nginx + stress-ng で学ぶ ECS の水平スケーリング挙動
- この記事は本番構成のベストプラクティスではない。
- 目的は「スケーリングのメカニズムを実感するデモ」にある。
- apt-get のような悪手もあえて採用しているのでそのまま使う事はできません。
まず、今現在のecsのタスク定義のコード
以下のようにnginxのデフォルトイメージをプルしてcommandでデフォルトページを適当に書き換えるという処理をやっている。
// 抜粋
taskDef.addContainer('NginxContainer', {
// ...
image: ecs.ContainerImage.fromRegistry('public.ecr.aws/nginx/nginx:stable'),
command: [
'sh',
'-c',
[
// タスクごとに異なる識別子(ホスト名=コンテナID相当 & ランダムUUID)
'HOST=$(cat /etc/hostname)',
'UUID=$(cat /proc/sys/kernel/random/uuid)',
// 適当なHTMLを書き込み
'mkdir -p /usr/share/nginx/html',
'echo "<html><body style=\'font-family:sans-serif\'>" > /usr/share/nginx/html/index.html',
'echo "<h1>Hello from $HOST</h1>" >> /usr/share/nginx/html/index.html',
'echo "<p>uuid: $UUID</p>" >> /usr/share/nginx/html/index.html',
'echo "</body></html>" >> /usr/share/nginx/html/index.html',
// nginx をフォアグラウンドで
"nginx -g 'daemon off;'",
].join(' && '),
],
});
}
}
これを変更し、nginxに負荷を与えるように改変してみる
stress-ngを使う
stress-ngの説明や使い方はまずは割愛するとして、名前の通り実行ホストに負荷をかけるツールである。負荷をかけるといっても外からでなく内側から負荷をかけていく感じだ。
まずそもそもこのコマンドが入ってないので入れないといけないのだが、そもそもこのcommandでの'echo...連打とかはソースコードがどんどん辛くなってゆくので、もうちょっと編集するのに楽なようにまずは初手で整理しておこう。
lib/ecs-stack.ts
@@ -78,6 +78,26 @@ export class EcsStack extends cdk.Stack {
messageParam.grantRead(execRole);
dbPasswordParam.grantRead(execRole);
+ const startupScript = `
+set -eu
+
+HOST="$(cat /etc/hostname)"
+UUID="$(cat /proc/sys/kernel/random/uuid)"
+
+mkdir -p /usr/share/nginx/html
+cat > /usr/share/nginx/html/index.html <<HTML
+<html>
