcp_request(req_id)
select_loop()
make_tcp_request関数では,selectorは file descriptor のみを保存し,後からそこからソケットオブジェクトを抽出できないことに注意してください。私たちはsockオブジェクトを関数スコープに保持し,コールバックが closure を通じてそれを捕捉します。
4.2 ステージ 2:クラスを使った基本的な Event Loop
コールバック地獄からの脱出の時が来ました!各コールバックを別々の関数として書き,それらを「連鎖的」につなげればいいと考えがちです。しかし,これには問題があります:それらの関数間でどのように状態を共有するのでしょうか?同じソケットオブジェクト,同じリクエスト ID などが必要です。
オブジェクト指向プログラミングの出番です!
クラスを使用してクリーンな状態管理システムを構築しましょう:
import selectors
import socket
selector = selectors.DefaultSelector()
data_to_send = [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
class BasicTCPClient:
def __init__(self, req_id: int) -> None:
self.host = 'localhost'
self.port = 8080
self.req_id = req_id
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setblocking(False)
self.sock = sock
def make_tcp_request(self) -> None:
try:
self.sock.connect((self.host, self.port))
except BlockingIOError:
pass
selector.register(self.sock.fileno(), selectors.EVENT_WRITE,
self._on_connected)
def _on_connected(self, key: selectors.SelectorKey, mask: int) -> None:
selector.unregister(key.fd)
message = f"Request {self.req_id}"
self.sock.send(message.encode())
selector.register(self.sock.fileno(), selectors.EVENT_READ,
self._on_data_received)
def _on_data_received(self, key: selectors.SelectorKey, mask: int) -> None:
data = self.sock.recv(4096)
response = data.decode()
print(f"Response for Request {self.req_id}: {response}")
selector.unregister(key.fd)
self.sock.close()
global data_to_send
data_to_send.remove(self.req_id)
美しい!すべてのコールバックがクラスのメソッドになり,selfを参照することで簡単に状態を共有できます。
event loop のコードは同じままです:
def select_loop() -> None:
while data_to_send:
events = selector.select(timeout=1)
for key, mask in events:
callback = key.data
callback(key, mask)
if __name__ == "__main__":
clients = [BasicTCPClient(req_id) for req_id in data_to_send]
for client in clients:
client.make_tcp_request()
select_loop()
このクラスベースのアプローチ(ステートマシンパターン)は,多くのプログラミング言語における非同期サポートの終点です — 従来の Java NIO,C++20 以前の C++,コールバック多用の Node.js などの言語はこの段階にとどまり,開発者にステートマシンの手動管理とネストしたコールバックの複雑さの処理を要求し続けます。Python の旅はこの先へ続き,今日私たちが知っているエレガントな async/await 文法へと至りました。
余談ですが,誤って設定された JavaScript トランスパイラ(ES5 をターゲットにしている)によって生成されたコードをたまたま見たことがある方(私のように 😁),Promise の実装がこのステージと非常に似ていることに気づくでしょう。
次に,Python が Generator でこれをどうさらに改善するかを見ていきましょう。
4.3 ステージ 3:Generator と yield の魔法
手動コールバック制御からの脱出の時が来ました!解決策は Python の Generator — 一時停止と再開が可能な関数 — にあります。私たちのロジックを複数のコールバックに分割する代わりに,I/O 境界で制御を yield する単一の,線形フローな関数として非同期操作を書くことができるのです。この手法で,制御を譲り合う,協調的マルチタスク(coroutine)が実現されました。
Generator:一時停止可能な関数
4 人のプレイヤーを紹介する前に,このすべてを可能にする魔法の材料である Python Generator とyield文法の進化を理解しましょう。
Python 2.2 (2001): yieldの誕生
Python はyieldキーワードで Generator を導入し,実行を一時停止および再開できる関数を作成しました:
def simple_generator() -> Generator[int, None, None]:
for i in range(3):
yield i # ここで一時停止,値を吹き出し,再開されるのを待つ
gen = simple_generator()
for item in gen:
print(item) # 出力:0, 1, 2
これは画期的でした — 呼び出し間で状態を維持できる関数!
