Generative AI on Vertex AI と Tableau でプロレスの試合動画を分析してみた
前段の話(長いです)
Tableauと非構造化データ
どうも、駆け出しカスタマーサクセスマネージャーの玉井です。
Tableauを使えば使うほど、分析元のデータソースの重要性が身にしみてわかるようになってきます。もう少し具体的に言うと、「如何に(Tableauにとって)分析しやすい行と列の構造化データを用意するか」がキモである、ということがわかってきます。
逆に言えば、Tableauで分析したい事柄が何かあるという時、それは「何とかしてその事柄を構造化データとして用意しなければいけない」ということになります。
分析したいデータが、半構造化データならまだしも、音声や動画といった非構造化データだったら、Tableauで分析するのは基本的に不可能だと思ってしまいます。だって、何をどう変換・処理していいのか検討がつかないからです。
しかし、さらに逆に言えば、これは「音声や動画を、何らかの手段で構造化データにすることができれば、Tableauで分析することができる」ということになります。「いや、それができれば苦労せーへんわ」って話ですが、昨今の生成AIのパワーを借りればできるのです。
Vertex AIの例
以下では、Google CloudのVertex AIを用いて、動画の内容をテキストで意味的に理解(音声認識等ではなく「見て」理解)する機能・事例の紹介がなされています。
上記の例では、「Generative Studio」というUI[1]で、動画をアップロードして、UI上で分析を行っています。これだけでも結構すごいですが、この動画は2023年12月のもの。2025年の現在では、生成AI(Gemini)と組み合わせて、もっと色々と分析できるようになっています。
更に、なんと公式サンプルコード(Notebook)まであります。
生成AIに「動画分析させた結果を構造化させる」という発想
上記のサンプル(のvideo_analysis.ipynb)では、3つのYoutube動画分析の例が載っています。
- Summarize a YouTube video
- 動画を要約させる
- Extract structured output from a YouTube video
- 動画で話されていることをまとめて構造化データ(表)にする
- Creating insights from analyzing multiple YouTube videos together
- 複数の動画をまとめて分析させる
「Summarize a YouTube video」はシンプルですが、面白みにかけます(何なら動画分析じゃなくても、音声や文字起こしで既に出来る)。「Creating insights〜」は、動画を複数用意するのが大変ですし、検証の頻度が多くなりそうで、骨が折れそうです。
「Extract structured output from a YouTube video」が丁度良さそうなサンプルだと思います。1つの動画から色々と要素を抽出させて、それを構造化データにする…まさに未来のデータ分析です。
さて、題材の動画を何にするか?ですが、ここは個人的に長年悲願だったプロレスの分析をやってみたいと思います。というわけで、「プロレスの試合をAIに分析させてみるとどうなるのか?」やってみます。
事前準備など
分析の流れを超ざっくり考える
今回は公式のサンプルコードを大いに参考にするため、基本的にGoogle Cloud上で完結させたいと思います。上記のサンプルNotebookを改造して、それをGoogle Colab Enterprise上で実行する形でいきます。その上で、Notebook上で実施する処理の流れは以下のように考えてみました。
- 動画をGeminiに読み込ませる
- Geminiにプロレスの動画を分析させるよう指示する(プロンプトを送る)
- Geminiが取得した分析結果を行列の構造化データに変換する
- 構造化データをBigQueryにロードする
- (Tableau DesktopからBQに接続して分析する)
検証した時の環境
- Google Cloud
- Colab Enterprise: Notebookの実行
- BigQuery: 分析結果の保存
- Gemini 2.0 Flash
- Tableau
- Tableau Desktop 2025.2
今回分析する動画
前述の通り、プロレスの動画を分析します。
私の好きな新日本プロレスでは、YouTubeでいくつか公式無料試合動画を公開しています。というわけで、今回はその中から、バチバチの試合をチョイスしました。
小細工無用のぶつかり合いがたまらない試合ですが、マジメな選定理由を言うと「試合時間が短い(TV王座はそもそも15分以内に決着をつける必要がある)」「シングルマッチである(タッグマッチや4way等は生成AIがついてこれないのでは?という懸念)」ということで、検証に向いているのでは、というのがあります。
分析したいこと(要件)について
ITの世界の例に漏れず、データ分析も要件が非常に大事です。今回は、最終的にTableauで分析するので、少なくともTableauで何をしたいか?については予め考えておく必要があります。
- どの技が何回出たのか?
- どっちの選手が技を多く出したのか?
- 歓声が大きかった技は?