+ <body style="font-family:sans-serif">
+ <h1>Hello from $HOST</h1>
+ <p>uuid: $UUID</p>
+ </body>
+</html>
+HTML
+
+# フォアグラウンドで nginx を実行
+exec nginx -g 'daemon off;'
+`;
+
taskDef.addContainer('NginxContainer', {
// image: ecs.ContainerImage.fromRegistry('nginx:latest'), // Docker Hub
// Docker Hub ではなく Public ECR ミラーを使う
@@ -91,24 +111,7 @@ export class EcsStack extends cdk.Stack {
APP_MESSAGE: ecs.Secret.fromSsmParameter(messageParam),
DB_PASSWORD: ecs.Secret.fromSsmParameter(dbPasswordParam),
},
-
- command: [
- 'sh',
- '-c',
- [
- // タスクごとに異なる識別子(ホスト名=コンテナID相当 & ランダムUUID)
- 'HOST=$(cat /etc/hostname)',
- 'UUID=$(cat /proc/sys/kernel/random/uuid)',
- // 適当なHTMLを書き込み
- 'mkdir -p /usr/share/nginx/html',
- 'echo "<html><body style=\'font-family:sans-serif\'>" > /usr/share/nginx/html/index.html',
- 'echo "<h1>Hello from $HOST</h1>" >> /usr/share/nginx/html/index.html',
- 'echo "<p>uuid: $UUID</p>" >> /usr/share/nginx/html/index.html',
- 'echo "</body></html>" >> /usr/share/nginx/html/index.html',
- // nginx をフォアグラウンドで
- "nginx -g 'daemon off;'",
- ].join(' && '),
- ],
+ command: ['sh', '-c', startupScript],
});
// (必須) SSM Messages チャネル用の権限
こんな形でstartupScriptに追い出して使いやすくした。ここまではまだ何の処理も加えていない。
stress-ngをapt
@@ -74,6 +74,11 @@ export class EcsStack extends cdk.Stack {
const startupScript = `
set -eu
+export DEBIAN_FRONTEND=noninteractive
+
+apt-get -qq update >/dev/null 2>&1
+apt-get -qq -y --no-install-recommends install stress-ng procps >/dev/null 2>&1
+rm -rf /var/lib/apt/lists/*
HOST="$(cat /etc/hostname)"
