2024年2月の日々精進
2/1
今日から2月かー
- LPIC201
- 粛々と進めております
- AWS-SAA
- コンテナサービスの勉強。
- ECS, EKS, ECR, Fargate のざっくりしたイメージは理解できた
- ECS と EKS は、一回手を動かして作っておきたい。
- ECSのクラスタ、サービス、タスクの違いを言葉では覚えたものの、作ってみないことにはイメージが湧かないぜ
- 機械学習
- SVM
- Postman
- サブフォルダを使ったテストコードの共通化
2/2
- LPIC201
- 過去問の通し復習
- キャパプラが苦手だ〜!
- Qiitaのまとめも「後でやろう」でたまっている項目が多いので、今週末には整理する
- ん? 今週末はピアノの発表会なんだが
- 過去問の通し復習
- AWS-SAA
- S3について改めて勉強
- 私の知らない機能がいっぱいある・・・!
- 明日も引き続きS3を勉強する
- 機械学習
- カーネルSVMを勉強 -> 日本語では非線形SVMというらしい
- 数式のところはもはや聞き流しに入っている
- 平面上に非線形にプロットされた点のうち、抽出したいグループの中心点を引っ張り上げて立体にして、高さで切ることでグルーピングする手法と理解。
- 引っ張り上げた円の大きさはσに連動するようである。。。
- 円(非線形なグループの中心地)の数だけカーネル関数が存在するというイメージらしい?
- カーネル関数の種類
- ガウスRBF
- シグモイドカーネル
- Polynomial Kernel
- 思ったんだが、先にクラスタリングをやってからこっちに戻ってくるんじゃだめかね
- ということでクラスタリングをやってみる
- 今日は K-Means Clustering
- Elbow Method - グループの数を増やしても、あまり効果がなくなるポイントを見つける
- 重要なポイントとして、ランダムにグルーピングした結果、同じデータセットの分類が変わってしまうのがいやだ -> そこで k-means++
- 概念の名前などに親しむという点ではいいけれども、このまま Udemy をだらだら流すことにどこまで意味があるのだろうか。
- 学校の課題に集中でもいいのかもしれない()
2/3
- LPIC201
- 朝電車で、全範囲のミスったところを復習
- コマ問はまだやっていない
- AWS-SAA
- S3の勉強を続行中
- データ分析の学校
- 要復習用語リスト
- VIF
- 赤池情報量基準
- 最尤法 <- 概念だけでなく、求め方もちゃんと(BCDay3の1h30-2hめくらい)
- そもそも e ってなんなんだーーーー
- ROC曲線
- これは概念の理解と、曲線を実際に手で描いてみるということ
- ロジスティック回帰は分類問題、の中身を深めに理解してアハ体験
- オッズとオッズ比が今日わかった
- ボーナスありの退職率 - オッズ1
- ボーナスなしの退職率 - オッズ2
- オッズ1とオッズ2の比 - オッズ比
- MSE, RMSE, MAE, MAPE
- MSE - 残差の二乗和
- 二乗しているので単位が揃わない
- RMSE - 👆の平方根
- 平方根にすることで単位が揃う(円なら円)
- 二乗しているので極端な値を罰する
- なめらかな関数で微分が可能なので扱いやすい・・・らしい
- MAE - 残差の絶対値の和
- 単位は揃う
- 絶対値は微分ができないので扱いづらい・・・らしい
- MAPE - ばらつきを%で見る
- 同じ2万でも、家賃の2万の誤差なのか、売買価格における2万の誤差なのかによって2万の価値が違う。
- ここを % で見られるのが MAPE
- MSE - 残差の二乗和
- 要復習用語リスト
2/4
ピアノの発表会があって、さすがに勉強に進捗なしでした
2/5
- LPIC201
- dmesg の中身の解読 -> どのメッセージがいつ出るものか
- API(POSTMAN)
- 境界値テストの書き方
- コレクション、フォルダ、APIのレベルでドキュメントを書けるということ
- 次はいよいよ、スクリプトでPOSTMANの変数を読み書きする方法を学ぶ!