- ダッシュボード上で動画分析ならではの要素を入れたい(後述)
- タイムスタンプ付き再生URL
上記あたりをTableauで実現できるようなデータ取得をしていくことにします。この要件がGeminiに対するプロンプトの根幹になってくるので、要件の検討はめちゃくちゃ重要です。これも後で詳しく説明します。
実際のNotebookの流れ
全コードを載せてもよかったのですが、流れとしては公式サンプルコードとそんなに変わらないし、AIによるVive Codingだし、長ったらしいコードなので、今回は部分部分の紹介にしたいと思います。
(下準備)
サンプルコード同様、必要なライブラリ等をインストールしたり、プロジェクト名やBQのテーブル名等をセットしていきます。
ライブラリだったり…
import json
from datetime import datetime
import re
from IPython.display import HTML, Markdown, display
from google import genai
from google.genai.types import GenerateContentConfig, Part
from google.cloud import bigquery
import pandas as pd
# Gemini クライアントの初期化
client = genai.Client(vertexai=True, project=PROJECT_ID, location=LOCATION)
# BigQuery クライアントの初期化
bq_client = bigquery.Client(project=PROJECT_ID)
Geminiのモデルを指定したり…
# 使用するGeminiモデル
GEMINI_MODEL_ID = "gemini-2.0-flash"
その他、諸々関数等の準備もしていますが、割愛します。
動画をGeminiに読み込ませる
YOUTUBE_VIDEO_URLに今回分析する動画のURLをセットします。ちなみに、試合情報は別にいらなかったのですが、AI様が提案してくれたコードを直すのも面倒だったので、そのまま使ってます。
# 分析するプロレス動画のYouTube URL
YOUTUBE_VIDEO_URL = "https://www.youtube.com/watch?v=T0C0dKIMbeg" # @param {type:"string"}
# 試合情報(BigQueryに保存する際に使用)
MATCH_DATE = "2024-06-09" # @param {type:"string"}
MATCH_EVENT = "2024年06月09日(日)大阪城ホール" # @param {type:"string"}
MATCH_TITLE = "NJPW WORLD認定TV王座" # @param {type:"string"}
display_youtube_video(YOUTUBE_VIDEO_URL)
ちなみに、display_youtube_videoを実行すると、Notebook上でプレビューしてくれます。石井!!石井!!
Geminiにプロレスの動画を分析させるよう指示する(プロンプトを送る)
今回の検証においての最重要プロセス…一番キモとなる部分です!
プロンプト準備