UUID="$(cat /proc/sys/kernel/random/uuid)"
このようにcommandでapt-getしている。
なお、topコマンドなども利用できるようにprocpsも一応入れておいた。
stress-ngを実行してみる
stress-ngは大量のオプションがあるが --CPUというオプションがあってCPU負荷をかける個数(ワーカー数)をセットできる、簡単にいえば数字がでかい程負荷が高くなる(可能性がある)。ここではこの数を動的に注入できるようにしておく。
@@ -83,17 +83,21 @@ rm -rf /var/lib/apt/lists/*
HOST="$(cat /etc/hostname)"
UUID="$(cat /proc/sys/kernel/random/uuid)"
+BURN_CPUS="${'$'}{BURN_CPUS:-0}"
+
mkdir -p /usr/share/nginx/html
cat > /usr/share/nginx/html/index.html <<HTML
<html>
<body style="font-family:sans-serif">
<h1>Hello from $HOST</h1>
<p>uuid: $UUID</p>
+ <p>burn.CPUs: $BURN_CPUS</p>
</body>
</html>
HTML
+stress-ng --CPU "$BURN_CPUS" &
# フォアグラウンドで nginx を実行
exec nginx -g 'daemon off;'
`;
@@ -111,6 +115,7 @@ exec nginx -g 'daemon off;'
APP_MESSAGE: ecs.Secret.fromSsmParameter(messageParam),
DB_PASSWORD: ecs.Secret.fromSsmParameter(dbPasswordParam),
},
+ environment: isDev ? { BURN_CPUS: '2' } : {},
command: ['sh', '-c', startupScript],
});
これをデプロイするとCPU負荷の高まったタスクが貼り付くはずだ。ここでは2タスク与えている。
今ECS execが有効なのでこの中に入ってみよう
aws ecs execute-command \
--region ap-northeast-1 \
--cluster ecs-cluster-dev \
--task 6ed07c8633dd4de4849cf2523c1c9335 \
--container NginxContainer \
--interactive \
--command "/bin/sh"
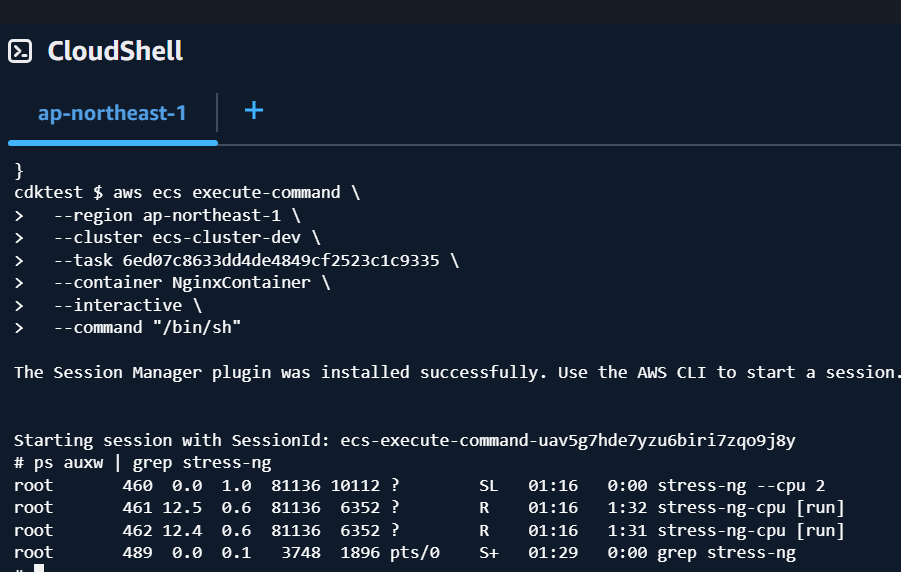
ps auxw | grep stress-ng

top

正しく$BURN_CPUSがセットされている
正常なstress-ngの起動が観察できた。
サービスの負荷を観察する
これはAWS CloudWatchで可能