2/6
- LPIC201
- やっとカーネルがらみの単元に一区切りつけることができた
- AWS-SAA
- S3の単元終わり(終わらせ)
- 今日からEC2
- EBSとインスタンスストアは別物!
- EBSの最大IOPSは64000程度だが、インスタンスストアは揮発性であるかわりに1MIOPS以上の性能が出る
- POSTMAN(API)
-
pm.collectionVariables.set('key', value)で、key を変数名としたコレクション変数に value の値を入れることができる!
-
2/7
- LPIC201
- システムの起動(主題202)を復習・・・の日でよかったんだっけ。。。
- コマ問もやりました。
- AWS-SAA
- プレイスメントグループ
- 複数のEC2インスタンスを論理的にグループ化し、単一AZ内の物理的に近い距離に配置
- インスタンス間での低遅延な通信や、ハードウェア障害による影響を軽減できる
- パーティションプレイスメントグループ
- グループをパーティションとよばれる論理グループに分割 -> ラックに相当
- 各パーティションに1つ以上のEC2インスタンスが所属
- スプレッドプレイスメントグループ
- グループ内のEC2インスタンスを異なるHW(ラック)に配置
- HWによる影響を最小限にとどめる
- プレイスメントグループ
2/8
学習記録、わりと細かめにメモっていたのに消えた
こまめにセーブ(投稿)するべきだな
- LPIC201
- ファイルシステムのコーナーに突入
- AWS-SAA
- CPに合格した
- Ping-TのEC2のところが終わったので、あとはVPCを1日3問とか解きながら、次はRDSに着手
- API
- レスポンスから変数の値を取り込み、それを次のAPIで使う一連の流れを学習
2/9
- LPIC201
- 平常運転
- AWS-SAA
- RDS - OLTP用のRDBMSをSQLでクエリ、transaction したいとき用
- Postgres, MySQL, Oracle, SQL Server, MariaDB, Custom(Oracle, SQL Server) をサポート
- EBSのボリュームタイプとサイズも選べる・・・だと?
- オートスケーリング対応
- マルチAZのリードレプリカをサポート
- IAM, セキュリティグループ、KMS, SSLでのセキュリティ
- 35日までの自動バックアップ
- より長期のリカバリについては、手動のDBスナップショットをとるべし
- ダウンタイムを伴うメンテナンスの管理
- IAM認証、Secrets Manager のインテグレーション
- Aurora - RDSがさらに高機能になり、管理の手間が省けた版
- PostgresSQLとMySQLに対応するAPI
- コンピュートとストレージの分離
- ストレージ
- データは3AZ、6レプリカに保持される
- HA、自己回復、オートスケーリングに対応
- コンピュート
- 複数AZにわたるDBクラスタ
- リードレプリカのオートスケーリングに対応
- クラスタ
- DBインスタンスに対する reader, writer として、カスタムのエンドポイントに対応
- セキュリティ、モニタリング、管理の機能はRDSと同様
- バックアップとリストアのオプションに何があるかは知っておいてね(←教えてくれよ〜)
- 関連サービス
- Aurora Serverless というものがある
- Aurora Global
- 各リージョンに16個のDBインスタンス
- 1つまでのセカンドストレージレプリケーション
- プライマリがこけた場合、セカンダリはプライマリに昇格可能
- Aurora Machine Learning
- SageMaker と Comprehend を Aurora 使って動かすぜ
- Aurora Database Cloning
- スナップショットよりも速いレプリカ
- Elastic Cache - 読みが頻繁で、書きはそうでもない key-value ストア用 ※SQLには対応していないぜ
- マネージドの Redis / Memcached のサービス
- インメモリのデータストア
- Redis の特徴
- クラスタリング
- Redis Auth のサポート
- ECに変更する場合は、アプリ側のコード変更が必要
- Dynamo - NoSQL, 変更が多いスキーマ、100KB以下のドキュメントを持つサーバレスアプリ、分散サーバレスキャッシュ
- キャパシティのプランニングは2とおり
- provisioned + autoscale
- on-demand
- キャパシティユニット -> https://qiita.com/Yona_Sou/items/c79d2bf5ffe1da454a6e
- Elastic Cache を replace できる (例:TTLを使って session データを保持できる)
- デフォルトでHAかつマルチAZ
- Read と write の完全な疎結合
- DAX Cluster
- Dynamo アクセラレータ
- read cache のこと
- Dynamo DB Streams : Lambda, Kinesisなどとも連携可能なイベント処理
- Global Table - Active / Active の赤っとアップ
- バックアップはデフォで35日まで(PITR : Point In Time Recovery 新たなテーブルへのリストア)、または手動でより長く
- S3連携
- Read Capacity Unit を使い、PITRウィンドウの中でS3にエクスポート
- Write Capacity Unit なしでS3からインポート
- キャパシティのプランニングは2とおり
- S3
- スモールファイルをたくさん、ではなく、でっかいファイルを扱うのに向いている
- Object Lambda
- S3に対する処理をキックに Lambda を起動できる
- CORS をサポート
- クロスオリジンリソース共有(ここよく勉強)
- Dodument DB
- MongoDBのことらしい
- MongoDBに対してAurora 的な高機能でくるんだもの
- Neptune
- AWS唯一のグラフDB!