# プロレス技検出用のプロンプト(歓声レベル分析を含む)
wrestling_moves_extraction_prompt = """
このプロレスの試合動画を注意深く分析し、試合中に実行されたすべての技を抽出してください。
以下の情報を含めてください:
1. 技を実行した選手名
2. 技を受けた選手名
3. 実行された技の名前(日本語名を優先)
4. 技のカテゴリー(打撃技、投げ技、関節技、飛び技、その他から選択)
5. 技が実行されたタイムスタンプ(mm:ss形式)
6. 技の説明(簡潔に20文字以内で)
7. 歓声レベル(1-100のスケールで評価)
歓声レベルの評価基準:
- 1-20: ほとんど無反応、静かな状態
- 21-40: 軽い反応、控えめな拍手
- 41-60: 通常の歓声、標準的な反応
- 61-80: 大きな歓声、興奮した反応
- 81-100: 爆発的な歓声、会場全体が沸いている状態
歓声レベルは以下の要素を総合的に判断してください:
- 観客の声の大きさと持続時間
- 技の派手さ、インパクト
- 試合の流れにおける重要性
- 実況やアナウンサーの興奮度
- 会場の雰囲気の変化
注意事項:
- 動画全体を最初から最後まで注意深く観察してください
- すべての技を漏れなく記録してください
- 同じ技でも実行されるたびに記録してください
- 選手名は動画内で呼ばれている名前を使用してください
- 歓声レベルは動画全体の中で相対的に評価してください
- タイムスタンプは「Youtube動画の再生時間」を記録するようにしてください
"""
# 応答スキーマの定義(歓声レベルを追加)
wrestling_moves_response_schema = {
"type": "ARRAY",
"items": {
"type": "OBJECT",
"properties": {
"performer_name": {"type": "STRING"},
"receiver_name": {"type": "STRING"},
"move_name": {"type": "STRING"},
"move_category": {
"type": "STRING",
"enum": ["打撃技", "投げ技", "関節技", "飛び技", "その他"]
},
"timestamp": {"type": "STRING"},
"move_description": {"type": "STRING"},
"cheering_level": {"type": "INTEGER"}
},
"required": [
"performer_name",
"receiver_name",
"move_name",
"move_category",
"timestamp",
"move_description",
"cheering_level"
]
}
}
# 生成設定
wrestling_moves_generation_config = GenerateContentConfig(
temperature=0.0,
max_output_tokens=8192,
response_mime_type="application/json",
response_schema=wrestling_moves_response_schema,
)
まず、wrestling_moves_extraction_promptに、Geminiに投げるプロンプトをセットします。
