2024年1月の日々精進
1/4
- Taking Python to Production: A Professional Onboarding Guide の受講を開始
- Mac のターミナルに oh my zsh を入れた
- oh my zsh を一時的に無効にする方法:https://unix.stackexchange.com/questions/137183/how-do-you-disable-oh-my-zsh-and-zsh-without-uninstalling-it
- Laravel が PHP のフレームワークだということを理解(←なぜ今)
- LPIC2のコースを見ながら
- Bind9をインストール
- bind9をインストールすると、 /etc/bind ディレクトリができる
- named.conf がプライマリの設定ファイルだが、こいつを直接編集するのではなく named.conf.options や named.conf.local を編集するのがおすすめらしい
-
sudoedit named.conf.options-> nanoが起動してnamed.conf.optionsを編集できる - デフォルトの設定(リスニングポート)
listen-on-v6 { any; };-> すべてのIPv6をリッスン - IPv4のリスニングポートも追加するために、
listen-on port 53{ 127.0.0.1; 10.0.0.17};というエントリを追加 - aclを設定
- options の {} の中に、
allow-query { trusted-hosts; };,allow-transfer { none; };というエントリを追加 - options の {} の外に、以下のエントリを追加
- options の {} の中に、
- Bind9をインストール
acl "trusted-hosts" {
localhost;
localnets;
}
-
その他の設定(bind9)
- options {}の中
recursion yes;allow-recursion { trusted-hosts; };
- forwarders {} の中にIPアドレスを定義してフォワーダーを追加する
- options {}の中
-
設定の反映(bind9)
- (再)起動が必要
sudo systemctl enable --now named.service
-
ファイアウォール
-
sudo ufw statusファイアウォールの状態を見る -
sudo ufw allow Bind9Bind9のアクセスを許可する -
sudo ufw allow 53 comment "hogehoge"hogehogeとコメントをつけて53ポートのアクセスを許可する
-
1/5
- Linux関係
- sudo vim と sudoedit の違いを理解
- デフォルトのエディタを変更する方法
sudo update-alternatives --config editor
- AWS関係
- パブリック&プライベートサブネットを持つVPCを、自分で手作成することを決意したところまで。
- API
- POSTMAN の変数の新しい作り方(URLを範囲選択して右クリック)と、スコープの概念を理解
1/6
- API
- Postman で投げたリクエストの戻りについて、以下を理解
- JSONの表示をたたむ方法
- HTMLが戻りの場合に Preview ができること
- HTTPリクエストのパラメータの渡し方/URL上のあらわれかたを理解
- パラメータ欄にパラメータ名と値を渡すと、?param=value という形でURLが編集される
- クエリパラメータとPATH変数の記法の違いを理解、Postmanでのあらわれかたも。
- Postman で投げたリクエストの戻りについて、以下を理解
1/7
- Numpy
- 機械学習のコースでちょっとつまづいているNumpyを先にやることに
- ND array は N dimension array の略だということ
- API
- Bearer Token で Authorization する POST リクエストを投げる練習
- LINUX
- iptraf を実行してみた。
- 最初、インストールしても iptraf が打てなくて一苦労。
- /usr/sbin/iptraf-ng にコマンドが入っていたので、/usr/sbin/iptraf から -ngにシンボリックリンクを貼ることによって iptraf のコマンドを打てるようになった。こんなやりかたもあるのか。
今日は機械学習をお休みしてしまった。
明日はデータ分析の学校の宿題と、機械学習の勉強をちょっと進める・・・?