- Amazon Key Spaces - IoTのデータ管理や、時系列データに向いている、らしい
- Kassandra
- テーブルのTraffic によって オートスケールする
- CQL - Kassandra Query Language
- Dynamo と同様のキャパプラ
- QLDB - Quantum Ledger Database
- https://docs.aws.amazon.com/ja_jp/qldb/latest/developerguide/what-is.html
- ledger - 元帳
- ブロックチェーン的なやつかなぁ
- ビンゴ 普通のブロックチェーンより 2-3 倍パフォーマンスがいいらしい
- イミュータブル
- AWSには Amazon Managed Blockchain というサービスもあるが、AMBがDecentralized に対してQLDBは中央集権型
- Amazon Timestream
- 時系列データのサーバレスDB
- AWS IoT や Kinesis、Lambda などから Timestream にデータを集め、QuickSight,SageMaker,Grafana、JDBCなどでそのデータを活用するというのが一般的な流れらしいです。
- RDS - OLTP用のRDBMSをSQLでクエリ、transaction したいとき用
2/9 長くなりすぎたので分けます
- RDS
- ストレージタイプ
- 汎用SSD
- プロビジョンド IOPS <- スループット向上、別名 PIOPS
- スナップショットを他のアカウントと共有できる(手動バックアップ分のみ)
- 自動バックアップのスナップショットは共有できない
- ストレージタイプ
- Aurora
- 削除保護ができる(MFA delete は S3固有の名称なので間違えないように)
- Aurora Auto Scaling - 水平方向(スケールイン・アウト)
- Aurora Serverless - 垂直方向(スケールアップ・ダウン)
2/13
おおっ。。。しばらく記録をさぼっていた形跡。
渡米中だったので仕方ないな。
- AWS
- VPC
- VPCフローログ
- VPC内のENI(Elastic Network Interface)に流れるネットワークトラフィック情報を出力する機能
- VPCフローログ
- Amazon Global Accelerator
- 複数のリージョンで展開しているWebアプリケーションなどへのリージョン間の負荷分散が可能
- エンドポイント(負荷分散先)はALB、NLB、EC2インスタンス、Elastic IPアドレスなどで指定可能
- 処理方式
- 2つの固定パブリックIPを保有 -> ユーザーはここにアクセス
- エンドポイントが増減しても、クライアントはAGAの固定IPへの通信として処理できる
- メリット
- Elastic IP を割り当てられないALBへのアクセスを固定IP化できる
- ALBでは対応できない、リージョンをまたいだ負荷分散ができる
- Athena
- サーバレスのSQLエンジン
- バックエンドで Presto (=Trino) を使っている
- 今は PySpark と SparkSQL も使えるっぽい?