当然ながら、生成AIが返してくる結果は、プロンプトの内容に大いに左右されます。それは、この動画分析においても同じです。
また、普通のチャット形式の生成AIを使う時には出てこない重要ポイントとして、Geminiが分析して取得した結果をうまいこと受け取らないといけないというのがあります。どういうことかというと、今回はコード上での実行なので、Geminiが返してくる結果を変数に入れないといけないのですが、この結果は最終的には構造化データにする必要があるため、この変数にいれる時点で半構造化データにしておきます(サンプルコードもそんな感じだった)。上記コードのwrestling_moves_response_schemaがそれにあたります(以降、便宜上「応答スキーマ」と呼称します)
半構造化データにするためには、そもそもこの半構造化データの構造(ややこしい)を考える必要があり、それを考えるということは、最終的にしたい構造化データの構造(ややこしい)を事前に考える必要があります。そして、その構造化データの構造(ややこしい)を考えるためには、つまるところ何を分析したいかという要件を先に固めておかないと、プロンプト(wrestling_moves_extraction_prompt)と応答スキーマ(wrestling_moves_response_schema)を決めることはできないのです。事前準備の際に、分析の要件を予めしっかり決めておく必要があると言っているのは、このためです。
プロンプト実行〜確認
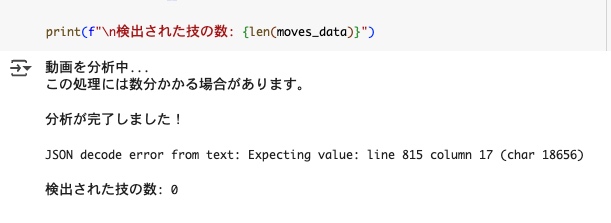
プロンプトと応答スキーマが準備できたら、いよいよ実行します。AI様がご丁寧にもprint文まで作ってくれました。
print("動画を分析中...")
print("この処理には数分かかる場合があります。")
try:
# Gemini APIを呼び出して動画を分析
wrestling_moves_response = client.models.generate_content(
model=GEMINI_MODEL_ID,
contents=[
wrestling_moves_extraction_prompt,
Part.from_uri(
file_uri=YOUTUBE_VIDEO_URL,
mime_type="video/webm",
),
],
config=wrestling_moves_generation_config,
)
print("\n分析が完了しました!")
# レスポンスからデータを抽出
# Google Gen AI SDKの場合、parsedプロパティを使用
if hasattr(wrestling_moves_response, 'parsed') and wrestling_moves_response.parsed is not None:
moves_data = wrestling_moves_response.parsed
print(f"\nParsed attribute found and used")
elif hasattr(wrestling_moves_response, 'text'):
# textプロパティがある場合はJSON文字列として解析
try:
moves_data = json.loads(wrestling_moves_response.text)