ですが,その時の用途はただのイテレーションに限られていました。
Python 2.5 (2006): yieldが双方向になる
send()メソッドにより,Generator は値を生成するだけでなく,受け取ることもできるようになりました:
def echo_generator() -> Generator[Any | None, Any, None]:
value = None
while True:
value = yield value # 値を受信し AND 送信する
print(f"Generator received: {value}")
gen = echo_generator()
next(gen) # Generator を起動する
for v in [10, 20, 30]:
returned = gen.send(v) # 値を Generator に送り込む
print(f"Generator yielded: {returned}")
この双方向通信は,結果のデータの渡し受けを可能にし,後に async/await を可能にしました。
Python 3.3 (2012): yield from - ゲームチェンジャー
yield from文法により,Generator は他の Generator にシームレスに委譲できるようになりました:
def sub_generator(n: int) -> Generator[int, Any, str]:
for i in range(n):
yield i
return "sub-generator done" # Generator から戻り値を返す!
def main_generator() -> Generator[Any, Any, None]:
yield "Start"
result = yield from sub_generator(3) # 委譲し AND 戻り値を捕捉する
print(f"Sub-generator returned: {result}")
yield "End"
イテレートされると,以下を生成します:
Start
0
1
2
Sub-generator returned: "sub-generator done"
End
yield fromの魔法:
- 透過的な委譲: 値は通常の関数呼び出しのようにサブ Generator に流れる
- 例外伝播: 例外が自然にバブルアップする
- 戻り値捕捉: サブ Generator が完了したときに戻り値を取得できる
-
双方向通信:
send()呼び出しはアクティブなサブ Generator に通過する
Asyncio 交響曲の 4 人のプレイヤー
この魔法を可能にする 4 人の主要なプレイヤーを紹介する必要があります:
- Generator: 主役 — 非同期ワークフローを定義する一時停止可能な関数
- Future: まだ準備できていない結果のためのプレースホルダ
- Task: Generator を駆動し,そのライフサイクルを管理する橋渡し役
- EventLoop: すべてをオーケストレーションする指揮者
これらがどのように連携するか見てみましょう。これが私たちの新しいmake_tcp_request関数です — 同期コードのように読めることに注目してください:
def make_tcp_request(req_id: int) -> Generator[Future, None, str]:
"""
各非同期境界で Future を yield する Generator 関数。
これは非同期操作全体を単一の線形関数として表します。
重要な洞察:yield/yield from により,同期のように「見える」が,
実際には I/O 境界で協調的に制御を譲る非同期コードを書くことができます。
"""
# ソケットを作成
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setblocking(False)
# ステージ 1: 接続
connect_future = Future()
try:
sock.connect(('localhost', 8080))
except BlockingIOError:
pass
# インラインでコールバックを定義 - ここで Future がコールバックと Generator の世界を橋渡しする
def on_connected():
print(f"Connection established for request {req_id}")
selector.unregister(sock.fileno())
connect_future.set_result(None)
selector.register(sock.fileno(), selectors.EVENT_WRITE, on_connected)
# future から yield - これは接続が完了するまで Generator を中断する
yield from connect_future
# ステージ 2: データ送信
message = f"Request {req_id}"
sock.send(message.encode())
# ステージ 3: レスポンス受信
receive_future = Future()
def on_data_received():
selector.unregister(sock.fileno())
data = sock.recv(4096)
response = data.decode()
receive_future.set_result(response)
selector.register(sock.fileno(), selectors.EVENT_READ, on_data_received)
# 受信 future から yield
response = yield from receive_future
print(f"Response for Request {req_id}: {response}")
sock.close()
return response
美しい!非同期ワークフロー全体が単一の関数に収まりました。もうコールバックの金字塔はありません。しかし,これはどのように機能するのでしょうか?