- CSV, JSON, ORC, Avro, Parquet に対応
- QuickSight (可視化)とよく組み合わせて使われる
- パフォーマンスの向上
- 列試行のデータにしておくとコストを節約できる
- 従って、Parquet と ORC がおすすめ
- Glue を使うと xx to Parquet / ORC が簡単にできる
- 圧縮もおすすめ
- bzip2, gzip, lz4, snappy, zlip, zstd
- パーティションも切ってね

- スモールファイルは問題になるので128MB以上を使うこと
- 列試行のデータにしておくとコストを節約できる
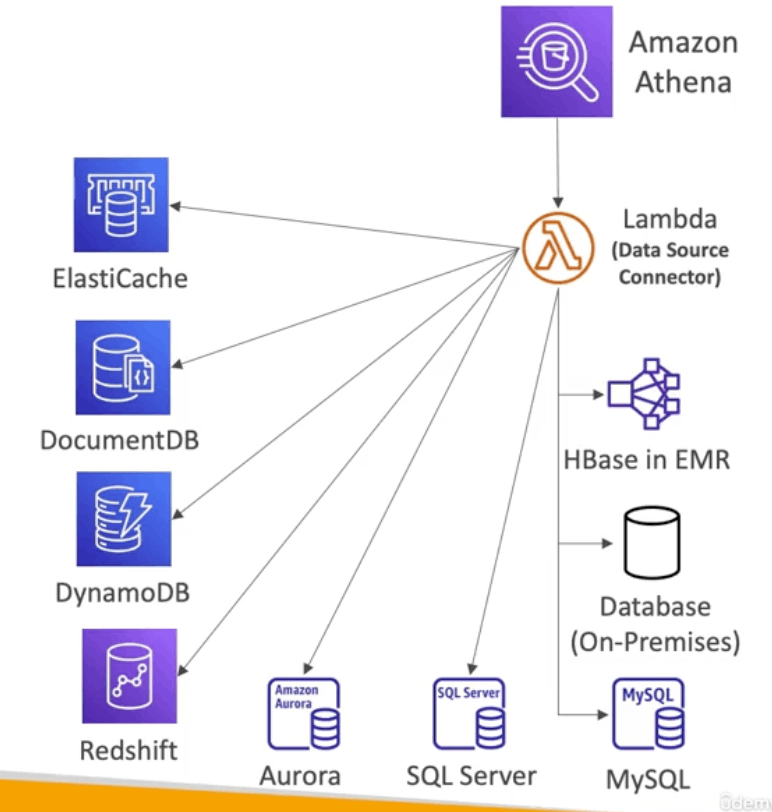
- Federated Query
- Lamda の中の Data Source Connectors を使って実現
- VPC
2/13つづき
- Amazon FSx
- サードパーティーのファイルシステムをAWS上でフルマネージドで利用できる
- Lustre, Windows FileServer,Lustre, Windows FileServer,NetApp ONTAP, OpenZFS
- FSx for Windows
- Share Drvive的なもの
- SMBとWindows NTFS プロトコルを使う
- AD連携ができる、ACL, ユーザーQuotaが使える
- Linux の EC2 インスタンスからマウントすることもできる
- Microsoft DFS (Distributed File System) の名前空間を使える
- 名前空間 - 複数のファイルシステムにまたがるファイルの一群
- ストレージの選択肢
- SSD(低レイテンシ)
- HDD(安い、Home Directory)
- VPNまたはDirect Connect を使うことでオンプレからアクセス可能
- マルチAZでの設定が可能
- 日次でS3にバックアップされる
- サードパーティーのファイルシステムをAWS上でフルマネージドで利用できる
- FSx for Lustre
- MLやHPC に使われる
- 動画処理、金融系のモデリング、電気設計の自動化 など
- 100GB/秒、100万IOPS, m秒未満のレイテンシ
- ストレージのオプション
- SSD - レイテンシ重視の場合
- HDD - スループット重視の場合
- S3とのシームレスな連携
- S3をファイルシステムとして読んだり・・・
- FSxに対する書き込みの先を裏でS3にしたり・・・
- VPNまたはDirect Connect を使うことでオンプレからアクセス可能
- MLやHPC に使われる
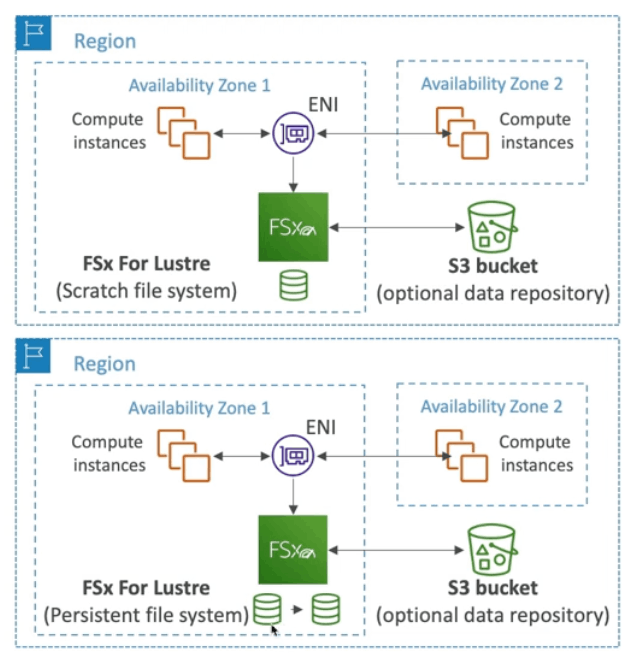
FSxの2つのデプロイオプション
- スクラッチ
- 一時的なストレージで複製もされない
- バーストが高い 6倍
- 短期の処理をコスト最適に実施する場合に利用
- Persistent File System
- 長期のストレージ
- 同じAZの中に複製を作成
- 失敗したら、数分でそのファイルを置き換える
- 長期の利用や、センシティブなデータの扱いに向いている
- FSx for NetApp ONTAP
- ONTAP
- NFS, SMB, iSCSI との互換性あり
- ONTAP、NAS、AWSの上で動く
- 互換性のあるOSが多い
- Linux, Windows, MacOS, VMWare Cloud on AWS, Amazon Workspaces & AppStream2.0, EC2, EKS, ECS
- 自動でオートスケール
- スナップショット、レプリケーション、圧縮、重複排除ができて低コスト
- Point-in Time instataneous cloning - タイムトラベル的なことができるらしい
- FSx for OpenZFS
- OpenZFS
- そういうファイルシステムがあるらしい https://aws.amazon.com/jp/fsx/openzfs/features/