print(f"\nParsed from text attribute")
except json.JSONDecodeError as e:
print(f"\nJSON decode error from text: {e}")
moves_data = []
else:
print(f"\nUnexpected response format")
print(f"Response type: {type(wrestling_moves_response)}")
print(f"Response attributes: {dir(wrestling_moves_response)}")
moves_data = []
except Exception as e:
print(f"\nError during API call: {e}")
print(f"Error type: {type(e)}")
moves_data = []
# moves_dataがリストでない場合の処理
if not isinstance(moves_data, list):
print(f"\nWarning: moves_data is not a list, it's {type(moves_data)}")
moves_data = []
print(f"\n検出された技の数: {len(moves_data)}")
ちなみに、プロンプトや応答スキーマの調整をミスってると、以下のようなエラーになったりします。Geminiが返す結果と応答スキーマがうまくハマらず、jsonの解析エラーとなります。
Geminiが取得した分析結果を行列の構造化データに変換する
ここまでうまく来れば、後はよくある普通のデータ処理なので、余裕です。
# 分析結果をDataFrameに変換
moves_df = pd.DataFrame(wrestling_moves_response.parsed)
# タイムスタンプ付きYouTubeリンクを追加
timestamp_urls = []
for move in wrestling_moves_response.parsed:
timestamp_url = create_youtube_timestamp_url(YOUTUBE_VIDEO_URL, move['timestamp'])
timestamp_urls.append(timestamp_url)
moves_df['youtube_timestamp_url'] = timestamp_urls
# 試合情報を追加
moves_df['match_date'] = MATCH_DATE
moves_df['match_event'] = MATCH_EVENT
moves_df['match_title'] = MATCH_TITLE
moves_df['video_url'] = YOUTUBE_VIDEO_URL
moves_df['analyzed_at'] = datetime.now()
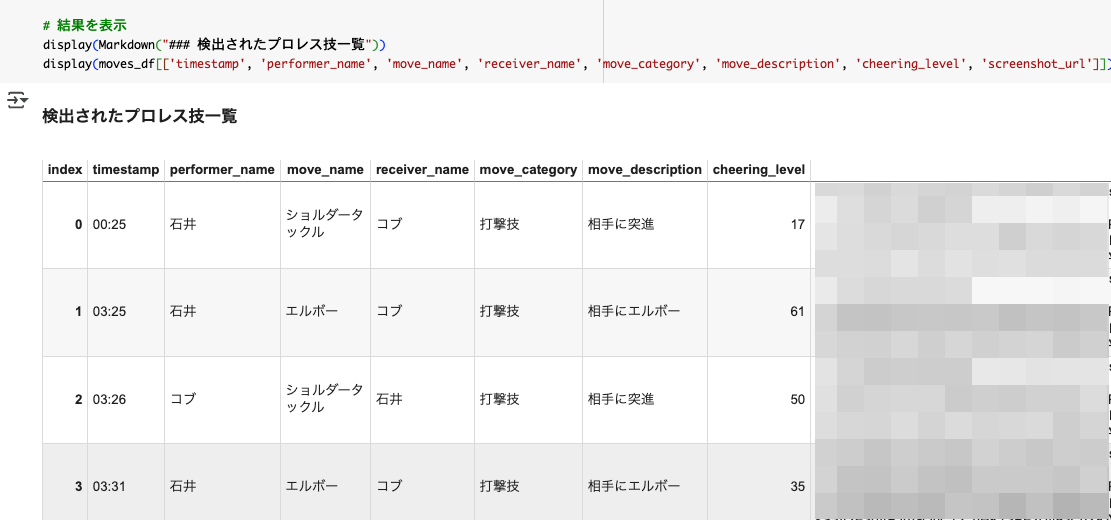
# 結果を表示
display(Markdown("### 検出されたプロレス技一覧"))