$ AWS CloudWatch get-metric-statistics --namespace AWS/ECS --metric-name CPUUtilization --dimensions Name=ClusterName,Value=ecs-cluster-dev Name=ServiceName,Value=dev-web --statistics Average --period 60 --start-time $(date -u -d '5 minutes ago' +%Y-%m-%dT%H:%M:%SZ) --end-time $(date -u +%Y-%m-%dT%H:%M:%SZ) --region ap-northeast-1
{
"Label": "CPUUtilization",
"Datapoints": [
{
"Timestamp": "2025-09-07T01:31:00+00:00",
"Average": 99.98344167073569,
"Unit": "Percent"
},
{
"Timestamp": "2025-09-07T01:32:00+00:00",
"Average": 99.96876653035483,
"Unit": "Percent"
},
{
"Timestamp": "2025-09-07T01:33:00+00:00",
"Average": 99.97200902303061,
"Unit": "Percent"
},
{
"Timestamp": "2025-09-07T01:34:00+00:00",
"Average": 99.95374552408855,
"Unit": "Percent"
}
]
}
単純な水平スケーリング
ここでは常にCPUが100%に張り付いているので、たとえば「CPU負荷80%を目処にタスクを増やす(スケールアウト)」するという指令を書くと常にタスクは増えるだろう。それはよいとしてここではタスクが増えていく様をみるためにこれをまず書いておこう。
@@ -183,6 +183,18 @@ exec nginx -g 'daemon off;'
enableExecuteCommand: true,
serviceName: webServiceName, // dev-web / prod-web
});
+ // Auto Scaling: CPU 80%を目標(常時100%なので必ず増殖→maxまで)
+ const scalable = service.autoScaleTaskCount({
+ minCapacity: 2, // 既定 desiredCount と合わせる
+ maxCapacity: 3, // 観察用に抑えめ(必要なら増やす)
+ });
+
+ scalable.scaleOnCpuUtilization('CPU80', {
+ targetUtilizationPercent: 80,
+ // 観察が目的なので縮小は遅らせる/拡大は早め
+ scaleOutCooldown: cdk.Duration.seconds(30),
+ scaleInCooldown: cdk.Duration.minutes(10),
+ });
// サービスをターゲットグループに登録(タスクENIのIPが自動でTGに入る)
service.attachToApplicationTargetGroup(tg);
これでしばらく放置すると
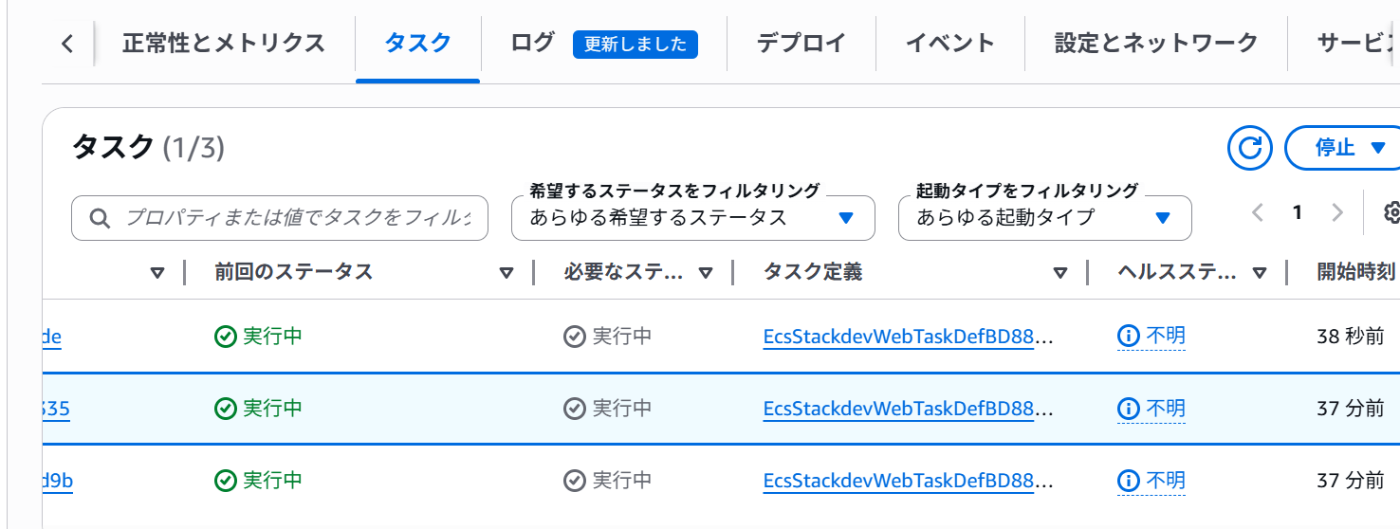
タスクが3つになった
このようにタスクが増えている。これはサービスで「サービスの自動スケーリング」タブ
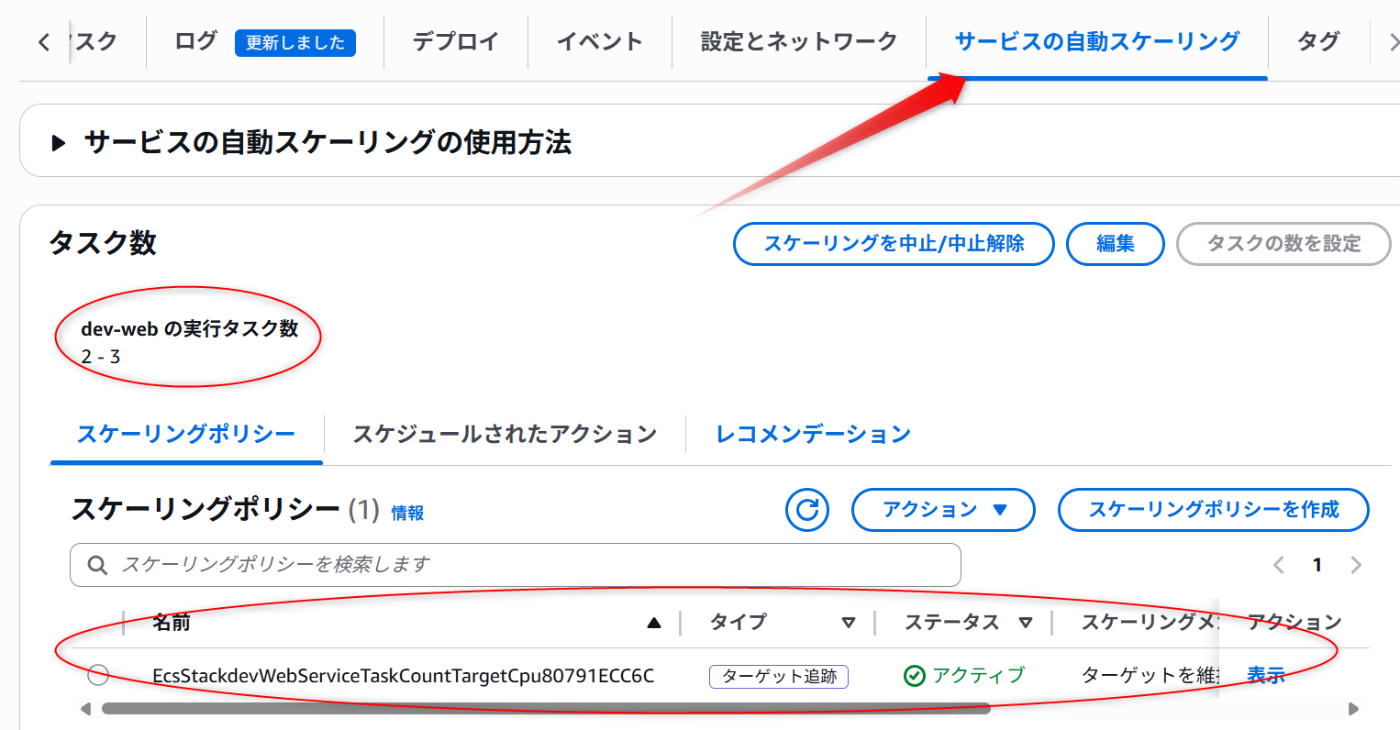