- 互換性があるプロトコルはNFSのみ(v3, v4, v4.1, v4.2)
- AWS上のZFSで動く
- OSの互換性は豊富
- Linux, Windows, MacOS, VMWare Cloud on AWS, Amazon Workspaces & AppStream2.0, EC2, EKS, ECS
- 1MIOPSを0.5ms級のレイテンシで実現
- スナップショット、圧縮をサポートし低コスト(※圧縮と重複排除はしてないぞ)
- Point-in-Time instataneous cloning はここでも available
- OpenZFS
Storage Gateway
- オンプレとCloud間のデータのブリッジ
- ユースケース
- DR, バックアップ&リストア
- ティアードストレージ
- オンプレにキャッシュを置いて低レイテンシのファイルアクセスを実現する
- ストレージゲートウェイの種類
- S3ファイルゲートウェイ
- FSxファイルゲートウェイ
- ボリュームゲートウェイ
- テープゲートウェイ
S3 ファイルゲートウェイ
- Glacier 以外のS3と互換性あり
- Glacier は、ライフサイクルポリシーでS3のバックアップ用として使う
- オンプレ上に、アプリサーバとNFSまたはSMBでつながるS3ファイルゲートウェイを置く
- AD連携の場合はSMB
- S3ファイルゲートウェイは、背後のS3とHTTPで通信する
- Most Recently Usage データが S3ファイルゲートウェイにキャッシュされる
- 配置するS3ファイルゲートウェイごとにIAMロールが必要
FSx ファイルゲートウェイ
- FSx for Windows File Server (FSxの全てではない) にネイティブアクセス
- AWS常にAmazon FSx for Windows File Server があれば、SMBクライアントからのアクセスは可能
- ただし、FSx File Gateway を置くことによってキャッシュの活用が可能
- Windows native との互換性(SMB, NTFS, Active Directory)
- グループファイルやホームディレクトリを共有する際に有効
Dynamo DB の基本 - キャパシティユニット
- DynamoDB では、テーブルに対する読み・書きのスループットをキャパシティユニットという単位で管理
- WCU - 書き込みキャパシティユニット
- 最大1KB/秒
- RCU - 読み込みキャパシティユニット
- 最大4KB/秒
- CU増やす -> パーティション増える -> スループット増える
- パーティションが増えると、データが分散されてプロビジョニングされたスループットを保てるため
- WCU - 書き込みキャパシティユニット
DynamoDB - 読み込みの整合性
- 2つのモードあり
- 結果整合性のある読み込み(デフォルト)
- 一時的に、読み込んだデータが最新ではないタイミングが発生しうる
- 強力な生合成のある読み込み
- 必ず最新のデータを取り出せるが、
- 読み込みのコストが2倍になり
- レイテンシが高くなる可能性がある
- 必ず最新のデータを取り出せるが、
- 結果整合性のある読み込み(デフォルト)
DynamoDB - バックアップ
- ポイントインリカバリは最大35日分
- バックアップ処理はパフォーマンスへの影響ない
Dynamo DB / Redshift
- DynamoDBではバックアップ先のリージョンを指定できない
- Redshift は DB のバックアップ(スナップショット)を異なるリージョンに作成できる
DynamoDB - グローバルテーブル
- 複数のリージョンにまたがってレプリケーションを作成
- バックアップではリージョンは指定できないらしいが、レプリケーションでは指定できるらしい
- バックアップとレプリケーションの違い:https://boxil.jp/mag/a2534/#:~:text=レプリケーションとバックアップとの大きな違いは、すぐに,十分だといえます。