プレイヤー 1: Future — 将来の約束
Futureは,将来利用可能になる値のプレースホルダです。これはコールバックの世界と Generator の世界を橋渡しします:
class Future:
def __init__(self) -> None:
self._result: Any = None
self._callbacks: list[Callable[[], None]] = []
def set_result(self, result: Any) -> None:
"""結果を設定し,完了としてマークする。これにより future が'解決'される。"""
assert self._result is None
self._result = result
# この結果を待っているコールバックを実行する
for callback in self._callbacks:
callback()
def add_callback(self, callback: Callable[[], None]) -> None:
"""この future が完了したときに実行されるコールバックを追加する。"""
if self._result is not None:
callback() # すでに完了しているので即時呼び出し
else:
self._callbacks.append(callback)
def __iter__(self):
"""Future を'yield self'によって完了するまで'待機可能'にする。"""
if self._result is None:
yield self # 制御を event loop に戻す
return self._result
魔法は__iter__()にあります。__iter__()を持っているクラスは,自動的に Generator になり,yield できるようになります。私たちの Generator がyield from connect_futureを行うとき,Python はiter(connect_future)を呼び出します。future が準備できていなければ,それは自分自身を呼び出し元に yield します。準備できていれば,結果を return します。
プレイヤー 2: Task — Generator 駆動装置
Taskは私たちの Generator をラップし,その実行を駆動します。これは event loop と私たちの一時停止可能な関数の仲介役です:
class Task:
def __init__(self, generator: Generator[Future, None, Any]) -> None:
self._generator = generator
self._done = False
self._result: Any = None
def step(self) -> None:
"""
Generator を 1 ステップ進める。
これは Task が実行準備ができたときに event loop によって呼び出される。
"""
if self._done:
return
try:
# Generator が何を待っているか尋ねる
future = next(self._generator)
# future が完了したときにこの Task を再開するコールバックを登録する
future.add_callback(lambda: event_loop.schedule_task(self))
except StopIteration as e:
# Generator が完了し,return 文で値を返した
self._done = True
self._result = getattr(e, 'value', None)
def done(self) -> bool:
return self._done
これが重要なフローです:
-
task.step()が Generator でnext()を呼び出す - Generator は
yield from futureに当たるまで実行される - Generator は future を Task に yield して戻す
- Task はコールバックを登録する:「この future が完了したら,私を再実行するようにスケジュールして」
- Task はコールバックが発火するまで休止状態になる
プレイヤー 3: EventLoop — オーケストレーター
event loop はすべてを調整します — 準備のできた Task を実行し,I/O イベントを処理します:
class EventLoop:
def __init__(self) -> None:
self._ready_tasks: list[Task] = []
def schedule_task(self, task: Task) -> None:
"""次のイテレーションで実行する Task をスケジュールする。"""
if not task.done():
self._ready_tasks.append(task)
def create_task(self, generator: Generator[Future, None, Any]) -> Task:
"""新しい Task を作成してスケジュールする。"""
task = Task(generator)
self.schedule_task(task)
return task
def run_until_complete(self) -> None:
"""すべての Task が完了するまで event loop を実行する。"""
while self._ready_tasks:
# 準備のできた Task を処理する
ready_tasks = self._ready_tasks[:]
self._ready_tasks.clear()
for task in ready_tasks:
task.step()
has_pending_io = len(selector.get_map()) > 0
has_ready_tasks = len(self._ready_tasks) > 0
# すべての Task と I/O が完了したら終了する
if not has_pending_io and not has_ready_tasks:
break
# I/O イベントを処理する
if not self._ready_tasks:
# 準備ができている Task のないときだけブロックする
events = selector.select(timeout=0.1)
for key, _ in events:
callback = key.data
callback() # これは future の結果を設定し,Task コールバックをトリガーする
ダンス:どのように連携するか
コードを実行するときに何が起こるかを追ってみましょう:
-
Generator の作成:
make_tcp_request(1)が Generator を作成しますが、まだ実行しません - *Task のラップ**:
event_loop.create_task(generator)がそれを Task でラップしてスケジュール -
最初のステップ:event loop が
task.step()を呼び出し、それがnext(generator)を呼び出す -
Generator の実行:
yield from connect_futureに到達し、Generator が一時停止して future を yield - Task コールバック:Task が future が完了したときに自身をスケジュールするよう登録
-
I/O 待機:event loop が
selector.select()を処理し、ソケットが書き込み可能になるのを待つ -
コールバック起動:ソケットが準備できたら、
on_connected()が実行され、connect_future.set_result(None)を呼び出す - 連鎖反応:Future がコールバックを呼び出し、Task を再度実行するようにスケジュール
-
再開:event loop が Task を再度実行し、
yield fromが返り、Generator が続行 - 繰り返し:このプロセスが受信ステージでも繰り返される
シーケンス図で表すと以下のようになります。ご参考までに:
美しいのは,コールバックがまだ存在することです(セレクターには必要)が,線形 Generator 関数の内部に隠されていることです。Generator はまさに正しい瞬間に制御を譲り,Task/Future システムが,I/O が完了したときに再開されることを保証します。
合成可能性:真の勝利
最高の部分は?Generator は自然に合成されます:
def consume_response() -> Generator[Future, None, None]:
req_id = 1234
resp = yield from make_tcp_request(req_id) # 既存の Generator を再利用!
print(f"Consumed response: {resp}")
他の Generator からyield fromでき,シンプルな構成要素から複雑な非同期ワークフローを構築できます。これが,モダンな async/await 構文が構築される基盤です。
ステージ 2 のコールバック版と比較してみてください:
-
ステージ 2:複数のコールバックメソッド,
selfでの状態共有,複雑な制御フロー - ステージ 3:単一の線形関数,ローカル変数,自然な制御フロー
イベント駆動プログラミングのパフォーマンス上の利点を維持しながら,コールバック地獄を排除しました。4 人のプレーヤーが調和して働き,実際には高度に並行的な同期コードの錯覚を作り出します。
次のステップは,おなじみのasync/awaitの話ですが,これはこの Generator ベースの基盤の上に構築された単なる糖衣構文なので,ここでは繰り返しません。
5. よくある Anti-Pattern とその回避方法
asyncio がどのように機能するかを理解したので,よくある間違いとその解決策を見てみましょう。
5.1 「偽の非同期」Anti-Pattern
Anti-pattern 1:非同期コード内のブロッキング呼び出し
# 間違い:これは event loop 全体をブロックします
async def bad_example():
response = requests.get("http://api.example.com") # ブロッキング!
return response.json()
# 正しい:非同期 HTTP クライアントを使用
async def good_example():
async with aiohttp.ClientSession() as session:
async with session.get("http://api.example.com") as response:
return await response.json()
また,非同期関数内での time.sleep の使用
# 間違い:event loop 全体をブロック
async def bad_example():
time.sleep(1) # すべてが停止!
# 正しい:event loop に制御を戻す
async def good_example():
await asyncio.sleep(1) # 他のタスクが実行できる
Anti-pattern 2:新しい event loop の作成
# 間違い:非同期関数内でこれを行わないでください
async def bad_example():
result = asyncio.run(some_coroutine()) # 新しいループを作成!