display(moves_df[['timestamp', 'performer_name', 'move_name', 'receiver_name', 'move_category', 'move_description', 'cheering_level', 'youtube_timestamp_url']])
うまくいった結果がこちら。ここで大事なのは、Geminiがちゃんと選手とか技を理解している、ということですね。こちらから選手名や技名を直接教えてはいません。
構造化データをBigQueryにロードする
これも、別段、目新しい処理ではないですね。AI様による生成で、ほぼ一発で正常実行できました。
# データセットの作成(既に存在する場合はスキップ)
dataset_id = f"{PROJECT_ID}.{BQ_DATASET_ID}"
dataset = bigquery.Dataset(dataset_id)
dataset.location = "US" # データセットのロケーション
try:
dataset = bq_client.create_dataset(dataset, timeout=30)
print(f"データセット {dataset_id} を作成しました。")
except Exception as e:
if "Already Exists" in str(e):
print(f"データセット {dataset_id} は既に存在します。")
else:
raise e
# テーブルスキーマの定義
schema = [
bigquery.SchemaField("performer_name", "STRING", mode="REQUIRED"),
bigquery.SchemaField("receiver_name", "STRING", mode="REQUIRED"),
bigquery.SchemaField("move_name", "STRING", mode="REQUIRED"),
bigquery.SchemaField("move_category", "STRING", mode="REQUIRED"),
bigquery.SchemaField("timestamp", "STRING", mode="REQUIRED"),
bigquery.SchemaField("move_description", "STRING", mode="NULLABLE"),
bigquery.SchemaField("cheering_level", "INTEGER", mode="NULLABLE"),
bigquery.SchemaField("youtube_timestamp_url", "STRING", mode="NULLABLE"),
bigquery.SchemaField("match_date", "DATE", mode="REQUIRED"),
bigquery.SchemaField("match_event", "STRING", mode="REQUIRED"),
bigquery.SchemaField("match_title", "STRING", mode="REQUIRED"),
bigquery.SchemaField("video_url", "STRING", mode="REQUIRED"),
bigquery.SchemaField("analyzed_at", "TIMESTAMP", mode="REQUIRED"),