DAX - Amazon DynamoDB ACCelerator
- Dynamo DB のインメモリのキャッシュクラスタ
- 読み込みアクセスが多い場合に利用すると効果あり
- レスポンスをミリ秒 -> マイクロ秒レベルに削減できる
- RCUを削減できる
2/8
- AWS
- Cloud Practitioner に受かった
- SAAは、EC2の ping-t は一応解き終わった。
- VPCはいっぺんにやると嫌になりそうなので、1日3問ずつくらい解くことにして、次はRDSやDynamoなどのハンズオンに手をつけたい。
- LPIC201
- 今日から「ファイルシステムの操作と保守」の単元を開始
- 全体の復習もやっていかないとな
- API(POSTMAN)
- response の内容を変数に取り込む → その内容を次のリクエストで使う という一連の流れを演習した
- 次は dynamic value の扱いを行うらしい!
2/14
Happy バレンタイン!
- AWS-SAA
- Storage Gateway について学ぶ
- なるほど、こうしてAWSはオンプレの領域にも手を広げてきているんだな
- SAA合格後の path についても考えを進め始めている。デベロッパー→DEという流れかなぁ・・・
- 会社で提供しているコースがあったので、デベロッパー→Security と進むことにした。
- LPIC201
- ファイルシステムについての学習を継続中
- 出題内容は Level 1 とほぼかぶっているっぽい
- API(POSTMAN)
- 久しぶりにやれた
- response の変数化 についての課題を実施
2/17
帰国!
- データ分析の学校
- 傾向スコアマッチングむずすぎる
- ICAそろそろ手をつけたい
- LPIC201
- 今日から「ファイルシステムの作成とオプションの構成」に入った
- SAA
- VPCを1日3問
- ELB を3問
- ELBの中に、以下の区分がある
- ALB - アプリケーションロードバランサ(HTTP, HTTPS)
- NLB - ネットワークロードバランサ(TCP, UDP, TLS)
- CLB - クラシックロードバランサ(HTTP, HTTPS, TCP, SSL/TLS)
- ELBの中に、以下の区分がある
- 読書『ドーパミン中毒』
- 苦痛を避けて快楽を追求すればするほど、結果的には苦痛が増して快楽を感じにくくなってしまう
- なので、ある意味意識的に(中毒にならない程度に)「苦痛に向かっていく」姿勢が大事。
- 自分にとって勉強は、仕事の苦痛を減らして快楽を増やすためのもの。
- そういう意味で、勉強することで仕事の苦痛から逃げていることは偽れない。
- でもなぁ。仕事の「苦痛」を正面からかぶりたくない気持ちは本当で。
- 正面からかぶりたくない、というか、かぶるにしてもきちんと well equipped になってからかぶりたい、今はまだ under equipped だ、という感覚。
- じゃあいつ equipped になるの、と言われると、結局仕事の苦痛をかぶることによって equipped に近づいていく部分があるというのは承知している。
2/20
今週の目標は、
□VPCの問題を1日3問解く
□ELBの問題を1日3問解く
□Route53、DirectConnect/VPN を解き切る
らしい(SAA)
- LPIC201
- 10問解いた(ファイルシステム)
- SAA
- VPC3問解いた
- ELB
- ステップスケーリング
- 閾値により、何台追加するかを決めるスケーリング手法
- (ここ体系的にさらったほうがいいな)
- ポート番号での負荷分散に対応しているのはNLBのみ(なんとなく知ってた)
- ステップスケーリング
- Route53
- シンプルルーティングポリシー、加重ルーティングポリシー、レイテンシルーティングポリシーがある
- S3で静的Webサイトをホストする場合、エンドポイントの一部が動的に変化するので通常のAレコードが使えない。そこでCNAMEレコード、エイリアスレコードが登場するが、より応答が速いのはエイリアスレコード