Numpyの基礎を先にやるべきか。まぁ、まず寝るか。
1/8
- Numpy
- Array と list の違いを細かく知る
- 要素の取り出し方の記法の違い(arrayはarray[x,y] / list は list[x][y]
- 3d array の作り方
- Why-NumPy-Excercise をわざと途中までで残している。続きは明日。
- Array と list の違いを細かく知る
- API
- body で使える {{$random なんちゃら}} 系のプリセット変数について知った。
これだよこれー知りたかったのは! わからなくてつまづいていたポイントがどんどんクリアになって嬉しい。
APIでも知らなかったことが知れて、今日は当たり日だ。
1/9
- API
- Param, Authorization, Headers の違い(以下と理解、100%の自信はない)
- Param : HTTPメッセージ(URL)の一部
- Header : ヘッダーの一部
- Authorization : ヘッダーの中で、特に認証に特化した部分
- Numpy
- np.array と list の Excercise を実施。
- Param, Authorization, Headers の違い(以下と理解、100%の自信はない)
1/11
昨日は学校の課題にかまけてほぼ自分の勉強ができなかった。
(学校の課題も勉強だけど)
- ネットワーク関連
- RFCの存在を知った https://www.rfc-editor.org/
- 例示用のIPアドレスなんてものがあるということを知った
- 例示用1 192.0.2.0 - 192.0.2.255
- 例示用2 198.51.100.0 - 198.51.100.255
- 例示用3 203.0.113.0 - 203.0.113.255
- localhostと127.0.0.1 がしばしば同義である理由もぼんやり。
- ループバックアドレス 127.0.0.1 - 127.255.255.254
- リンクローカルアドレスって何?については今後。
- Numpy
- Indexingのやりかた
- 普通のリストと同様に、二次配列の要素を a[1][0] みたいに取り出すこともできるけど、a[1,0]のようにカンマ区切りで書くこともできる。
- どっちで書くかは personal preference だけど自分のコードの中では一貫しておけとのこと。
- numpy array だよということがわかるように、a[0,1] の記法でいきたいと思う。
- Indexingのやりかた
- API
- Collectionのインポートのしかたで、jsonファイルをエクスポート→インポートする以外に、APIキーを生成してインポート機能でそのAPIをたたくというやりかたがあるのを知った。
1/12
- Linux関連
- 暗記系の内容をどうメモるかで悩み中。
- unameコマンドの引数
- ubuntu@ip-10-1-1-75:~$ uname -s # カーネルの名前
Linux
ubuntu@ip-10-1-1-75:~$ uname -r # カーネルのバージョン
6.2.0-1017-aws
ubuntu@ip-10-1-1-75:~$ uname -n # ホスト名
ip-10-1-1-75
ubuntu@ip-10-1-1-75:~$ uname -m # ハードウェア名
x86_64
ubuntu@ip-10-1-1-75:~$ uname -p # CPUタイプ
x86_64
ubuntu@ip-10-1-1-75:~$ uname -a # そのすべて
Linux ip-10-1-1-75 6.2.0-1017-aws #17~22.04.1-Ubuntu SMP Fri Nov 17 21:07:13 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux - カーネルのバージョンについて
- 2.5系以前
- 2.x.y の x の部分が偶数なら安定版
- 2.6系以降
- ハイフンや記号がついていなければ安定版
- 2.5系以前
- 仕事
- 自社製品の管理用CLIをようやくちゃんと活用した。。。
- Numpy
- NDarray への値の代入のしかた。こういう基本中の基本を、改めてちゃんと教えてもらえるってありがたや。
1/13
- Linux 関連
- 試験が明後日なので演習をゴリゴリ進めている。最後は暗記の詰めという感じだが、nmcli がまだまだ苦手である。。。
- LPIC201に向けて、1日10問解くのも進めている。こっちはコマンドたたきながらじっくり学習しているので、同じ10問でも時間がかかる。。。
- Numpy
- List と Array の挙動の違いが、両者の目的の違い(List は値を保存する目的、Arrayは数値計算をする目的)から来ているという説明に納得。
- API
- PATCH リクエストの Body の中身をちょっといじくる練習など。
- …あ。PATCHリクエストを昨日やったことを書いてないな。
- データ分析
- 学校で課題の発表あり。
- グラフ&考察を順序よく並べて発表、という点にこだわっていたが、ロジックツリーをぺら1つけるとわかりやすいとフィードバックをいただいた。それを取り入れてみて、自分でもなるほどと思った。
1/14
- Linux
- 明日に迫ったLevel1試験に向けて追い込み模試中。
- API (Postman)
- 変数による共通化。current value さえいれておけばOK
- Numpy
- dtype による型の指定
- Arrayを作ると、デフォルトではセットされている値を保持できる最低限の型になる
- dtypeによる指定で、C言語でサポートされているデータ型(booleanもしくは数値型)にできる

- bool と str だけは、builtin の bool/strを使う(dtype = np.bool ではなく dtype=bool)→あるバージョンから、np.bool と np.str が deprecate されて base の bool, str を使ってねという方針になったらしい