]
# テーブルの作成(既に存在する場合は既存のテーブルを使用)
table_id = f"{PROJECT_ID}.{BQ_DATASET_ID}.{BQ_TABLE_ID}"
table = bigquery.Table(table_id, schema=schema)
try:
table = bq_client.create_table(table)
print(f"テーブル {table_id} を作成しました。")
except Exception as e:
if "Already Exists" in str(e):
print(f"テーブル {table_id} は既に存在します。")
else:
raise e
ロードする部分
# DataFrameをBigQueryにロード
job_config = bigquery.LoadJobConfig(
schema=schema,
write_disposition="WRITE_APPEND", # 既存のデータに追加
)
# データ型の調整
moves_df['match_date'] = pd.to_datetime(moves_df['match_date']).dt.date
# BigQueryにロード
job = bq_client.load_table_from_dataframe(
moves_df, table_id, job_config=job_config
)
job.result() # ジョブの完了を待つ
print(f"\n{len(moves_df)} 行のデータを {table_id} にロードしました。")
というわけで、BQを確認してみましょうね。

ちゃんと格納されております!Geminiに、動画に関する要素を抜き出すよう指示し、それを構造化データにすることができました。
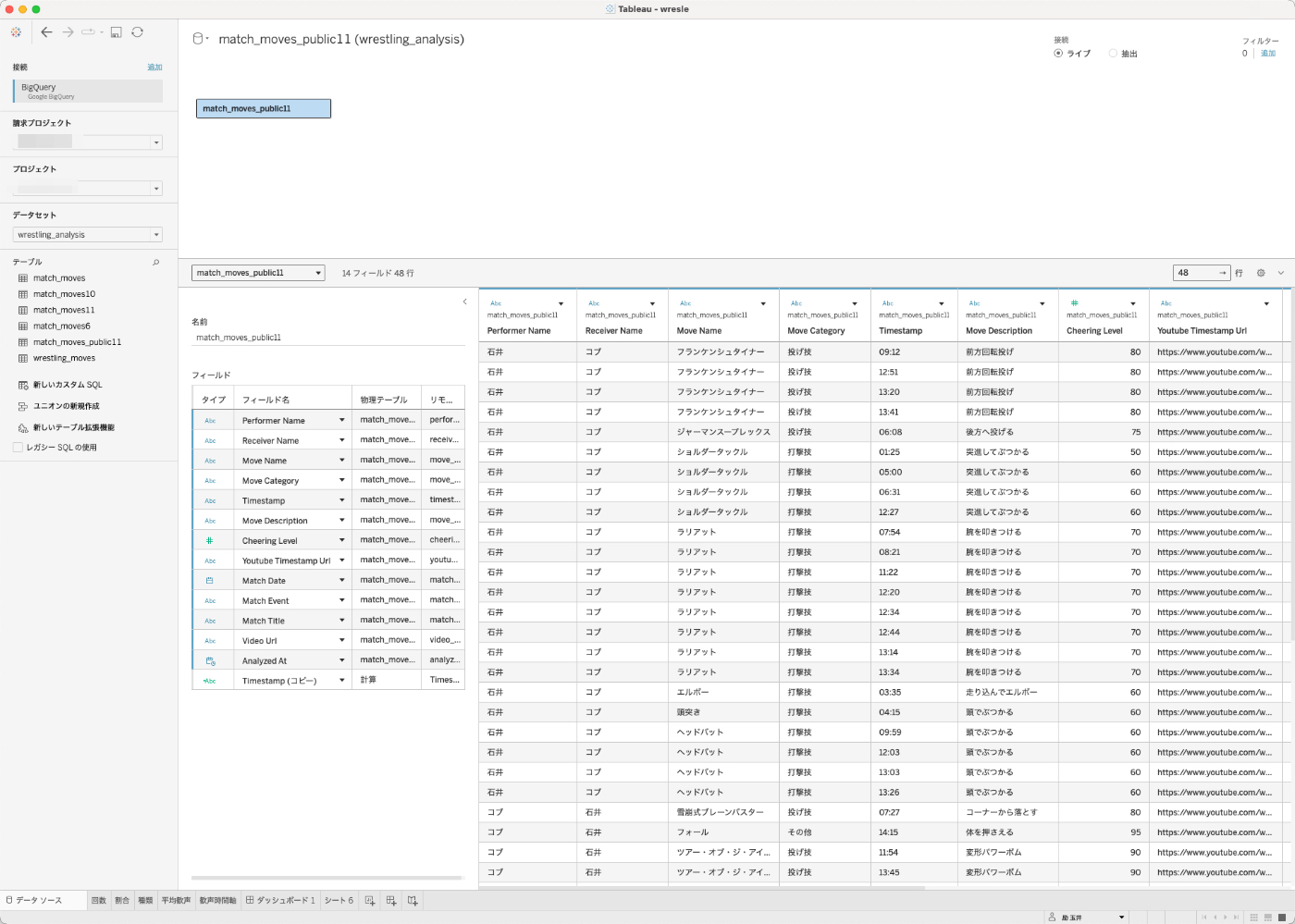
Tableau DesktopからBQに接続して分析してみる
ある意味、ここからが本番です。データは分析して初めて価値が出ます。というわけで、やってみましょう。Tableauは標準でBQに接続することができます。私はOAuthでスムーズに接続しました。
先ほどのデータがTableau越しにも見えます。
ダッシュボード作ってみた
とりあえずサーッて作ってみたのがこちら。
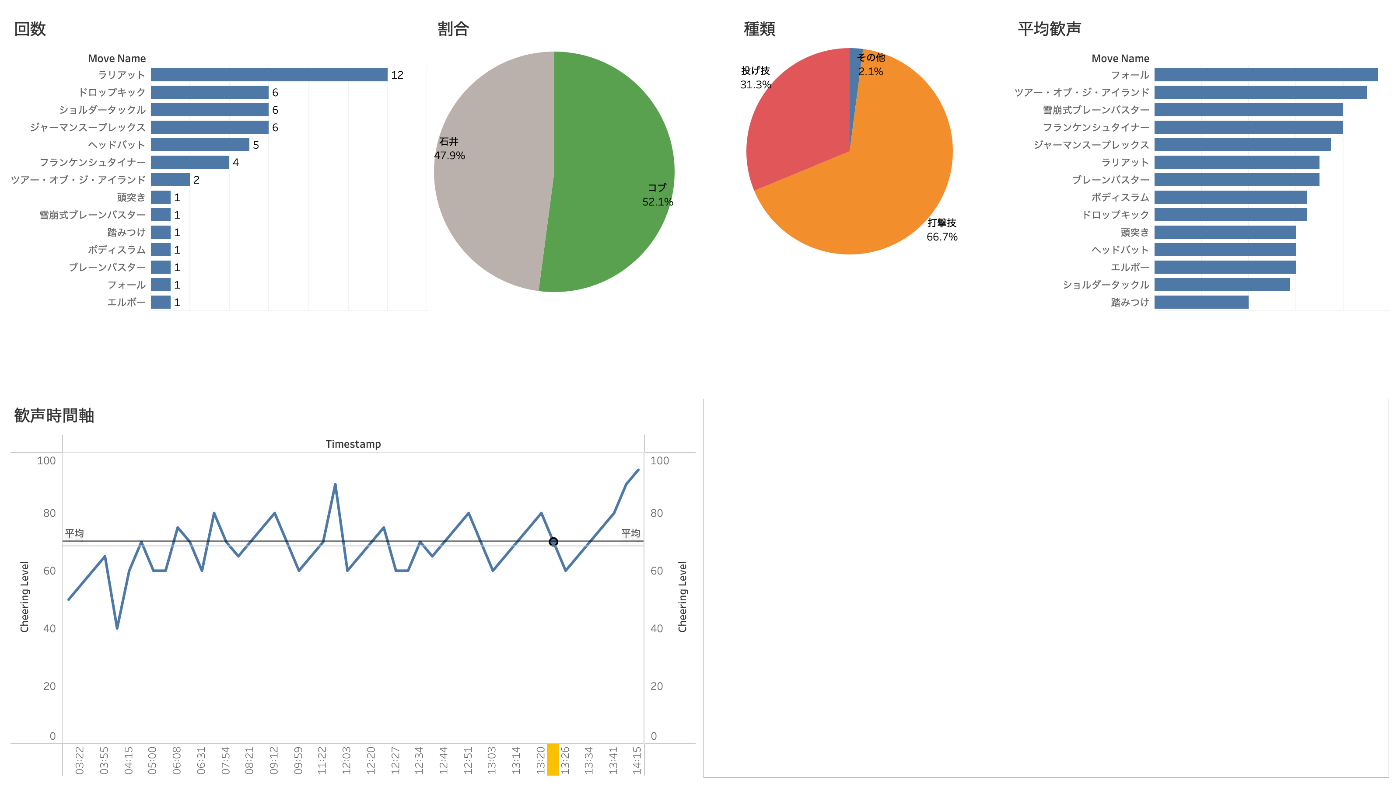
「ラリアット多すぎ!」「お互い五分五分に技出してるんや〜」「打撃の多いバチバチな試合だったのか」といったインサイトが得られました。
URLアクションを駆使して、その時点の動画を直接見る
せっかくの動画分析なのに、グラフだけだと面白くない!ということで、ここで以前から準備していた「タイムスタンプ付きYoutubeURL」が火を吹きます。
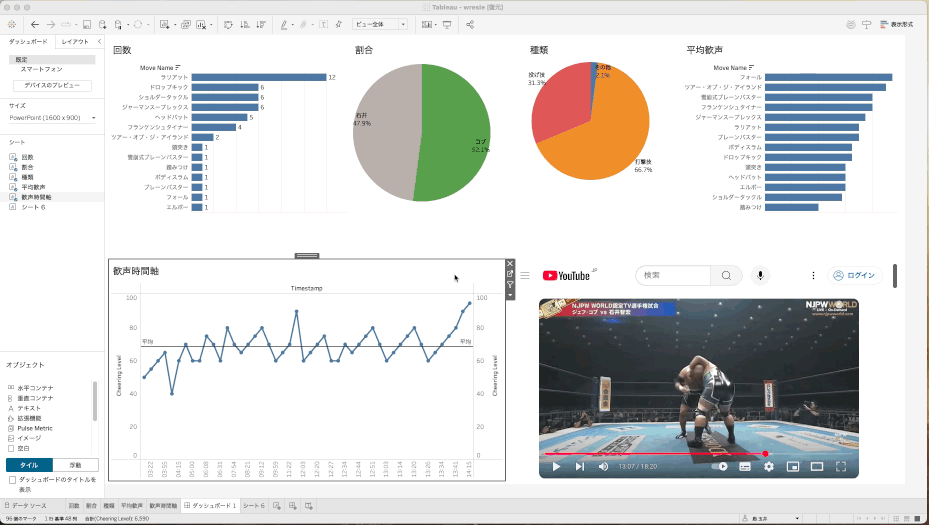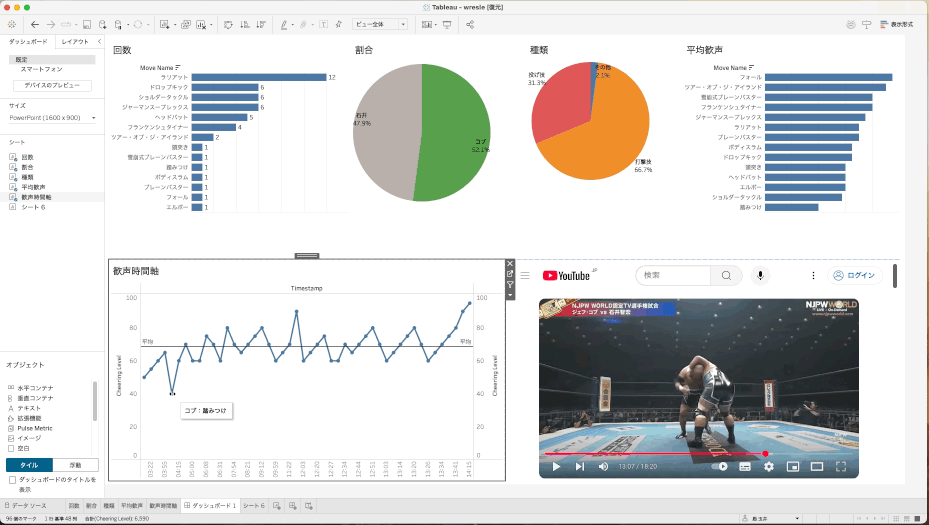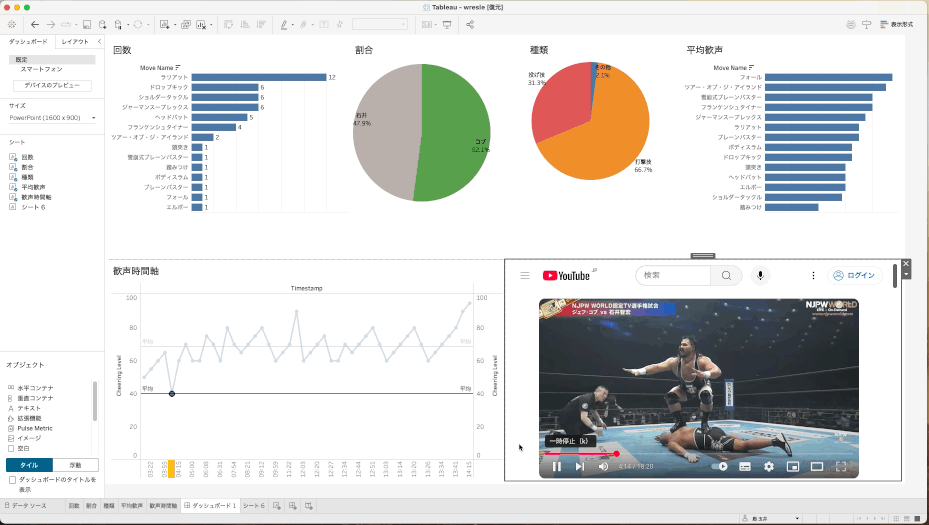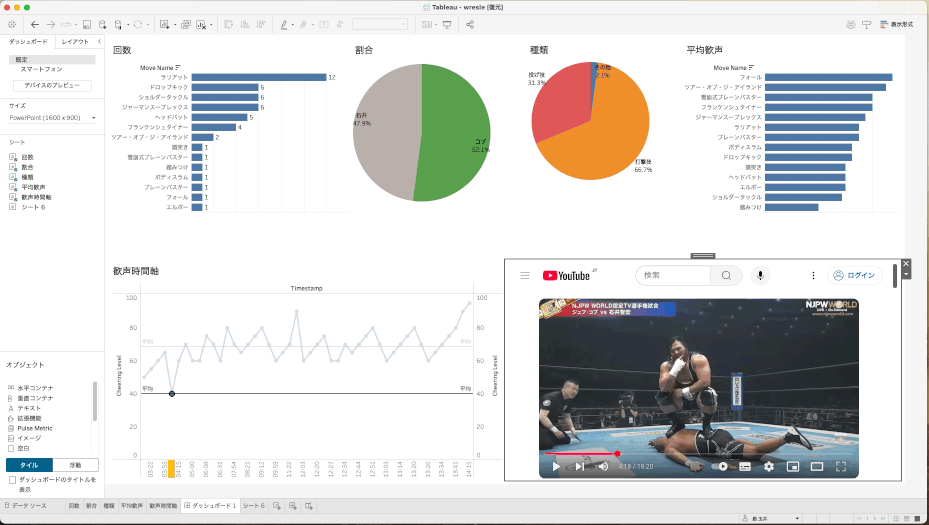