自動スケールに関してもろもろ設定されている

タスク数が頭打ちになっている
このあたりで確認可能だと思う。
水平スケールイン(減少)を確認する
まずstress-ngは時間をセットして実行可能であるので、これも環境変数からセット可能にしてみよう。
@@ -84,6 +84,7 @@ HOST="$(cat /etc/hostname)"
UUID="$(cat /proc/sys/kernel/random/uuid)"
BURN_CPUS="${'$'}{BURN_CPUS:-0}"
+BURN_SECS=${'$'}{BURN_SECS:-0}
mkdir -p /usr/share/nginx/html
cat > /usr/share/nginx/html/index.html <<HTML
@@ -97,7 +98,7 @@ cat > /usr/share/nginx/html/index.html <<HTML
HTML
-stress-ng --CPU "$BURN_CPUS" &
+stress-ng --CPU "$BURN_CPUS" --timeout "$BURN_SECS" &
# フォアグラウンドで nginx を実行
exec nginx -g 'daemon off;'
`;
@@ -115,7 +116,12 @@ exec nginx -g 'daemon off;'
APP_MESSAGE: ecs.Secret.fromSsmParameter(messageParam),
DB_PASSWORD: ecs.Secret.fromSsmParameter(dbPasswordParam),
},
- environment: isDev ? { BURN_CPUS: '2' } : {},
+ environment: isDev
+ ? {
+ BURN_CPUS: '2',
+ BURN_SECS: '300',
+ }
+ : {},
command: ['sh', '-c', startupScript],
});
これにより300秒経ったらstress-ngがtimeoutするので想定する流れは以下のようになるはずだ
-
desiredCount: 2によりタスク2つ起動 - 2タスクそれぞれ
stress-ngが発動しサービスのCPUが80%を越える -
scaleOnCPUUtilizationにより スケールアウト(タスク数増加) しタスクが3になる -
BURN_SECS: '300'の指定により先行の2タスクのCPU負荷が減る -
targetUtilizationPercent: 80を下回る事でminCapacity: 2まで スケールイン(タスク数減少) する

細かいのはいろいろあるが2から3になって2となった
とまあこんな感じなので、テストとしてはdesiredCountを1にしたりminCapacityを4とか5にしたりいろいろ試してみるとよいとは思う。
その他
スケールイン/アウトの基準の考え方
今現在はタスクのCPUの度合のみを考えているが、ことwebアプリに関してはタスクごとのCPUがぶん回っている場合に加えて、IOが詰まっている場合などいろいろな理由で遅くなる。
この場合scaleOnCPUUtilizationでなくscaleToTrackCustomMetricでスケールの閾値をセットする方法もあるのだが、やや上級なのでここでは割愛します。
Discussion