- エイリアスレコードは、Zone Apex の別名を登録できる。(これはCNAMEではできない)
- Zone Apex とは
- 最上位のドメイン。www.example.com や abc.example.com のZone Apexは example.com
- Zone Apex とは
- 3問解いた
- API(POSTMAN)
- コレクションに指定した変数の get のしかた
-
pm.collectionVariables.get("変数名")で、コレクションに入れた変数を使える
2/20
- LPIC201
- 10問解いた
- これでファイルシステムまでひととおり解き終わり
- AWS-SAA
- NATゲートウェイが対応していないもの
- ポート転送 -> NATインスタンスで対応
- IPv6 -> IPv6に対応したサービスで対応
- Auto Scaling のライフサイクルフック
- スケールイン時に終了するインスタンスのログを収集・退避させる
- スケールアウトによって新たに追加されたインスタンスに初期化スクリプトを実行させる
- ※連動する起動リソースは起動テンプレートで制御するので、ライフサイクルフックとは異なる
- Route53
-
位置情報ルーティングポリシーは、クライアントの使用言語に応じたコンテンツにアクセスをさせるらしい
- 位置じゃないのか(・_・;)
- 位置情報をもとに、クライアントと地理的に近いリージョンにあるサーバーのIPアドレスを回答するのは地理的近接性ルーティングポリシー
-
位置情報ルーティングポリシーは、クライアントの使用言語に応じたコンテンツにアクセスをさせるらしい
- そもそもポリシーには7種類ある
- シンプルルーティングポリシー
- 加重ルーティングポリシー
- レイテンシールーティングポリシー
- 位置情報ルーティングポリシー
- 地理的近接性ルーティングポリシー
- 複数値回答ルーティングポリシー
- フェイルオーバールーティングポリシー
- シンプル以外は、複数を組み合わせることが可能/ヘルスチェックが利用可能
- 複数回答とフェイルオーバーは、ヘルスチェックが必須
- NATゲートウェイが対応していないもの
2/22
給料日!
- LPIC201
- ファイルシステムの章全体を復習中。
- 30問解いて93%正解、だいぶ進歩したなぁ。
- xfs
- xfsにはスナップショットの機能がない。
- xfsを作るコマンド
- mkfs -t xfs
- mkfs.xfs
- ZFSの後継は btrfs で、btrfs は次世代ファイルシステムとして期待されているそう。
- nfsとntfs
- nfs - ネットワーク経由でディレクトリをマウントできる分散ファイルシステム
- ntfs - Windows OSで使われるファイルシステム
- Windows 9x 系以前では、FAT16 / FAT32 が使われていた
- 最近の Windows は ntfs を使う
- AWS - SAA
- ■VPCの問題を1日3問解く
- ■ELBの問題を1日3問解く
- □Route53、DirectConnect/VPN を解き切る
- 1問ずつ解いた → 残り6問ずつなので、土日で3問ずつ解いたらクリアじゃ
- 明日はDirect Connect のところの参考文章を熟読したい。
- ファイルシステムの章全体を復習中。
2/23
- LPIC201
- 章全体の復習30問、全体の復習で20問解いた
- AWS-SAA
- Egress-Only インターネットゲートウェイ
- NATゲートウェイとインターネットゲートウェイの特徴を併せ持つ
- IPv6専用の機能
- VPCエンドポイント
- VPCとVPC外のAWSリソースをプライベートネットワーク経由でつなぐ
- ■VPCの問題を1日3問解く
- ■ELBの問題を1日3問解く
- □Route53、DirectConnect/VPN を解き切る
- こちらは3問ずつ解いて、明日3問ずつ解いたら上がり!