- そもそも np.array が文字列を受け付けるとは知らなんだ
- dtype による型の指定
1/15
- Numpy
- Broadcastingについて
- https://numpy.org/devdocs/reference/ufuncs.html
- API
- PATCH リクエストの続き
- APIは、all about ドキュメントの仕様どおりにリクエストを投げること、なんだよなぁ。(・・・つまらん)←
- でもなぁ。このつまらなさをクリアしてちゃんとデータとれないことにはデータ分析もはじまらねんだよなぁ。がんばる。
- Linux
- LPIC Level1 両区分合格した。
1/16
- Numpy
- Array のスライシングの基本を学んだ。
- 結果の値自体は同じでも、スライスのしかたによって一次配列になったり二次配列になったりする場合がある。この点は注意すべし(←機械学習系のライブラリで、配列の shape が違うというエラーで怒られたことがあったのでここはすごく知りたかった。Yeah)
- API
- PUTメソッドの投げ方
- Patch メソッド: 1項目だけの変更
- PUT メソッド : 複数項目にわたる変更
- ・・・ということでいいのか? Put, Patch, Post の違いは後のレクチャーでカバーされるらしい。
- PUTメソッドの投げ方
1/17
- LPIC
- 201の対策として、カーネルのビルドの手順などを学び中。Qiitaにまとめてる。
- API
- DELETEリクエストの練習と、PUT/POST/GET/DELETE/PATCHの違いなど。
- 呼ぶ側としては、メソッドの違いをそこまで意識する必要はない(なぜならすべてはAPIドキュメントに書いてあり、呼ぶ側は no choice だから)とのこと。・・・そりゃそうだよな。
- HEAD というリクエストのメソッドがある。
- APIそのものが生きているかどうかの確認用
- Bodyを持たず、軽量
- 副作用を起こさない
- Numpy
- stepwise slicing - array[::x,::y]のx,やyの部分で、要素を何個おきに取得するかを指定できる
- array[starts:ends:step] で、デフォルトは[0:len+1:1]
- マイナスは逆向き
- conditional slicing
- array < 2 で、array の中の要素が <2 かどうかを示すTrue/Falseの配列を返す(形はarray と同様)
- array[array<2] で、⏫がTrueの値だけを取り出す一次配列を返す
- stepwise slicing - array[::x,::y]のx,やyの部分で、要素を何個おきに取得するかを指定できる
- np.squeeze()メソッド
- 配列の余計な字数をとりのぞいて、 配列 を返す
- 値の数が1つの場合、結果をprint すると一見 scalar のように見えるが実際には **0次配列 ** が入っている
squeezeの挙動は謎だと思っていたのでちょっとすっきり。(完全にはわかっていないけど)
1/18
今日は会社のハンズオンで自分が講師。
- API
- POSTMAN コースの基本編の宿題をやった。解くところまで。
- Solutionのビデオは明日見る
- Numpy
- Working with Array の Exercise をやった。
1/19
大きな仕事が終わってほっと一息。これでまたちょっと勉強にエンジンかけられる。
- Numpy
- Working with Array の答え合わせした。
- 問題を読み解くのに苦労して、スライスのしかたが模範解答と違うところはちょいちょいあったが、読み取った題意に対してスライスする仕方は合っていた。
- データの生成
- np.empty(), np.zeros(), np.ones(), np,full() を使って任意の型の配列を生成する方法
- Rust (なぜ)
- Twitter でこの言語を知って、興味を持ってしまった
- The book を始めた
- 以下のコードをコンパイルして実行すると、ハローワールドできるという Java っぽい記法
fn main(){
println!("Hello, world!");
}
- printlnのあとの ! は rustmacro の意味で、rustmacro が何かは追々勉強。
- セミコロンは必須。
- .rs -> ソースファイル、コンパイルのコマンド
rustc xxx.rs - すると xxx という名前の実行ファイルができる
- 実行ファイルは、rustがインストールされている・されていないにかかわらず実行可能(.pyだとこうはいかないよねという The book の指摘 <- なるほど)
- Rust でプログラミングする人のことを Rustacean という。へー
- Cargo
- Rust のビルドシステム&パッケージマネージャ
- Rust をインストールすると、自動でついてくる(はず)
cargo new hello_cargo
-
これをたたくと、hello_cargo というディレクトリができて、配下にCargo.toml と src ディレクトリができている
- TOMLってドキュメントの形式なんだ・・・Tom's Obvious Minimal Language たぁふざけた名前だぜ(ほめてる) (https://toml.io/en/)
-
と同時に、.gitignoreファイルもできていて git レポジトリを初期化してくれる。。。
-
Cargo.toml
- [package] セクション
- name, version, edition は、コンパイルに必要な情報
- [dependencies] セクション
- プロジェクトの依存関係を記述。
- Rustでは、コードのパッケージを Crate と呼ぶ。