return result
# 正しい:コルーチンを await するだけ
async def good_example():
result = await some_coroutine()
return result
5.2 並行性の Anti-Pattern
Anti-pattern 3:並行したいタスクの順次 await
# 間違い:これらは並行的ではなく順次実行されます
async def bad_example(urls):
results = []
for url in urls:
result = await fetch_url(url) # それぞれを待つ
results.append(result)
return results
# 正しい:並行性のために gather または create_task を使用
async def good_example(urls):
tasks = [asyncio.create_task(fetch_url(url)) for url in urls]
results = await asyncio.gather(*tasks)
return results
6. パフォーマンスとスケーラビリティ:百万並行処理の夢
asyncio が大規模な並行性を処理できるようにするパフォーマンス特性を探ってみましょう。
しかし,重要な事実を共有しなければなりません。多数の並行タスクを処理する場合(私の感覚では数万以上)を除いて,asyncio は一般的なワークロードに対して threading より必ずしも高速ではありません。
また:
- Asyncio は計算タスクでは勝てません
- Context switch のオーバーヘッドが大きい,少数の I/O 操作のみを必要とする一般的な並行ダウンロードシナリオでは,asyncio は数ミリ秒しか速くありません
- 状況 2 では,asyncio はメモリをより少なく消費しません
- Asyncio のメンタルモデルを理解する必要があります
誰かがこう尋ねるかもしれません:「asyncio が常に速いわけではないなら,なぜ使うべきなのか?」
私たちは常に夢を持っています,たとえそれらが実生活で今すぐ必要でなくても。しかし,私が思うに,私たちが選ぶべきものは,将来偉大なことを達成する可能性を排除すべきではありません。つまり,より洗練された,将来性のある技術を選ぶということです。
6.1 ベンチマークシナリオ
自宅で実際の百万接続のワークロードをシミュレートするのは非常に困難なので,大量のスリープ操作を使用して,並行タスクの数が増えたときに異なる並行性モデル間の context switch オーバーヘッドの違いがどれほど大きいかを示すことにしました。
シナリオ:0.01 秒間スリープを指定された回数実行する必要があり,異なる並行性モデルを使用します:asyncio と threading。合計時間を短縮するために並行タスクの数を増やし,各モデルがどのようにスケールするかを見てみます。
まず threading から:
def make_request(self, worker_id: int, target_requests: int) -> None:
"""グローバルターゲットに達するまでリクエストを行います。"""
while True:
with self.lock:
if self.request_count >= target_requests:
break
self.request_count += 1
current_count = self.request_count
try:
time.sleep(0.01) # asyncio 版のように作業をシミュレート
except Exception as e:
print(f"Worker {worker_id} error: {e}", file=sys.stderr)
# エラー時も中断せず,続行
continue
そして asyncio 版:
async def make_request(self, worker_id: int, target_requests: int) -> None:
"""グローバルターゲットに達するまでリクエストを行います。"""
while True:
async with self.lock:
if self.request_count >= target_requests:
break
self.request_count += 1
current_count = self.request_count
try:
await asyncio.sleep(0.01) # event loop に制御を譲る
except Exception as e:
print(f"Worker {worker_id} error: {e}", file=sys.stderr)
# エラー時も中断せず,続行
continue
6.2 ベンチマーク結果
この表をチェックしてください:
表:100,000 のスリープタスクを完了するのにかかった時間
| 並行タスク数 | threading 時間(秒) | Asyncio 時間(秒) |
|---|---|---|
| 100 | 11.834 | 11.345 |