URLアクションを使って、タイムラインの折れ線グラフのポイントをクリックすると、その時間のところからYoutube再生ができるようにしてみました。これで、その技や歓声の大きい部分をすぐに確認することができます。
画像にしなかった理由
上記の「その技の瞬間の実際の場面を見れるようにする」というものですが、実は、当初は全然違う設計を考えていました。
- 技が繰り出された時間のスクリーンショットを撮る
- スクリーンショットをGCSに格納する
- BQにGCSのURL(その技の時間に該当するスクショ)を入れる
- TableauのURLアクションで画像が表示されるようにする
何なら、無理にYoutubeを再生させるより、こちらの方が何かスマートな気すらします。じゃあ何でこれをやらなかったかというと、スクショの取得処理のために、どうしても動画を一度ダウンロードする必要があったからです(規約的にアレ)。
動画をダウンロードせずに、その場面のスクショを取得する方法を調べましたが、Youtube側のAPIは決まった時間のサムネイルしか撮れなかったり、かなり難しいことがわかりました[2]。というわけで、動画そのものを再生する方法に切り替えた、と言う訳です。
動画分析の精度は?
ここまで動画分析の処理や、それの可視化など、流れるように(?)やってきましたが、ここで一つ大事なことを確認する必要があります。それは、そもそもGeminiの動画分析の結果は合っているのかということです。本当にその時間にその技が出ているのか?正解しているのか?どうなんでしょうか?
結論からいうと、結構な頻度で間違っていました。
- 技を結構間違っている
- 「ツアー・オブ・ジ・アイランド」となっている部分があるが、実際は「F5」である
- 「ヘッドバッド」となっている部分があるが、実際は「ブレーンバスター」である
- etc.
- 全体的に技と時間がズレている
- 石井選手がフランケンシュタイナーを決めるのはもっと後
- etc.
- 技を見逃している(データとしてとれていない)
- ジェフ・コブ選手のその場飛びムーンサルト
- ジェフ・コブ選手の雪崩式ブレーンバスター
- 石井選手の延髄斬り
- 石井選手のスライディングラリアット
- etc.
- その他
- フォールを技として扱うかどうかは絶妙なところ
特に、技と時間がズレているものが非常に多かったですね。データ上はエルボーしてることになっているが、実際は両者ダウン中…みたいなのがほとんどでした。ここはプロンプトの調整で何とかなるのかもしれませんし、Geminiのモデルを上位にできるようになれば、すぐに解決するのかもしれません。が、実際のところはまだまだわからない感じです。
とはいえ、プロレスのことを何にも知らない生成AIに対して、時間はズレていたりしても、一通りの技はそれなりに認識しているのには驚きました。実況解説の音声を参考にするように指示しているのもありますが、プロレスに一切興味ない人間に同じ作業をやらせても、今回のGeminiよりいい結果は出せないと思います[3]。
終わりに
プロレスを題材にした技術ブログを書くことができて本望です。
…………
非構造化データを構造化する方法は、生成AIの登場によって、グンと幅が広がった気がしています。また、各種データウェアハウス側も非構造化データに対応してきているので、今回のようなYouTube動画ではなく、社内の動画(CMとか?)をDWHに入れて、そこから生成AIで分析…みたいなことができそうですね。
Discussion