- bin crate と lib crate ができる
- bin crate には実際に処理を実行するモジュールのファイルが入る。 サブモジュールに分かれることも。
- lib crate には他のモジュールから呼び出されるライブラリのモジュールファイルが入る
- 公開されている lib crate は https://crates.io/ で参照できる
- lib crate の自作もできる(github や crates.io で公開もできる)
- ここまでで疲れたので続きはまた今度。
- と思ったけど、udemy の動画だと続けられそうだったのでもうちょっと
-
cargo runビルドと実行を同時 -
cargo buildビルドのみ - ビルドされた実行ファイルは、target ディレクトリ配下に自動で作られる
-
cargo check文法チェック -
cargo new xxxをやると、- xxx フォルダ配下に、main.rs ができる
- xxx という名前の bin crate ができる
-
cargo new --lib xxxは、共用ライブラリを作る用の new コマンド- これをやると、src 配下に main.rs とともに lib.rs ができる
- src配下に lib.rs があることをもって、xxx という名前の lib crate が生成される
- パッケージは少なくとも一つの crate を持たなければならない(bin or lib)
- pkg : library crate = 1 : 0~1
- pkg : bin crate = 1:*
-
- [package] セクション
-
ここで本当に Rust は打ちとめ。新しいことって楽しいな。
-
API
- TrelloのAPIをPostmanでたたいてみる練習
- APIキーとトークンの取得
- ボードを作った
1/23
土日は勉強をさぼってしまったな。
いや、さぼってはいないんだけど、計画したとおりに進まなかった。
- API(POSTMAN)
- パラメータの bulk edit という機能について知る。
- GUIベースじゃなく、key : value の形でテキストベースで編集できる。
- GUIベースでAPIの基本を学ぶコーナーは、どうやら完了したらしい!
- これからは JavaScript を使ったAPIテストについてのコーナーに入っていく。ここからが本命だっ!
- POSTMAN上では、Pre-request Script と Test のタブで JavaScript が書けるんだとさ!
- Pre-request Script - APIを実行する前に実施するJavaScript
- ここに console.clear(); を記述しておくことで、毎回手でコンソールをクリアする必要がなくなる!
- Test - API実行後に実施するJavaScript
- Pre-request Script - APIを実行する前に実施するJavaScript
- Numpy
- ランダムジェネレーター(ある分布に従ったランダムなMatrixを生成できる機能)について学んだ
- 確率分布の種類について、学校でさんざんやっているのにもう忘れている><
- https://numpy.org/doc/stable/reference/random/generator
学習を先に進めることと、学んだ知識を定着させること。
これをどうすればよかんべと今悩んでいる。
Numpy も API も、これ自体をやることが目的じゃなく、Numpyのあとには機械学習を勉強したいし、APIは・・・なんのためにやっているんだっけ。まぁ、これができないと話にならない領域が多すぎるからやっているという。
Numpyの勉強は、仕事が落ち着いている今週のうちにとっとと終わらせて来週からは機械学習の勉強を再開したい。
APIは・・・いよいよ楽しくなってきたので、まぁやるんだけど、これに加えてLPICもあるしAWSもやりたいし、やることいっぱい。まぁ、焦らずひとつひとつやっていくべこ。
1/24
- EQ的なこと
- 自分が何もやってないくせにこっちばっかり急かしてこられると本当に腹が立つ
- と思ったけど、相手が何もやっていないかどうかを自分は知らないんだなと。反省
- 自分が何もやってないくせにこっちばっかり急かしてこられると本当に腹が立つ
- Numpy
- Numpyer にとって、 transpose() がなんでそんなに重要なのかが今日わかった気がする
- (正直、transposeしなくていい形でデータ作ればいいじゃんと思っていた)
たとえば以下のようなコードでランダムな配列を作り・・・
# 各列の値を作る(要素の数を揃えておく)
col1 = array_RG.normal(loc=2, scale=3, size = (1000))
col2 = array_RG.normal(loc=7, scale=2, size = (1000))
col3 = array_RG.logistic(loc=11, scale=3, size = (1000))
col4 = array_RG.exponential(scale=4, size=(1000))
col5 = array_RG.geometric(p=0.7, size=(1000))
各列の値をマトリックスにまとめると、shape は 5,1000 になる(5行1000列)
random_test_data = np.array([col1, col2, col3, col4, col5])
random_test_data.shape
そこで、transpose() を使う。
random_test_data = np.array([col1, col2, col3, col4, col5]).transpose()
random_test_data.shape()
すると、1000,5 になる(1000行5列)
- API(POSTMAN)
- Test に JavaScript を書いてテストを流す一連の流れを体験!
- This is what POSTMAN is for!!
- 今までいかに自分が表層的にしか POSTMAN を使っていなかったかを実感、ようやく入り口に立てた感じ。
- がんばるぞ!
1/25
けっこう勉強したのに、その日のうちにメモるのを忘れた
- LPIC201
- システムの起動に関するトピックに移行
- コマ問の正解をひととおり見た(見ただけ)
- API(POSTMAN)
- テストコードのためのJavaScriptの勉強に突入
- 関数の書き方をひととおり学ぶ。おもれーぞ
- Numpy
- データの生成のChapterの演習を途中まで実施
1/26
- LPIC201
- システムの起動をコマ10問、選択10問解く
- Level1でやっていた点が線になっていく感じがして楽しい!
- Level1 でやめていたら、「暗記がつらかった」で終わっていただろう。続けてよかった。
- データ分析
- 重回帰分析について、とりあえず「わからないことがたくさんある」という程度に概要をうっすらさらった(明日の通学までに、もう少し解像度上げとかないとやばそう)
- Numpy
- データ生成の演習を終了。
- 分布関係の概念を忘れすぎていて、そこでつまづくことが多い。
- loadtxt()とgenfromtxt()の使い方と違いについて
- Numpy では基本、ひとつの array の中で型をまぜてはいけないということ。。。
- データ生成の演習を終了。
1/27
- データ分析の学校
- 単回帰と重回帰分析についての授業
- 予習のときはどうなることかと思ったが、授業についていくことはついていけた
- しかし復習しないと絶対忘れる
- QQプロットについては、授業ではあまり深く理解できず YouTubeの解説動画(熊野コミチさん)を見てようやく理解できた
- 単回帰と重回帰分析についての授業
明日からの宿題
- 以下のキーワードで1日最低1個はYouTube動画を見る
- 凸度、尖度、歪度
1/28
- LPIC201
- 着々と1日10問を消化
- Numpy
- np.save() と np.savez() を、朝やってもう忘れかけているとかそういうレベル
- JavaScript
- オブジェクト内の変則的な変数名の指定方法と、["変数名"]での呼び方
- object を JSON.stringify で JSON にする方法 / JSON を JSON.parse() で object にする方法
- API(POSTMAN)
- ついに、BODY 部分にアクセスして特定の値をとりだす方法を理解したぜー!
1/29
- AWS
- 昨日から、LPIC201に加えSAAも1日10問解くことにした
- こちらは特に目標を決めず、とりあえず10問ずつ解いていく
- ...けどそのペースでやっていれば、早くて2ヶ月、遅くとも3ヶ月くらいで合格すんだよな
- Anyways, 学びとしては
- HDFSのライバルかもしれない? Lustre というファイルシステムの存在
- SMBプロトコル - Windows 標準のファイル共有プロトコル。SMB1ではポート139, 2-3ではポート445を仕様。445では初期接続時からSSL/TLSによる暗号化通信を行う。
- Amazon FSx For Windows へのアクセスには、クライアント側が SMB プロトコルに対応している必要あり(Windowsである必要はない)
- 昨日から、LPIC201に加えSAAも1日10問解くことにした
- API
- Postman における、データの Parse のしかた
- レスポンスボディが JSON なら、
-
const xxx = pm.response.json();でxxxに JSON が入る - あとはここにアクセスができればOK!
- たたんである要素を展開することで、構造と数が見えやすくなる
-
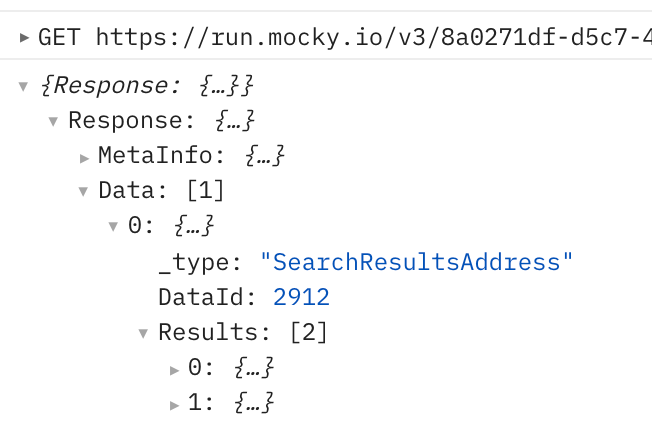
- 親の要素から始めて、一段階ずつ順番に、エラーが出ないことを確認しながら進めていくのがおすすめです
- Postman における、データの Parse のしかた
- 以下のコードを使って、ステータスコードが想定通りであることをテストする練習をひたすら実施
pm.test("ステータスコードが200であること", () => {
pm.response.to.have.status(200);
});
- Numpy
- 今日からNumpyやめて、機械学習の勉強に戻る!
1/30
SAAの勉強会が始まりそうでわくわく。
SAAの勉強始めたの一昨日だったのか・・・改めて、行動はえーな自分。
- LPIC201
- 毎朝ちゃんとやっているのに、やっていることを忘れるくらい生活に馴染んでいる。良い傾向。(馴染みすぎて忘れそう。今後も忘れないように続ける 笑)
- AWS-SAA
- RedShift と EBSについての基礎問題をやった。考えて解いたら9割以上正解できた。
- こんな感じで勉強続けていけば、まぁ受かるだろうという兆しが見えてきた。
- 機械学習
- 難しすぎてびびって Numpy の勉強に走ったきっかけとなったお手本コードに関する解説ビデオを見る → 極めて上級編のコードである上、throughout the entire career において二度と書くことはないコードだろうと言われてめっちゃ肩透かし。最初から先に進んでいればよかった。
- でもこの1ヶ月弱? ちゃんと Numpy を基礎から学んだことは、回り道だったようで無駄にはなっていない。
- これから1日1トピック、MLのコースを進めていけば、再来週のクラスタリングのクラスまでに予習が完了しそう! という見込みが立った。よかった。
- API(JS, Postman)
- Body の内容を検査するテストの書き方を学んだ
1/31
今日で1月最後か。
- AWS-SAA
- サーバレス関係がよく出るということで、Lambda, API Gateway あたりを勉強
- ●●のひとつ覚え系で切り抜けられる問題はなくて、関連サービス(VPC、NAT GWなど)の内容も理解した上で解く必要がありそう
- Lambda を動かしてみたい気もするが、試験対策としてそこまで必要かを見極めてから
- 試験に申し込んでしまった。。。
- LPIC 201
- 今日から「システムのリカバリ」の単元へ。
- ちょっとずつ、ちょっとずつ、点が線につながっている。
- 機械学習
- KNN Classification を回した
- 与えられたデータで、指定されたアルゴリズムの予測を回すこと自体はそんなに難しくないんだよなぁ
- 肝心なのは与えられたデータをもとに、使うアルゴリズムを判断することだけど、このあたりはまさに学校で学べる部分。なので Udemy では How to 手を動かすを学んで、学校では頭の使い方を学ぶという両輪でやっていければいいのかなと思いました。
- API
- APIのことを勉強していたおかげで、Lambdaの理解がスムーズに進んだ。
- Happy path test -> 全部正常に行った場合の挙動テスト
- Negative test -> エラー時の振る舞いや境界値などの確認
- POSTMANではコレクション、フォルダ、APIのレベルでテストコードを共通化できるということ!!!!!