- Egress-Only インターネットゲートウェイ
2/25
失恋した(広義の意味で)
- LPIC201
- 全体の復習で30問解いた
- AWS-SAA
- ELBの中で、固定のIPアドレスを割り当てられるのはNLBだけ
2/26
APIの勉強をさぼり倒している今日この頃
データ分析の学校のベーシックステップが終わったら、Advanced に向けた機械学習の勉強と並行してAPIの勉強を再開したいところ。
- LPIC201
- ファイルシステムのところを復習で30問解いた
- レベル11
- AWS-SAA
- パスベースのルーティング(=URLによるルーティングと理解)に対応しているのはALBのみ
- 今週どうしようかな
============================================
今週の目標
□ELB/AutoScaling の問題 明日3問解く -> これであがり
□パフォーマンス効率の問題 1日3問解く
□運用上の優秀性 1日3問解く
□セキュリティ、アイデンティティ、コンプライアンス 終わらせる(水曜まで)
□マネジメント、ガバナンス 進める(木曜以降)
こんな感じかなー
2/25
失恋した(広義の意味で)
- LPIC201
- 全体の復習で30問解いた
- AWS-SAA
- ELBの中で、固定のIPアドレスを割り当てられるのはNLBだけ
2/27
仕事そろそろ本気出さないとな。
- LPIC201
- efiboot.img は UEFIでISOLINUXを使ってブートする際に使われるイメージで、FAT16で作られている。
- 全体の復習として30問解いた
- 定着していないところが残っているので正答率が低め
- 「解説を熟読する」と書いて放っているところがあるので、明日は熟読の日にしようかな。
- コマ問は捨てに入っている
- AWS-SAA
■ELB/AutoScaling の問題 明日3問解く -> これであがり
■パフォーマンス効率の問題 1日3問解く
↓ここから先は午後
■運用上の優秀性 1日3問解く - AWS Shield - DDos攻撃対策
- API Gateway は保護の対象外
- Standard は無償、Advanced は有償
- Advanced に固有の機能は以下
- 攻撃によって増加したAWS利用料金の補填
- AWSのDDos対応チームによるサポート
- DDos発生時のモニタリングやレポート
- 高度化された大規模な攻撃からの保護
- AWS WAF - 脆弱性をつく攻撃への対策
-
NLB, CLBは保護の対象外
□セキュリティ、アイデンティティ、コンプライアンス 終わらせる(水曜まで)
-
NLB, CLBは保護の対象外
2/28
明日で2月も終わりなのか。
- LPIC201
- 今日から「高度なストレージ管理」の単元で、RAIDの構成を始めた。
- AWS-SAA
- 今日までの目標を達成。
■ パフォーマンス効率の問題 1日3問解く
■ 運用上の優秀性 1日3問解く
■ セキュリティ、アイデンティティ、コンプライアンス 終わらせる(水曜まで)
============================================
明日からの方針
□パフォーマンス効率の問題 1日3問解く
□運用上の優秀性 1日3問解く
□マネジメント、ガバナンス 進める(木曜以降)→1日7問
2/29 閏日!
- LPI201
- 「RAIDの構成」を解ききった
- RAID0 = ストライピング
- 複数のディスクをあわせて一台の巨大なディスクにする
- 読み書きの高速化
- 冗長化はしていない
- 明日からは「記憶装置へのアクセス方法の調整」
- AWS-SAA
■パフォーマンス効率の問題 1日3問解く 解いたけど全問みすった。帰りにまた解く
■運用上の優秀性 1日3問解く
■ マネジメント、ガバナンス 進める(木曜以降)→1日7問 10問解いた