| 1,000 | 1.245 | 1.139 |
| 10,000 | 完了せず | 0.293 |
| 100,000 | 完了せず | 0.693 |
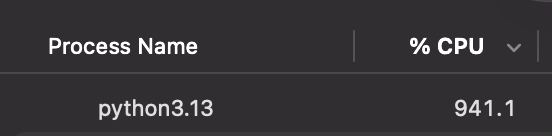
Threading worker の数が 10,000 に達したときの CPU 使用率
結果は,threading が約 10,000 の並行タスクで壁にぶつかる一方,asyncio は効率的にスケールし続けることを示しています。これは,スレッドと比較して asyncio の context switch のオーバーヘッドが低いことを示しています。百万並行処理の夢への道があるとすれば,asyncio がその道を切り開きます。
(私のコンピューターのパフォーマンスを笑わないでください――控えめなんです 😅)
7. 未来:Asyncio が向かう先
7.1 Async-First ライブラリの台頭
Python エコシステムは急速に async-first デザインを採用しています:
- aiohttp:非同期 HTTP クライアント/サーバー
- httpx:モダンな非同期 HTTP クライアント
- FastAPI:高速な非同期 API フレームワーク
- asyncpg:非同期 PostgreSQL ドライバー
- motor:非同期 MongoDB ドライバー
- aiofiles:非同期ファイル操作
- aioredis:非同期 Redis クライアント
- asyncio-mqtt:非同期 MQTT クライアント
これにより,非同期アプリケーションがスタック全体を通じて非同期を維持できる好循環が生まれます。
8. 結論:適切なツールの選択
8.1 Asyncio を使うべきとき
Asyncio に最適:
- 多数の同時リクエストを処理する Web サーバー
- 複数の同時呼び出しを行う API クライアント
- リアルタイムアプリケーション(チャット,ゲーム,ストリーミング)
- I/O 集約的なデータ処理パイプライン
- ネットワーク通信が多いマイクロサービス
代替案を検討:
- CPU 集約的な計算 → multiprocessing を使用
- レガシーコードの統合 → 段階的な移行がより良いかも
8.2 メンタルモデルのシフト
asyncio の採用には,考え方の根本的な変化が必要です:
Preemptive から協調的へ:
- スレッド:OS がコンテキストを切り替えるタイミングを決定
- Asyncio:あなたが制御を譲るタイミングを決定
Blocking から non-blocking へ:
- 従来:「これが完了するまでここで待つ」
- Asyncio:「これを開始して,完了したら教えて」
並列から並行へ:
- threading:異なるコア上で同時に発生
- Asyncio:同じコア上で織り交って発生
8.3 百万並行処理への道
10 接続の処理から 100 万接続への旅は,単に asyncio を選ぶことではありません。理解することについてです:
- ハードウェア:I/O がシステムレベルで実際にどのように動作するか
- OS:select/epoll がどのように I/O 多重化を可能にするか
- 言語:Generator がどのように一時停止可能な関数を可能にするか
- フレームワーク:event loop がどのようにすべてをオーケストレートするか
- アプリケーション:非同期コードを適切に構造化する方法
Asyncio が素晴らしいのは,魔法だからではなく,堅実な基礎の上に構築されているからです。ハードウェア割り込みから async/await 構文まで,すべての層が連携して,効率的でエレガントな同時性の錯覚を作り出します。
8.4 最後の考え
次にasync defやawaitを書くときは,シリコンから構文までにまたがる美しい抽象化に参加していることを思い出してください。あなたは何千もの操作を捌く event loop と協力し,まさに正しい瞬間に制御を譲り,I/O バウンドなアプリケーションを驚くほど速くしているのです。
Asyncio は単なるツールではありません――並行性について考える異なる方法です。そして,一度それを真に理解すれば,I/O を二度と同じように見ることはないでしょう。
百万並行処理への道は,単一のawaitを理解することから始まります。それでは,非同期で,スケーラブルで,美しい何かを構築してください。
A. 参考資料
- PEP 3156 - Asyncio 仕様
- The C10K Problem - Dan Kegel の古典的な論文
- Latency Numbers Every Programmer Should Know
- Asyncio Documentation

IBM Client Engineering の非公式テックブログです。IBM Client Engineeringは、高度なスキルを備えた多分野のチームと人間中心のアプローチにより、スケーラブルなビジネス成果をもたらします。そして、お客様のデジタル・トランスフォーメーションの取り組みを推進し、ビジネス価値に繋げます。
Discussion
サンプルで使われているサーバーのコードはこちらです: